

Dans ce guide, nous vous présenterons quatre méthodes pratiques pour accéder à GLM-4.7 — d’une interface web pour des tests rapides, au déploiement local pour des contraintes strictes de résidence des données. Nous mettrons particulièrement l’accent sur l’accès API via Novita AI, où GLM-4.7 est disponible sous le nom zai-org/glm-4.7 via un point de terminaison serverless — vous pourrez donc passer d’une idée à une intégration fonctionnelle en quelques minutes, sans avoir à gérer d’infrastructure d’inférence.
À la fin de ce guide, vous saurez exactement quelle option d’accès correspond à votre charge de travail, et vous disposerez d’une configuration API étape par étape que vous pourrez copier dans votre application pour commencer à développer avec GLM-4.7 immédiatement.
GLM-4.7 vs GLM-4.6 : Principales améliorations en un coup d’œil
GLM-4.7 conserve les mêmes limites de contexte principales que GLM-4.6 — fenêtre de contexte de 200K et sortie allant jusqu’à 128K, mais les plus grands gains de GLM-4.7 se manifestent là où les applications de production en ont le plus besoin : flux de travail agentiques utilisant des outils et exécution de code de bout en bout. Vous pouvez essayer GLM-4.7 rapidement via Novita.
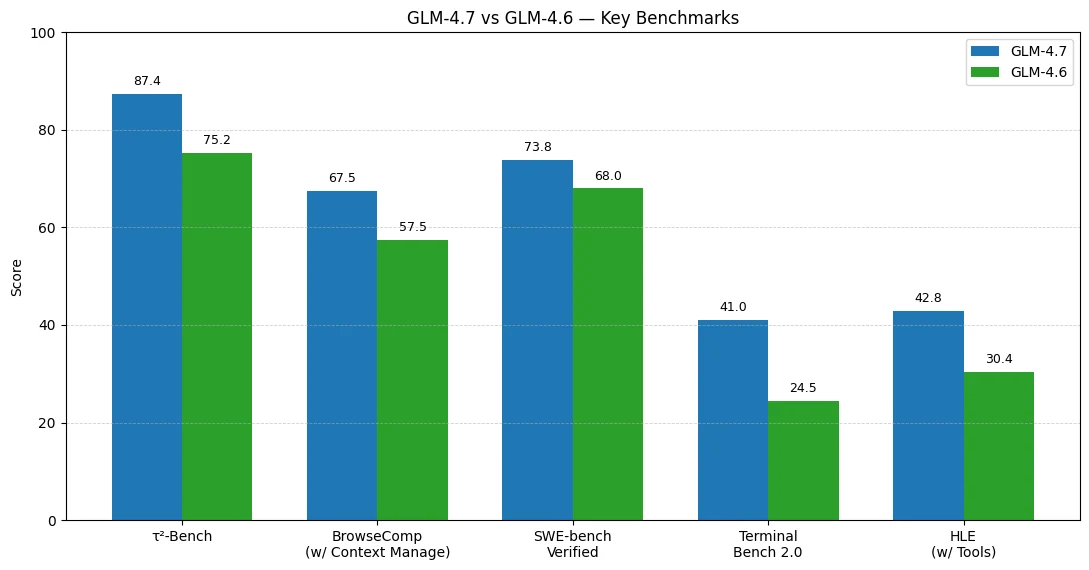
Les résultats des benchmarks suggèrent que les plus grands gains de GLM-4.7 par rapport à GLM-4.6 se manifestent dans les flux de travail agentiques utilisant des outils et l’exécution de code de bout en bout.
L’utilisation d’outils et les flux de travail agentiques s’améliorent le plus
- τ²-Bench : 75,2 → 87,4 (+12,2)
- BrowseComp (avec gestion du contexte) : 57,5 → 67,5 (+10,0)
Le codage dans des cas concrets devient plus fiable
- SWE-bench Verified : 68,0 → 73,8 (+5,8)
Les agents de codage de type terminal connaissent une progression majeure
- Terminal Bench 2.0 : 24,5 → 41,0 (+16,5)
Le raisonnement complexe avec outils est nettement plus performant
- HLE (avec outils) : 30,4 → 42,8 (+12,4)
Que pouvez-vous faire avec GLM-4.7 ?
