

개발자에게 적합한 클라우드 AI 플랫폼을 선택할 때 고려해야 할 핵심 요소는 보통 세 가지입니다: 비용, 사용 편의성, 확장성입니다. Novita AI와 RunPod 모두 AI 모델 배포, 학습, 실행을 위한 강력한 GPU 기반 인프라와 도구를 제공하지만, 약간 다른 개발자 요구사항을 충족시킵니다.
- Novita AI는 플러그 앤 플레이 API와 서버리스 GPU 액세스를 통한 빠르고 저렴한 추론에 강점이 있습니다. 하드웨어나 설정에 신경 쓰지 않고 빠르게 AI를 통합해야 하는 인디 개발자, 스타트업, 제품 팀에 이상적입니다.
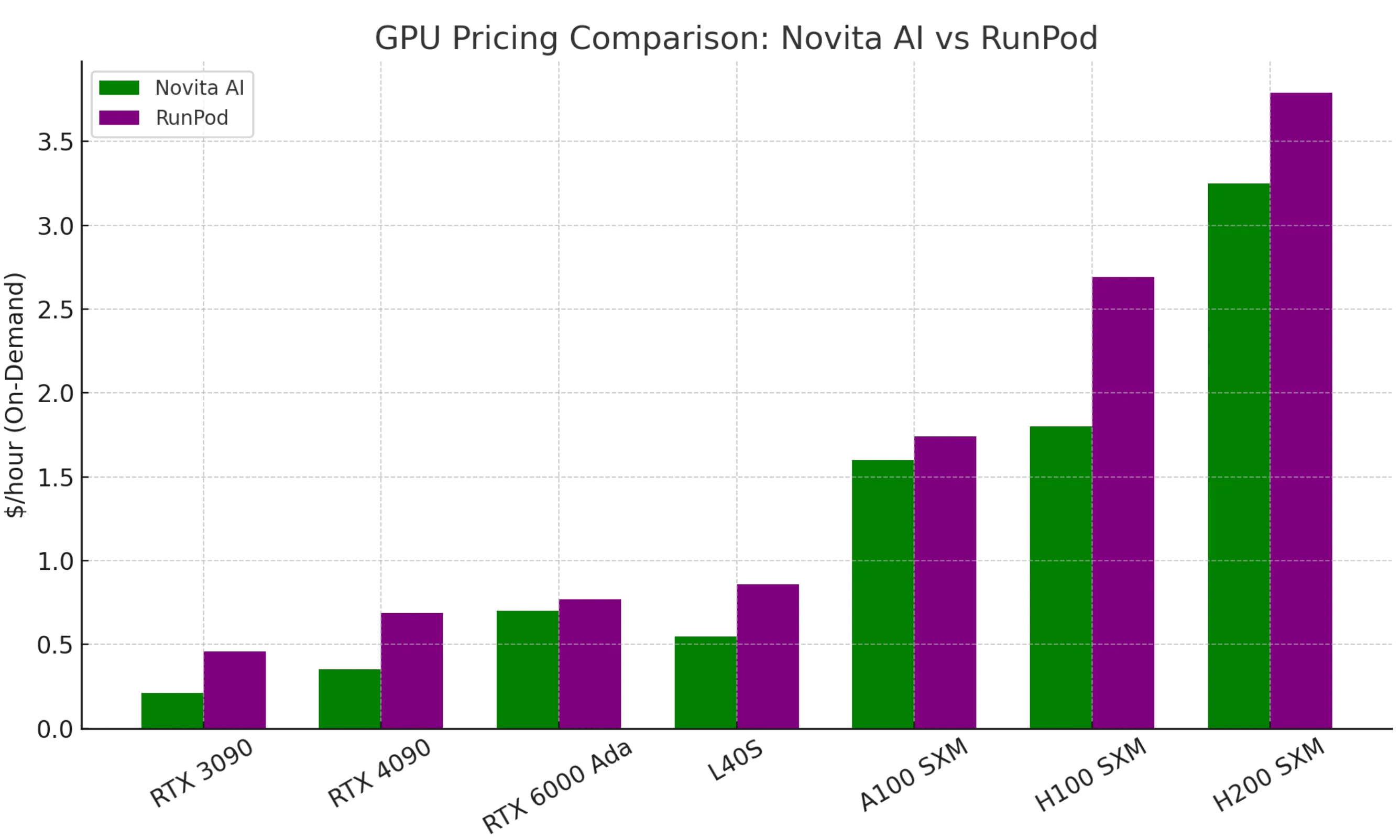
Novita AI의 주요 selling point는 저렴한 가격입니다. 동등한 성능의 GPU는 RunPod나 경쟁사 제품에 비해通常 절반 수준의 가격으로 제공됩니다.
