

En esta guía, te mostraremos cuatro formas prácticas de acceder a GLM-4.7 —desde una interfaz web para pruebas rápidas, hasta la implementación local para estrictos requisitos de residencia de datos. Nos centraremos especialmente en el acceso por API a través de Novita AI, donde GLM-4.7 está disponible como zai-org/glm-4.7 mediante un endpoint serverless —para que puedas pasar de la idea a una integración funcional en minutos, sin gestionar infraestructura de inferencia.
Al final, sabrás exactamente qué opción de acceso se adapta a tu carga de trabajo y tendrás una configuración de API paso a paso que podrás copiar en tu aplicación para empezar a crear con GLM-4.7 de inmediato.
GLM-4.7 vs GLM-4.6: Mejoras clave de un vistazo
GLM-4.7 mantiene los mismos límites de contexto principales que GLM-4.6 —ventana de contexto de 200K y hasta 128K de salida, pero los mayores avances de GLM-4.7 se ven donde más importan las aplicaciones en producción: flujos de trabajo agentivos y con uso de herramientas y ejecución de código de extremo a extremo. Puedes probar GLM-4.7 rápidamente a través de Novita.
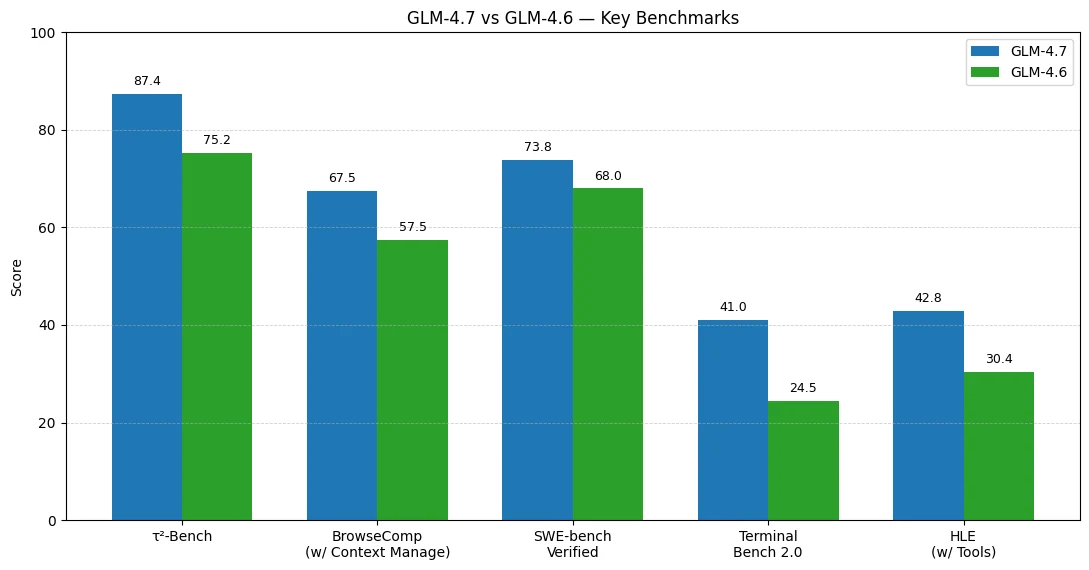
Los resultados de los benchmarks sugieren que las mayores mejoras de GLM-4.7 respecto a GLM-4.6 se dan en flujos de trabajo agentivos y con uso de herramientas y ejecución de código de extremo a extremo.
El uso de herramientas y los flujos agentivos mejoran más
- τ²-Bench: 75.2 → 87.4 (+12.2)
- BrowseComp (con Gestión de Contexto): 57.5 → 67.5 (+10.0)
La codificación en el mundo real se vuelve más fiable
- SWE-bench Verified: 68.0 → 73.8 (+5.8)
Los agentes de codificación tipo terminal experimentan un gran salto
- Terminal Bench 2.0: 24.5 → 41.0 (+16.5)
El razonamiento complejo con herramientas es significativamente más potente
- HLE (con Herramientas): 30.4 → 42.8 (+12.4)
¿Qué puedes hacer con GLM-4.7?
