

このガイドでは、GLM-4.7にアクセスする4つの実用的な方法を紹介します。すばやくテストするためのウェブインターフェースから、厳格なデータ保存要件に対応するローカルデプロイまで。特に、Novita AIを介したAPIアクセスに焦点を当てます。GLM-4.7はサーバーレスエンドポイント経由でzai-org/glm-4.7として利用可能です。推論インフラを管理することなく、アイデアから実際の統合まで数分で完了できます。
これを読めば、どのアクセス方法が自分のワークロードに適しているかがわかり、すぐにGLM-4.7を使った開発を始めるためのステップバイステップのAPI設定をアプリケーションにコピーできるようになります。
GLM-4.7 vs GLM-4.6:主なアップグレードポイント
GLM-4.7はGLM-4.6と同じ200Kコンテキストウィンドウ、最大128K出力を備えていますが、GLM-4.7の最大の進歩はプロダクションアプリケーションで最も重要となるエージェント的・ツール使用ワークフローとエンドツーエンドのコーディング実行に現れています。NovitaからGLM-4.7をすぐにお試しいただけます。
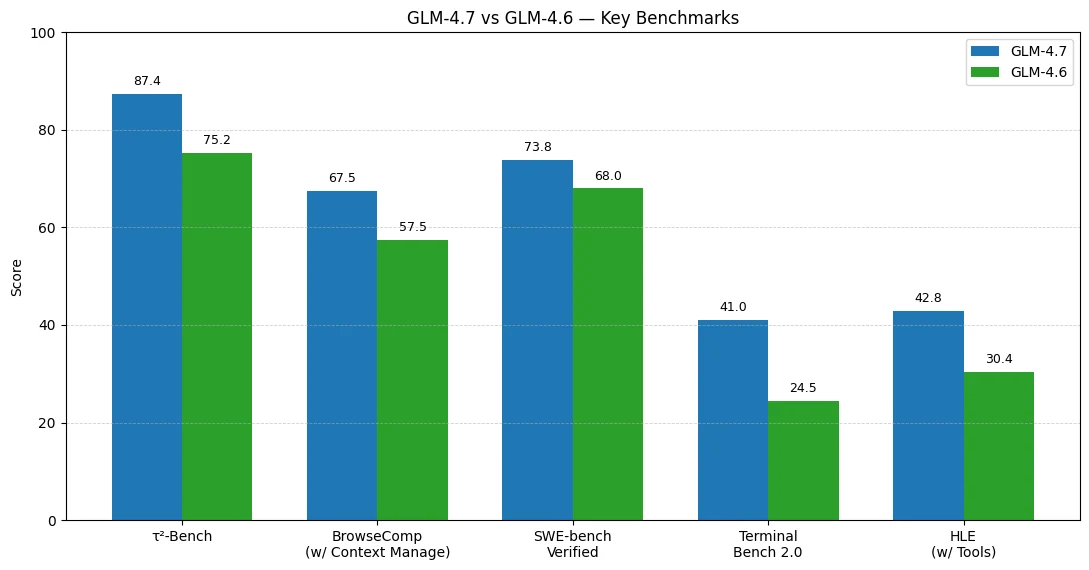
ベンチマーク結果は、GLM-4.7がGLM-4.6に対して最も大きな向上を示しているのが、エージェント的・ツール使用ワークフローとエンドツーエンドのコーディング実行であることを示しています。
ツール使用とエージェントワークフローが最も向上
- τ²-Bench: 75.2 → 87.4 (+12.2)
- BrowseComp (w/ Context Manage): 57.5 → 67.5 (+10.0)
実用的なコーディングがより信頼性向上
- SWE-bench Verified: 68.0 → 73.8 (+5.8)
ターミナル型コーディングエージェントが大幅に向上
- Terminal Bench 2.0: 24.5 → 41.0 (+16.5)
ツールを使用した高度な推論が大幅強化
- HLE (w/ Tools): 30.4 → 42.8 (+12.4)
GLM-4.7で何ができるか?
