

開発者にとって、適切なクラウドAIプラットフォームを選択する際に重要なのは主に3つ:コスト、使いやすさ、スケーラビリティです。Novita AIとRunPodの両方が、AIモデルのデプロイ、トレーニング、実行をサポートする強力なGPUインフラとツールを提供していますが、それぞれが対応する開発者のニーズは少し異なります。
- Novita AIは、プラグアンドプレイAPIとサーバーレスGPUアクセスによる高速かつ低コストの推論に優れています。ハードウェアや設定を気にせずにAIを迅速に統合したいインディー開発者、スタートアップ、プロダクトチームに最適です。
Novitaの最大のセールスポイントは低コストです。同等のGPUは、RunPodや競合他社と比較して半分の価格であることが多いです。
- RunPodは、成熟した開発環境、設定可能なポッド、推論とトレーニングワークロードの両方に対する強力なサポートを特徴としています。モデルの構築やファインチューニングを行い、制御、スケーラビリティ、インフラの柔軟性を求めるMLエンジニアや開発チームに最適です。
この記事では、各プラットフォームの強みとトレードオフを解説し、どのプラットフォームがあなたのプロジェクトに適しているかを判断するのに役立てます。
Novita AI 概要

Novita AIは、AIモデルのデプロイを簡単かつ低コストで実現するクラウドプラットフォームです。
言語、ビジョン、オーディオなど向けの200以上のすぐに使えるAPIを提供しているほか、カスタムモデル向けのGPUクラウドインフラも利用可能です。
開発者はシンプルなREST APIでAIを迅速に統合したり、ハードウェアの管理なしでGPUインスタンスを起動したりできます。低コストで信頼性の高い推論に注力するNovita AIは、インディー開発者や企業がAI搭載機能を容易にリリースするのをサポートします。
Runpod 概要
RunPodは、開発者がトレーニング、ファインチューニング、モデルのデプロイ用の強力なGPUをオンデマンドで利用できるオールインワンのAIクラウドプラットフォームです。30以上のグローバルリージョン(オンデマンドとスポットの両方)でGPUポッドを提供しており、ユーザーは数分でJupyterノートブックからマルチノードGPUクラスタまで、あらゆるリソースを迅速に起動できます。MLエンジニアや開発チーム向けに設計されたRunPodは、DevOpsの知識がなくてもAIのスケーリングを簡単かつ低コストで実現します。
RunPodとNovita AIのスケーラビリティ比較
Novita AIは、LLM、画像、動画APIなど数十のAPIを提供しており、新しいAPIが継続的に追加されています。これらはプレイグラウンドで直接無料で試すことができます。RunPodは標準でLLM APIを提供していませんが、事前設定されたvLLMワーカーを使用して大規模言語モデル(LLM)をデプロイできます。
| GPUモジュール | RunPod | Novita AI |
|---|---|---|
| サーバーレス | ✅ 短期間の推論 | ✅ 短期間の推論 |
| インスタンス | ✅ GPUインスタンス | ✅ GPUインスタンス |
| ストレージ | ✅ 永続ストレージとネットワークストレージ | ✅ 永続ストレージとネットワークストレージ |
| ベアメタル | ❌ 利用不可 | ✅ 専用物理サーバー |
| ファインチューニング | ✅ 組み込みファインチューニングサービス | ❌ 直接利用不可 |
| クラスタ | ✅ マルチGPU分散 | ✅ マルチGPU分散 |
