

Introdução
Com a infinidade de Modelos de Linguagem de Grande Escala (LLMs) disponíveis, identificar aquele que se alinha com seus requisitos específicos pode parecer esmagador. O cenário está em constante evolução, com novos modelos e versões refinadas surgindo quase semanalmente. Consequentemente, qualquer tentativa de catalogar LLMs e seus atributos certamente se tornará rapidamente desatualizada.
Em vez de tentar delinear cada LLM de destaque e descrever seus pontos fortes e fracos, este artigo visa fornecer um conjunto de critérios para avaliar modelos. Ao oferecer uma estrutura de análise, os leitores podem avaliar modelos recém-lançados em relação a características essenciais e compará-los de forma eficaz. Os atributos principais a considerar ao avaliar um LLM incluem:
- tamanho
- tipo de arquitetura
- desempenho em benchmarks
- processos de treinamento e vieses
- licenciamento/disponibilidade
Qual é o tamanho de um LLM?
Sua principal consideração ao selecionar um LLM é sua restrição orçamentária. Operar LLMs pode incorrer em custos substanciais, destacando a importância de optar por um modelo que permaneça dentro dos limites orçamentários. Um fator indicativo de custo é o número de parâmetros dentro de um LLM.
Qual é o número de parâmetros de um modelo?
A quantidade de parâmetros corresponde à contagem de pesos e vieses ajustados pelo modelo durante o treinamento e utilizados no cálculo de sua saída. Por que essa quantidade é significativa? Ela oferece uma aproximação aproximada da sobrecarga de desempenho e da velocidade de inferência de um modelo. De forma geral, esses fatores estão diretamente relacionados: à medida que o número de parâmetros aumenta, também aumenta o custo associado à geração de uma saída.
Qual é a velocidade de inferência de um modelo?
A velocidade de inferência de um modelo de linguagem refere-se à duração necessária para processar uma entrada, medindo essencialmente sua velocidade de saída. É importante reconhecer que a velocidade de inferência e o desempenho geral de um modelo são complexos e multifacetados, não determinados unicamente pelo número de parâmetros. No entanto, para o contexto deste artigo, a contagem de parâmetros fornece uma estimativa aproximada do desempenho potencial de um modelo. Felizmente, existem vários métodos estabelecidos para mitigar o tempo de inferência de modelos de aprendizado de máquina.

