

- Novita AI Einführung
- RunPod Einführung
- Vergleich der Skalierbarkeit von RunPod und Novita AI
- Vergleich der Benutzerfreundlichkeit von RunPod und Novita AI (GPU-Instanz als Beispiel)
- Vergleich der Preispläne von RunPod und Novita AI
- Ist RunPod oder Novita AI besser für kleine Teams?
- Wie greife ich auf RunPod zu?
- Wie greife ich auf Novita AI zu?
Für Entwickler hängt die Wahl der richtigen Cloud-AI-Plattform oft von drei Dingen ab: Kosten, Benutzerfreundlichkeit und Skalierbarkeit. Sowohl Novita AI als auch RunPod bieten leistungsstarke GPU-gestützte Infrastruktur und Tools zum Bereitstellen, Trainieren oder Ausführen von KI-Modellen – sie richten sich jedoch an leicht unterschiedliche Entwicklerbedürfnisse.
- Novita AI glänzt mit schneller, erschwinglicher Inferenz über plug-and-play-APIs und serverlosen GPU-Zugriff – ideal für Indie-Entwickler, Startups und Produktteams, die eine schnelle KI-Integration benötigen, ohne sich um Hardware oder Konfiguration kümmern zu müssen.
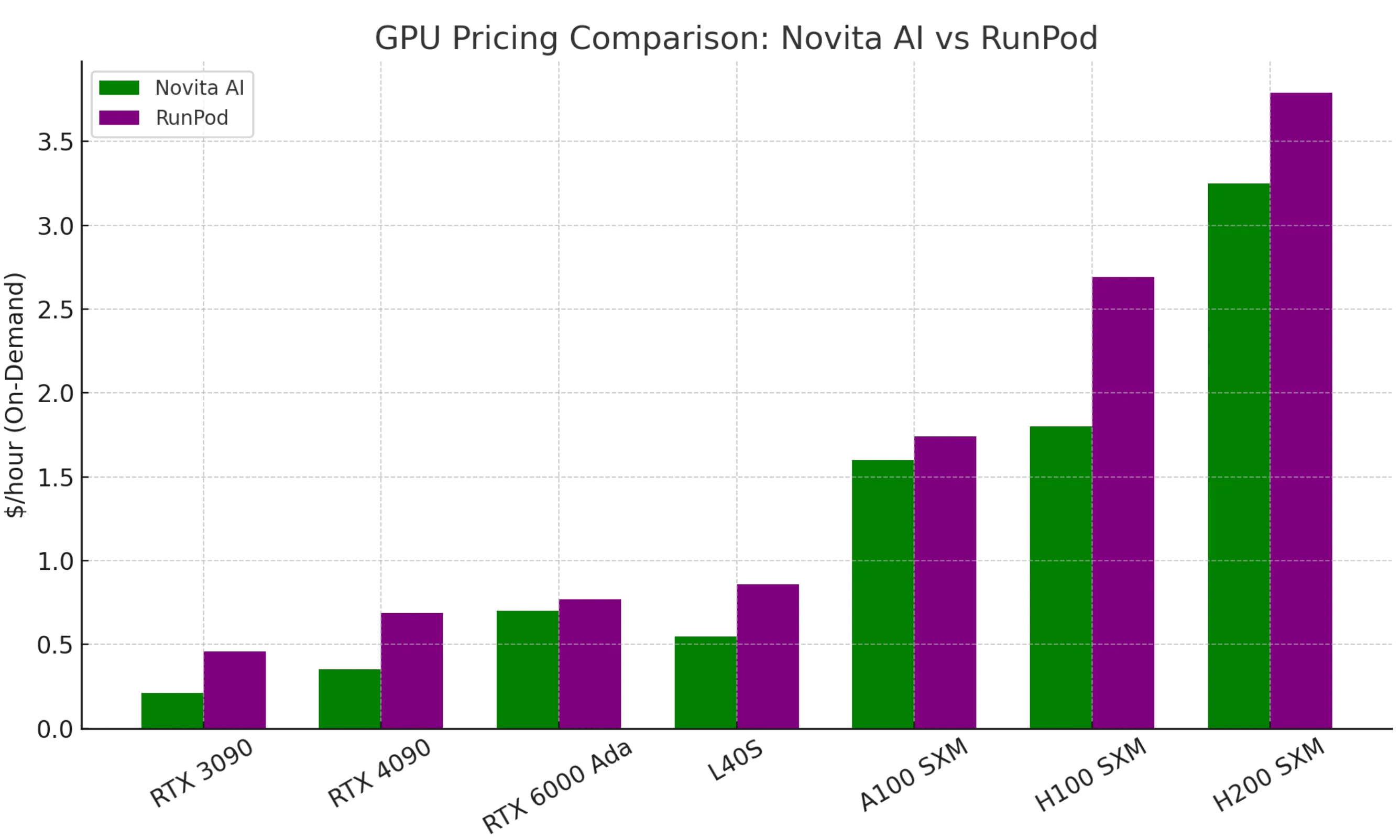
Novitas Hauptverkaufsargument sind niedrige Kosten. Vergleichbare GPUs kosten oft nur halb so viel wie bei RunPod oder Konkurrenten.
- RunPod glänzt mit seiner ausgereiften Entwicklungsumgebung, konfigurierbaren Pods und robuster Unterstützung für Inferenz- und Trainingsworkloads – ideal für ML-Ingenieure oder Entwicklungsteams, die Modelle erstellen und feinabstimmen, sowie Kontrolle, Skalierbarkeit und Infrastrukturflexibilität benötigen.
In diesem Beitrag zerlegen wir die Stärken und Kompromisse jeder Plattform, um Ihnen bei der Entscheidung zu helfen, welche zu Ihrem Projekt passt.
Novita AI Einführung

Novita AI ist eine Cloud-Plattform, die das Bereitstellen von KI-Modellen einfach und erschwinglich macht.
Sie bietet über 200 gebrauchsfertige APIs für Sprache, Vision, Audio und mehr sowie GPU-Cloud-Infrastruktur für benutzerdefinierte Modelle.
Entwickler können KI schnell über einfache REST-APIs integrieren oder GPU-Instanzen starten, ohne sich mit Hardware auseinandersetzen zu müssen. Mit dem Fokus auf kostengünstige, zuverlässige Inferenz hilft Novita AI Indie-Entwicklern und Unternehmen, KI-gestützte Funktionen mühelos bereitzustellen.
RunPod Einführung
RunPod ist eine All-in-One-Cloud-Plattform für KI, die Entwicklern on-Demand-Zugriff auf leistungsstarke GPUs für Training, Feinabstimmung und Bereitstellung von Modellen bietet. Mit GPU-Pods, die in über 30 globalen Regionen (sowohl on-Demand als auch Spot) verfügbar sind, können Nutzer innerhalb von Minuten alles von einem Jupyter-Notebook bis zu einem Multi-Node-GPU-Cluster starten. Entwickelt für ML-Ingenieure und Entwicklungsteams macht RunPod das Skalieren von KI einfach und erschwinglich – kein DevOps erforderlich.
