

はじめに
数多くの大規模言語モデル(LLM)が利用可能な中、自社の特定要件に合致するモデルを見極めるのは困難に思えるかもしれません。状況は絶えず変化しており、ほぼ毎週のように新たなモデルや改良版が登場しています。そのため、LLMとその属性を列挙しようとする試みはすぐに時代遅れになる運命にあります。
本記事では、各トップLLMの長所と短所を詳細に説明する代わりに、モデルを評価するための一連の基準を提供することを目的としています。分析の枠組みを提供することで、読者は新しくリリースされたモデルを核となる特性に基づいて評価し、効果的に比較することができます。LLMを評価する際に考慮すべき主な属性は以下の通りです:
- サイズ
- アーキテクチャの種類
- ベンチマーク性能
- トレーニングプロセスとバイアス
- ライセンス/利用可能性
LLMのサイズとは?
LLMを選択する際の主な考慮事項は予算の制約です。LLMの運用には多大なコストがかかる可能性があり、予算範囲内に収まるモデルを選ぶことの重要性が強調されます。コストを示す指標の1つは、LLM内のパラメーター数です。
モデルのパラメーター数とは?
パラメーターの数は、モデルがトレーニング中に調整され、出力の計算に使用される重みとバイアスの数に相当します。なぜこの数が重要なのでしょうか?それは、モデルのパフォーマンスのオーバーヘッドと推論速度の大まかな見積もりを提供するからです。一般的に、これらの要素は直接関連しています。パラメーター数が増加すると、出力を生成するためのコストも増加します。
モデルの推論速度とは?
言語モデルの推論速度とは、入力の処理にかかる時間を指し、実質的に出力速度を測定します。推論速度とモデルの全体的なパフォーマンスは複雑で多面的であり、パラメーター数だけで決まるわけではないことを認識することが重要です。ただし、この記事の文脈では、パラメーター数はモデルの潜在的なパフォーマンスの大まかな推定値を提供します。幸い、機械学習モデルの推論時間を短縮するための確立された方法がいくつか存在します。