Número de parâmetros para cada LLM.
Um modelo de tamanho médio normalmente contém menos de 10 bilhões de parâmetros, enquanto os mais acessíveis podem ter menos de 1 bilhão. No entanto, modelos com menos de 1 bilhão de parâmetros são frequentemente mais antigos ou não são especificamente adaptados para tarefas de geração de texto. No outro extremo do espectro, modelos caros possuem mais de 100 bilhões de parâmetros, exemplificados pelo GPT-4 com impressionantes 1,76 trilhão de parâmetros. Muitas séries de modelos, incluindo LLaMa 2, Mistral, Falcon e GPT, oferecem versões menores, com menos de 10 bilhões de parâmetros, e versões maiores variando de 10 a 100 bilhões de parâmetros.
Quais são os diferentes tipos de LLMs?
Em termos gerais, os LLMs baseados em transformers podem ser categorizados em três grupos com base em sua arquitetura: apenas encoder, encoder-decoder e apenas decoder. Essa categorização ajuda a entender o propósito pretendido do modelo e seu desempenho em tarefas de geração de texto.
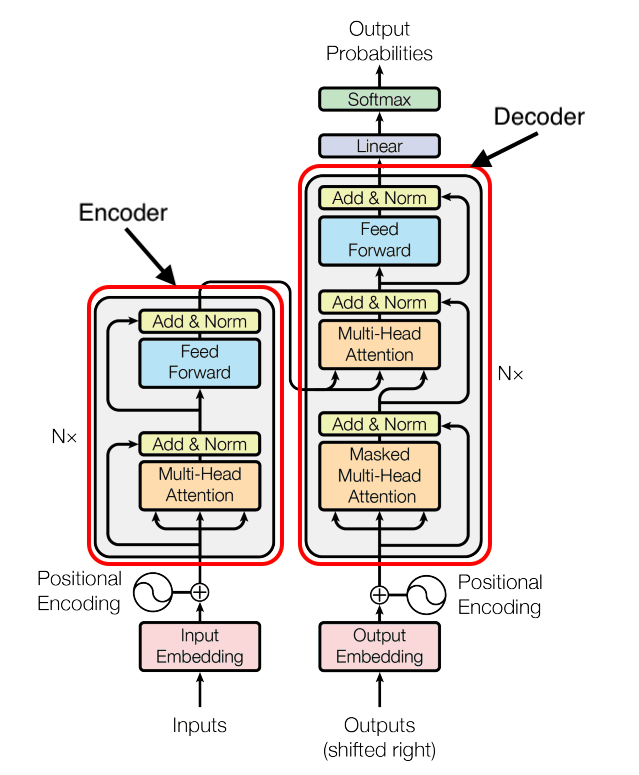
O que é um modelo apenas encoder?
Os modelos apenas encoder utilizam exclusivamente um componente encoder, encarregado de codificar e categorizar o texto de entrada. Esses modelos são benéficos para atribuir texto a categorias específicas. O BERT, o modelo apenas encoder predominante, foi treinado como um modelo de linguagem mascarada (MLM) e para previsão da próxima frase (NSP). Ambos os objetivos de treinamento envolvem discernir elementos essenciais dentro de uma frase.
O que é um modelo encoder-decoder?
Os modelos encoder-decoder primeiro codificam o texto de entrada, semelhante aos modelos apenas encoder, antes de proceder à geração ou decodificação de uma resposta com base nas entradas codificadas. Um exemplo de arquitetura de modelo encoder-decoder é o BART. Esses modelos são versáteis, adequados tanto para tarefas de geração de texto quanto de compreensão, tornando-os particularmente valiosos para fins de tradução. O BART, por exemplo, é excelente em resumir textos longos, como artigos, em saídas coerentes. Por exemplo, o BART-Large-CNN é uma variante ajustada especializada em gerar resumos de texto, tendo sido treinada em uma ampla gama de artigos de notícias. No geral, os modelos encoder-decoder servem a um propósito duplo, atendendo tanto a tarefas de compreensão quanto de geração de texto.
O que é um modelo apenas decoder?
Os modelos apenas decoder são especializados em gerar a próxima palavra ou token com base em um prompt dado, concentrando-se exclusivamente em tarefas de geração de texto. Eles oferecem simplicidade no treinamento e são particularmente eficientes para fins de geração de texto puro. Séries de modelos como GPT, Mistral e LLaMa se enquadram na categoria apenas decoder. Se seu requisito principal gira em torno da geração de texto, os modelos apenas decoder são a escolha preferida.
No entanto, vale notar que o Mistral 8x7B (também conhecido como Mixtral) emprega uma arquitetura única denominada “mixtral de especialistas”, que o diferencia dos modelos apenas decoder convencionais. Similarmente, há indícios de que o GPT-4 pode utilizar uma técnica semelhante. Portanto, esses modelos podem não se encaixar perfeitamente na categoria apenas decoder. Além disso, técnicas arquitetônicas emergentes como a geração aumentada por recuperação (RAG) desafiam a classificação dentro dessas categorias estabelecidas.
Você pode se aprofundar em nosso blog sobre a tecnologia RAG: O que é RAG: Uma Introdução Abrangente à Geração Aumentada por Recuperação

Como medir a qualidade de desempenho de um LLM
Várias métricas são empregadas para avaliar a capacidade de um modelo de linguagem de compreender, interpretar e fornecer respostas precisas a diversos prompts. Esses métodos de avaliação diferem dependendo do uso pretendido do modelo de linguagem. Por exemplo, o BERT, um modelo apenas encoder projetado principalmente para tarefas como classificação, não é avaliado usando os mesmos critérios que o GPT-3, um modelo apenas decoder adaptado para geração de texto. Nas seções seguintes, elucidaremos algumas das metodologias usadas para avaliar LLMs de geração de texto.
Medindo a qualidade de um LLM usando exames acadêmicos
Um método prevalente para avaliar a eficácia de um modelo de linguagem generativo envolve submetê-lo a exames. Por exemplo, o GPT-4 foi avaliado em relação ao GPT-3.5 em uma variedade de testes acadêmicos. Através desse processo, o desempenho do modelo é comparado tanto com pontuações humanas quanto com as de modelos anteriores, fornecendo insights sobre suas capacidades de raciocínio dentro de um contexto acadêmico. Abaixo está uma breve compilação de alguns dos exames administrados ao GPT-4, juntamente com suas pontuações comparativas em relação ao GPT-3.5 e à média humana:

Desempenho do GPT-4 e GPT-3.5 em exames padronizados em comparação com a média humana.
Outra métrica de desempenho semelhante aos exames acadêmicos envolve apresentar ao modelo diversos conjuntos de dados de Perguntas e Respostas (QnA). Essa abordagem é utilizada no Hugging Face Open LLM Leaderboard, oferecendo um recurso valioso para comparar diferentes LLMs com base em seu desempenho em conjuntos de dados QnA. Esses conjuntos de dados fornecem um meio direto de benchmarking de um LLM, permitindo a avaliação de sua inteligência geral e capacidades lógicas.
Tabela de comparação de qualidade entre LLMs
É essencial observar que comparar uma pontuação de 0-shot com uma pontuação de 25-shot tem pouco valor. Idealmente, para comparações de qualidade, você deve manter consistência no tipo de prompting usado. Mesmo ao comparar dois pontos de dados com o mesmo método de prompting, diferenças nos procedimentos de teste ainda podem levar a imprecisões. No entanto, o seguinte deve fornecer uma comparação aproximada de qualidade:

Uma tabela de comparação de qualidade entre LLMs nos testes ARC, MMLU e WinoGrande usando prompting few-shot e zero-shot.
Qual é o melhor LLM atual para usar como chatbot?
Examinando esta tabela, considerando as ressalvas mencionadas anteriormente, é evidente que o GPT-4 se destaca como o LLM com melhor desempenho em termos de qualidade geral. No entanto, para o melhor custo-benefício, os modelos Mistral oferecem a melhor escolha. Particularmente, a versão 8x7B Mistral emprega uma técnica única que amalgama múltiplos modelos Mistral 7b, resultando em saídas de maior qualidade. Essa abordagem cria um modelo altamente eficiente que também se destaca em avaliações de benchmark.
Como os dados de treinamento podem afetar os LLMs
A seleção de conjuntos de dados de treinamento para um modelo levanta considerações significativas. Que tipo de dado foi utilizado? O conjunto de dados é especificamente adaptado para aplicações particulares? Existem vieses inerentes dentro do conjunto de dados que podem impactar o modelo?
Como os vieses do modelo surgem, tomando o BERT como exemplo
Para a maioria dos LLMs, os dados de treinamento são tipicamente extensos, visando fornecer ao modelo uma compreensão fundamental da linguagem. O BERT, por exemplo, passou por pré-treinamento usando Wikipedia (2.500M palavras) e BookCorpus (800M palavras). No entanto, em alguns casos, como com os modelos Mistral, o conjunto de dados de treinamento permanece indisponível ao público.
Examinar esses conjuntos de dados pode oferecer insights sobre potenciais vieses inerentes ao modelo. Considere o BERT, que depende fortemente do conjunto de dados da Wikipedia em inglês para treinamento. Embora a Wikipedia seja frequentemente considerada uma fonte neutra e imparcial, isso pode nem sempre ser verdade. Por exemplo, The Guardian relatou que apenas 16% dos editores da Wikipedia são mulheres, e apenas 17% dos artigos sobre pessoas notáveis são sobre mulheres. Além disso, o conteúdo sobre a África Subsaariana é principalmente escrito por indivíduos fora da região. Dada a dependência do BERT na Wikipedia em inglês, é plausível que vieses presentes na plataforma possam ser herdados pelo modelo. De fato, evidências sugerem que o BERT exibe vieses de gênero e raciais em suas saídas. Em resumo, vieses nos conjuntos de dados de treinamento de modelos pré-treinados podem influenciar suas capacidades de geração de texto. Portanto, é essencial considerar tais vieses, pois eles impactam a experiência do usuário final.
O que é um modelo ajustado (fine-tuned)?
O ajuste fino envolve retreinar um modelo já treinado em novos dados, muitas vezes levando à criação de modelos derivados especializados para fins específicos. A escolha dos dados usados para ajuste fino é crucial ao avaliar as aplicações potenciais de um modelo. Por exemplo, o FinBERT, um derivado do BERT, foi ajustado em um conjunto substancial de dados de linguagem financeira, tornando-o particularmente útil para analisar o sentimento financeiro de textos. Se você quiser saber mais sobre ajuste fino, leia nosso artigo: Como Fazer Ajuste Fino em Modelos de Linguagem de Grande Escala?
Embora alguns modelos sejam projetados com a intenção de permitir ajuste fino posterior, outros já são ajustados para cumprir objetivos específicos. Por exemplo, modelos como Falcon podem ter versões de chat refinadas para funcionar efetivamente como chatbots. Vários métodos são empregados para ajuste fino de modelos, embora os detalhes dessas técnicas estejam além do escopo deste artigo. Em geral, um modelo ajustado normalmente fornece informações sobre seus propósitos pretendidos e as técnicas específicas de ajuste fino aplicadas.
Qual conjunto de dados cada modelo de linguagem utiliza?
Dado o impacto significativo dos dados de treinamento no desempenho de um modelo, os desenvolvedores criaram vários métodos de raspagem web para adquirir conjuntos de dados de alta qualidade. Por exemplo, a ferramenta Webtext da OpenAI raspa “todos os links de saída do Reddit que receberam pelo menos 3 karma”. Abaixo está uma compilação de conjuntos de dados utilizados por alguns dos modelos mais notáveis até o momento, tendo em mente que muitos desenvolvedores não divulgam os conjuntos de dados que empregam.