Vergleich der Skalierbarkeit von RunPod und Novita AI
Novita AI bietet Dutzende von APIs, einschließlich LLM-, Bild- und Video-APIs, mit ständig neuen Ergänzungen. Sie können diese direkt im Playground kostenlos ausprobieren. RunPod hingegen stellt keine LLM-APIs out-of-the-box bereit, ermöglicht es Ihnen aber, ein Large Language Model (LLM) mithilfe seiner vorkonfigurierten vLLM-Worker bereitzustellen.
| GPU-Modul | RunPod | Novita AI |
|---|---|---|
| Serverless | ✅ Kurzfristige Inferenz | ✅ Kurzfristige Inferenz |
| Instanz | ✅ GPU-Instanzen | ✅ GPU-Instanzen |
| Speicher | ✅ Persistenter Speicher und Netzwerkspeicher | ✅ Persistenter Speicher und Netzwerkspeicher |
| Bare Metal | ❌ Nicht verfügbar | ✅ Dedizierte physische Server |
| Feinabstimmung | ✅ Integrierter Feinabstimmungsdienst | ❌ Nicht direkt verfügbar |
| Cluster | ✅ Multi-GPU-verteilt | ✅ Multi-GPU-verteilt |
| Region | ✅ Die meisten Regionscluster werden unterstützt | ⚠️ Nur zwei Regionscluster werden unterstützt |
Serverless-Unterschied
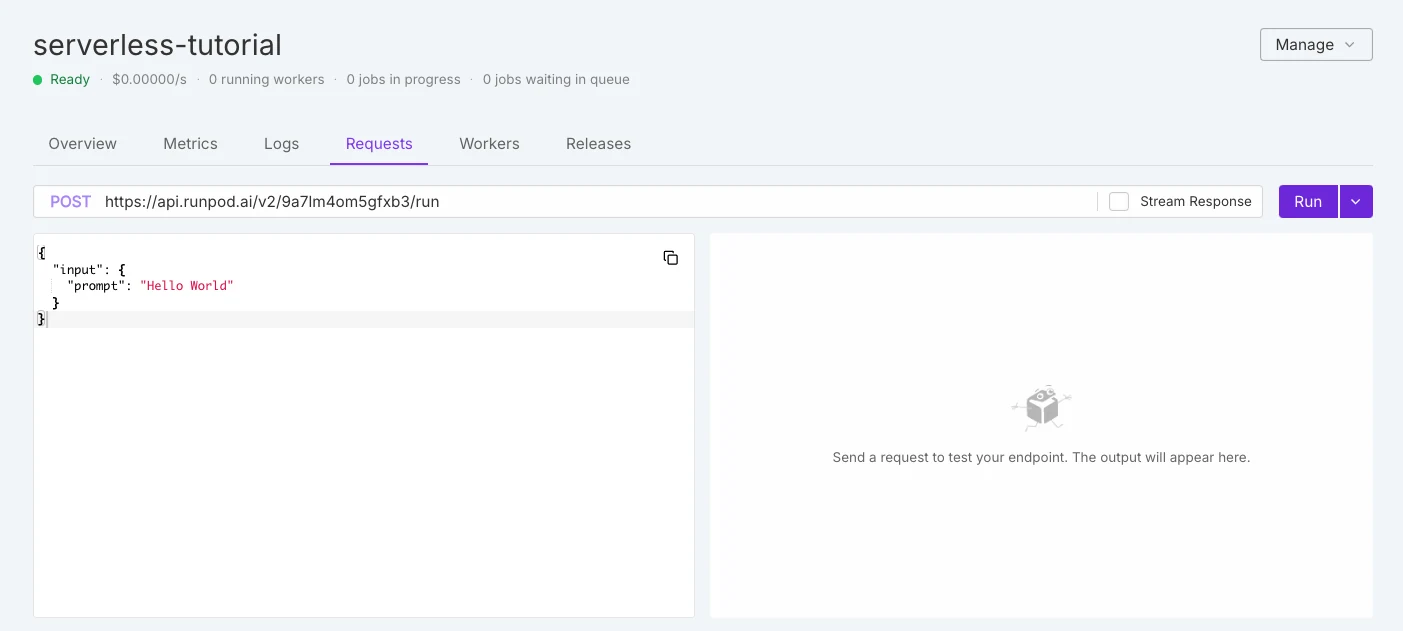
RunPod Serverless
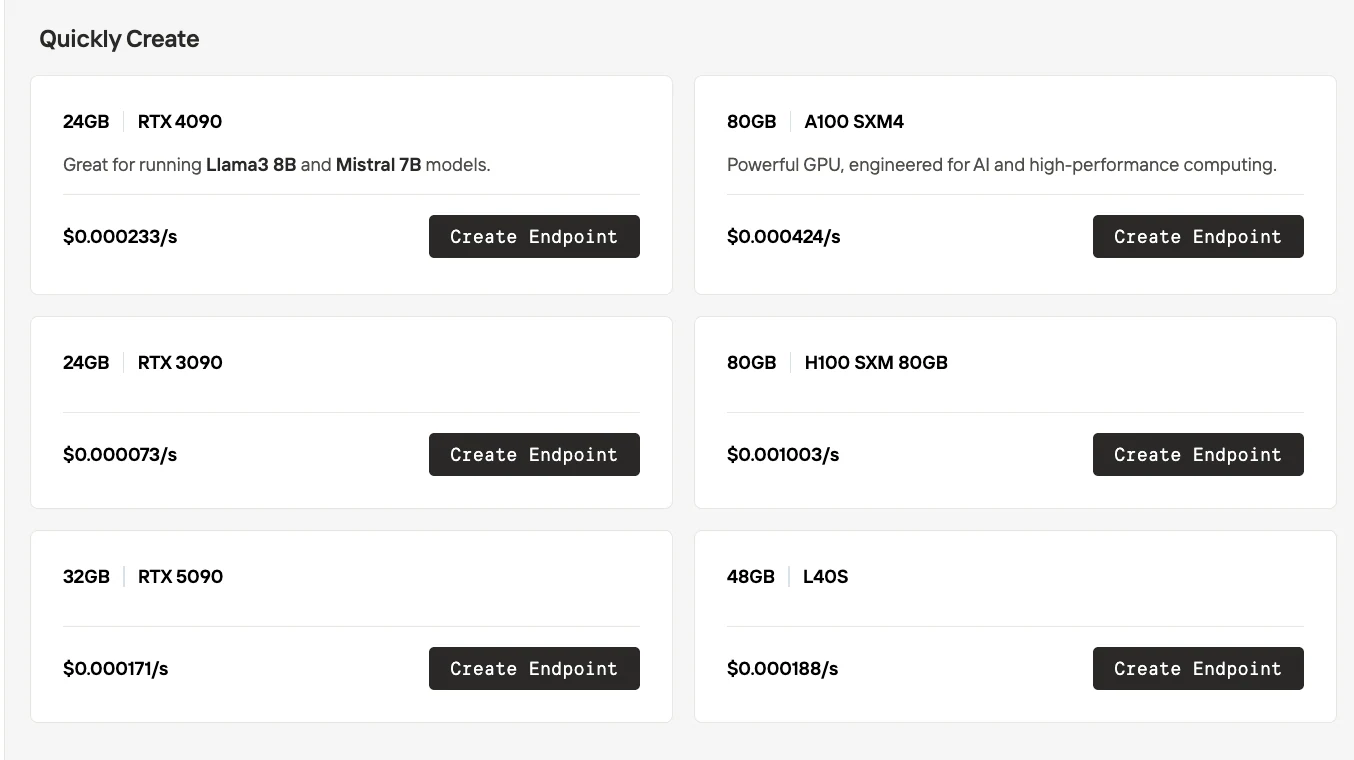
Novita AI Serverless
| Aspekt | RunPod Serverless | Novita AI Serverless |
|---|---|---|
| GPU-Auswahl | Black-Box-Modell – GPUs werden automatisch von der Plattform zugewiesen. Nutzer können den genauen GPU-Typ nicht auswählen. | White-Box-Modell – Nutzer wählen den GPU-Typ (z. B. RTX 3090, 4090, 5090, A100, H100, L40S) explizit vor der Erstellung eines Endpunkts aus. |
| Preisgestaltung | Abrechnung entsprechend dem zur Laufzeit automatisch zugewiesenen GPU-Typ. | Preisgestaltung ist transparent und pro GPU-Typ angegeben (z. B. 0,000073 $/s für RTX 3090, 0,000233 $/s für RTX 4090 usw.). |
| Kontrolle | Einfacher für schnelle Bereitstellungen, aber weniger Flexibilität für Kosten-Leistungs-Optimierung. | Flexibler: Teams können Kosten, Leistung und VRAM-Anforderungen ausbalancieren, indem sie die GPU auswählen. |
Regionsunterschied
- RunPod: Die meisten Regionen unterstützen sowohl Regions- als auch Cluster-Knoten.
