

Neste guia, mostraremos quatro formas práticas de acessar o GLM-4.7 — de uma interface web para testes rápidos até a implantação local para requisitos rigorosos de residência de dados. Nos concentraremos especialmente no acesso via API pela Novita AI, onde o GLM-4.7 está disponível como zai-org/glm-4.7 por meio de um endpoint serverless — para que você vá da ideia a uma integração funcional em minutos, sem precisar gerenciar infraestrutura de inferência.
Ao final, você saberá exatamente qual opção de acesso se adapta à sua carga de trabalho e terá uma configuração de API passo a passo que pode copiar para o seu aplicativo para começar a construir com o GLM-4.7 imediatamente.
GLM-4.7 vs GLM-4.6: Principais Aprimoramentos de Relance
O GLM-4.7 mantém os mesmos limites de contexto principais do GLM-4.6 — janela de contexto de 200K e saída de até 128K, mas os maiores ganhos do GLM-4.7 aparecem onde os aplicativos de produção mais se importam — fluxos de trabalho agenticos e com uso de ferramentas e execução de código ponta a ponta. Você pode testar o GLM-4.7 rapidamente pela Novita.
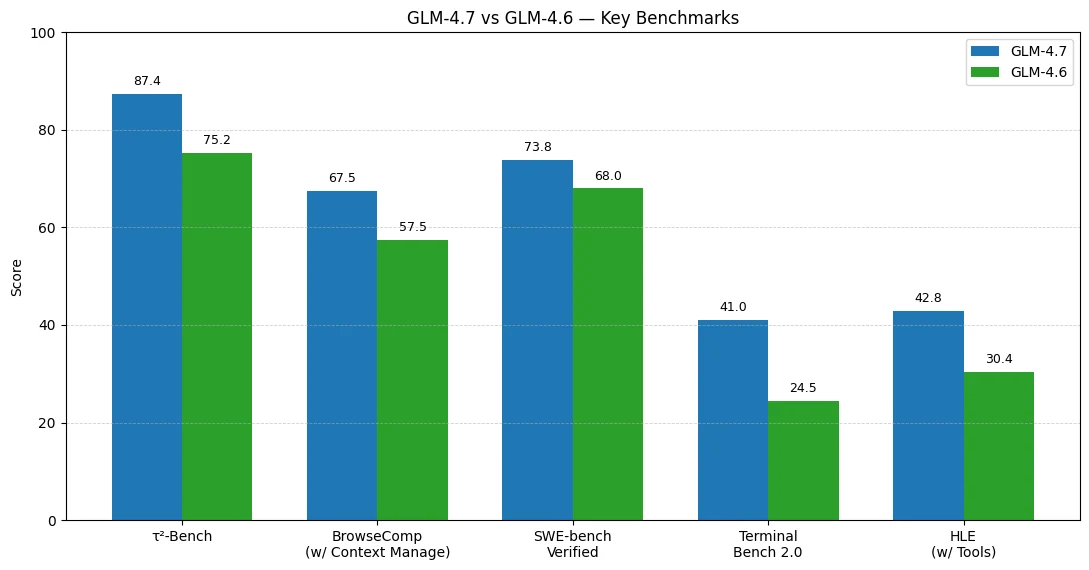
Os resultados de benchmark sugerem que os maiores ganhos do GLM-4.7 em relação ao GLM-4.6 aparecem em fluxos de trabalho agenticos e com uso de ferramentas e execução de código ponta a ponta.
Uso de ferramentas e fluxos de trabalho agenticos melhoram mais
- τ²-Bench: 75.2 → 87.4 (+12.2)
- BrowseComp (com Gerenciamento de Contexto): 57.5 → 67.5 (+10.0)
Codificação no mundo real se torna mais confiável
- SWE-bench Verified: 68.0 → 73.8 (+5.8)
Agentes de codificação no estilo terminal tem um salto grande
- Terminal Bench 2.0: 24.5 → 41.0 (+16.5)
Raciocínio complexo com ferramentas é significativamente mais forte
- HLE (com Ferramentas): 30.4 → 42.8 (+12.4)
O Que Você Pode Fazer Com o GLM-4.7?