- RunPod는 성숙한 개발 환경, 구성 가능한 포드, 추론 및 학습 워크로드 모두에 대한 강력한 지원으로 강점이 있습니다. 모델 구축 및 미세 조정이 필요하고 제어, 확장성, 인프라 유연성이 필요한 ML 엔지니어나 개발 팀에 이상적입니다.
이 글에서는 각 플랫폼의 강점과 trade-off를 분석하여 프로젝트에 맞는 플랫폼을 선택할 수 있도록 도와드립니다.
Novita AI 소개

Novita AI는 AI 모델 배포를 쉽고 저렴하게 만들어주는 클라우드 플랫폼입니다.
언어, 비전, 오디오 등 분야별 200개 이상의 즉시 사용 가능한 API는 물론 커스텀 모델을 위한 GPU 클라우드 인프라를 제공합니다.
개발자는 간단한 REST API로 AI를 빠르게 통합하거나 하드웨어를 다루지 않고 GPU 인스턴스를 실행할 수 있습니다. 저렴하고 안정적인 추론에 중점을 둔 Novita AI는 인디 개발자와 기업이 AI 기반 기능을 손쉽게 출시할 수 있도록 지원합니다.
RunPod 소개
RunPod는 개발자가 모델 학습, 미세 조정, 배포를 위한 강력한 GPU를 온디맨드로 이용할 수 있도록 지원하는 올인원 AI 클라우드 플랫폼입니다. 30개 이상의 글로벌 리전에서 온디맨드 및 스팟 GPU 포드를 제공하므로, 사용자는 몇 분 만에 Jupyter 노트북부터 다중 노드 GPU 클러스터까지 빠르게 실행할 수 있습니다. ML 엔지니어와 개발 팀을 위해 설계된 RunPod는 DevOps 지식 없이도 AI 확장을 쉽고 저렴하게 만들어줍니다.
RunPod와 Novita AI의 확장성 비교