Estos son casos de uso de alto impacto que coinciden con los puntos fuertes de GLM-4.7:
- Asistentes de codificación agentivos
- Bucles “Planificar → Implementar → Probar → Corregir”
- Refactorizaciones de múltiples archivos, tareas tipo terminal y sesiones de programación más largas
- Agentes que usan herramientas (búsqueda + navegación + salidas estructuradas)
- Agentes de investigación que recopilan fuentes, comparan resultados y devuelven resúmenes estructurados
- Generación de front-end con una estética más limpia
- Páginas de aterrizaje, componentes de UI, generación de diseño consistente
- Automatización de oficina (esquemas de presentaciones, carteles, redacción pulida)
- Formato y consistencia de diseño más fiables, borradores “listos para usar” de mayor calidad
Primeros pasos con GLM-4.7: tus opciones de acceso
Generalmente tienes cuatro opciones prácticas:
Pruébalo primero: Novita Web Playground (lo más fácil para principiantes)
Si quieres probar rápidamente prompts y ver cómo se comporta GLM-4.7, Novita ofrece una experiencia web con un solo clic.
Construye con APIs: Endpoint oficial vs Novita AI Serverless (para desarrolladores)
Ideal para: aplicaciones en producción, startups que optimizan costos, equipos que desean una API unificada para muchos modelos.
Si necesitas escalado serverless, llamadas compatibles con OpenAI y facturación por uso, GLM-4.7 está disponible en Novita AI como zai-org/glm-4.7.
💡Aspectos destacados de Novita AI:
- Serverless: ejecútalo inmediatamente, paga solo por lo que usas
- Precios: $0.6 / M tokens de entrada, $2.2 / M tokens de salida
- Contexto largo + salida grande: 204,800 de contexto, 131,072 de salida máxima
- Llamada a funciones + salida estructurada + razonamiento compatibles
Paso a paso: Usa GLM-4.7 a través de la API con Novita AI
Integra GLM-4.7 en tus aplicaciones usando la API REST unificada compatible con OpenAI de Novita AI.
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Visita https://novita.ai/: Inicia sesión (o regístrate) en tu cuenta de Novita AI y navega a la Biblioteca de Modelos.
Paso 2: Elige GLM-4.7
Examina los modelos disponibles y selecciona GLM-4.7 según los requisitos de tu carga de trabajo.
Paso 3: Comienza tu prueba gratuita
Activa tu prueba gratuita para explorar las características de razonamiento, contexto largo y relación costo-rendimiento de GLM-4.7.
Paso 4: Obtén tu clave API
Abre la página de Configuración para generar y copiar tu clave API para la autenticación.
Paso 5: Instala y llama a la API (Ejemplo en Python)
A continuación se muestra un ejemplo simple usando la API de Chat Completions con Python:
from openai import OpenAI
client = OpenAI(
api_key="<Tu Clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Esta configuración te permite controlar la profundidad del razonamiento, el uso de tokens y el comportamiento de generación —particularmente útil al aprovechar el pensamiento a nivel de turno para gestionar el costo y la latencia.
Ejecútalo en tu propio stack: Servicio local para usuarios avanzados
Ideal para: cargas de trabajo sin conexión, restricciones de residencia de datos, stacks de inferencia personalizados.
GLM-4.7 es código abierto bajo la licencia MIT en Hugging Face, y la tarjeta oficial del modelo incluye orientación para servir localmente (vLLM, SGLang, transformers) además de notas sobre soporte de frameworks.
Requisitos de GPU/VRAM (referencia rápida)
Al servir GLM-4.7 localmente, la VRAM es la restricción principal. La memoria de GPU requerida depende principalmente del ancho de bits de cuantización (cuantización de menor bit → menor VRAM), más un pequeño margen para gastos generales de ejecución.
A continuación se muestra una referencia práctica (tamaño del modelo + requisito estimado de VRAM + configuraciones de GPU sugeridas):
| Bit-width | Quantization | Model size | Est. VRAM required | Recommended GPU | Total VRAM |
|---|---|---|---|---|---|
| 1-bit | TQ1_0 | 84.5 GB | ~86 GB | NVIDIA L4 ×4 | 96 GB |
| 1-bit | IQ1_S | 97.2 GB | ~99 GB | NVIDIA A100 ×2 | 160 GB |
| 1-bit | IQ1_M | 108 GB | ~110 GB | — | — |
| 3-bit | Q3_K_XL | 159 GB | ~161 GB | NVIDIA L40S ×4 | 192 GB |
| 3-bit | Q3_K_M | 171 GB | ~173 GB | NVIDIA L40S ×4 | 192 GB |
| 4-bit | IQ4_XS | 192 GB | ~194 GB | NVIDIA A100 ×4 | 320 GB |
| 8-bit | Q8_0 | 381 GB | ~383 GB | NVIDIA A100 ×8 | 640 GB |
| 16-bit | BF16 | 717 GB | ~719 GB | NVIDIA H200 ×8 | 1128 GB |
Regla general: planifica un poco más de VRAM que el número de “requisito de memoria” (gastos generales del framework/tiempo de ejecución, crecimiento de la caché KV, batching, etc.). Para la mayoría de configuraciones de “servicio local para usuarios avanzados”, la cuantización de 3–4 bits es el punto de partida más práctico, mientras que 8/16 bits generalmente requiere servidores multi-GPU.