| リージョン | ✅ ほとんどのリージョンクラスタがサポート | ⚠️ 2つのリージョンクラスタのみサポート |
サーバーレスの違い
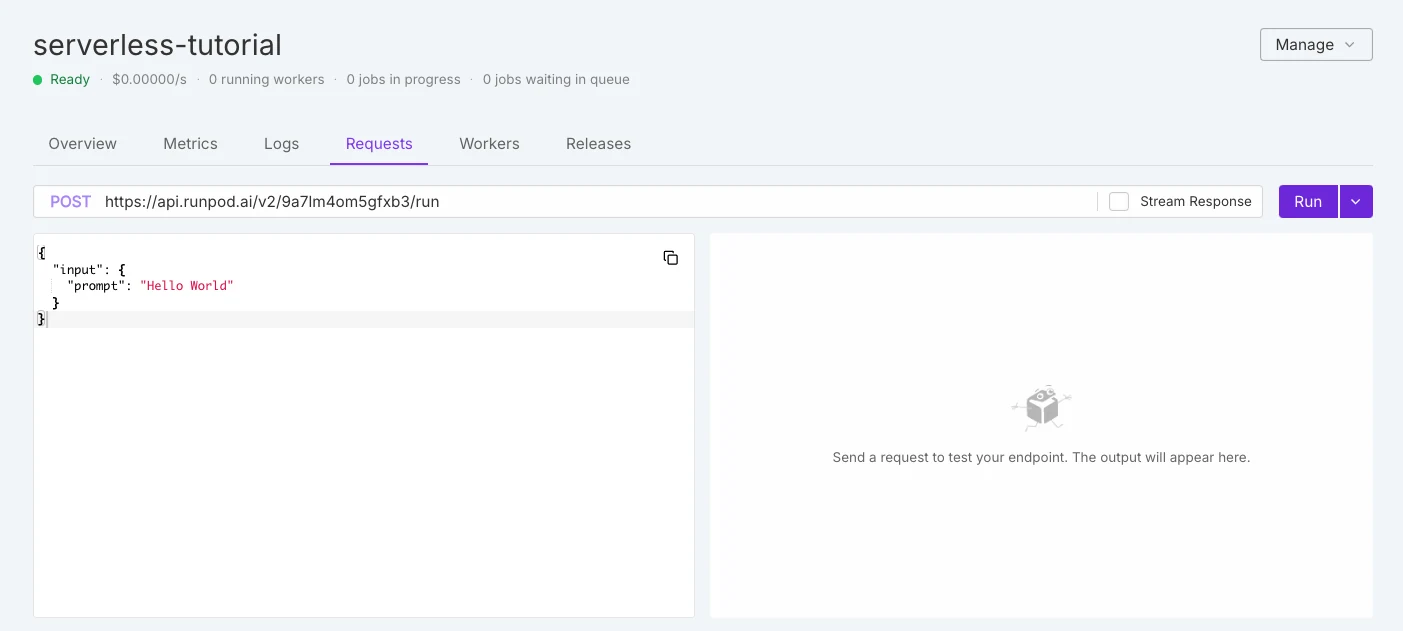
RunPod サーバーレス
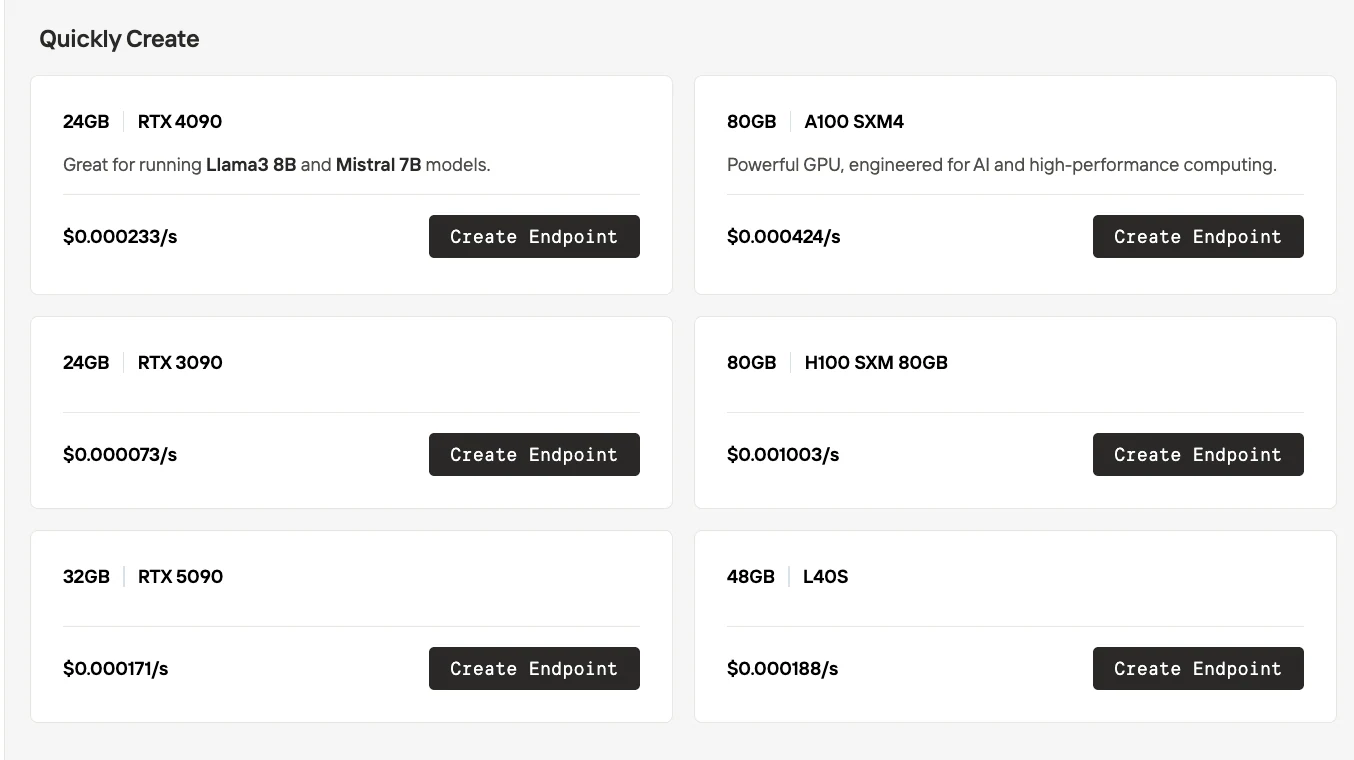
Novita AI サーバーレス
| 項目 | RunPod サーバーレス | Novita AI サーバーレス |
|---|---|---|
| GPU選択 | ブラックボックスモデル — GPUはプラットフォームによって自動的に割り当てられます。ユーザーは正確なGPUの種類を選択できません。 | ホワイトボックスモデル — ユーザーはエンドポイントを作成する前にGPUの種類(例:RTX 3090、4090、5090、A100、H100、L40S)を明示的に選択できます。 |
| 料金 | 実行時に自動的に割り当てられたGPUの種類に応じて課金されます。 | 料金は透明で、GPUの種類ごとに表示されます(例:RTX 3090は$0.000073/秒、RTX 4090は$0.000233/秒など)。 |
| 制御 | 迅速なデプロイには簡単ですが、コストパフォーマンスの最適化の柔軟性は低いです。 | より柔軟:チームはGPUを選択することでコスト、パフォーマンス、VRAMのニーズのバランスを取ることができます。 |
リージョンの違い
- RunPod:ほとんどのリージョンがリージョンノードとクラスタノードの両方をサポートしています。
- Novita AI:現在2つのリージョンのみが両方のタイプをサポートしています。ただし、Novita AIは今四半期に強化されたキャッシング機能を備えたリージョンGPU機能をリリースする予定で、この機能は以前はエンタープライズクライアントのみが利用可能でした。
リージョンノード
定義:長期安定型ワークロード向けに設計された集中型の高品質ノード。
主な特徴:
- 持続可能な容量を持つ、信頼性の高い高性能コンピューティング。
- データセットへの繰り返しアクセスが必要なワークロードに適した、共有データアクセス用のNAS(ネットワーク接続ストレージ)を搭載。
- エンタープライズグレードの信頼性を実現する専用回線と補助サービス。
- モデルトレーニングや継続的な推論サービスなどの長期タスクに最適。
- 注意:ここでのNASはキャッシュ/共有ストレージであり、永続ストレージではありません。ユーザーは引き続き外部にデータをバックアップする必要があります。
例え:専用のオフィススペースのようなもので、完全に装備されており安定しており、長期プロジェクトに最適です。
クラスタノード
定義:短期間またはオンデマンドの使用向けに設計された分散型の弾性コンピューティングノード。
主な特徴:
- NASがなく、長期のキャッシュやストレージもありません。
- 専用回線がなく、ノードはより分散されており柔軟性が高いです。
- 短期間の大規模弾性コンピューティング(例:一回限りの実験、一時的な並列タスク)に最適化されています。
- コスト効率が高いですが、永続的なワークロードにはあまり適していません。
例え:共有のコワーキングスペースのようなもので、使いやすく、柔軟で、手頃な価格ですが、永続的な居住を目的としていません。
RunPodとNovita AIの使いやすさ比較(GPUインスタンスを例に)
Novita AI
ステップ1:テンプレートを選択/作成し、GPUを選択
- 事前構築されたテンプレート(GPUドライバ、CUDA/cuDNN、フレームワーク、ランタイムが事前設定済み)を選択するか、独自のカスタムテンプレートを作成し、GPUの種類と数量を選択してください!