Aqui estão casos de uso de alto impacto que correspondem aos pontos fortes do GLM-4.7:
- Assistentes de codificação agenticos
- Fluxos de “Planejamento → implementação → teste → correção”
- Refatorações de múltiplos arquivos, tarefas no estilo terminal e sessões de programação mais longas
- Agentes com uso de ferramentas (pesquisa + navegação + saídas estruturadas)
- Agentes de pesquisa que coletam fontes, comparam resultados e retornam resumos estruturados
- Geração de front-end com estética mais limpa
- Páginas de destino, componentes de UI, geração de layouts consistentes com o design
- Automação de escritório (esquemas de PPT, pôsteres, textos polidos)
- Formatação mais confiável e consistência de layout, rascunhos “prontos para usar” melhores
Primeiros Passos com o GLM-4.7: Suas Opções de Acesso
Você geralmente tem quatro opções práticas:
Experimente Primeiro: Playground Web da Novita (Mais Fácil para Iniciantes)
Se você quiser testar prompts rapidamente e ver como o GLM-4.7 se comporta, a Novita oferece uma experiência web com um clique.
Construa com APIs: Endpoint Oficial vs Serverless da Novita AI (Para Desenvolvedores)
Melhor para: aplicativos de produção, startups que otimizam custos, equipes que desejam uma API unificada para vários modelos.
Se você deseja escalonamento serverless, chamadas compatíveis com OpenAI e faturamento baseado no uso, o GLM-4.7 está disponível na Novita AI como zai-org/glm-4.7.
💡Destaques da Novita AI:
- Serverless: execute imediatamente, pague apenas pelo que usar
- Preços: $0,6 / M tokens de entrada, $2,2 / M tokens de saída
- Contexto longo + saída grande: 204.800 de contexto, 131.072 de saída máxima
- Chamada de funções + saída estruturada + raciocínio suportados
Passo a passo: Use o GLM-4.7 via API com a Novita AI
Traga o GLM-4.7 para seus aplicativos usando a API REST unificada compatível com OpenAI da Novita AI.
Passo 1: Faça login e acesse a Biblioteca de Modelos Visite https://novita.ai/: Faça login (ou cadastre-se) na sua conta da Novita AI e navegue até a Biblioteca de Modelos.
Passo 2: Escolha o GLM-4.7 Navegue pelos modelos disponíveis e selecione o GLM-4.7 de acordo com os requisitos da sua carga de trabalho.
Passo 3: Inicie seu Teste Gratuito Ative seu teste gratuito para explorar o raciocínio, o contexto longo e as características de custo-desempenho do GLM-4.7.
Passo 4: Obtenha sua Chave de API Abra a página de Configurações para gerar e copiar sua chave de API para autenticação.
Passo 5: Instale e Chame a API (Exemplo em Python) Abaixo está um exemplo simples usando a API de Conclusões de Chat com Python:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Essa configuração permite controlar a profundidade do raciocínio, o uso de tokens e o comportamento de geração — particularmente útil ao aproveitar o pensamento em nível de turno para gerenciar custo e latência.
Execute no Seu Próprio Stack: Serviço Local para Usuários Avançados
Melhor para: cargas de trabalho offline, restrições de residência de dados, stacks de inferência personalizados.
O GLM-4.7 é open source sob a licença MIT no Hugging Face, e o cartão oficial do modelo inclui orientações para servir localmente (vLLM, SGLang, transformers) além de notas sobre suporte a frameworks.
Requisitos de GPU / VRAM (referência rápida)
Ao servir o GLM-4.7 localmente, a VRAM é a restrição principal. A memória de GPU necessária depende principalmente da largura de bits de quantização (quantização de bits menor → VRAM menor), além de uma pequena margem para sobrecarga de tempo de execução.