GLM-4.7の強みにマッチした、影響力の高いユースケースをご紹介します。
- エージェント型コーディングアシスタント
- 「計画→実装→テスト→修正」のサイクル
- 複数ファイルのリファクタリング、ターミナル型タスク、長めのプログラミングセッション
- ツールを使用するエージェント(検索+ブラウズ+構造化出力)
- 情報源を収集し、結果を比較し、構造化されたサマリーを返すリサーチエージェント
- より洗練された美観を備えたフロントエンド生成
- ランディングページ、UIコンポーネント、デザイン一貫性のあるレイアウト生成
- オフィス自動化(PPTアウトライン、ポスター、洗練された文章)
- より信頼性の高いフォーマットとレイアウトの一貫性、「すぐ使える」下書きの向上
GLM-4.7を使い始める:アクセスオプション
一般的には次の4つの実用的なオプションがあります。
まずは試す:Novita Web Playground(初心者に最適)
すばやくプロンプトをテストしてGLM-4.7の動作を確認したい場合、Novitaがワンクリックで使えるウェブ体験を提供しています。
APIで構築する:公式エンドポイント vs Novita AI Serverless(開発者向け)
最適な用途: プロダクションアプリ、コスト最適化を図るスタートアップ、多数のモデルに対して統一APIを求めるチーム。
サーバーレススケーリング、OpenAI互換の呼び出し、使用量ベースの課金を求めるなら、GLM-4.7はNovita AIでzai-org/glm-4.7として利用可能です。
💡Novita AIの特長:
- サーバーレス:すぐに実行、使用した分だけ支払い
- 価格:$0.6 / M 入力トークン、$2.2 / M 出力トークン
- 長いコンテキスト+大きな出力:コンテキスト204,800、最大出力131,072
- 関数呼び出し+構造化出力+推論対応
ステップバイステップ:Novita AIのAPIでGLM-4.7を使用する
GLM-4.7をアプリケーションに組み込むには、Novita AIのOpenAI互換の統合REST APIを使用します。
ステップ 1:ログインしてモデルライブラリにアクセス
https://novita.ai/にアクセスし、ログイン(またはサインアップ)して、モデルライブラリに移動します。
ステップ 2:GLM-4.7を選択
利用可能なモデルから、ワークロードの要件に基づいてGLM-4.7を選択します。
ステップ 3:無料トライアルを開始
無料トライアルを有効にして、GLM-4.7の推論、長いコンテキスト、コストパフォーマンスの特性を試します。
ステップ 4:APIキーを取得
設定ページを開き、認証用のAPIキーを生成してコピーします。
ステップ 5:APIをインストールして呼び出す(Python例)
以下は、Chat Completions APIを使用した簡単なPythonの例です。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
この設定により、推論の深さ、トークン使用量、生成動作を制御できます。特に、ターンレベルの思考を活用してコストとレイテンシを管理する場合に便利です。
自身のスタックで実行する:パワーユーザー向けローカルサーブ(上級者向け)
最適な用途: オフラインワークロード、データ保存に関する制約、カスタム推論スタック。
GLM-4.7はHugging FaceでMITライセンスでオープンソース化されており、公式モデルカードにはローカルでのサービス提供(vLLM、SGLang、transformers)のガイダンスや、フレームワークサポートに関する注意事項が含まれています。
GPU / VRAM要件(クイックリファレンス)
GLM-4.7をローカルで提供する場合、VRAMが厳しい制約となります。必要なGPUメモリは主に量子化ビット幅(低ビット量子化→低VRAM)に依存し、実行時のオーバーヘッド用に若干の余裕が必要です。
以下は実用的な参考値です(モデルサイズ+推定VRAM要件+推奨GPU構成)。
| Bit幅 | 量子化 | モデルサイズ | 推定必要VRAM | 推奨GPU | 合計VRAM |
|---|---|---|---|---|---|
| 1-bit | TQ1_0 | 84.5 GB | ~86 GB | NVIDIA L4 ×4 | 96 GB |
| 1-bit | IQ1_S | 97.2 GB | ~99 GB | NVIDIA A100 ×2 | 160 GB |
| 1-bit | IQ1_M | 108 GB | ~110 GB | — | — |
| 3-bit | Q3_K_XL | 159 GB | ~161 GB | NVIDIA L40S ×4 | 192 GB |
