

In dieser Anleitung zeigen wir Ihnen vier praktische Wege, auf GLM-4.7 zuzugreifen – von einer Weboberfläche für schnelle Tests bis hin zur lokalen Bereitstellung für strenge Datenresidenzanforderungen. Wir konzentrieren uns insbesondere auf den API-Zugriff über Novita AI, wo GLM-4.7 als zai-org/glm-4.7 über einen serverlosen Endpunkt verfügbar ist – so können Sie in wenigen Minuten von der Idee zur funktionierenden Integration gelangen, ohne Inferenz-Infrastruktur verwalten zu müssen.
Am Ende wissen Sie genau, welche Zugriffsmöglichkeit zu Ihrem Workload passt, und Sie haben eine schrittweise API-Einrichtung, die Sie in Ihre App kopieren können, um sofort mit der Entwicklung mit GLM-4.7 zu beginnen.
GLM-4.7 vs GLM-4.6: Wichtige Upgrades auf einen Blick
GLM-4.7 hat die gleichen hervorstechenden Kontextlimits wie GLM-4.6 – 200K Kontextfenster und bis zu 128K Ausgabe, aberGLM-4.7’s größten Verbesserungen zeigen sich dort, wo es für Produktions-Apps am wichtigsten ist – agentische, toolnutzende Workflows und End-to-End-Codeausführung.Sie können GLM- 4.7 schnell über Novita testen.
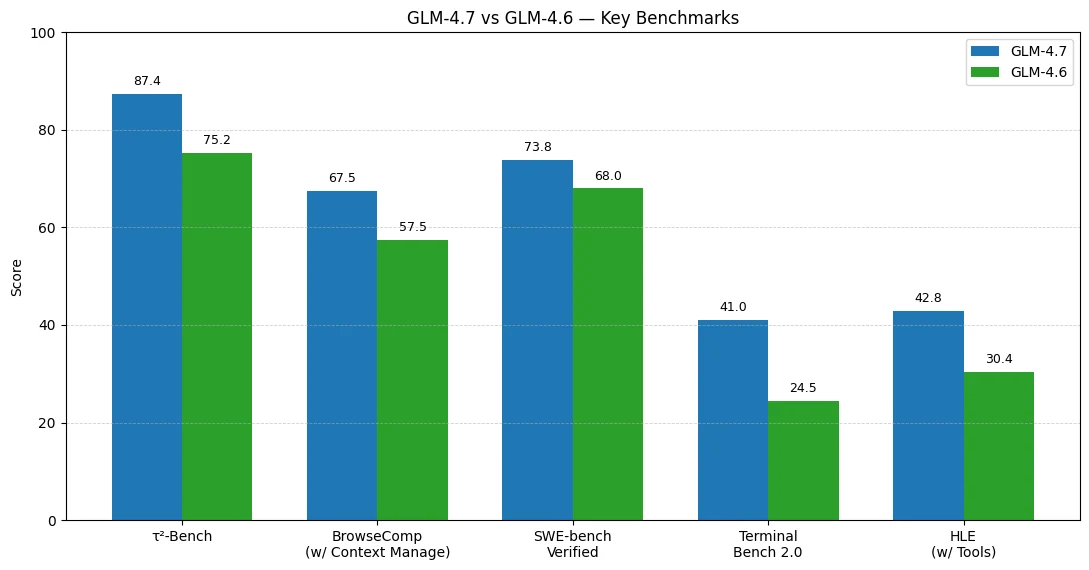
Benchmark-Ergebnisse deuten darauf hin, dass die größten Verbesserungen von GLM-4.7 gegenüber GLM-4.6 in agentischen, toolnutzenden Workflows und End-to-End-Codeausführung liegen.
Toolnutzung und Agenten-Workflows verbessern sich am stärksten
- τ²-Bench: 75.2 → 87.4 (+12.2)
- BrowseComp (mit Kontextverwaltung): 57.5 → 67.5 (+10.0)
Echtwelt-Codierung wird zuverlässiger
- SWE-bench Verified: 68.0 → 73.8 (+5.8)
Terminalbasierte Coding-Agenten verzeichnen einen großen Sprung
- Terminal Bench 2.0: 24.5 → 41.0 (+16.5)
Schwieriges Schließen mit Tools ist deutlich stärker
- HLE (mit Tools): 30.4 → 42.8 (+12.4)
Was können Sie mit GLM-4.7 tun?