Novita AI는 LLM, 이미지, 비디오 API를 포함한 수십 개의 API를 제공하며 지속적으로 새로운 API가 추가되고 있습니다. Playground에서 무료로 직접 사용해 볼 수 있습니다. RunPod는 기본 제공 LLM API는 없지만, 사전 구성된 vLLM 워커를 사용하여 대규모 언어 모델(LLM)을 배포할 수 있습니다.
| GPU 모듈 | RunPod | Novita AI |
|---|---|---|
| 서버리스 | ✅ 단기 추론 | ✅ 단기 추론 |
| 인스턴스 | ✅ GPU 인스턴스 | ✅ GPU 인스턴스 |
| 스토리지 | ✅ 영구 스토리지 및 네트워크 스토리지 | ✅ 영구 스토리지 및 네트워크 스토리지 |
| 베어메탈 | ❌ 제공하지 않음 | ✅ 전용 물리 서버 |
| 미세 조정 | ✅内置 미세 조정 서비스 | ❌ 직접 제공하지 않음 |
| 클러스터 | ✅ 다중 GPU 분산 | ✅ 다중 GPU 분산 |
| 리전 | ✅ 대부분의 리전 클러스터 지원 | ⚠️ 두 개의 리전 클러스터만 지원 |
서버리스 차이점
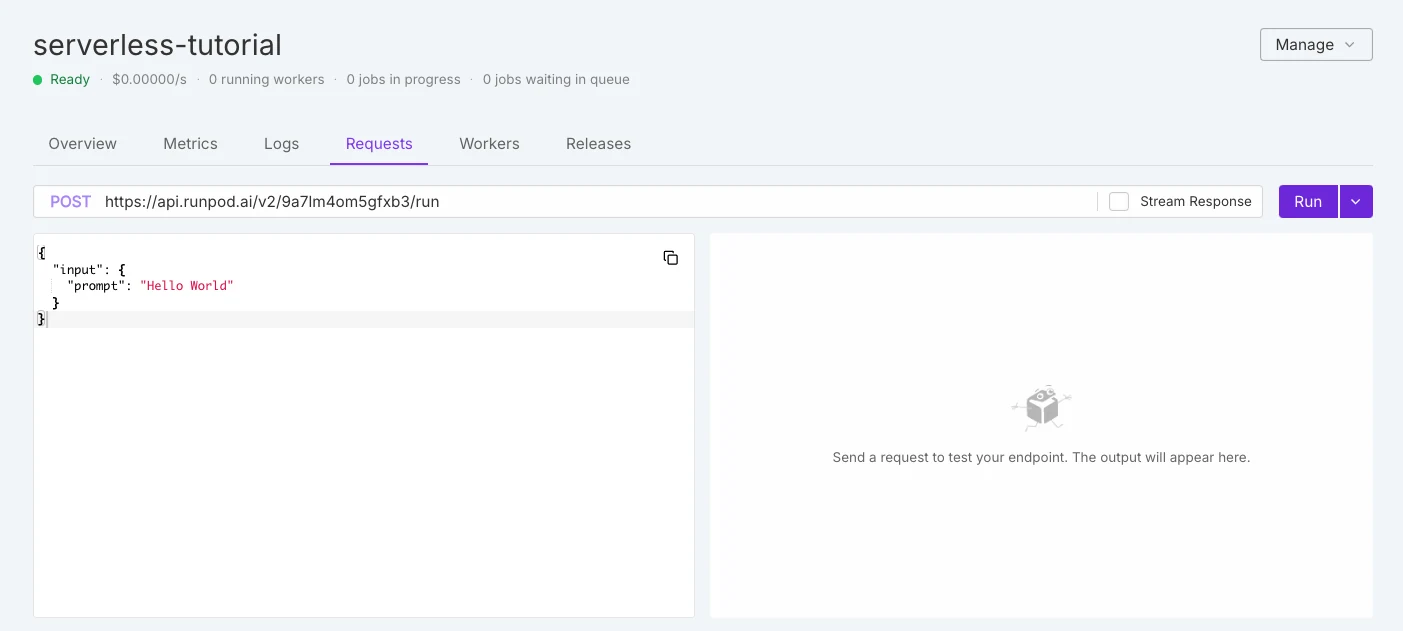
Runpod 서버리스
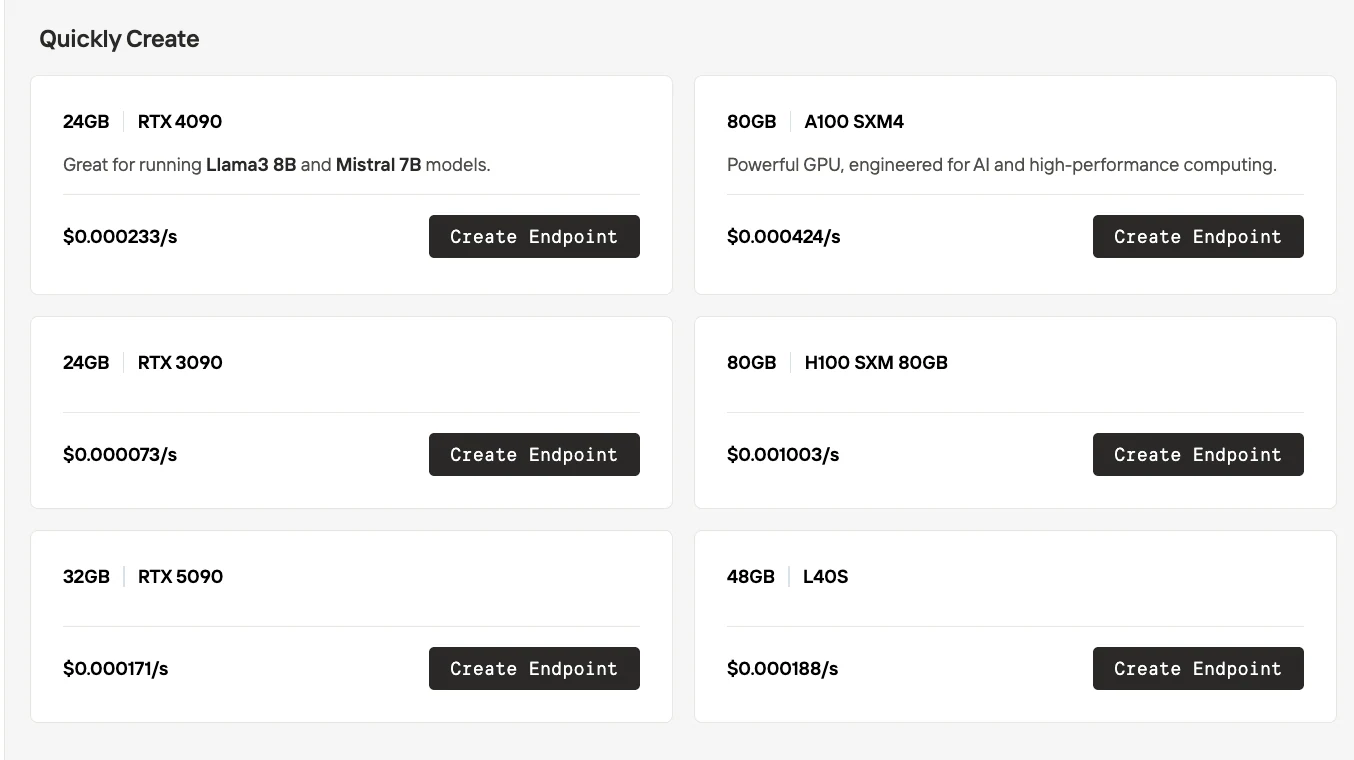
Novita AI 서버리스
| 항목 | RunPod 서버리스 | Novita AI 서버리스 |
|---|---|---|
| GPU 선택 | 블랙박스 모델 — GPU가 플랫폼에서 자동으로 할당됩니다. 사용자는 정확한 GPU 종류를 선택할 수 없습니다. | 화이트박스 모델 — 사용자가 엔드포인트 생성 전에 GPU 종류(예: RTX 3090, 4090, 5090, A100, H100, L40S)를 명시적으로 선택합니다. |
| 가격 | 런타임에 자동 할당된 GPU 종류에 따라 요금이 부과됩니다. | 가격이 투명하게 공개되어 GPU 종류별로 표시됩니다(예: RTX 3090은 초당 $0.000073, RTX 4090은 초당 $0.000233 등). |