各LLMのパラメーター数。
中規模モデルは通常、100億未満のパラメーターを持ち、より手頃なモデルは10億未満の場合もあります。ただし、10億未満のパラメーターを持つモデルは、多くの場合、古いか、テキスト生成タスクに特化して調整されていません。一方、高価なモデルは1000億を超えるパラメーターを持ち、GPT-4は驚異の1.76兆パラメーターを誇ります。LLaMa 2、Mistral、Falcon、GPTなどの多くのモデルシリーズは、100億未満のパラメーターを持つ小型バージョンと、100億から1000億のパラメーターを持つ大型バージョンの両方を提供しています。
LLMの種類は何ですか?
大まかに言えば、トランスフォーマーベースのLLMは、そのアーキテクチャに基づいてエンコーダーのみ、エンコーダー-デコーダー、デコーダーのみの3つのグループに分類できます。この分類は、モデルの意図された目的とテキスト生成タスクにおけるパフォーマンスを理解するのに役立ちます。
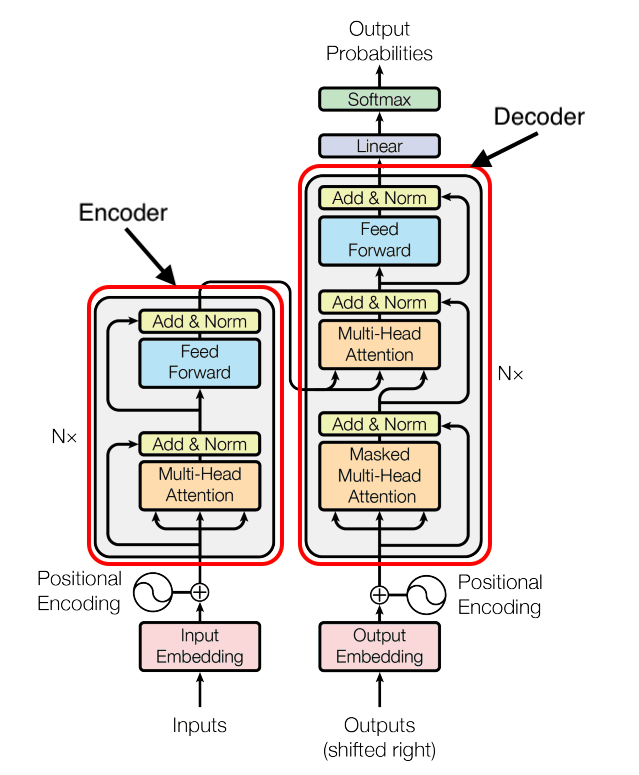
エンコーダーのみのモデルとは?
エンコーダーのみのモデルは、入力テキストをエンコードして分類するタスクを担当するエンコーダーコンポーネントのみを使用します。これらのモデルは、テキストを特定のカテゴリに割り当てるのに役立ちます。主要なエンコーダーのみのモデルであるBERTは、マスク言語モデル(MLM)および次文予測(NSP)としてトレーニングされました。これらのトレーニング目標はどちらも、文中の重要な要素を識別することを伴います。
エンコーダー-デコーダーモデルとは?
エンコーダー-デコーダーモデルは、最初にエンコーダーのみのモデルと同様に入力テキストをエンコードし、その後、エンコードされた入力に基づいて応答を生成またはデコードします。エンコーダー-デコーダーモデルアーキテクチャの例はBARTです。これらのモデルは多用途であり、テキスト生成と理解タスクの両方に適しており、特に翻訳目的で価値があります。例えば、BARTは長いテキスト(記事など)を一貫した出力に要約することに優れています。たとえば、BART-Large-CNNは、さまざまなニュース記事でトレーニングされた、テキストの要約を生成することに特化したファインチューニングバリアントです。全体として、エンコーダー-デコーダーモデルは、テキスト理解と生成タスクの両方に対応する二重の目的を果たします。
デコーダーのみのモデルとは?
デコーダーのみのモデルは、与えられたプロンプトに基づいて次の単語またはトークンを生成することに特化しており、テキスト生成タスクにのみ焦点を当てています。トレーニングがシンプルで、純粋なテキスト生成の目的に特に効率的です。GPT、Mistral、LLaMaなどのモデルシリーズは、デコーダーのみのカテゴリに分類されます。主な要件がテキスト生成である場合、デコーダーのみのモデルが推奨される選択肢です。
ただし、Mistralの8x7B(Mixtralとも呼ばれる)は、「エキスパートの混合」と呼ばれる独自のアーキテクチャを採用しており、従来のデコーダーのみのモデルとは一線を画しています。同様に、GPT-4も同様の手法を採用している可能性があります。したがって、これらのモデルはデコーダーのみのカテゴリにきれいに当てはまらない可能性があります。さらに、検索拡張生成(RAG)などの新しいアーキテクチャ手法は、これらの確立されたカテゴリ内での分類を無視します。
RAG技術については、ブログで詳しく知ることができます:RAGとは何か:検索拡張生成の包括的な入門

LLMのパフォーマンス品質を測定する方法
さまざまな指標が、言語モデルが多様なプロンプトを理解、解釈、正確に応答する能力を評価するために使用されます。これらの評価方法は、言語モデルの意図された用途によって異なります。たとえば、分類などのタスク向けに設計されたエンコーダーのみのモデルであるBERTは、テキスト生成向けに調整されたデコーダーのみのモデルであるGPT-3と同じ基準で評価されません。以下のセクションでは、テキスト生成LLMの評価に使用される方法論のいくつかを説明します。
学術試験を使用したLLMの品質測定
生成言語モデルの有効性を評価する一般的な方法の1つは、試験を受けさせることです。たとえば、GPT-4は、さまざまな学術テストでGPT-3.5と比較評価されました。このプロセスを通じて、モデルのパフォーマンスは人間のスコアおよび以前のモデルのスコアと比較され、学術的コンテキストにおける推論能力についての洞察が得られます。以下は、GPT-4に実施された試験の一部と、GPT-3.5および平均的な人間のパフォーマンスとの比較スコアの簡単なリストです。