Hier sind hochwirksame Anwendungsfälle, die zu den Stärken von GLM-4.7 passen:
-
Agentische Coding-Assistenten
- „Planen → Implementieren → Testen → Beheben“-Schleifen
- Mehrdatei-Refactorings, terminalbasierte Aufgaben und längere Programmier-Sessions
-
Toolnutzende Agenten (Suche + Durchsuchen + Strukturierte Ausgaben)
- Recherche-Agenten, die Quellen sammeln, Ergebnisse vergleichen und strukturierte Zusammenfassungen zurückgeben
-
Frontend-Generierung mit saubererem Design
- Landingpages, UI-Komponenten, designkonforme Layout-Generierung
-
Büroautomatisierung (PPT-Gliederungen, Poster, polierte Texte)
- Zuverlässigere Formatierung und Layout-Konsistenz, bessere „gebrauchsfertige“ Entwürfe
Erste Schritte mit GLM-4.7: Ihre Zugriffsmöglichkeiten
Im Allgemeinen haben Sie vier praktische Optionen:
Zuerst testen: Novita Web Playground (Am einfachsten für Einsteiger)
Wenn Sie schnell Prompts testen und sehen möchten, wie GLM-4.7 reagiert, bietet Novita ein One-Click-Web-Erlebnis.
Mit APIs entwickeln: Offizieller Endpunkt vs. Novita AI Serverless (Für Entwickler)
Ideal für: Produktions-Apps, Startups, die Kosten optimieren, Teams, die eine einheitliche API für viele Modelle wünschen.
Wenn Sie serverlose Skalierung, OpenAI-kompatible Aufrufe und nutzungsbasierte Abrechnung wünschen, ist GLM-4.7 auf Novita AI als zai-org/glm-4.7 verfügbar.
💡Novita AI Highlights:
- Serverlos: Sofort ausführen, nur für die tatsächliche Nutzung zahlen
- Preise: $0.6 / M Eingabe-Tokens, $2.2 / M Ausgabe-Tokens
- Langer Kontext + große Ausgabe: 204.800 Kontext, 131.072 maximale Ausgabe
- Funktionsaufrufe + strukturierte Ausgabe + Schlussfolgerung unterstützt
Schritt für Schritt: Nutzen Sie GLM-4.7 über die API mit Novita AI
Integrieren Sie GLM-4.7 in Ihre Anwendungen mithilfe der einheitlichen REST-API von Novita AI, die mit OpenAI kompatibel ist.
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Besuchen Sie https://novita.ai/: Melden Sie sich an (oder registrieren Sie sich) bei Ihrem Novita AI-Konto und navigieren Sie zur Modellbibliothek.
Schritt 2: GLM-4.7 auswählen
Durchsuchen Sie die verfügbaren Modelle und wählen Sie GLM-4.7 entsprechend Ihrer Workload-Anforderungen aus.
Schritt 3: Kostenlose Testversion starten
Aktivieren Sie Ihre kostenlose Testversion, um die Schlussfolgerungsfähigkeiten, den Langkontext und die Kosten-Leistungs-Merkmale von GLM-4.7 zu erkunden.
Schritt 4: API-Schlüssel abrufen
Öffnen Sie die Einstellungsseite, um Ihren API-Schlüssel zur Authentifizierung zu generieren und zu kopieren.
Schritt 5: API installieren und aufrufen (Python-Beispiel)
Unten finden Sie ein einfaches Beispiel für die Nutzung der Chat-Completions-API mit Python:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Diese Einrichtung ermöglicht es Ihnen, die Schlussfolgerungstiefe, die Token-Nutzung und das Generierungsverhalten zu steuern – besonders nützlich, wenn Sie die Denkweise auf Turn-Ebene nutzen, um Kosten und Latenz zu verwalten.
Auf eigenem Stack ausführen: Lokale Bereitstellung für Power-User (Fortgeschrittene Benutzer)
Ideal für: Offline-Workloads, Datenresidenzanforderungen, benutzerdefinierte Inferenz-Stacks.
GLM-4.7 ist unter der MIT-Lizenz quelloffen auf Hugging Face verfügbar, und die offizielle Modellkarte enthält Anleitungen zur lokalen Bereitstellung (vLLM, SGLang, Transformers) sowie Hinweise zur Framework-Unterstützung.
GPU-/VRAM-Anforderungen (Kurzübersicht)
Bei der lokalen Bereitstellung von GLM-4.7 ist VRAM die harte Einschränkung. Der benötigte GPU-Speicher hängt hauptsächlich von der Quantisierungs-Bitbreite ab (niedrigere Bitbreite → weniger VRAM), zuzüglich eines kleinen Puffers für Laufzeit-Overhead.