- Novita AI: Derzeit unterstützen nur zwei Regionen beide Typen. Novita AI wird jedoch in diesem Quartal die verbesserte Caching-Funktion für Regions-GPUs starten, eine Funktion, die zuvor nur für Unternehmenskunden verfügbar war.
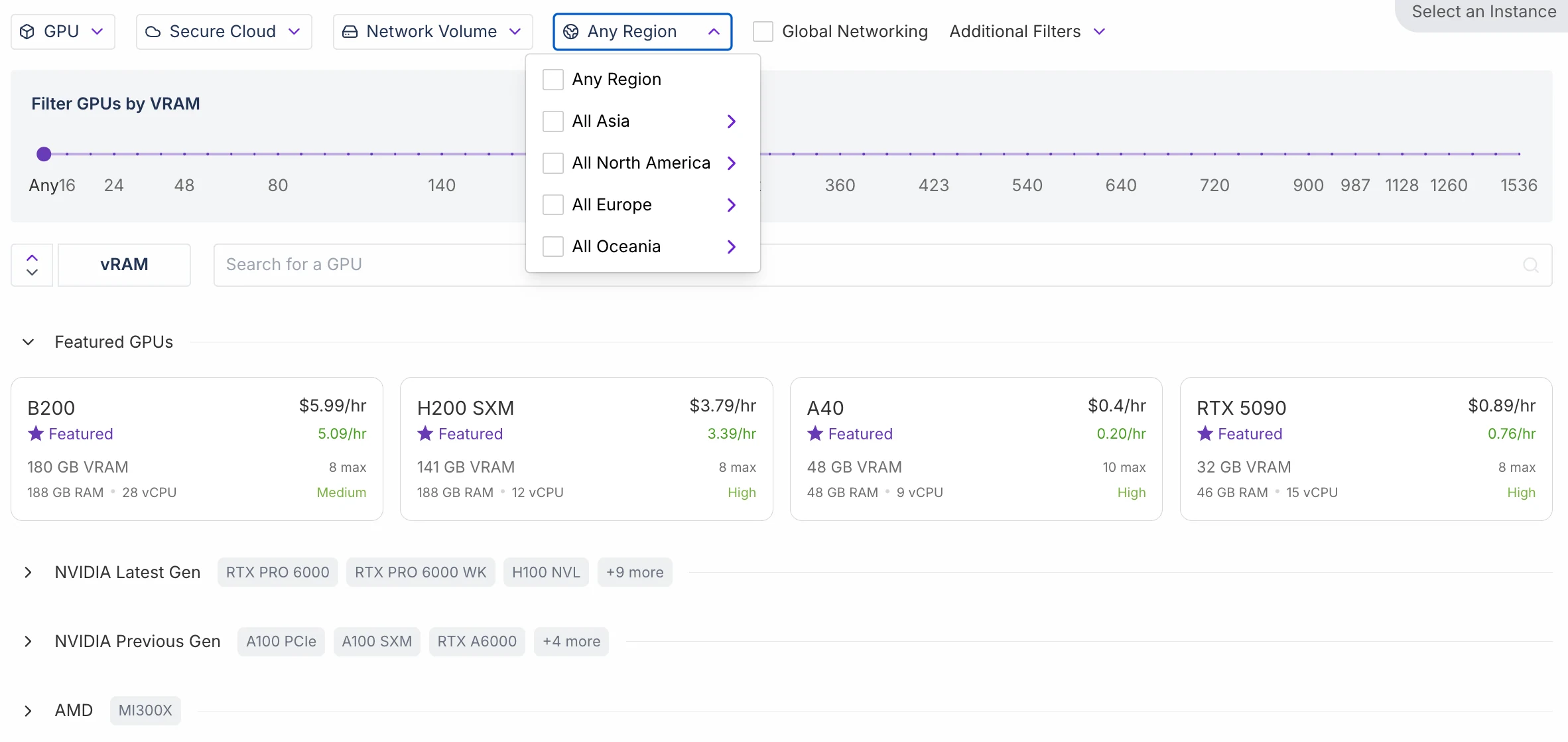
Regions-Knoten
Definition: Zentralisierte, hochwertige Knoten, die für langfristige, stabile Workloads ausgelegt sind.
Hauptmerkmale:
- Zuverlässige, leistungsstarke Rechenleistung mit nachhaltiger Kapazität.
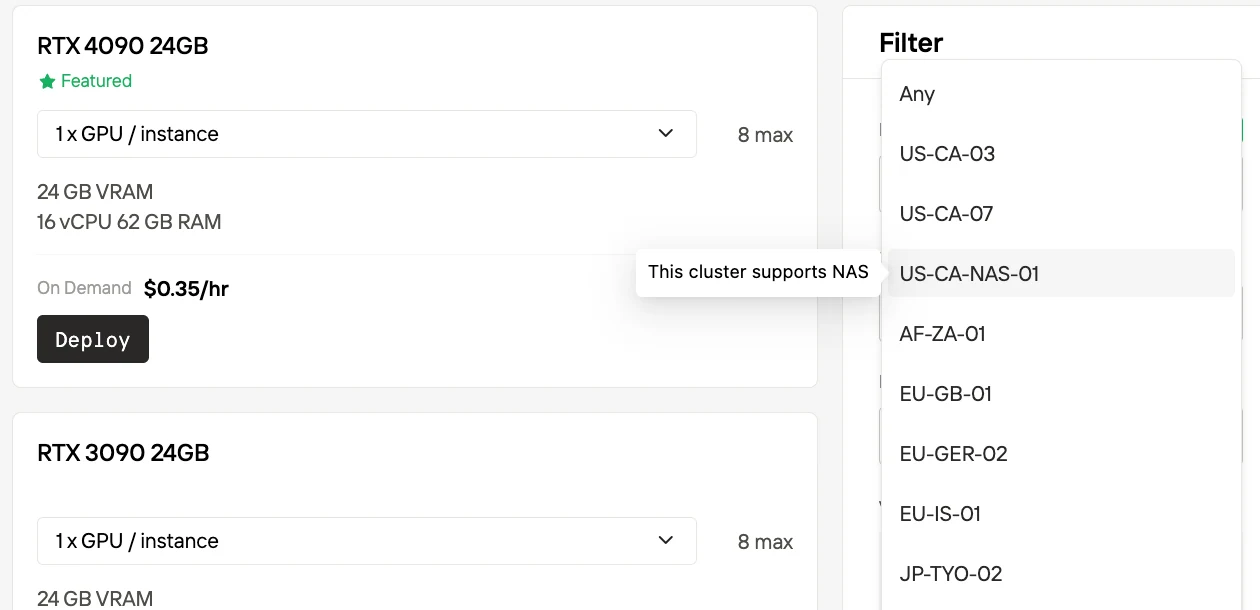
- Enthält NAS (Network-Attached Storage) für gemeinsamen Datenzugriff – geeignet für Workloads, die wiederholten Zugriff auf Datensätze erfordern.
- Dedizierte Leitungen und Zusatzdienste für unternehmensweite Zuverlässigkeit.
- Am besten geeignet für langfristige Aufgaben wie Modelltraining und kontinuierliche Inferenzdienste.
- Hinweis: NAS hier ist Cache-/Freigabespeicher, kein permanenter Speicher – Nutzer müssen Daten dennoch extern sichern.
Analogie: Wie ein dedizierter Büroraum – voll ausgestattet und stabil, ideal für langfristige Projekte.
Cluster-Knoten
Definition: Verteilte, elastische Rechenknoten, die für kurzfristige oder on-Demand-Nutzung ausgelegt sind.
Hauptmerkmale:
- Kein NAS, kein langfristiges Caching oder Speicher.
- Keine dedizierten Leitungen; Knoten sind verteilter und flexibler.