Conjuntos de dados nos quais os LLMs mais populares foram treinados.
O licenciamento e a disponibilidade de LLMs
Para utilização comercial de LLMs, é imperativo avaliar os termos de licenciamento associados a um modelo específico. Além disso, a disponibilidade pode ser sutil: certos modelos são de código fechado, exigindo acesso apenas por meio de sua API.
O que é um modelo de linguagem de código fechado?
Um modelo de código fechado implica que seu código-fonte não é publicamente acessível. Modelos como GPT-3 e GPT-4 se enquadram nesta categoria, tipicamente acessíveis apenas através de uma API. No entanto, embora a integração da API possa ser direta, ela também acarreta despesas. Geralmente, para integração de plataforma, dependendo da escala, é mais econômico utilizar um modelo de linguagem de código aberto e treiná-lo ou implantá-lo usando uma plataforma como a UbiOps.

API LLM da novita.ai
O que é um LLM de código aberto?
Um LLM de código aberto refere-se a um modelo que é publicamente acessível e, sujeito à sua licença, pode ser empregado para empreendimentos comerciais. Além disso, dependendo dos termos da licença, pode ser ajustado, bifurcado ou modificado conforme necessário. Normalmente, para integração de plataforma ou fins de ajuste fino, optar por um modelo de código aberto é aconselhável.
Além disso, alavancar tecnologias de código aberto é propício para avançar o campo dos LLMs, pois fomenta incentivos para aprimoramento e customização de modelos, beneficiando toda a comunidade.
Licenças comerciais
Um modelo que possua uma licença comercial é adequado para fins comerciais, permitindo sua integração em plataformas comerciais.

Visão geral dos LLMs e suas licenças.
Conclusão
Selecionar um LLM que se alinhe com seus requisitos pode parecer esmagador, mas você pode simplificar seu processo de avaliação comparando características-chave com suas necessidades. Estas incluem tamanho, tipo, benchmarks de qualidade, metodologias de treinamento, vieses e licenciamento. Embora esta lista sirva como ponto de partida, há inúmeros outros fatores a considerar. No entanto, este artigo visa fornecer a você o conhecimento necessário para avaliar um modelo de IA recém-lançado, permitindo determinar sua potencial adequação aos seus requisitos e decidir se uma investigação mais aprofundada é justificada.
novita.ai, a plataforma única para criatividade ilimitada que oferece acesso a mais de 100 APIs. Desde geração de imagens e processamento de linguagem até aprimoramento de áudio e manipulação de vídeo, com pagamento por uso acessível, ela libera você das dores de manutenção de GPU enquanto constrói seus próprios produtos. Experimente gratuitamente.
Leitura recomendada
Novita AI LLM Inference Engine: a maior taxa de transferência e inferência mais barata disponível