| 제어 | 빠른 배포에 유리하지만, 비용 대비 성능 최적화를 위한 유연성이 적습니다. | 더 유연합니다: 팀이 GPU를 선택하여 비용, 성능, VRAM 요구사항을 균형 있게 맞출 수 있습니다. |
리전 차이점
- RunPod: 대부분의 리전에서 리전 노드와 클러스터 노드를 모두 지원합니다.
- Novita AI: 현재 두 개의 리전만 두 가지 노드 유형을 모두 지원합니다. 다만 Novita AI는 이번 분기부터 향상된 캐싱 기능을 탑재한 리전 GPU 기능을 출시할 예정으로, 이 기능은 기업 고객에게만 제공되었습니다.
리전 노드
정의: 장기적인 안정적인 워크로드를 위해 설계된 중앙 집중형 고품질 노드입니다.
주요 특징:
- 지속 가능한 용량을 갖춘 안정적이고 고성능의 컴퓨팅 리소스를 제공합니다.
- 데이터셋에 반복적으로 접근해야 하는 워크로드에 적합한 공유 데이터 접근용 NAS(네트워크 연결 스토리지)를 포함합니다.
- 엔터프라이즈급 안정성을 위한 전용 회선과 보조 서비스를 제공합니다.
- 모델 학습, 지속적 추론 서비스 등 장기 작업에 가장 적합합니다.
- 참고: 여기서의 NAS는 캐시/공유 스토리지로, 영구 스토리지가 아닙니다. 사용자는 여전히 외부에 데이터를 백업해야 합니다.
비유: 전용 사무실 공간과 같습니다. 모든 시설이 갖춰져 있고 안정적이므로 장기 프로젝트에 이상적입니다.
클러스터 노드
정의: 단기 또는 온디맨드 사용을 위해 설계된 분산형 탄력적 컴퓨팅 노드입니다.
주요 특징:
- NAS가 없으며 장기 캐싱이나 스토리지도 제공하지 않습니다.
- 전용 회선이 없으며 노드가 더 분산되어 유연성이 높습니다.