- Optimiert für kurzfristige, groß angelegte elastische Berechnungen (z. B. einmalige Experimente, temporäre parallele Aufgaben).
- Kosteneffizienter, aber weniger geeignet für dauerhafte Workloads.
Analogie: Wie ein gemeinsamer Co-Working-Space – einfach zu nutzen, flexibel und erschwinglich, aber nicht zur dauerhaften Nutzung gedacht.
Vergleich der Benutzerfreundlichkeit von RunPod und Novita AI (GPU-Instanz als Beispiel)
Novita AI
Schritt 1. Vorlage auswählen / Vorlage erstellen und GPU auswählen
- Wählen Sie eine vorkonfigurierte Vorlage (mit GPU-Treibern, CUDA/cuDNN, Frameworks und Laufzeitumgebung) oder erstellen Sie Ihre eigene benutzerdefinierte Vorlage und wählen Sie GPU-Typen und Mengen aus!
Schritt 2. Datenträger und Konfiguration bestätigen
- Überprüfen und passen Sie die technische Einrichtung an: GPU-Typ (z. B. RTX 4090, VRAM, CPU, RAM), Container-Image, Startbefehl, Umgebungsvariablen, exponierte Ports und Datenträgergröße.
Schritt 3. Zahlung bestätigen
- Wählen Sie den Abrechnungsmodus (On-Demand vs. Spot oder 1–12-monatiges Abonnement) und überprüfen Sie die Preisübersicht (GPU-Kosten pro Stunde, Datenträgerkosten pro Tag, monatliche Gesamtkosten).
RunPod
Schritt 1. GPU auswählen
- Durchsuchen Sie verfügbare GPU-Typen (z. B. B200, H200, A40, RTX 5090). Sie können nach VRAM, Region oder anderen Attributen filtern.
Schritt 2. Instanz konfigurieren
- Was es ist: Passen Sie Umgebungs- und Laufzeitoptionen, Datenträgervolumen und zusätzliche Optionen wie Verschlüsseltes Volumen, SSH-Terminalzugriff und die Option, ein Jupyter-Notebook automatisch zu starten, an.
RunPod hat über 50 vorkonfigurierte Vorlagen, sodass Sie keine komplexen Parameter anpassen müssen.
Schritt 3. Preisplan auswählen
- Wählen Sie, wie Sie für die Instanz zahlen möchten.
- Verfügbare Optionen:
- On-Demand
- 3-Monats-Sparplan
- 6-Monats-Sparplan
- 12-Monats-Sparplan
- Spot
Vergleich der Preispläne von RunPod und Novita AI
| Preisaspekt | RunPod | Novita AI |
|---|---|---|
| Kostenlose Stufe / Guthaben | Keine dauerhafte kostenlose GPU-Stufe. Neue Nutzer können Testguthaben erhalten, und qualifizierte Startups können bis zu 1.000 kostenlose H100-Stunden über das Startup-Programm erhalten. |
Keine dauerhafte kostenlose Stufe. Novita hat ebenfalls ein Startup-Programm (sie werben mit bis zu 10.000 $ an kostenlosen Guthaben für qualifizierte Startups) |
| GPU-Instanzpreis | GPU-Instanzen haben stündliche Tarife (Abrechnung pro Minute). | GPU-Instanzen haben stündliche Tarife (Abrechnung pro Minute). |
| Spot-Preis | Niedriger als der On-Demand-GPU-Preis | 50 % des On-Demand-GPU-Preises |
| Serverless-Preis | /Worker/sec |
| Speichertyp | Novita AI (pro GB/Tag) | RunPod (pro GB/Monat) |
|---|---|---|
| Container-Datenträger | 0,005 $/GB/Tag, enthält 60 GB kostenloses Kontingent | 0,10 $/GB/Monat |
| Persistenter (Volume-)Datenträger | 0,005 $/GB/Tag | 0,10 $/GB/Monat für laufende Pods (gleich wie Container-Datenträger) 0,20 $/GB/Monat für beendete Pods |
| Netzwerk-Volume (Cloud-Speicher) | 0,002 $/GB/Tag | 0,07 $/GB/Monat (<1 TB) 0,05 $/GB/Monat (≥1 TB) |
Auf RunPod wird Speicher pro Sekunde abgerechnet, nicht als feste monatliche Gebühr. Der Tarif von „0,10 $ pro GB pro Monat“ ist nur ein Richtwert: Wenn Sie 1 GB für volle 30 Tage speichern, kostet das ca. 0,10 $. Wenn Sie es nur für wenige Tage oder Stunden speichern, werden die Kosten sekundengenau anteilig berechnet, sodass Sie viel weniger zahlen.
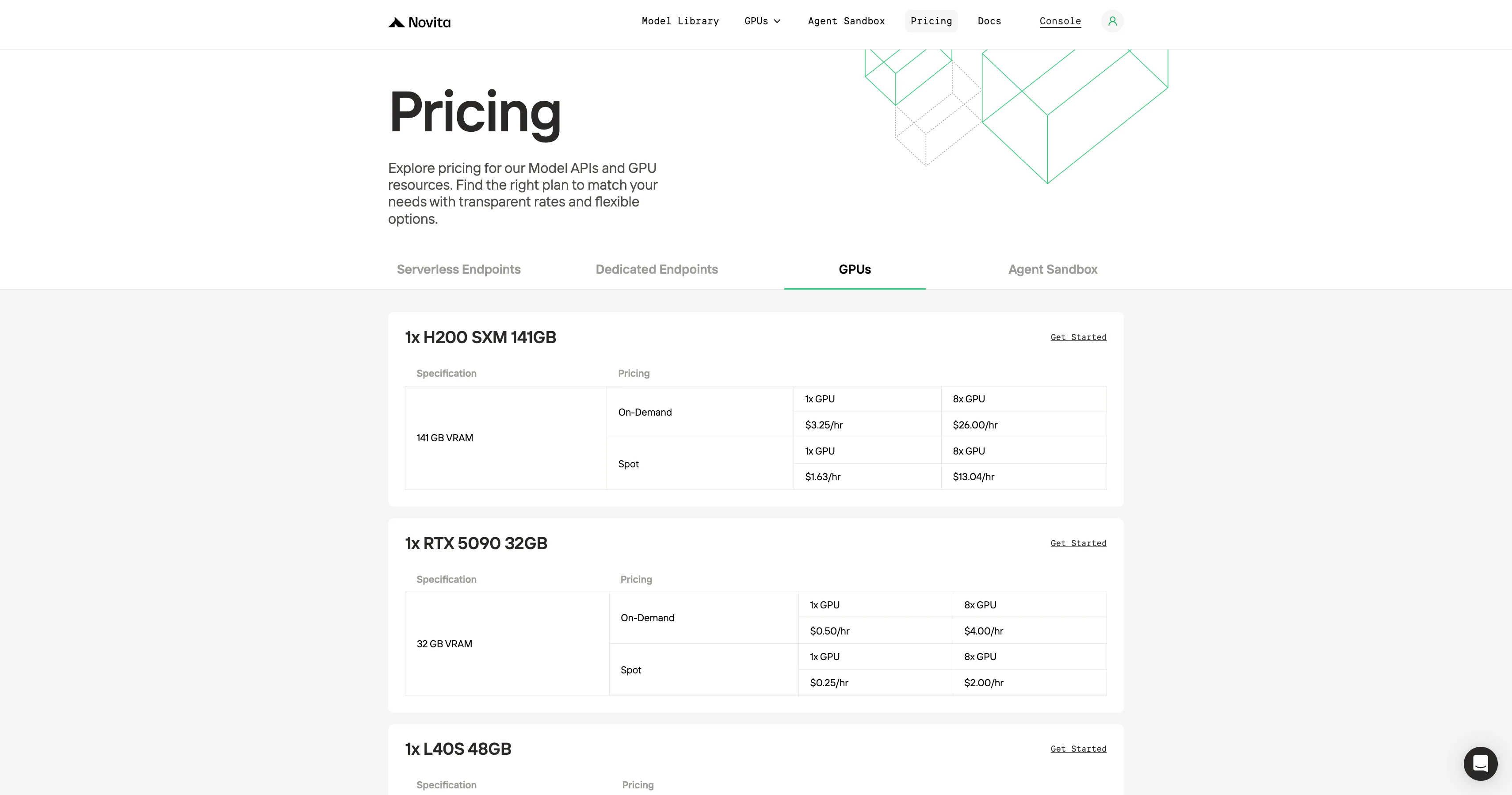
GPU-On-Demand-Preisvergleich
Novitas Hauptverkaufsargument sind niedrige Kosten. Vergleichbare GPUs kosten oft nur halb so viel wie bei RunPod oder Konkurrenten.