Voici des cas d’usage à fort potentiel qui correspondent aux points forts de GLM-4.7 :
-
Assistants de codage agentiques
- Boucles « Planifier → Implémenter → Tester → Corriger »
- Refactorisations multi-fichiers, tâches de type terminal et sessions de programmation plus longues
-
Agents utilisant des outils (recherche + navigation + sorties structurées)
- Agents de recherche qui collectent des sources, comparent des résultats et renvoient des résumés structurés
-
Génération de front-end avec une esthétique plus soignée
- Pages d’atterrissage, composants UI, génération de mises en page cohérentes avec le design
-
Automatisation des tâches bureautiques (plans PPT, affiches, rédaction soignée)
- Mise en forme et cohérence de la mise en page plus fiables, des brouillons « prêts à l’emploi » de meilleure qualité
Premiers pas avec GLM-4.7 : Vos options d’accès
Vous disposez généralement de quatre options pratiques :
Essayez-le d’abord : Terrain de jeu web Novita (Le plus simple pour les débutants)
Si vous souhaitez tester rapidement des prompts et voir comment se comporte GLM-4.7, Novita propose une expérience web en un clic.
Développez avec des API : Point de terminaison officiel vs Novita AI Serverless (Pour les développeurs)
Idéal pour : applications en production, startups optimisant leurs coûts, équipes souhaitant une API unifiée pour de nombreux modèles.
Si vous souhaitez bénéficier d’une scalabilité serverless, d’appels compatibles OpenAI et d’une facturation à l’usage, GLM-4.7 est disponible sur Novita AI sous le nom zai-org/glm-4.7.
💡Points forts de Novita AI :
- Serverless : exécution immédiate, vous ne payez que ce que vous utilisez
- Tarification : 0,6 $ / M de tokens d’entrée, 2,2 $ / M de tokens de sortie
- Contexte long + sortie volumineuse : contexte de 204 800, sortie maximale de 131 072
- Appel de fonctions + sortie structurée + raisonnement pris en charge
Étape par étape : Utilisez GLM-4.7 via API avec Novita AI
Intégrez GLM-4.7 dans vos applications en utilisant l’API REST unifiée compatible OpenAI de Novita AI.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Rendez-vous sur https://novita.ai/ : connectez-vous (ou inscrivez-vous) sur votre compte Novita AI et accédez à la bibliothèque de modèles.
Étape 2 : Choisissez GLM-4.7
Parcourez les modèles disponibles et sélectionnez GLM-4.7 en fonction des exigences de votre charge de travail.
Étape 3 : Démarrez votre essai gratuit
Activez votre essai gratuit pour explorer les capacités de raisonnement, de contexte long et de rapport qualité-prix de GLM-4.7.
Étape 4 : Récupérez votre clé API
Ouvrez la page des paramètres pour générer et copier votre clé API pour l’authentification.
Étape 5 : Installez et appelez l’API (Exemple Python)
Vous trouverez ci-dessous un exemple simple utilisant l’API de complétion de chat avec Python :
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Cette configuration vous permet de contrôler la profondeur de raisonnement, l’utilisation de tokens et le comportement de génération — particulièrement utile lorsque vous exploitez la réflexion au niveau des tours de parole pour gérer les coûts et la latence.
Exécutez-le sur votre propre pile : Serveur local pour les utilisateurs avancés (Utilisateurs expérimentés)
Idéal pour : charges de travail hors ligne, contraintes de résidence des données, piles d’inférence personnalisées.
GLM-4.7 est open source sous licence MIT sur Hugging Face, et la fiche modèle officielle inclut des conseils pour l’exécution locale (vLLM, SGLang, transformers) ainsi que des notes sur la compatibilité des frameworks.
Exigences GPU / VRAM (référence rapide)
Lors de l’exécution locale de GLM-4.7, la VRAM est la contrainte principale. La mémoire GPU requise dépend principalement de la largeur de bit de quantification (quantification à plus faible bit → VRAM plus faible), plus une petite marge pour les frais généraux d’exécution.