ステップ2:ディスクと設定を確認
- 技術的な設定を確認・調整します:GPUの種類(例:RTX 4090、VRAM、CPU、RAM)、コンテナイメージ、起動コマンド、環境変数、公開ポート、ディスクサイズ。
ステップ3:支払いを確認
- 課金モード(オンデマンド vs スポット、または1〜12ヶ月のサブスクリプション)を選択し、料金の概要(GPUの時間あたり料金、ディスクの日あたり料金、月額合計)を確認します。
RunPod
ステップ1:GPUを選択
- 利用可能なGPUの種類(例:B200、H200、A40、RTX 5090)を閲覧します。VRAM、リージョン、その他の属性でフィルタリングできます。
ステップ2:インスタンスを設定
- 内容:環境とランタイムオプション、ディスクボリュームサイズ、ボリュームの暗号化、SSHターミナルアクセス、Jupyter Notebookの自動起動の有無などの追加オプションを調整します。
RunPodには50以上の事前設定テンプレートがあるため、複雑なパラメータをカスタマイズする必要がありません。
ステップ3:料金プランを選択
- インスタンスの支払い方法を選択します。
- 利用可能なオプション:
- オンデマンド
- 3ヶ月節約プラン
- 6ヶ月節約プラン
- 1年節約プラン
- スポット
RunPodとNovita AIの料金プラン比較
| 料金項目 | RunPod | Novita AI |
|---|---|---|
| 無料ティア/クレジット | 恒久的な無料GPUティアはありません。 新規ユーザーはtrialクレジットを取得でき、対象となるスタートアップはスタートアッププログラムを通じて最大1,000時間の無料H100利用時間を受け取れます |
恒久的な無料ティアはありません。 Novitaにもスタートアッププログラムがあり(対象となるスタートアップには最大10,000ドルの無料クレジットを提供していると宣伝しています) |
| GPUインスタンス料金 | GPUインスタンスは時間あたりの料金(1分単位で課金)です。 | GPUインスタンスは時間あたりの料金(1分単位で課金)です。 |
| スポット料金 | オンデマンドGPU料金より低い | オンデマンドGPU料金の50% |
| サーバーレス料金 | /ワーカー/秒 |
| ストレージ種類 | Novita AI(GBあたり/日) | RunPod(GBあたり/月) |
|---|---|---|
| コンテナディスク | $0.005/GB/日、60GBの無料クォータを含む | $0.10/GB/月 |
| 永続(ボリューム)ディスク | $0.005/GB/日 | 実行中のポッド:$0.10/GB/月(コンテナディスクと同じ) 終了したポッド:$0.20/GB/月 |
| ネットワークボリューム(クラウドストレージ) | $0.002/GB/日 | 1TB未満:$0.07/GB/月 1TB以上:$0.05/GB/月 |
RunPodでは、ストレージは固定の月額料金ではなく秒単位で課金されます。「1GBあたり月額0.10ドル」という料金はあくまで参考値です:1GBを30日間保持した場合、約0.10ドルかかります。数日間または数時間だけ保持する場合は、秒単位で按分されるため、支払額ははるかに少なくなります。