Ist RunPod oder Novita AI besser für kleine Teams?
| Aspekt | RunPod | Novita AI | Was ist besser für kleine Teams? |
|---|---|---|---|
| GPU-Instanzen (Benutzerfreundlichkeit) | Schritt 1: GPU auswählen Schritt 2: Instanz konfigurieren. Über 50 vorkonfigurierte Vorlagen Schritt 3: Preisplan auswählen |
Schritt 1: Vorlage auswählen oder erstellen + GPU. Schritt 2: Datenträger, Laufzeit, Umgebungsvariablen konfigurieren. Schritt 3: Zahlung bestätigen |
Beide sind unkompliziert. RunPod hat mehr Vorlagen; Novita betont Anpassung und niedrigere Kosten. |
| Serverless | Black-Box-GPU-Zuweisung, schnelle Bereitstellung, aber Preisgestaltung ist weniger transparent. | White-Box-GPU-Auswahl, transparente Preisgestaltung pro GPU, ermöglicht Kostenkontrolle. | Novita AI – klarere Preisgestaltung, besseres Kosten-Leistungs-Verhältnis. |
| Region | Ausgereifte Abdeckung in vielen Regionen, stabil für langfristige Workloads, aber GPU-Auswahl ist begrenzt und Preisgestaltung undurchsichtig. | Regions-Knoten mit transparenter GPU-Preisgestaltung, Caching-Funktionen kommen bald, aber derzeit weniger Regionen unterstützt. | Wenn Sie Stabilität und globale Abdeckung benötigen → RunPod. |
| Skalierbarkeit | Unterstützt Multi-GPU-Cluster, Feinabstimmungsdienst, persistenter Speicher. Geeignet für verteiltes Training. | Unterstützt Multi-GPU-Cluster, persistenter Speicher. | RunPod besser für groß angelegtes Training und Feinabstimmung |
| Preisgestaltung | GPU-Instanzen werden pro Minute abgerechnet. Spot ist günstiger als On-Demand. |
In der Regel 50 % günstiger als RunPod. | Novita ist in der Regel viel günstiger – vorteilhaft für kleine Teams mit begrenztem Budget. |
| APIs | ❌Keine vorkonfigurierten LLM-APIs, unterstützt aber die Bereitstellung von vLLM-Workern. | ✅Über 200 gebrauchsfertige APIs (LLM, Bild, Video, Einbettungen usw.), direkt per REST aufrufbar. | Novita AI ist besser für Teams, die schnelle KI-Funktionen ohne Training wünschen. |
Für kleine Teams/Startups ist Novita AI in der Regel die bessere Option aufgrund niedrigerer Preise, GPU-Flexibilität und umfangreichen vorkonfigurierten APIs.
RunPod ist stärker für Teams, die sich auf groß angelegtes Training, Feinabstimmung und GitHub-integrierte Workflows konzentrieren.
Wie greife ich auf RunPod zu?
Der Einstieg in RunPod ist unkompliziert. Hier ist eine Schritt-für-Schritt-Anleitung für Entwickler:
- Registrieren: Gehen Sie zu runpod.io und erstellen Sie ein Konto (Sie können sich mit einer E-Mail-Adresse registrieren oder Single-Sign-On mit Diensten wie Google/GitHub verwenden). Nach der Verifizierung Ihres Kontos haben Sie Zugriff auf das RunPod-Dashboard.
- GPU-Pod starten: Navigieren Sie in der RunPod-Konsole zum Bereich „Cloud GPUs“ oder „Pods“, um Ihre erste GPU-Instanz bereitzustellen. Sie werden typischerweise:
- Eine Region (z. B. US West, EU usw.) und einen GPU-Typ (z. B. RTX 4090, A100) aus der Liste der verfügbaren Instanzen auswählen. Der Preis für jede wird bei der Auswahl angezeigt.
- Eine Umgebungsvorlage auswählen. RunPod bietet vorkonfigurierte Vorlagen (wie Ubuntu mit CUDA, Jupyter-Notebook, Stable Diffusion usw.), oder Sie können Ihr eigenes Docker-Image verwenden. Für einen schnellen Start wählen Sie etwas wie eine Jupyter-Notebook-Vorlage, sodass Sie eine fertige IDE haben.
- Klicken Sie auf Bereitstellen. Innerhalb von Sekunden bis einer Minute startet RunPod Ihren Container auf der ausgewählten GPU. Sie sehen, dass der Pod-Status im Dashboard auf „Laufend“ wechselt.
- Verbinden und nutzen: Sobald der Pod läuft, können Sie sich mit ihm verbinden. Wenn es sich um eine Jupyter-Vorlage handelt, wird eine URL bereitgestellt, um die Jupyter-Oberfläche in Ihrem Browser zu öffnen (mit GPU-Unterstützung). Für andere Umgebungen können Sie eine Web-Shell öffnen oder SSH verwenden (RunPod gibt Verbindungsdetails in der Benutzeroberfläche an). Jetzt können Sie Ihren Code ausführen oder Ihr Modell auf dieser Remote-GPU trainieren.
- Serverlose Endpunkte (optional): Wenn Ihr Ziel darin besteht, einen Inferenzendpunkt (serverlos) bereitzustellen, verfügt RunPod über einen Bereich für Serverless. Sie würden einen neuen Endpunkt erstellen, ein Modell angeben oder eine vorkonfigurierte Modellserving-Vorlage verwenden und bereitstellen. RunPod gibt Ihnen eine API-Endpunkt-URL. Dieser Endpunkt skaliert automatisch mit eingehenden Anfragen. Dies ist ideal, um eine API für Ihre App bereitzustellen, ohne einen Pod 24/7 laufen zu lassen.
- Verwalten und Überwachen: Im Dashboard können Sie Ihre laufenden Pods, deren Auslastung und Ihre Guthaben/Abrechnungsinformationen einsehen. Sie können Pods stoppen oder beenden, wenn sie nicht verwendet werden, um Geld zu sparen (da die Abrechnung sekundengenau erfolgt). Sie können auch automatische Abschaltrichtlinien einstellen (z. B. einen Pod nach einer Stunde Leerlauf beenden). Alles kann zunächst über die Web-Benutzeroberfläche verwaltet werden. Für fortgeschrittene Nutzer erkunden Sie die RunPod-CLI und -API, um Bereitstellungen zu skripten, wenn Ihr Team wächst.
Wie greife ich auf Novita AI zu?
GPU-Leitfaden
Schritt 1: Konto registrieren
Erstellen Sie Ihr Novita AI-Konto über unsere Website. Nach der Registrierung navigieren Sie zum Bereich „Entdecken“ in der linken Seitenleiste, um unsere GPU-Angebote einzusehen und Ihre KI-Entwicklungsreise zu beginnen.

Probieren Sie Novita AI jetzt aus
Schritt 2: Vorlagen und GPU-Server erkunden
Wählen Sie Vorlagen wie PyTorch, TensorFlow oder CUDA, die zu Ihren Projektanforderungen passen.
Wählen Sie dann Ihre bevorzugte GPU-Konfiguration und GPU-Mengen aus – Optionen umfassen die leistungsstarken L40S, RTX 4090 oder A100 SXM4, jeweils mit unterschiedlichen VRAM-, RAM- und Spezifikationen.