Conéctalo: Agentes IDE, llamadas a herramientas y frameworks de aplicaciones
Ideal para: “trae tu propio agente IDE”, sistemas multi-agente, aplicaciones que llaman a herramientas.
Se describe explícitamente que GLM-4.7 funciona bien en entornos populares de agentes de codificación (por ejemplo, flujos de trabajo estilo Claude Code).
En Novita AI, puedes integrar GLM-4.7 en herramientas existentes que ya hablen APIs compatibles con OpenAI (y la página del modelo de Novita también enumera soporte para la API de Anthropic en la plataforma).
Si estás usando una configuración de codificación agentiva, GLM-4.7 puede servir como modelo detrás de asistentes IDE populares y agentes de codificación:
- Claude Code: Flujos de trabajo de codificación agentivos avanzados con fuerte razonamiento en múltiples pasos
- Qwen Code: Herramienta de codificación AI especializada optimizada para tareas de desarrollo
- Cline (VS Code): Asistente AI integrado directamente en VS Code para codificación iterativa y ejecución de herramientas
- Cursor IDE : Un IDE moderno con una experiencia de codificación impulsada por AI sin interrupciones
- Trae: Asistente de desarrollo AI basado en terminal para flujos de trabajo orientados a comandos
- Codex CLI: Asistencia AI desde la línea de comandos para planificación, ediciones y automatización rápida
- Kilo: Agente/asistente de codificación AI ligero para ediciones rápidas, refactorizaciones y preguntas y respuestas sobre el código base en todos los proyectos
- OpenCode: Asistente/agente de codificación AI de código abierto y local, que admite flujos de trabajo personalizables e integraciones de herramientas
Cómo usar GLM-4.7 en estos flujos de trabajo:
- Configura el proveedor/URL base al endpoint compatible con OpenAI de Novita
- Elige el modelo:
zai-org/glm-4.7
La ruta más rápida: Prueba GLM-4.7 en Novita AI
Si tu objetivo es “poner GLM-4.7 en funcionamiento hoy” sin gestionar infraestructura, el acceso serverless de Novita AI suele ser la ruta más directa, especialmente cuando estás comparando modelos, optimizando gastos o lanzando rápidamente.
Novita AI es una plataforma de nube AI que ofrece a los desarrolladores una forma sencilla de implementar modelos AI usando nuestra API simple, al mismo tiempo que proporciona la nube GPU asequible y fiable para construir y escalar.
Preguntas frecuentes
¿GLM-4.7 es gratuito?
En Novita AI, GLM-4.7 se paga por token: $0.6/M tokens (entrada), $0.11/M tokens (lectura de caché) y $2.2/M tokens (salida).
En Z.ai, el acceso suele estar empaquetado a través de un Plan de Codificación de pago (desde $3/mes).
Algunas plataformas pueden ofrecer pruebas/cuotas limitadas, pero GLM-4.7 en sí no es universalmente “gratuito”.
¿GLM-4.7 es realmente bueno?
Para flujos de trabajo de codificación + agentivos, su editor lo posiciona como un modelo abierto de primer nivel. Z.ai reporta resultados sólidos en benchmarks de codificación y agentes (por ejemplo, LiveCodeBench v6, SWE-bench Verified, BrowseComp, τ²-Bench), y lo presenta como competitivo con Claude Sonnet 4.5 en varias mediciones.
¿GLM-4.7 tiene visión?
GLM-4.7 es solo texto. Si necesitas visión, usa una variante GLM-V en su lugar (por ejemplo, GLM-4.6V o GLM-4.5V, que admiten entradas de imagen según el proveedor).