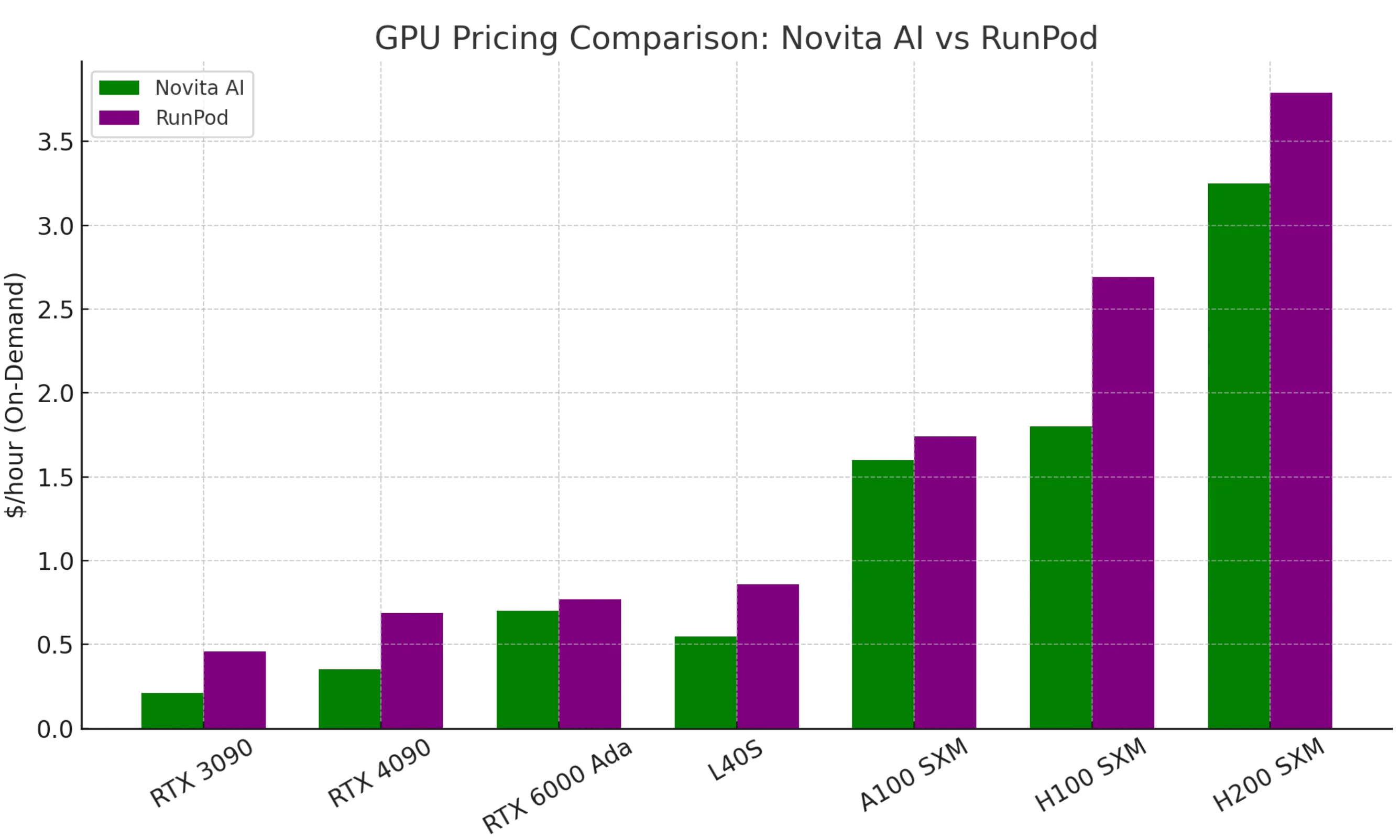
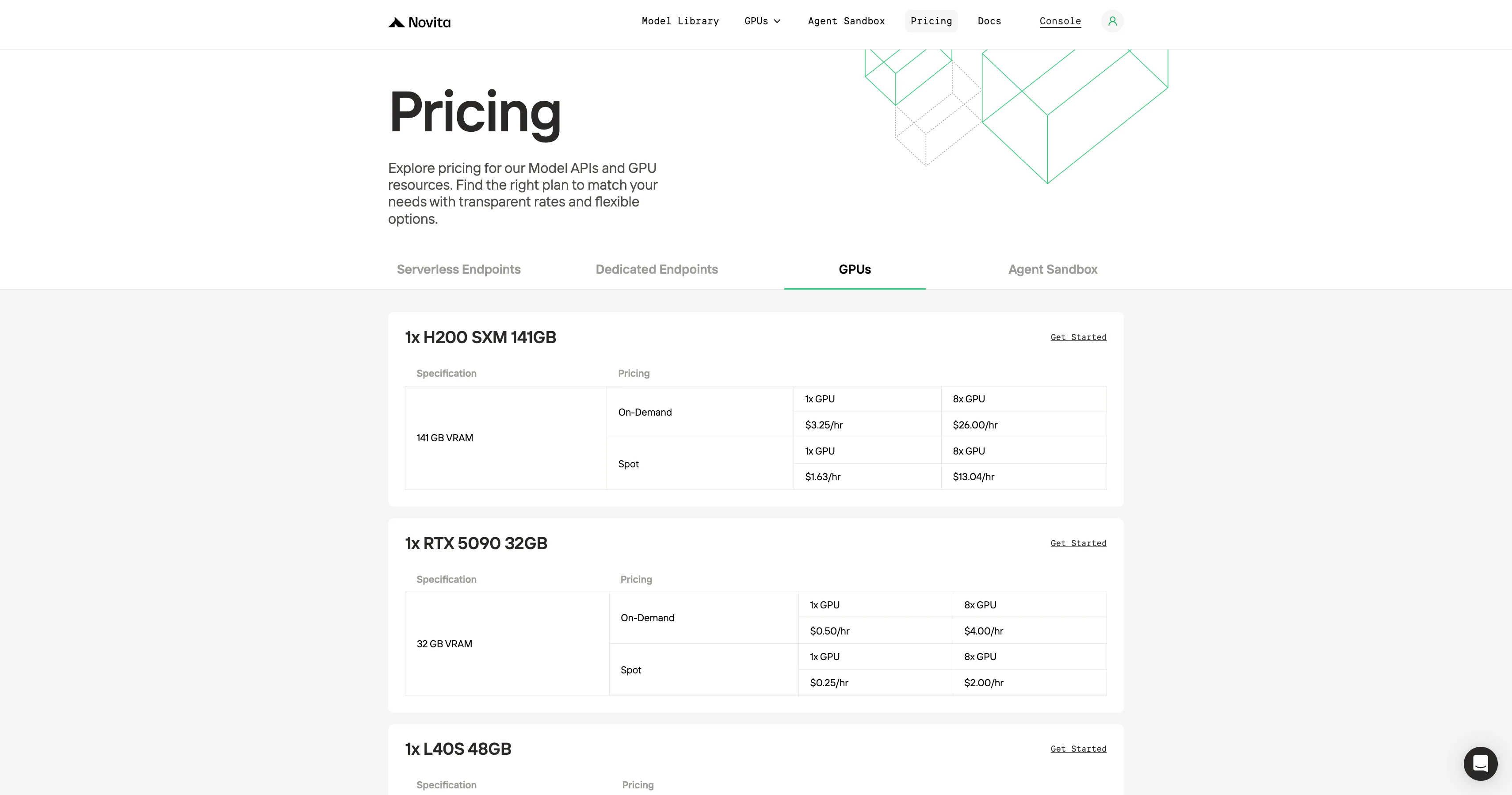
GPUオンデマンド料金比較
Novitaの最大のセールスポイントは低コストです。同等のGPUは、RunPodや競合他社と比較して半分の価格であることが多いです。
小規模チームにはRunPodとNovita AIのどちらが適しているか?
| 項目 | RunPod | Novita AI | 小規模チームに適しているのは? |
|---|---|---|---|
| GPUインスタンス(使いやすさ) | ステップ1:GPUを選択 ステップ2:インスタンスを設定。50以上の事前設定テンプレート ステップ3:料金を選択 |
ステップ1:テンプレートを選択または作成 + GPUを選択。 ステップ2:ディスク、ランタイム、環境変数を設定。 ステップ3:支払いを確認 |
どちらも操作は簡単です。 RunPodはテンプレートが豊富; Novitaはカスタマイズと低コストを重視。 |
| サーバーレス | ブラックボックス型のGPU割り当て、迅速なデプロイが可能だが、料金が不透明。 | ホワイトボックス型のGPU選択、GPUごとの透明な料金設定、コスト制御が可能。 | Novita AI — 料金が明確で、コストパフォーマンスのバランスが良い。 |
| リージョン | 多くのリージョンで成熟したカバレッジがあり、長期ワークロードに安定しているが、GPUの選択肢が限られており料金が不透明。 | 透明なGPU料金のリージョンノード、キャッシング機能が近日公開予定だが、現在サポートされているリージョンが少ない。 | 安定性とグローバルカバレッジが必要な場合 → RunPod。 |
| スケーラビリティ | マルチGPUクラスタ、ファインチューニングサービス、永続ストレージをサポート。分散トレーニングに適している。 | マルチGPUクラスタ、永続ストレージをサポート。 | 大規模トレーニングとファインチューニングにはRunPodが適している |
| 料金 | GPUインスタンスは1分単位で課金。 スポットはオンデマンドより安い。 |
通常RunPodより50%安い。 | Novitaは一般的にはるかに安価で、予算が限られた小規模チームに有利。 |
| API | ❌事前構築のLLM APIはないが、vLLMワーカーのデプロイをサポート。 | ✅200以上のすぐに使えるAPI(LLM、画像、動画、埋め込みなど)を提供し、RESTで直接呼び出し可能。 | トレーニングを行わずに迅速にAI機能を導入したいチームにはNovita AIが適している。 |
小規模チーム/スタートアップの場合、低価格、GPUの柔軟性、豊富な事前構築APIにより、通常Novita AIの方が適しています。
大規模トレーニング、ファインチューニング、GitHub統合ワークフローに注力するチームには、RunPodの方が適しています。
RunPodの利用方法は?