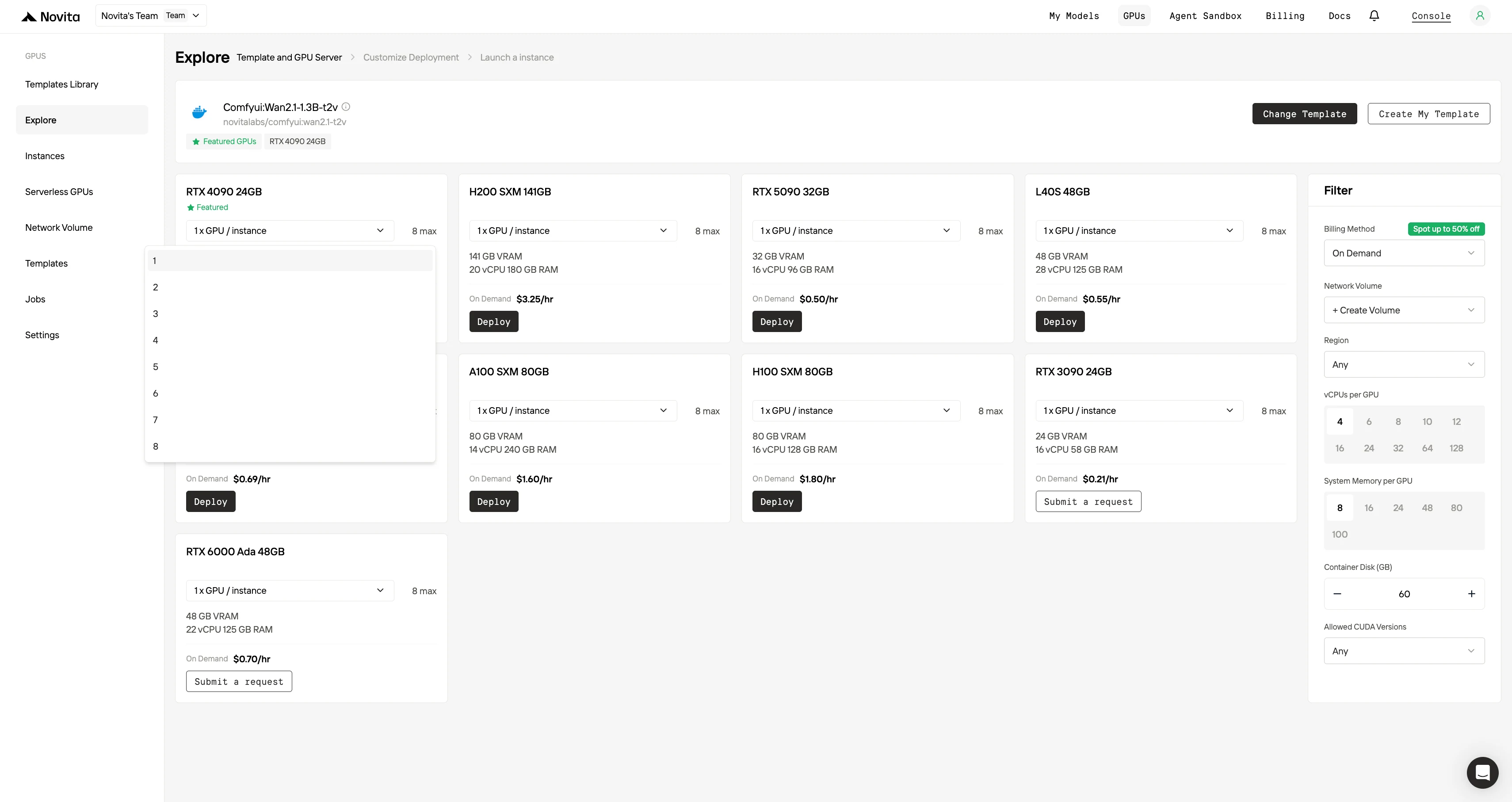
Schritt 3: Ihre Bereitstellung anpassen
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen zu gewährleisten.
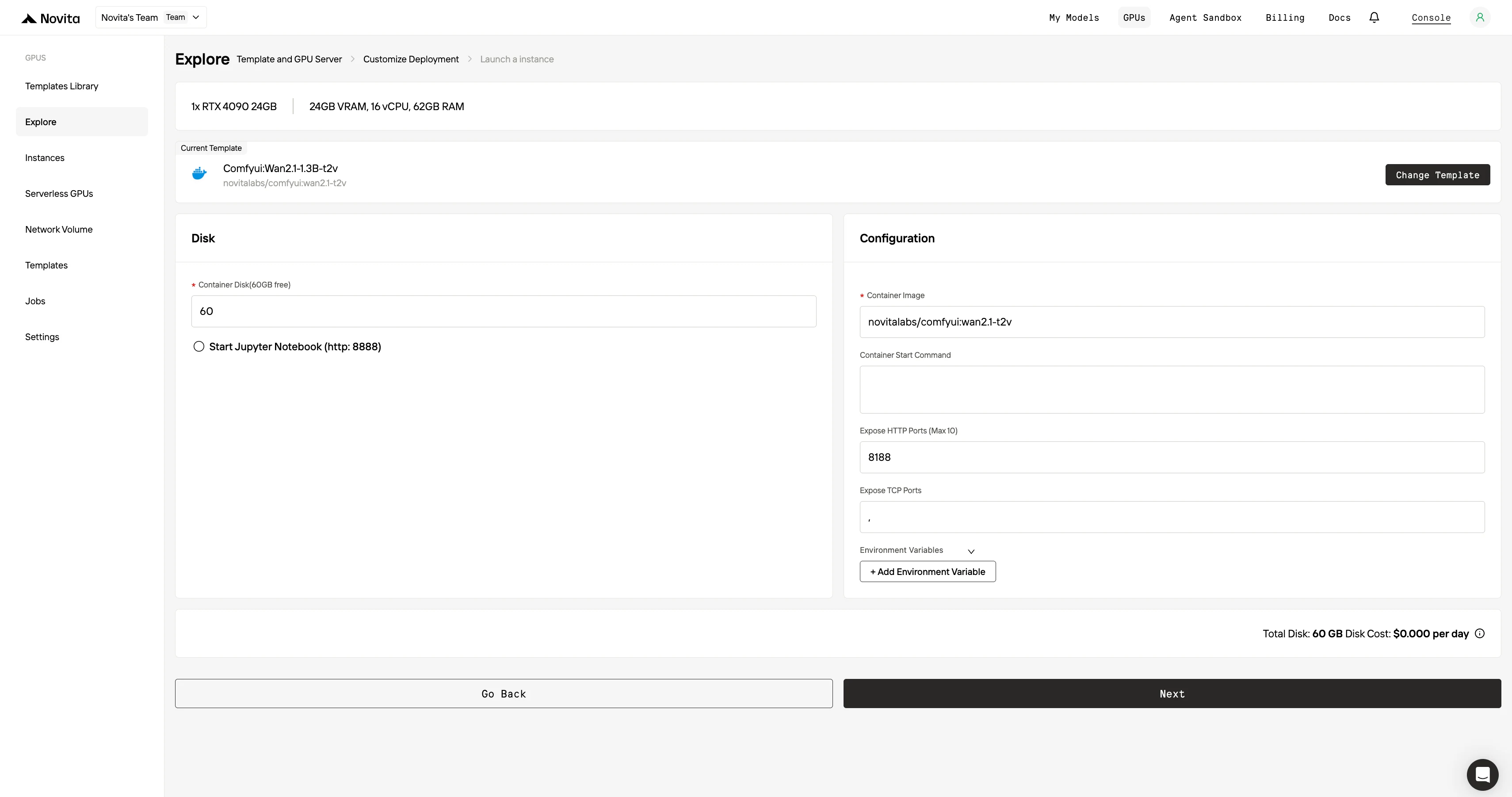
Schritt 4: Instanz starten
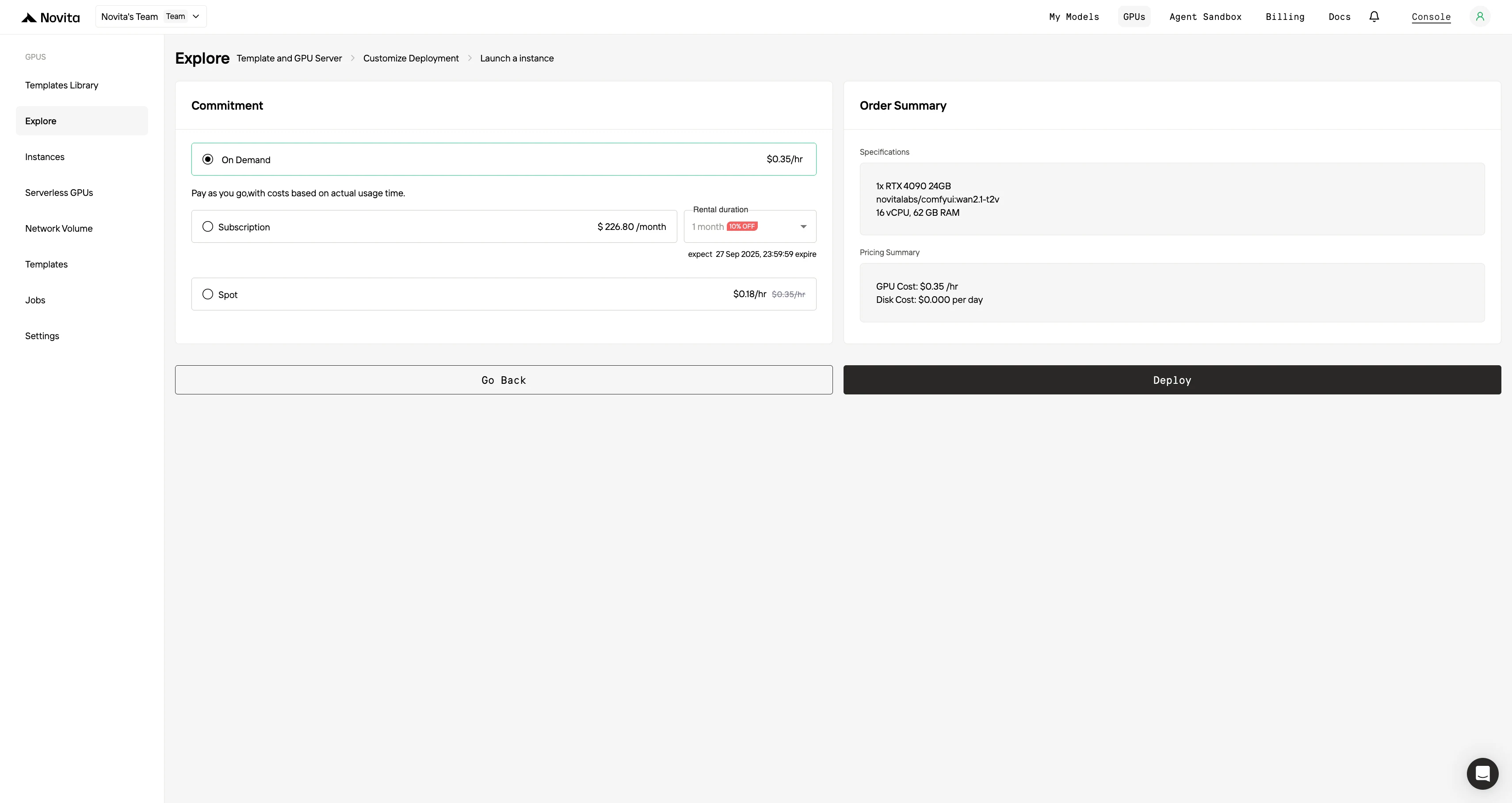
Wählen Sie „Instanz starten“, um Ihre Bereitstellung zu beginnen. Ihre leistungsstarke GPU-Umgebung ist innerhalb von Minuten einsatzbereit, sodass Sie sofort mit Ihren Machine-Learning-, Rendering- oder Rechenprojekten beginnen können.
API-Leitfaden (am Beispiel von Kimi K2)
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

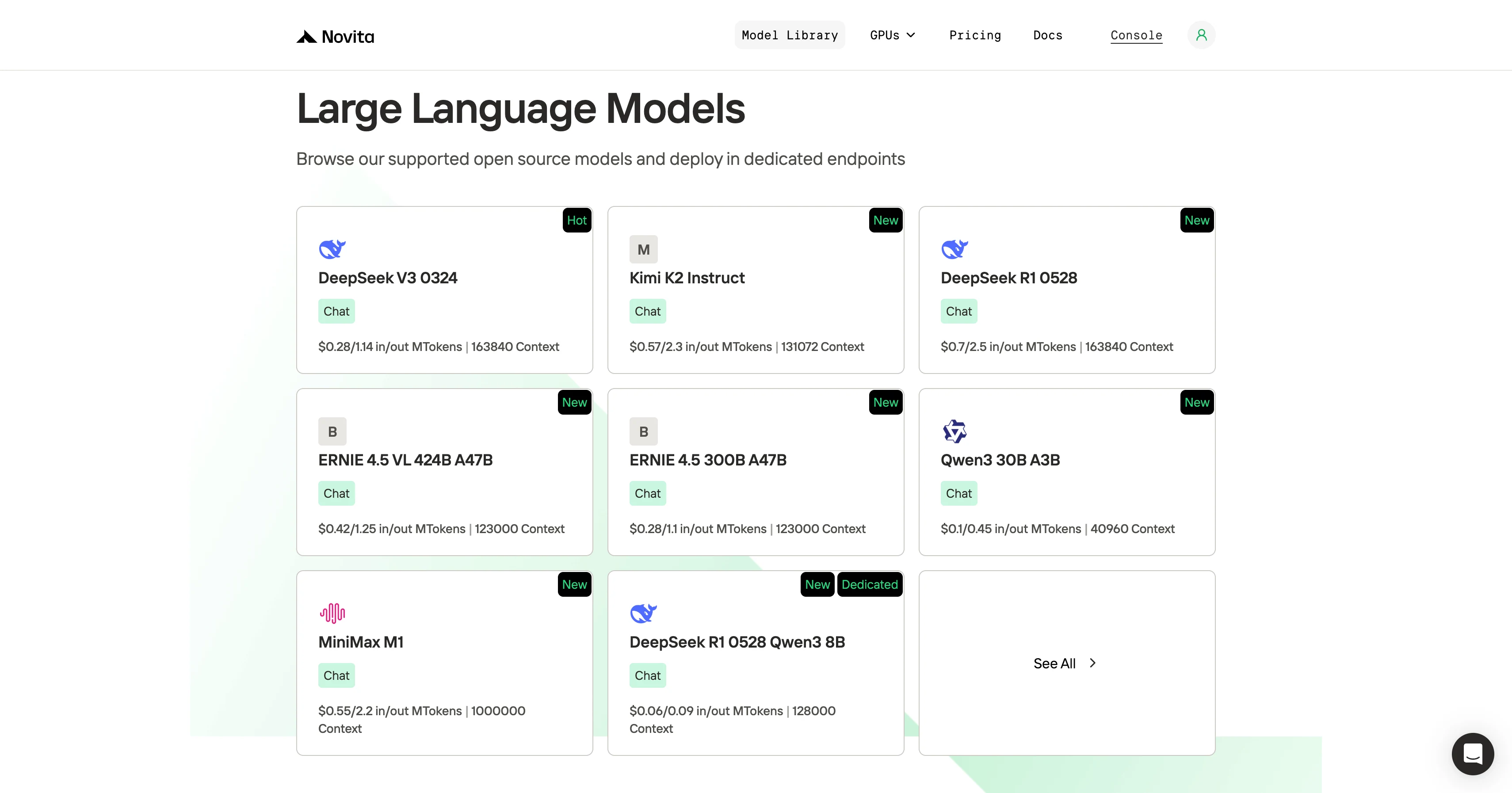
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
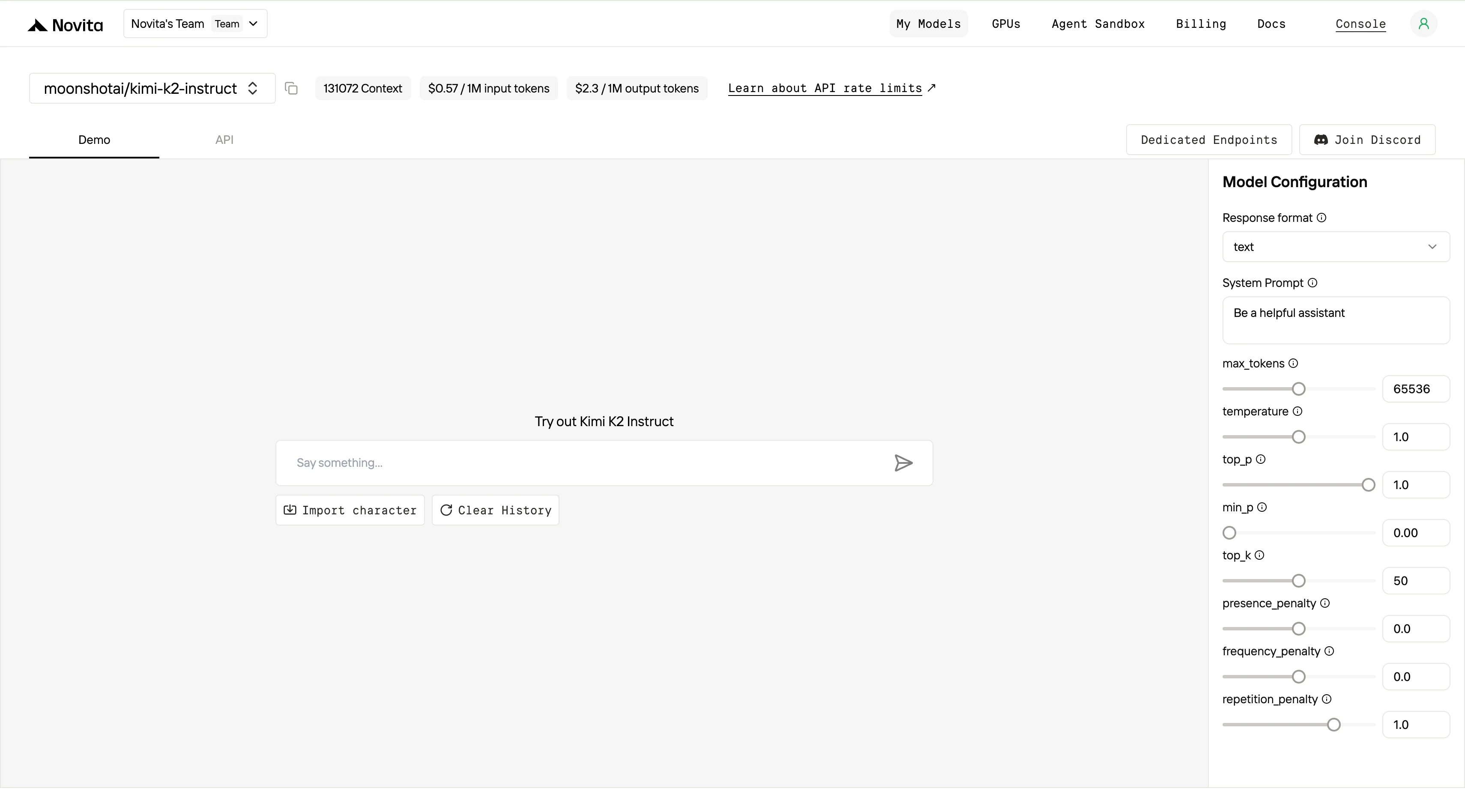
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Um sich bei der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie zur Seite „Einstellungen“, dort können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Verwendung des Agent Sandbox (optional): Novita verfügt auch über eine Agent Sandbox-Funktion, die über das Dashboard zugänglich ist. Diese ermöglicht es Ihnen, KI-Agenten oder Code in einer vollständig verwalteten Sandbox-Umgebung mit Internetisolierung auszuführen. Wenn Ihr Anwendungsfall Dinge wie die Auswertung von von einem KI-Agenten generierten Code umfasst, ist dies praktisch. Sie können dies erkunden, sobald Sie mit den Grundlagen vertraut sind.