Vous trouverez ci-dessous une référence pratique (taille du modèle + exigence de VRAM estimée + configurations GPU suggérées) :
| Largeur de bit | Quantification | Taille du modèle | VRAM requise estimée | GPU recommandé | VRAM totale |
|---|---|---|---|---|---|
| 1-bit | TQ1_0 | 84,5 Go | ~86 Go | NVIDIA L4 ×4 | 96 Go |
| 1-bit | IQ1_S | 97,2 Go | ~99 Go | NVIDIA A100 ×2 | 160 Go |
| 1-bit | IQ1_M | 108 Go | ~110 Go | — | — |
| 3-bit | Q3_K_XL | 159 Go | ~161 Go | NVIDIA L40S ×4 | 192 Go |
| 3-bit | Q3_K_M | 171 Go | ~173 Go | NVIDIA L40S ×4 | 192 Go |
| 4-bit | IQ4_XS | 192 Go | ~194 Go | NVIDIA A100 ×4 | 320 Go |
| 8-bit | Q8_0 | 381 Go | ~383 Go | NVIDIA A100 ×8 | 640 Go |
| 16-bit | BF16 | 717 Go | ~719 Go | NVIDIA H200 ×8 | 1128 Go |
Règle générale : prévoyez légèrement plus de VRAM que le chiffre d’« exigence mémoire » (frais généraux du framework/runtime, croissance du cache KV, traitement par lots, etc.). Pour la plupart des configurations d’exécution locale destinées aux utilisateurs expérimentés, la quantification à 3-4 bits est le point de départ le plus pratique, tandis que les quantification 8/16 bits nécessitent généralement des serveurs multi-GPU.
Intégrez-le : Agents IDE, appel d’outils et frameworks d’applications
Idéal pour : « apportez votre propre agent IDE », systèmes multi-agents, applications appelant des outils.
GLM-4.7 est explicitement décrit comme fonctionnant bien dans les environnements d’agents de codage populaires (par exemple, les flux de travail de type Claude Code).
Sur Novita AI, vous pouvez intégrer GLM-4.7 dans des outils existants qui utilisent déjà des API compatibles OpenAI (et la page de modèle de Novita indique également la compatibilité avec l’API Anthropic sur la plateforme).
Si vous utilisez une configuration de codage agentique, GLM-4.7 peut servir de modèle sous-jacent aux assistants IDE et agents de codage populaires :
- Claude Code : Flux de travail de codage agentique avancés avec un fort raisonnement multi-étapes
- Qwen Code : Outil de codage IA spécialisé optimisé pour les tâches de développement
- Cline (VS Code) : Assistant IA intégré directement à VS Code pour le codage itératif et l’exécution d’outils
- Cursor IDE : Un IDE moderne offrant une expérience de codage alimentée par l’IA fluide
- Trae : Assistant de développement IA basé sur le terminal pour les flux de travail orientés commandes
- Codex CLI : Assistance IA en ligne de commande pour la planification, les modifications et l’automatisation rapide
- Kilo : Agent/assistant de codage IA léger pour des modifications rapides, des refactorisations et des questions/réponses sur des bases de code dans tous les projets
- OpenCode : Assistant/agent de codage open source, prioritairement local, qui prend en charge des flux de travail personnalisables et des intégrations d’outils
Comment utiliser GLM-4.7 dans ces flux de travail :
- Définissez l’URL du fournisseur/point de terminaison sur le point de terminaison compatible OpenAI de Novita
- Choisissez le modèle :
zai-org/glm-4.7
Chemin le plus rapide : Essayez GLM-4.7 sur Novita AI
Si votre objectif est de « faire fonctionner GLM-4.7 dès aujourd’hui » sans gérer d’infrastructure, l’accès serverless de Novita AI est généralement la voie la plus directe — surtout si vous comparez des modèles, optimisez vos dépenses ou livrez rapidement.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle vos projets.
Questions fréquemment posées
GLM-4.7 est-il gratuit ?
Sur Novita AI, GLM-4.7 est payant à l’usage : 0,6 $ par million de tokens (entrée), 0,11 $ par million de tokens (lecture de cache) et 2,2 $ par million de tokens (sortie). Sur Z.ai, l’accès est généralement proposé dans le cadre d’un abonnement Coding Plan payant (à partir de 3 $ par mois). Certaines plateformes peuvent proposer des essais ou des quotas limités, mais GLM-4.7 lui-même n’est pas universellement « gratuit ».
GLM-4.7 est-il vraiment performant ?
Pour les tâches de codage et les flux de travail agentiques, il est positionné comme un modèle open source de premier plan par son éditeur. Z.ai rapporte des résultats solides sur les benchmarks de codage et d’agents (par exemple LiveCodeBench v6, SWE-bench Verified, BrowseComp, τ²-Bench), et le présente comme concurrentiel avec Claude Sonnet 4.5 sur plusieurs mesures.
GLM-4.7 prend-il en charge la vision ?
GLM-4.7 est exclusivement textuel. Si vous avez besoin de la vision, utilisez plutôt une variante GLM-V (par exemple GLM-4.6V ou GLM-4.5V, qui prennent en charge les entrées image selon le fournisseur).