RunPodの利用開始は簡単です。開発者向けのステップバイステップガイドを紹介します:
- アカウント登録:runpod.ioにアクセスしてアカウントを作成します(メールアドレスで登録するか、Google/GitHubなどのシングルサインオンを利用できます)。アカウントを確認すると、RunPodのダッシュボードにアクセスできます。
- GPUポッドを起動:RunPodコンソールで**「Cloud GPUs」または「Pods」**セクションに移動して、最初のGPUインスタンスをデプロイします。通常は以下の操作を行います:
- 利用可能なインスタンスのリストから、リージョン(例:US West、EUなど)とGPUの種類(例:RTX 4090、A100)を選択します。選択すると各インスタンスの料金が表示されます。
- 環境テンプレートを選択します。RunPodは事前構築テンプレート(CUDA搭載Ubuntu、Jupyter Notebook、Stable Diffusionなど)を提供しているほか、独自のDockerイメージを使用することもできます。クイックスタートの場合は、IDEがすぐに使えるようにJupyter Notebookテンプレートなどを選択してください。
- デプロイをクリックします。数秒から1分以内に、RunPodは選択したGPU上でコンテナを起動します。ダッシュボードでポッドのステータスが「Running」になるのを確認できます。
- 接続して使用:ポッドが起動したら、それに接続できます。Jupyterテンプレートの場合は、ブラウザでJupyterインターフェースを開くためのURLが提供されます(GPUがバックアップされています)。その他の環境の場合は、Webシェルを開くかSSHを使用できます(RunPodはUIに接続詳細を表示します)。これで、このリモートGPU上でコードを実行したり、モデルをトレーニングしたりできます。
- サーバーレスエンドポイント(任意):推論エンドポイント(サーバーレス)をデプロイすることが目的の場合は、RunPodにServerlessセクションがあります。新しいエンドポイントを作成し、モデルを指定するか事前構築のモデル提供テンプレートを使用してデプロイします。RunPodはAPIエンドポイントのURLを提供します。このエンドポイントはリクエストが来ると自動的にスケーリングされます。これにより、ポッドを24時間365日実行しなくても、アプリにAPIを提供できるため非常に便利です。