Wann Sie Novita AI wählen sollten
- Knappe Budget – Novita ist in der Regel ca. 50 % günstiger als RunPod für die GPU-Nutzung, mit sehr erschwinglichem Speicher und großzügigen kostenlosen Guthaben für Startups.
- Sie benötigen schnelle, problemlose Funktionalität – Mit über 200 vorkonfigurierten APIs (LLM, Bild, Audio, Video) ist es ideal, wenn Sie KI-gestützte Funktionen wünschen, ohne Infrastruktur verwalten zu müssen.
- Sie bevorzugen Einfachheit und Geschwindigkeit – Perfekt für die schnelle Integration von KI, insbesondere wenn Training/Feinabstimmung keine Priorität ist.
Am besten geeignet für: Indie-Entwickler, Startups, Produktteams, die eine schnelle KI-Integration benötigen, ohne sich um Hardware oder Konfiguration kümmern zu müssen.
Wann Sie RunPod wählen sollten
- Sie planen komplexe Trainingsworkflows – Bietet starke Unterstützung für Multi-GPU-Cluster, persistenten Speicher und integrierte Feinabstimmungsdienste.
- Sie benötigen Skalierbarkeit oder robuste Rechenleistung – Perfekt für das Training großer Modelle, Multi-Node-Setups oder langfristige Experimente.
- Sie bevorzugen Standardisierung über Regionen hinweg – Seine Präsenz in über 30 globalen Regionen und die umfangreiche Vorlagenbibliothek vereinfachen Bereitstellungen.