Unten finden Sie eine praktische Referenz (Modellgröße + geschätzter VRAM-Bedarf + empfohlene GPU-Konfigurationen):
| Bit-Breite | Quantisierung | Modellgröße | Geschätzter VRAM-Bedarf | Empfohlene GPU | Gesamter VRAM |
|---|---|---|---|---|---|
| 1-Bit | TQ1_0 | 84,5 GB | ~86 GB | NVIDIA L4 ×4 | 96 GB |
| 1-Bit | IQ1_S | 97,2 GB | ~99 GB | NVIDIA A100 ×2 | 160 GB |
| 1-Bit | IQ1_M | 108 GB | ~110 GB | — | — |
| 3-Bit | Q3_K_XL | 159 GB | ~161 GB | NVIDIA L40S ×4 | 192 GB |
| 3-Bit | Q3_K_M | 171 GB | ~173 GB | NVIDIA L40S ×4 | 192 GB |
| 4-Bit | IQ4_XS | 192 GB | ~194 GB | NVIDIA A100 ×4 | 320 GB |
| 8-Bit | Q8_0 | 381 GB | ~383 GB | NVIDIA A100 ×8 | 640 GB |
| 16-Bit | BF16 | 717 GB | ~719 GB | NVIDIA H200 ×8 | 1128 GB |
Faustregel: Planen Sie etwas mehr VRAM als die „Speicherbedarf“-Angabe ein (Framework-/Laufzeit-Overhead, KV-Cache-Wachstum, Batch-Verarbeitung etc.). Für die meisten „Power-User-Lokalbereitstellung“-Setups ist die 3–4-Bit-Quantisierung der praktischste Ausgangspunkt, während 8/16-Bit in der Regel Multi-GPU-Server erfordern.
Anbinden: IDE-Agenten, Tool-Aufrufe und App-Frameworks
Ideal für: „Bring Your Own IDE Agent“, Multi-Agenten-Systeme, Apps mit Tool-Aufrufen.
GLM-4.7 wird explizit als gut funktionierend in beliebten Coding-Agenten-Umgebungen beschrieben (z. B. Workflows im Stil von Claude Code).
Auf Novita AI können Sie GLM-4.7 in bestehende Tools integrieren, die bereits OpenAI-kompatible APIs unterstützen (auf der Modellseite von Novita wird außerdem die Unterstützung der Anthropic-API auf der Plattform aufgeführt).
Wenn Sie ein agentisches Coding-Setup verwenden, kann GLM-4.7 als Modell hinter beliebten IDE-Assistenten und Coding-Agenten dienen:
- Claude Code: Fortgeschrittene agentische Coding-Workflows mit starker mehrstufiger Schlussfolgerung
- Qwen Code: Spezialisiertes KI-Coding-Tool, optimiert für Entwicklungsaufgaben
- Cline (VS Code): KI-Assistent, der direkt in VS Code integriert ist für iteratives Coding und Tool-Ausführungen
- Cursor IDE: Eine moderne IDE mit nahtloser, KI-gestützter Coding-Erfahrung
- Trae: Terminalbasierter KI-Entwicklungsassistent für befehlsorientierte Workflows
- Codex CLI: KI-Unterstützung für die Kommandozeile zur Planung, Bearbeitung und schnellen Automatisierung
- Kilo: Leichtgewichtiger KI-Coding-Agent/-Assistent für schnelle Bearbeitungen, Refactorings und Codebase-Fragen über Projekte hinweg
- OpenCode: Open-Source, lokal-first Coding-Assistent/-Agent, der anpassbare Workflows und Tool-Integrationen unterstützt
So nutzen Sie GLM-4.7 in diesen Workflows:
- Setzen Sie die Provider-/Basis-URL auf den OpenAI-kompatiblen Endpunkt von Novita
- Wählen Sie das Modell:
zai-org/glm-4.7
Schnellster Weg: Testen Sie GLM-4.7 auf Novita AI
Wenn Ihr Ziel ist, „GLM-4.7 noch heute zum Laufen zu bringen“ ohne Infrastruktur zu verwalten, ist der serverlose Zugriff von Novita AI in der Regel der direkteste Weg – insbesondere wenn Sie Modelle vergleichen, Kosten optimieren oder schnell ausliefern möchten.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.
Häufig gestellte Fragen
Ist GLM-4.7 kostenlos?
Auf Novita AI ist GLM-4.7 nutzungsbasiert pro Token abgerechnet: $0.6/M Token (Eingabe), $0.11/M Token (Cache-Lesen) und $2.2/M Token (Ausgabe)
Auf Z.ai ist der Zugriff üblicherweise in einem kostenpflichtigen Coding-Plan enthalten (ab 3 $ / Monat).
Einige Plattformen bieten möglicherweise begrenzte Testversionen/Kontingente an, aber GLM-4.7 selbst ist nicht universell „kostenlos“.
Ist GLM-4.7 wirklich gut?
Für Coding- und agentische Workflows wird es von seinem Herausgeber als Top-Open-Modell positioniert. Z.ai meldet starke Ergebnisse bei Coding- und Agenten-Benchmarks (z. B. LiveCodeBench v6, SWE-bench Verified, BrowseComp, τ²-Bench) und stuft es bei mehreren Messungen als konkurrenzfähig zu Claude Sonnet 4.5 ein.
Hat GLM-4.7 Vision (Bildeingabe)?
GLM-4.7 ist rein textbasiert. Wenn Sie Vision benötigen, verwenden Sie stattdessen eine GLM-V-Variante (z. B. GLM-4.6V oder GLM-4.5V, die je nach Anbieter Bildeingaben unterstützen).