標準化試験におけるGPT-4とGPT-3.5のパフォーマンス(人間の平均と比較)。
学術試験に似た別のパフォーマンス指標は、モデルにさまざまな質問応答(QnA)データセットを提示することです。このアプローチは、Hugging Face Open LLM Leaderboardで使用されており、QnAデータセットでのパフォーマンスに基づいてさまざまなLLMを比較するための貴重なリソースを提供します。これらのデータセットは、LLMの全体的な知性と論理能力を評価できるようにし、LLMのベンチマークを簡単に行う手段を提供します。
LLM間の品質比較表
0ショットスコアを25ショットスコアと比較しても、ほとんど意味がないことに注意することが重要です。品質比較には、理想的には使用するプロンプトの種類を一貫させることが望まれます。同じプロンプト方法で2つのデータポイントを比較した場合でも、テスト手順の違いが不正確さを生む可能性があります。それでも、以下の表は品質の大まかな比較を提供します。

Few-shotおよびZero-shotプロンプティングを使用したARC、MMLU、WinoGrandeテストにおけるLLM間の品質比較表。
チャットボットとして現在最良のLLMはどれですか?
この表を、前述の注意事項を考慮して見ると、GPT-4が全体的な品質でトップのLLMであることは明らかです。ただし、最適な価値を求めるなら、Mistralモデルが最良の選択肢を提供します。特に、8x7B Mistralバージョンは、複数のMistral 7bモデルを融合する独自の手法を採用しており、より高品質な出力を実現しています。このアプローチは、ベンチマーク評価でも優れた性能を発揮する非常に効率的なモデルを生み出します。
トレーニングデータがLLMに与える影響
モデルのトレーニングデータセットの選択は、重要な考慮事項を引き起こします。どのような種類のデータが使用されたのか?データセットは特定のアプリケーション向けに調整されているのか?データセット内にモデルに影響を与える可能性のある固有のバイアスはあるのか?
モデルのバイアスはどのように発生するか、BERTを例に
ほとんどのLLMでは、トレーニングデータは通常広範囲にわたり、モデルに言語の基本的な理解を提供することを目的としています。たとえば、BERTはWikipedia(2500万語)およびBookCorpus(800万語)を使用して事前トレーニングされました。ただし、Mistralのモデルのように、トレーニングデータセットが一般に公開されていない場合もあります。
これらのデータセットを調べることで、モデルに内在する潜在的なバイアスについての洞察が得られます。BERTはトレーニングに英語のWikipediaデータセットに大きく依存しています。Wikipediaは中立的で偏りのない情報源と考えられることが多いですが、これは常に当てはまるとは限りません。たとえば、The Guardianは、Wikipedia編集者のわずか16%が女性であり、著名人に関する記事のわずか17%が女性についてであると報じています。さらに、サハラ以南のアフリカに関するコンテンツは、主に地域外の個人によって執筆されています。BERTが英語のWikipediaに依存していることを考えると、そのプラットフォームに存在するバイアスがモデルに継承される可能性があります。実際、BERTがその出力に性別や人種的なバイアスを示すという証拠があります。要約すると、事前トレーニングされたモデルのトレーニングデータセット内のバイアスは、そのテキスト生成能力に影響を与える可能性があります。したがって、そのようなバイアスはエンドユーザー体験に影響を与えるため、考慮することが不可欠です。
ファインチューニングされたモデルとは?
ファインチューニングとは、すでにトレーニングされたモデルを新しいデータで再トレーニングすることを含み、多くの場合、特定の目的に特化した派生モデルの作成につながります。ファインチューニングに使用されるデータの選択は、モデルの潜在的なアプリケーションを評価する際に重要です。たとえば、BERTの派生モデルであるFinBERTは、大規模な金融言語データセットでファインチューニングされており、テキストの金融センチメントを分析するのに特に役立ちます。ファインチューニングについて詳しく知りたい場合は、記事をお読みください:大規模言語モデルのファインチューニング方法は?
一部のモデルはさらなるファインチューニングを可能にすることを意図して設計されていますが、他のモデルは特定の目的を達成するためにすでにファインチューニングされています。たとえば、Falconのようなモデルには、チャットボットとして効果的に機能するように調整されたチャットバージョンが関連付けられている場合があります。モデルのファインチューニングにはさまざまな方法が使用されますが、これらの手法の詳細はこの記事の範囲外です。一般的に、ファインチューニングされたモデルは、その意図された目的と適用された特定のファインチューニング手法に関する情報を提供します。
各言語モデルはどのデータセットを使用していますか?
トレーニングデータがモデルのパフォーマンスに与える影響が大きいため、開発者は高品質なデータセットを取得するためにさまざまなWebスクレイピング方法を開発してきました。たとえば、OpenAIのWebtextツールは、「少なくとも3カルマを受け取ったRedditからのすべての外部リンク」をスクレイピングします。以下は、これまでで最も注目すべきモデルの一部で使用されているデータセットのリストです。ただし、多くの開発者は使用するデータセットを開示していないことに留意してください。