- Sie arbeiten eng mit Code/GitHub-Repos zusammen – Integrierte Unterstützung für Serverless Reps macht es einfach, direkt aus Open-Source-Projekten bereitzustellen.
Häufig gestellte Fragen
Kann ich Multi-GPU-Cluster bereitstellen?
Nur RunPod unterstützt dies nativ über die Funktion Instant Clusters. Novita AI unterstützt derzeit die Skalierung über Serverless und vertikale Skalierung, aber keine benutzerverwalteten Cluster.
Was ist günstiger für den Betrieb einer 4090- oder A100-GPU?
Novita AI ist in der Regel günstiger – es bietet RTX 4090 für ca. 0,35 $/Stunde und A100 für ca. 1,2 $/Stunde (mit Spot-Preisen sogar noch niedriger). RunPod bietet mehr Regionen und Flexibilität, kostet aber pro Stunde etwas mehr.
Bietet RunPod eine LLM-API wie OpenAI?
L40S. Seine 300–350 W TDP und starke Leistung pro Watt machen es zu einer besseren Option für stromsensitive Bereitstellungen. H100 (bis zu 700 W SXM5) erfordert erhebliche Infrastruktur.Ja. RunPod bietet Serverless-Endpunkte mit vLLM, mit denen Sie Hugging Face-Modelle bereitstellen und über OpenAI-ähnliche APIs verfügbar machen können. Sie können diese Endpunkte per REST aufrufen oder sie mit LangChain integrieren.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig erschwingliche und zuverlässige GPU-Cloud für die Erstellung und Skalierung bereitstellt.
Empfohlene Lektüre