Abaixo está uma referência prática (tamanho do modelo + requisito estimado de VRAM + configurações de GPU sugeridas):
| Largura de Bits | Quantização | Tamanho do Modelo | VRAM Est. Necessária | GPU Recomendada | VRAM Total |
|---|---|---|---|---|---|
| 1-bit | TQ1_0 | 84.5 GB | ~86 GB | NVIDIA L4 ×4 | 96 GB |
| 1-bit | IQ1_S | 97.2 GB | ~99 GB | NVIDIA A100 ×2 | 160 GB |
| 1-bit | IQ1_M | 108 GB | ~110 GB | — | — |
| 3-bit | Q3_K_XL | 159 GB | ~161 GB | NVIDIA L40S ×4 | 192 GB |
| 3-bit | Q3_K_M | 171 GB | ~173 GB | NVIDIA L40S ×4 | 192 GB |
| 4-bit | IQ4_XS | 192 GB | ~194 GB | NVIDIA A100 ×4 | 320 GB |
| 8-bit | Q8_0 | 381 GB | ~383 GB | NVIDIA A100 ×8 | 640 GB |
| 16-bit | BF16 | 717 GB | ~719 GB | NVIDIA H200 ×8 | 1128 GB |
Regra geral: planeje ter um pouco mais de VRAM do que o número de “requisito de memória” (sobrecarga de framework/tempo de execução, crescimento do cache KV, processamento em lote, etc.). Para a maioria das configurações de “serviço local para usuários avançados”, a quantização de 3 a 4 bits é o ponto de partida mais prático, enquanto 8/16 bits geralmente requer servidores com várias GPUs.
Conecte: Agentes de IDE, Chamada de Ferramentas e Frameworks de Aplicativos
Melhor para: “traga seu próprio agente de IDE”, sistemas multiagente, aplicativos que usam chamada de ferramentas.
O GLM-4.7 é explicitamente descrito como funcionando bem em ambientes populares de agentes de codificação (ex: fluxos de trabalho no estilo Claude Code).
Na Novita AI, você pode integrar o GLM-4.7 a ferramentas existentes que já usam APIs compatíveis com OpenAI (e a página de modelos da Novita também lista suporte à API Anthropic na plataforma).
Se você está usando uma configuração de codificação agentica, o GLM-4.7 pode servir como o modelo por trás de assistentes de IDE populares e agentes de codificação:
- Claude Code: Fluxos de trabalho de codificação agentica avançados com forte raciocínio de múltiplos passos
- Qwen Code: Ferramenta de codificação com IA especializada, otimizada para tarefas de desenvolvimento
- Cline (VS Code): Assistente de IA integrado diretamente ao VS Code para codificação iterativa e execução de ferramentas
- Cursor IDE: Uma IDE moderna com uma experiência de codificação com IA integrada e fluida
- Trae: Assistente de desenvolvimento com IA baseado em terminal para fluxos de trabalho orientados a comandos
- Codex CLI: Assistência de IA por linha de comando para planejamento, edições e automação rápida
- Kilo: Agente/assistente de codificação com IA leve para edições rápidas, refatorações e perguntas e respostas sobre bases de código em vários projetos
- OpenCode: Assistente/agente de codificação open source, local-first, que suporta fluxos de trabalho personalizáveis e integrações de ferramentas
Como usar o GLM-4.7 nesses fluxos de trabalho:
- Defina o URL do provedor/base para o endpoint compatível com OpenAI da Novita
- Escolha o modelo:
zai-org/glm-4.7
Caminho Mais Rápido: Experimente o GLM-4.7 na Novita AI
Se o seu objetivo é “colocar o GLM-4.7 para rodar hoje” sem gerenciar infraestrutura, o acesso serverless da Novita AI é geralmente a rota mais direta — especialmente quando você está comparando modelos, otimizando gastos ou lançando rapidamente.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma forma fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.
Perguntas frequentes
O GLM-4.7 é gratuito? Na Novita AI, o GLM-4.7 é pago por token: $0,6/M tokens (entrada), $0,11/M tokens (leitura de cache) e $2,2/M tokens (saída) Na Z.ai, o acesso é geralmente disponibilizado por meio de um Plano de Codificação pago (a partir de $3/mês). Algumas plataformas podem oferecer testes/quotas limitados, mas o próprio GLM-4.7 não é “gratuito” universalmente.
O GLM-4.7 é realmente bom? Para fluxos de trabalho de codificação + agenticos, ele é posicionado como um modelo aberto de primeira linha por seu editor. A Z.ai relata resultados fortes em benchmarks de codificação e agentes (ex: LiveCodeBench v6, SWE-bench Verified, BrowseComp, τ²-Bench), e o enquadra como competitivo com o Claude Sonnet 4.5 em várias medições.
O GLM-4.7 tem suporte a visão? O GLM-4.7 é apenas texto. Se você precisar de suporte a visão, use uma variante GLM-V (ex: GLM-4.6V ou GLM-4.5V, que suportam entradas de imagem dependendo do provedor).