- 管理と監視:ダッシュボードでは、実行中のポッド、その使用率、クレジット/請求情報を確認できます。使用していないときはポッドを停止または終了して費用を節約できます(課金は秒単位のため)。アイドル時間が1時間を超えたらポッドを終了するなど、自動シャットダウンポリシーを設定することも可能です。最初はWeb UIですべてを管理できます。より高度な使用の場合は、チームが成長するにつれてデプロイをスクリプト化するためのRunPod CLIとAPIを確認してください。
Novita AIの利用方法は?
GPUガイド
ステップ1:アカウント登録
当社のWebサイトからNovita AIアカウントを作成してください。登録後、左サイドバーの「Explore」セクションに移動して、GPUの offerings を確認し、AI開発の旅を始めましょう。

ステップ2:テンプレートとGPUサーバーの確認
プロジェクトのニーズに合ったPyTorch、TensorFlow、CUDAなどのテンプレートから選択してください。
次に、希望するGPU設定とGPU数量を選択します。選択肢には、強力なL40S、RTX 4090、A100 SXM4があり、それぞれ異なるVRAM、RAM、ストレージ仕様を備えています。
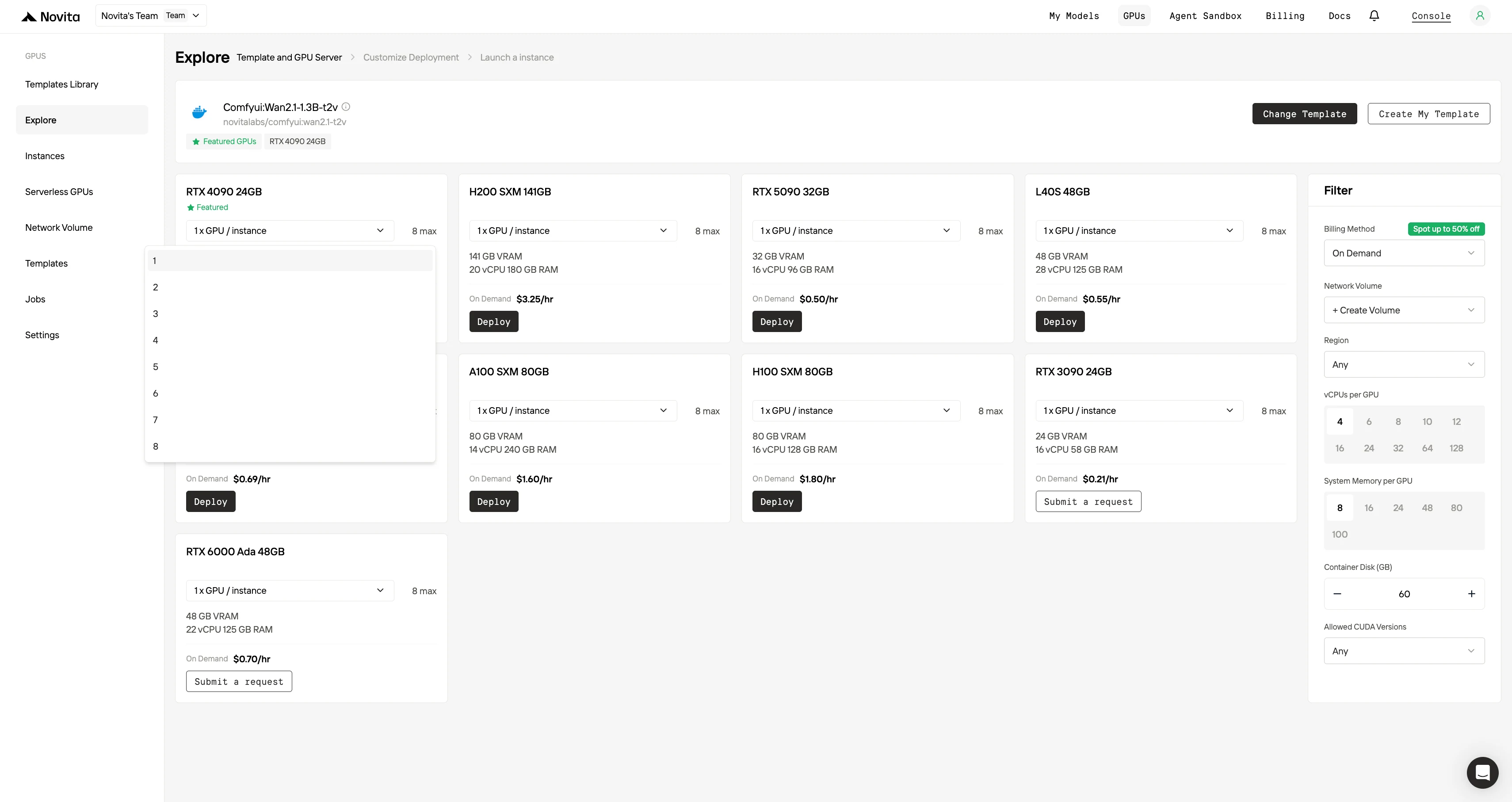
ステップ3:デプロイをカスタマイズ
希望するオペレーティングシステムと設定オプションを選択して環境をカスタマイズし、特定のAIワークロードと開発ニーズに最適なパフォーマンスを確保してください。
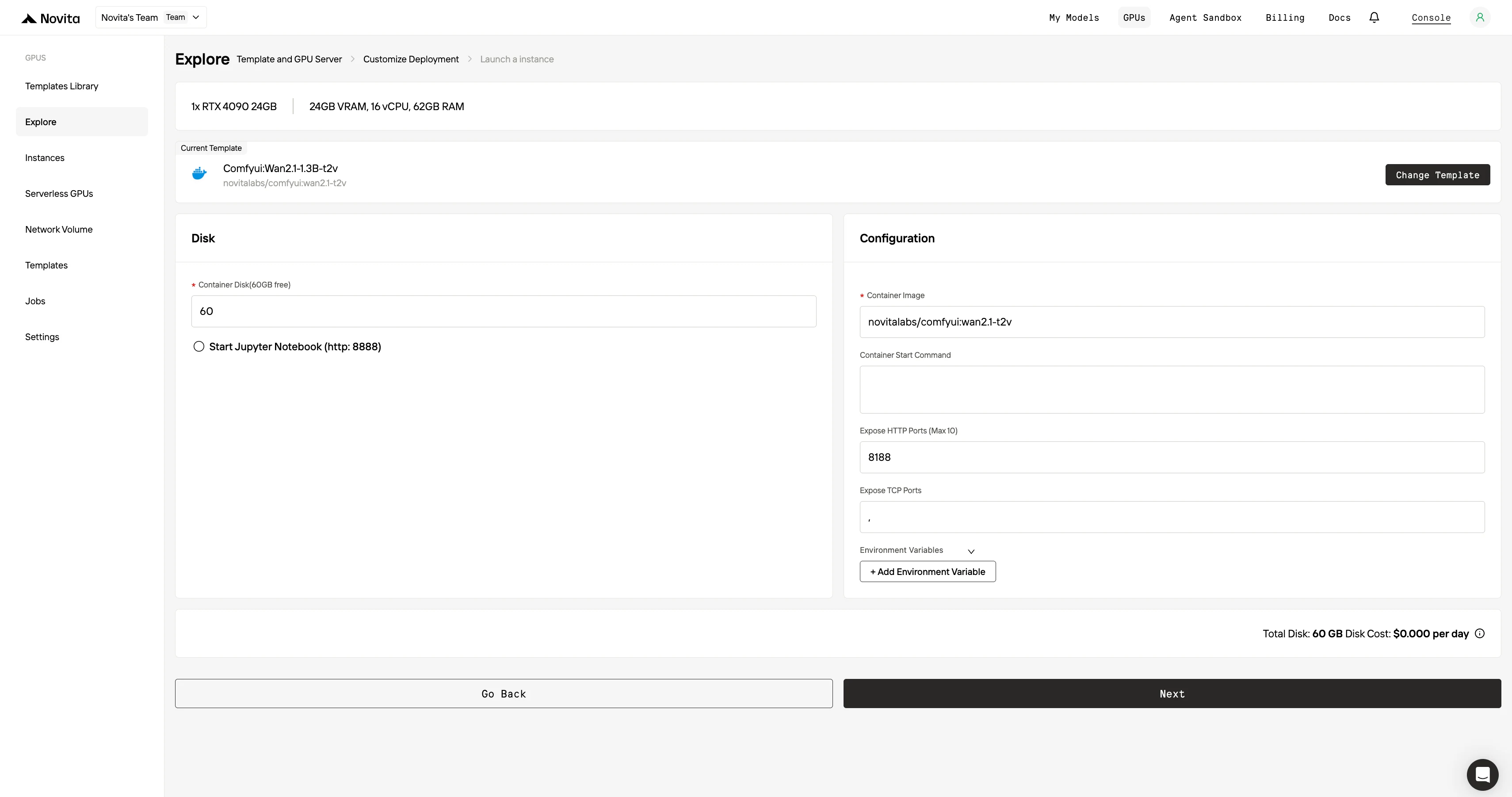
ステップ4:インスタンスを起動
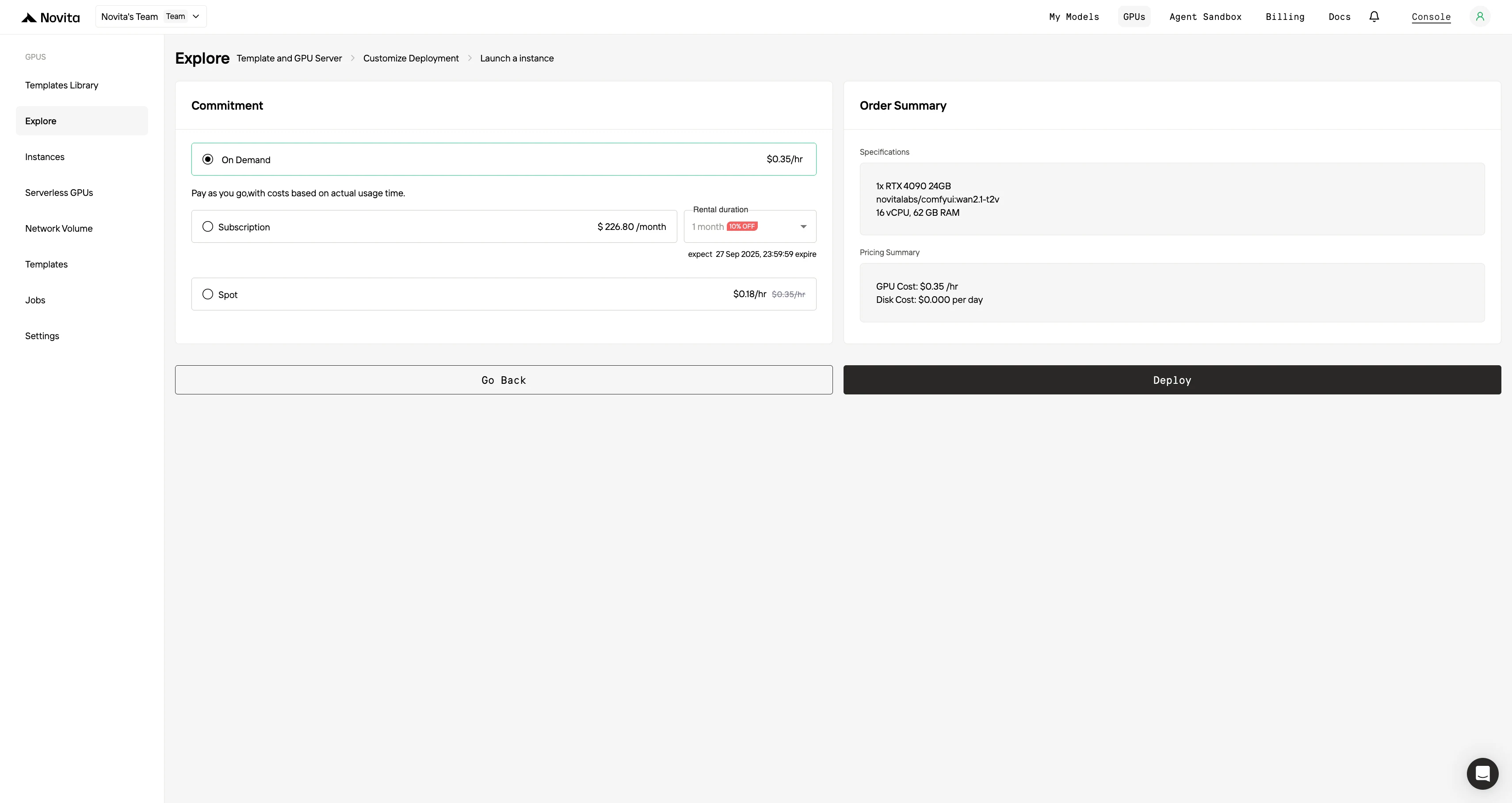
「Launch Instance」を選択してデプロイを開始します。高性能なGPU環境が数分で準備できるため、機械学習、レンダリング、計算プロジェクトにすぐに取り掛かれます。
APIガイド(Kimi K2を例に)
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリボタンをクリックします。