最も人気のあるLLMがトレーニングされたデータセット。
LLMのライセンスと利用可能性
LLMを商業的に利用するには、特定のモデルに関連するライセンス条件を評価することが不可欠です。さらに、利用可能性は微妙です。一部のモデルはクローズドソースであり、APIを介してのみアクセスする必要があります。
クローズドソース言語モデルとは?
クローズドソースモデルとは、そのソースコードが公開されていないことを意味します。GPT-3やGPT-4などのモデルはこのカテゴリに分類され、通常はAPIを介してのみアクセスできます。ただし、API統合は簡単ですが、費用もかかります。一般的に、プラットフォーム統合では、規模に応じて、オープンソース言語モデルを使用し、それをUbiOpsのようなプラットフォームを使用してトレーニングまたはデプロイする方がコスト効率が高くなります。

novita.ai LLM API
オープンソースLLMとは?
オープンソースLLMとは、公開されており、そのライセンスに従い、商業的な取り組みに使用できるモデルを指します。また、ライセンス条件に応じて、必要に応じてファインチューニング、フォーク、または変更することもできます。通常、プラットフォーム統合やファインチューニングの目的では、オープンソースモデルを選択することをお勧めします。
さらに、オープンソース技術を活用することは、LLM分野の進歩に貢献します。なぜなら、モデルの改善とカスタマイズへのインセンティブを促進し、最終的にコミュニティ全体に利益をもたらすからです。
商用ライセンス
商用ライセンスを持つモデルはビジネス目的に適しており、商用プラットフォームへの統合が可能です。

LLMとそのライセンスの概要。
結論
要件に合致するLLMを選択するのは困難に思えるかもしれませんが、主要な特性をニーズと比較することで評価プロセスを合理化できます。これらの特性には、サイズ、種類、品質ベンチマーク、トレーニング方法論、バイアス、ライセンスが含まれます。このリストは出発点として役立ちますが、考慮すべき他の多くの要因があります。それでも、この記事は、新しくリリースされたAIモデルを評価するために必要な知識を提供し、それが要件に適合する可能性があるかどうかを判断し、さらに調査する価値があるかどうかを決定できるようにすることを目的としています。
novita.aiは、無限の創造性のためのワンストッププラットフォームであり、100以上のAPIにアクセスできます。画像生成や言語処理から音声強調や動画操作まで、従量課金制で手頃な価格を実現し、GPUメンテナンスの手間から解放されながら自社製品を構築できます。今すぐ無料でお試しください。
おすすめの記事



