

Introduction
With the multitude of Large Language Models (LLMs) available, pinpointing one that aligns with your specific requirements can seem overwhelming. The landscape is constantly evolving, with new models and refined versions emerging almost weekly. Consequently, any attempt to catalog LLMs and their attributes is bound to swiftly become outdated.
Instead of attempting to delineate each top LLM and delineate their strengths and weaknesses, this article aims to provide a set of criteria for evaluating models. By offering a framework for analysis, readers can assess newly released models against core characteristics and compare them effectively. The primary attributes to consider when evaluating an LLM include:
- size
- architecture type
- benchmark performance
- training processes and biases
- licensing/availability
What is the size of an LLM?
Your primary consideration when selecting an LLM is your budgetary constraint. Operating LLMs can incur substantial costs, underscoring the importance of opting for a model that remains within budgetary bounds. One indicative factor of cost is the number of parameters within an LLM.
What is the number of parameters of a model?
The quantity of parameters corresponds to the count of weights and biases adjusted by the model during training and utilized in computing its output. Why is this quantity significant? It offers a rough approximation of the performance overhead and inference speed of a model. Broadly speaking, these factors are directly related: as the number of parameters increases, so does the cost associated with generating an output.
What is the inference speed of a model?
The inference speed of a language model refers to the duration it takes to process an input, essentially measuring its output speed. It’s important to acknowledge that the inference speed and overall performance of a model are intricate and multifaceted, not solely determined by the number of parameters. However, for the context of this article, parameter count provides a rough estimate of a model’s potential performance. Fortunately, there exist several established methods for mitigating the inference time of machine learning models.

Number of parameters for each LLM.
A medium-sized model typically contains fewer than 10 billion parameters, while more affordable ones may have fewer than 1 billion. However, models with fewer than 1 billion parameters are often older or not specifically tailored for text generation tasks. On the other end of the spectrum, expensive models boast over 100 billion parameters, exemplified by GPT-4 with a staggering 1.76 trillion parameters. Many model series, including LLaMa 2, Mistral, Falcon, and GPT, offer both smaller versions, with fewer than 10 billion parameters, and larger versions ranging from 10 to 100 billion parameters.
What are the different types of LLMs?
In broad terms, transformer-based LLMs can be categorized into three groups based on their architecture: encoder-only, encoder-decoder, and decoder-only. This categorization aids in understanding the intended purpose of the model and its performance in text generation tasks.
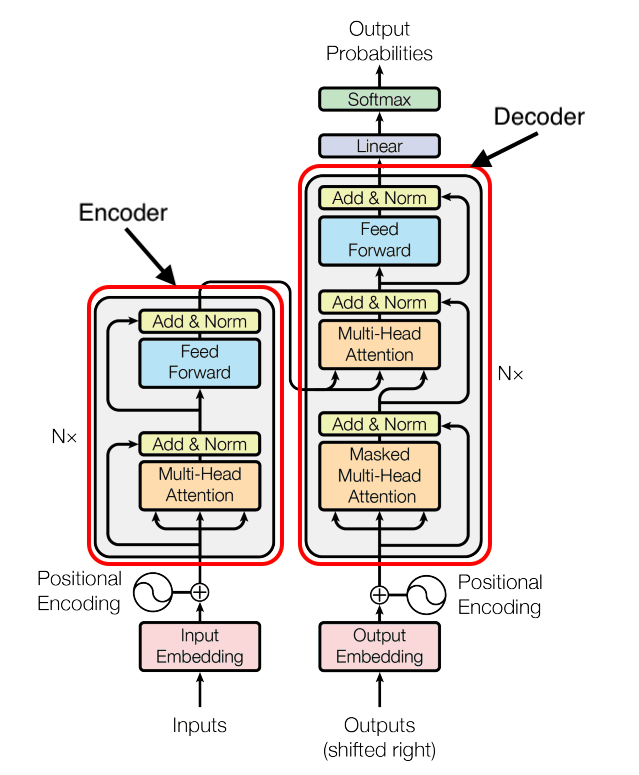
What is an encoder-only model?
Encoder-only models solely utilize an encoder component, tasked with encoding and categorizing input text. These models prove beneficial for assigning text to specific categories. BERT, the predominant encoder-only model, underwent training as a masked language model (MLM) and for next sentence prediction (NSP). Both of these training objectives entail discerning essential elements within a sentence.
What is an encoder-decoder model?
Encoder-decoder models initially encode the input text, similar to encoder-only models, before proceeding to generate or decode a response based on the encoded inputs. An example of an encoder-decoder model architecture is BART. These models are versatile, suitable for both text generation and comprehension tasks, making them particularly valuable for translation purposes. BART, for instance, excels in summarizing lengthy texts, such as articles, into coherent outputs. For instance, BART-Large-CNN is a fine-tuned variant specialized in generating summaries of text, having been trained on a diverse range of news articles. Overall, encoder-decoder models serve a dual purpose, catering to both text comprehension and generation tasks.
What is a decoder-only model?
Decoder-only models specialize in generating the next word or token based on a given prompt, exclusively focusing on text generation tasks. They offer simplicity in training and are particularly efficient for pure text generation purposes. Model series like GPT, Mistral, and LLaMa fall into the decoder-only category. If your primary requirement revolves around text generation, decoder-only models are the preferred choice.
However, it’s worth noting that Mistral’s 8x7B (also known as Mixtral) employs a unique architecture termed “mixtral of experts,” which sets it apart from conventional decoder-only models. Similarly, there are indications that GPT-4 may utilize a similar technique. Hence, these models may not neatly fit into the decoder-only category. Additionally, emerging architectural techniques like retrieval-augmented generation (RAG) defy classification within these established categories.
You can get deeper in our blog for RAG tech: What is RAG: A Comprehensive Introduction to Retrieval Augmented Generation