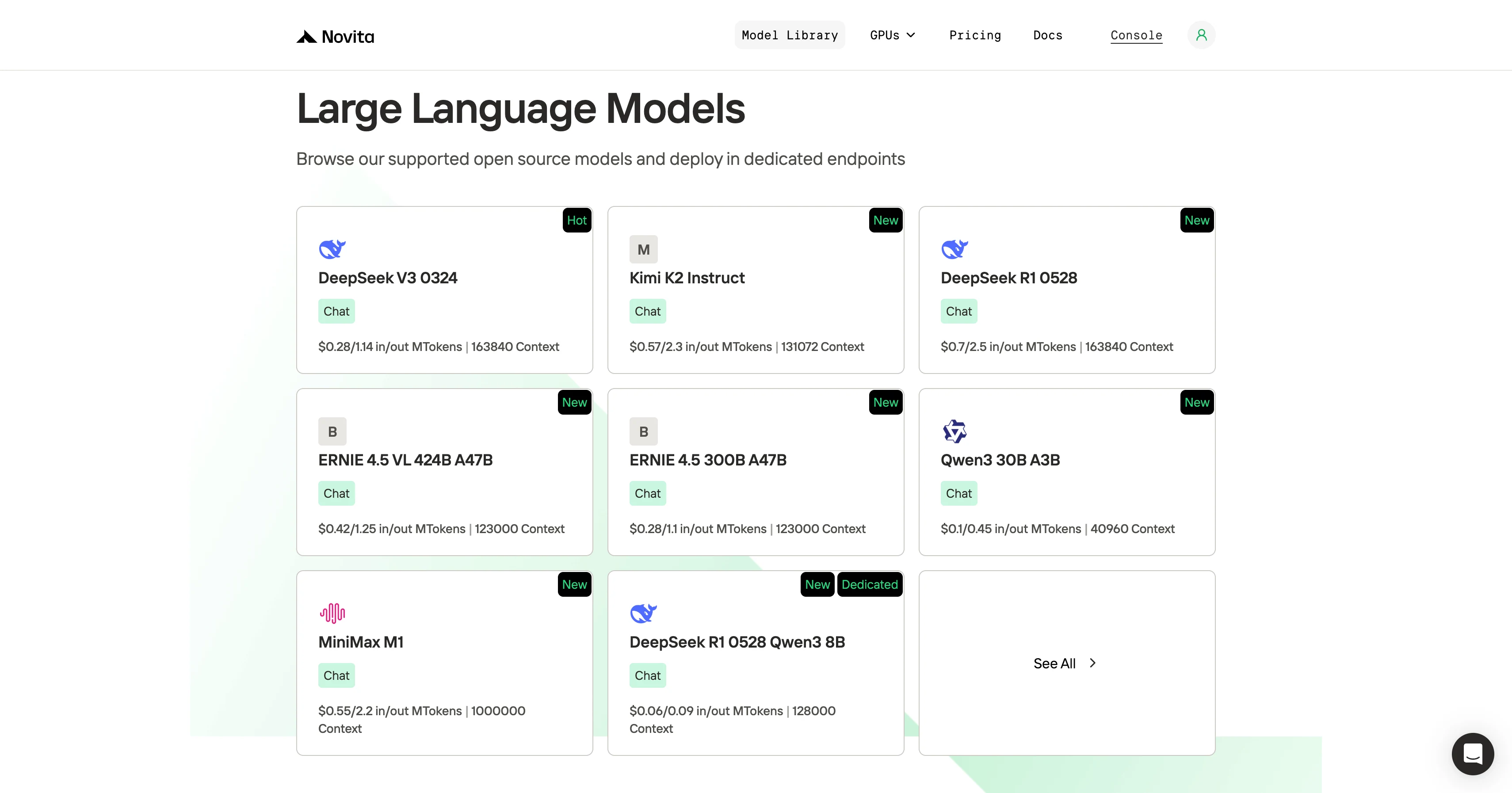
ステップ2:モデルを選択
利用可能なオプションを閲覧し、ニーズに合ったモデルを選択します。
ステップ3:無料トライアルを開始
選択したモデルの機能を探索するために、無料トライアルを開始します。
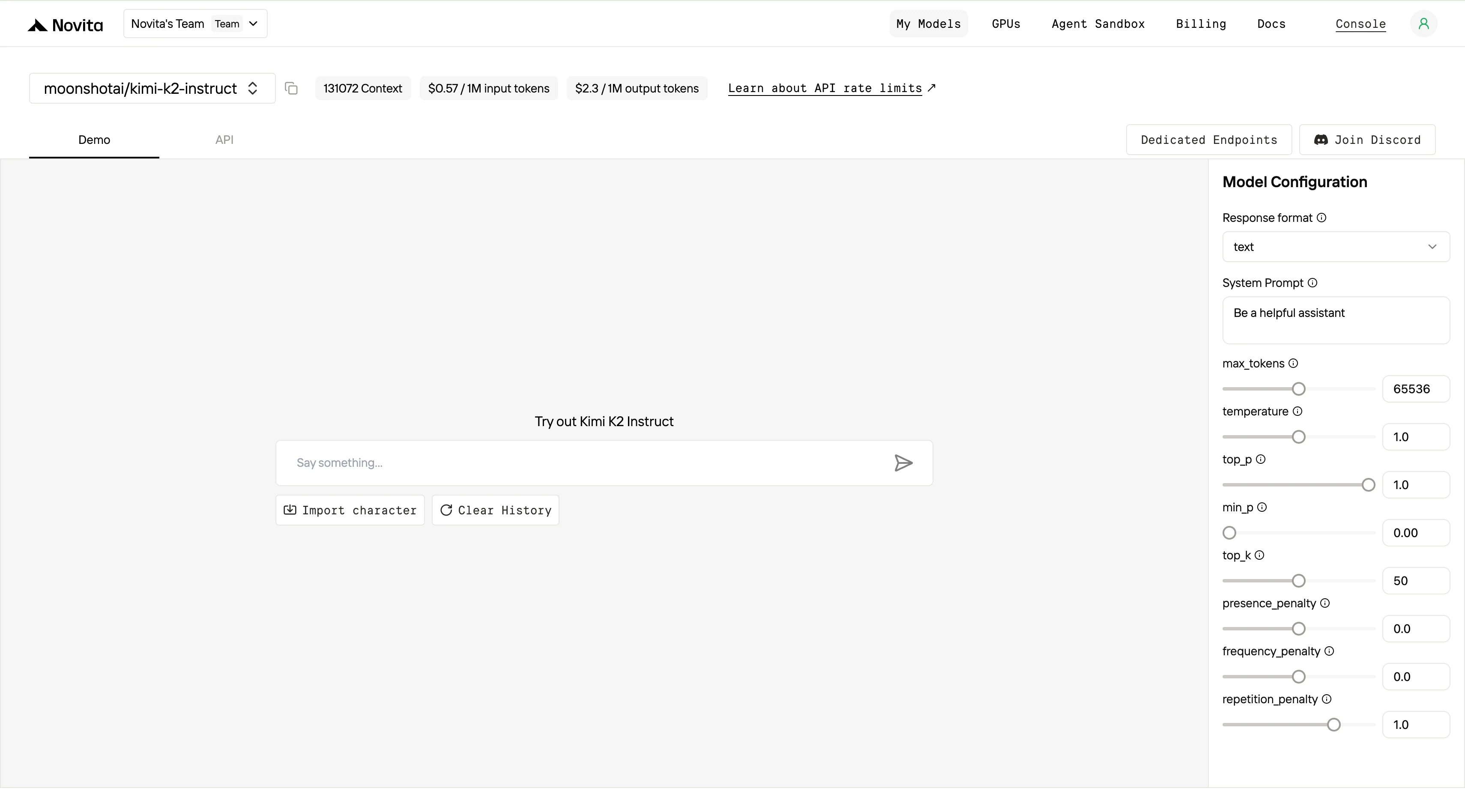
ステップ4:APIキーを取得
APIでの認証のために、新しいAPIキーを提供します。「設定」ページに移動すると、画像の指示に従ってAPIキーをコピーできます。

ステップ5:APIをインストール
プログラミング言語に固有のパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーでAPIを初期化し、Novita AI LLMとの対話を開始します。これはPythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Agent Sandbox(任意)の使用:NovitaにはダッシュボードからアクセスできるAgent Sandbox機能もあります。これにより、インターネット分離された完全に管理されたサンドボックス環境でAIエージェントやコードを実行できます。AIエージェントが生成したコードの評価など、ユースケースで必要になる場合に便利です。基本的な操作に慣れたら、この機能を探索してみてください。
Novita AIを選ぶべき場合
- 予算が限られている場合 — NovitaはGPU利用料金がRunPodより一般的に約50%安く、ストレージも非常に手頃で、スタートアップには充実した無料クレジットを提供しています。
- 迅速かつ手間のかからない機能が必要な場合 — 200以上の事前構築API(LLM、画像、オーディオ、動画)を備えているため、インフラの管理なしにAI搭載機能を導入したい場合に最適です。
- シンプルさと速度を重視する場合 — 特にトレーニング/ファインチューニングが優先事項でない場合、AIを迅速に統合するのに適しています。
最適な対象:ハードウェアや設定を気にせずにAIを迅速に統合したいインディー開発者、スタートアップ、プロダクトチーム。
RunPodを選ぶべき場合