| 3-bit | Q3_K_M | 171 GB | ~173 GB | NVIDIA L40S ×4 | 192 GB |
| 4-bit | IQ4_XS | 192 GB | ~194 GB | NVIDIA A100 ×4 | 320 GB |
| 8-bit | Q8_0 | 381 GB | ~383 GB | NVIDIA A100 ×8 | 640 GB |
| 16-bit | BF16 | 717 GB | ~719 GB | NVIDIA H200 ×8 | 1128 GB |
経験則:「メモリ要件」の数値よりも若干多いVRAMを計画すること(フレームワーク/ランタイムのオーバーヘッド、KVキャッシュの増加、バッチ処理など)。ほとんどの「パワーユーザーのローカルサーブ」設定では、3~4ビット量子化が最も実用的な出発点であり、8/16ビットは通常マルチGPUサーバーを必要とします。
プラグインする:IDEエージェント、ツール呼び出し、アプリケーションフレームワーク
最適な用途: 「自分好みのIDEエージェント」、マルチエージェントシステム、ツール呼び出しアプリ。
GLM-4.7は、一般的なコーディングエージェント環境(例:Claude Codeスタイルのワークフロー)でうまく動作することが明示的に説明されています。
Novita AIでは、すでにOpenAI互換APIに対応している既存のツールにGLM-4.7を統合できます(Novitaのモデルページにはプラットフォーム上のAnthropic APIサポートも記載されています)。
エージェント型コーディング設定を使用している場合、GLM-4.7は人気のIDEアシスタントやコーディングエージェントの背後にあるモデルとして機能します。
- Claude Code: 強力なマルチステップ推論を備えた高度なエージェント型コーディングワークフロー
- Qwen Code: 開発タスクに最適化された専用AIコーディングツール
- Cline (VS Code) : VS Codeに直接統合され、反復的なコーディングとツール実行を行うAIアシスタント
- Cursor IDE : シームレスなAI搭載コーディング体験を提供するモダンなIDE
- Trae: コマンド指向のワークフロー向けターミナルベースAI開発アシスタント
- Codex CLI: 計画、編集、迅速な自動化のためのコマンドラインAIアシスタンス
- Kilo: 軽量AIコーディングエージェント/アシスタント。プロジェクト全体にわたる迅速な編集、リファクタリング、コードベースQ&Aに対応
- OpenCode: カスタマイズ可能なワークフローとツール統合をサポートする、オープンソースでローカルファーストのコーディングアシスタント/エージェント
これらのワークフローでGLM-4.7を使用する方法:
- プロバイダ/ベースURLをNovitaのOpenAI互換エンドポイントに設定
- モデルを選択:
zai-org/glm-4.7
最速のパス:Novita AIでGLM-4.7を試す
「インフラを管理せずに今日中にGLM-4.7を動かしたい」という目標があるなら、Novita AIのサーバーレスアクセスが最も直接的な方法です。特にモデルを比較したり、コストを最適化したり、迅速に出荷したい場合に適しています。
Novita AIは、開発者がシンプルなAPIを使ってAIモデルを簡単にデプロイできるAIクラウドプラットフォームです。また、手頃で信頼性の高いGPUクラウドを提供し、構築とスケーリングを支援します。
よくある質問
GLM-4.7は無料ですか?
Novita AIでは、GLM-4.7はトークン単位の従量課金です:入力$0.6/Mトークン、キャッシュ読み取り$0.11/Mトークン、出力$2.2/Mトークン。
Z.aiでは、有料のCoding Plan(月額$3から)として提供されることが一般的です。
一部のプラットフォームでは限定的な無料トライアル/割り当てを提供する場合がありますが、GLM-4.7自体が普遍的に「無料」というわけではありません。
GLM-4.7は本当に優れていますか?
コーディング+エージェントワークフローの点では、提供元によって最高クラスのオープンモデルとして位置づけられています。Z.aiはコーディングとエージェントのベンチマーク(例:LiveCodeBench v6、SWE-bench Verified、BrowseComp、τ²-Bench)で強力な結果を報告しており、いくつかの測定ではClaude Sonnet 4.5と競合するフレームを提示しています。
GLM-4.7にビジョン機能はありますか?
GLM-4.7はテキスト専用です。ビジョン機能が必要な場合は、代わりにGLM-Vバリアント(例:GLM-4.6VやGLM-4.5V。プロバイダによって画像入力に対応)を使用してください。