How to measure the performance quality of an LLM
Various metrics are employed to assess a language model’s capacity to comprehend, interpret, and provide accurate responses to diverse prompts. These evaluation methods differ depending on the intended usage of the language model. For instance, BERT, an encoder-only model primarily designed for tasks like classification, isn’t evaluated using the same criteria as GPT-3, a decoder-only model tailored for text generation. In the following sections, we will elucidate some of the methodologies used to evaluate text generation LLMs.
Measuring the quality of an LLM using academic exams
One prevalent method for assessing the effectiveness of a generative language model involves subjecting it to examinations. For example, GPT-4 underwent evaluation against GPT-3.5 across a range of academic tests. Through this process, the model’s performance is compared against both human scores and those of previous models, providing insights into its reasoning capabilities within an academic context. Presented below is a brief compilation of some of the examinations administered to GPT-4, along with its comparative scores against GPT-3.5 and the average human performance:

Performance of GPT-4 and GPT-3.5 on standardized exams compared to the human average.
Another performance metric akin to academic examinations involves presenting the model with diverse Question and Answer (QnA) datasets. This approach is utilized in the Hugging Face Open LLM Leaderboard, offering a valuable resource for comparing different LLMs based on their performance on QnA datasets. These datasets provide a straightforward means of benchmarking an LLM, allowing for the assessment of its overall intelligence and logical capabilities.
Quality comparison table between LLMs
It’s essential to note that comparing a 0-shot score to a 25-shot score yields little value. Ideally, for quality comparisons, you should maintain consistency in the type of prompting used. Even when comparing two data points with the same prompting method, differences in testing procedures may still lead to inaccuracies. Nevertheless, the following should provide a rough comparison of quality:

A quality comparison table between LLMs across ARC, MMLU, and WinoGrande tests using few-shot and zero-shot prompting.
What is the best current LLM to use as a chatbot?
Examining this table, while considering the disclaimers mentioned earlier, it’s evident that GPT-4 stands out as the top-performing LLM in terms of overall quality. However, for optimal value, the Mistral models offer the best choice. Particularly, the 8x7B Mistral version employs a unique technique that amalgamates multiple Mistral 7b models, resulting in higher-quality outputs. This approach creates a highly efficient model that also excels in benchmark assessments.
How training data can affect LLMs
The selection of training datasets for a model raises significant considerations. What type of data was utilized? Is the dataset specifically tailored for particular applications? Are there any inherent biases within the dataset that might impact the model?
How model biases emerge, taking BERT as an example
For most LLMs, the training data is typically extensive, aiming to provide the model with a foundational understanding of language. BERT, for example, underwent pre-training using Wikipedia (2,500M words) and BookCorpus (800M words). However, in some cases, such as with Mistral’s models, the training dataset remains unavailable to the public.
Examining these datasets can offer insights into potential biases inherent in the model. Consider BERT, which heavily relies on the English Wikipedia dataset for training. While Wikipedia is often considered a neutral and unbiased source, this may not always hold true. For instance, The Guardian reported that only 16% of Wikipedia editors are female, and merely 17% of articles about notable people are about women. Additionally, content about sub-Saharan Africa is primarily authored by individuals outside the region. Given BERT’s reliance on English Wikipedia, it’s plausible that biases present in the platform could be inherited by the model. Indeed, evidence suggests that BERT exhibits gender and racial biases in its outputs. In summary, biases within the training datasets of pre-trained models can influence their text generation capabilities. Therefore, it’s essential to consider such biases as they impact the end-user experience.
What is a fine-tuned model?
Fine-tuning involves retraining an already trained model on new data, often leading to the creation of specialized offshoot models tailored for specific purposes. The choice of data used for fine-tuning is crucial when assessing the potential applications of a model. For example, FinBERT, an offshoot of BERT, has been fine-tuned on a substantial financial language dataset, making it particularly useful for analyzing the financial sentiment of text. If you want to know more about fine-tuning, read our article: How to Fine-Tune Large Language Models?
While some models are designed with the intention of enabling further fine-tuning, others are already fine-tuned to fulfill specific objectives. For instance, models like Falcon may have associated chat versions refined to function effectively as chatbots. Various methods are employed for fine-tuning models, although the details of these techniques fall beyond the scope of this article. In general, a fine-tuned model typically provides information about its intended purposes and the specific fine-tuning techniques applied.
What dataset does each language model use?
Given the significant impact of training data on a model’s performance, developers have devised various web scraping methods to acquire high-quality datasets. For instance, OpenAI’s Webtext tool scrapes “all outbound links from Reddit that received at least 3 karma.” Below is a compilation of datasets utilized by some of the most notable models to date, bearing in mind that many developers do not disclose the datasets they employ.

Datasets that the most popular LLMs were trained on.
The licensing and availability of LLMs
For commercial utilization of LLMs, it’s imperative to assess the licensing terms associated with a specific model. Moreover, availability can be nuanced: certain models are closed-source, necessitating access solely through their API.
What is a closed source language model?
A closed-source model implies that its source code is not publicly accessible. Models like GPT-3 and GPT-4 fall into this category, typically accessible only through an API. However, while API integration can be straightforward, it also entails expenses. Generally, for platform integration, depending on the scale, it’s more cost-effective to utilize an open-source language model and train or deploy it using a platform like UbiOps.

novita.ai LLM API
What is an open source LLM?
An open-source LLM refers to a model that is publicly accessible and, subject to its license, can be employed for commercial endeavors. Additionally, depending on the license terms, it can be fine-tuned, forked, or modified as needed. Typically, for platform integration or fine-tuning purposes, opting for an open-source model is advisable.
Moreover, leveraging open-source technologies is conducive to advancing the LLM field, as it fosters incentives for enhancement and customization of models, ultimately benefiting the entire community.
Commercial licenses
A model possessing a commercial license is suitable for business purposes, enabling its integration into commercial platforms.

Overview of LLMs and their licenses.
Conclusion
Selecting an LLM that aligns with your requirements may seem overwhelming, but you can streamline your evaluation process by comparing key characteristics against your needs. These include size, type, quality benchmarks, training methodologies, biases, and licensing. While this list serves as a starting point, there are numerous other factors to consider. Nonetheless, this article aims to furnish you with the knowledge needed to assess a newly released AI model, enabling you to determine its potential suitability for your requirements and decide whether further investigation is warranted.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available