- 複雑なトレーニングワークフローを計画している場合 — マルチGPUクラスタ、永続ストレージ、組み込みファインチューニングサービスを強力にサポートしています。
- スケーラビリティまたは強力なコンピューティングが必要な場合 — 大規模モデルのトレーニング、マルチノードセットアップ、長期の実験に適しています。
- リージョン間の標準化を重視する場合 — 30以上のグローバルリージョンにわたる導入実績と豊富なテンプレートライブラリにより、デプロイが簡素化されます。
- コード/GitHubリポジトリと密接に連携する場合 — サーバーレスリポジトリの組み込みサポートにより、オープンソースプロジェクトから直接デプロイするのが簡単です。
よくある質問
マルチGPUクラスタをデプロイできますか?
RunPodのみがInstant Clusters機能によりネイティブでこれをサポートしています。Novita AIは現在、サーバーレスと垂直スケーリングによるスケーリングをサポートしていますが、ユーザー管理のクラスタはサポートしていません。
RTX 4090やA100 GPUを実行する場合、どちらが安いですか?
Novita AIは通常安価です — RTX 4090は約1時間あたり0.35ドル、A100は約1時間あたり1.2ドル(スポット料金はさらに安い)で提供しています。RunPodはより多くのリージョンと柔軟性を提供していますが、1時間あたりの料金は少し高くなります。
RunPodはOpenAIのようなLLM APIを提供していますか?
L40S。その300〜350WのTDPと優れたワットあたりパフォーマンスにより、電力に敏感なデプロイにはより良い選択肢となります。H100(最大700W SXM5)には大規模なインフラが必要です。はい。RunPodはvLLMを使用したサーバーレスエンドポイントを提供しており、Hugging Faceのモデルをデプロイし、OpenAIスタイルのAPI経由で公開できます。これらのエンドポイントはREST経由で呼び出すか、LangChainと統合できます。
Novita AIは、シンプルなAPIを使用してAIモデルを簡単にデプロイできる方法を開発者に提供するとともに、構築とスケーリングのための手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。
おすすめの記事