- 일회성 실험, 임시 병렬 작업 등 단기 대규모 탄력적 컴퓨팅에 최적화되어 있습니다.
- 비용 효율성이 더 높지만 영구 워크로드에는 적합하지 않습니다.
비유: 공유 공유 오피스와 같습니다. 사용하기 쉽고 유연하며 저렴하지만 영구 거주용으로는 적합하지 않습니다.
RunPod와 Novita AI의 사용 편의성 비교(GPU 인스턴스 예시)
Novita AI
1단계. 템플릿 선택 / 템플릿 생성 및 GPU 선택
- 미리 구성된 템플릿(GPU 드라이버, CUDA/cuDNN, 프레임워크, 런타임이 이미 설정된 상태)을 선택하거나 직접 커스텀 템플릿을 생성한 후 GPU 종류와 수량을 선택하세요!
2단계. 디스크 및 구성 확인
- 기술 설정을 검토하고 조정하세요: GPU 종류(예: RTX 4090, VRAM, CPU, RAM), 컨테이너 이미지, 시작 명령어, 환경 변수, 노출 포트, 디스크 용량 등입니다.
3단계. 결제 확인
- 과금 모드를 (온디맨드/스팟, 또는 1~12개월 구독) 중 선택하고 요금 요약(GPU 시간당 비용, 디스크 일일 비용, 월 총 비용)을 검토하세요.
RunPod
1단계. GPU 선택
- 사용 가능한 GPU 종류(예: B200, H200, A40, RTX 5090)를 둘러보세요. VRAM, 리전 등 다양한 속성으로 필터링할 수 있습니다.
2단계. 인스턴스 구성
- 구성이란: 환경 및 런타임 옵션, 디스크 볼륨 용량, 볼륨 암호화, SSH 터미널 접근, Jupyter Notebook 자동 실행 여부 등의 추가 옵션을 조정하세요.
Runpod has 50+ pre-configured templates so you don’t need to customize complex parameters
3단계. 요금제 선택
- 인스턴스에 대한 지불 방식을 선택하세요.
- 이용 가능한 옵션:
- 온디맨드
- 3개월 요금 할인 플랜
- 6개월 요금 할인 플랜
- 1년 요금 할인 플랜
- 스팟
RunPod와 Novita AI의 요금제 비교
| 요금 항목 | RunPod | Novita AI |
|---|---|---|
| 무료 티어 / 크레딧 | 영구 무료 GPU 티어는 없습니다. 신규 사용자는 체험 크레딧을 받을 수 있으며, 자격을 갖춘 스타트업은 스타트업 프로그램을 통해 최대 1,000시간의 무료 H100 사용 시간을 받을 수 있습니다. |
영구 무료 티어는 없습니다. Novita AI도 스타트업 프로그램을 운영하고 있으며(자격을 갖춘 스타트업에게 최대 $10,000 상당의 무료 크레딧을 제공한다고 광고하고 있습니다). |
| GPU 인스턴스 가격 | GPU 인스턴스는 시간 단위 요금이 적용됩니다(1분 단위로 과금). | GPU 인스턴스는 시간 단위 요금이 적용됩니다(1분 단위로 과금). |
| 스팟 가격 | 온디맨드 GPU 가격보다 저렴합니다. | 온디맨드 GPU 가격의 50% |
| 서버리스 가격 | /워커/초 |
| 스토리지 유형 | Novita AI (GB/일) | RunPod (GB/월) |
|---|---|---|
| 컨테이너 디스크 | $0.005/GB/일, 60GB 무료 할당량 포함 | $0.10/GB/월 |
| 영구(볼륨) 디스크 | $0.005/GB/일 | 실행 중인 포드: $0.10/GB/월 (컨테이너 디스크와 동일) 종료된 포드: $0.20/GB/월 |
| 네트워크 볼륨(클라우드 스토리지) | $0.002/GB/일 | 1TB 미만: $0.07/GB/월 1TB 이상: $0.05/GB/월 |
RunPod에서는 스토리지가 초 단위로 과금되며 고정 월 요금이 아닙니다. “GB당 월 $0.10” 요금은 참고용입니다: 1GB를 30일 전체 동안 보관하면 약 $0.10의 비용이 발생합니다. 며칠이나 몇 시간만 보관하는 경우 초 단위로 prorated되므로 훨씬 적은 비용을 지불합니다.
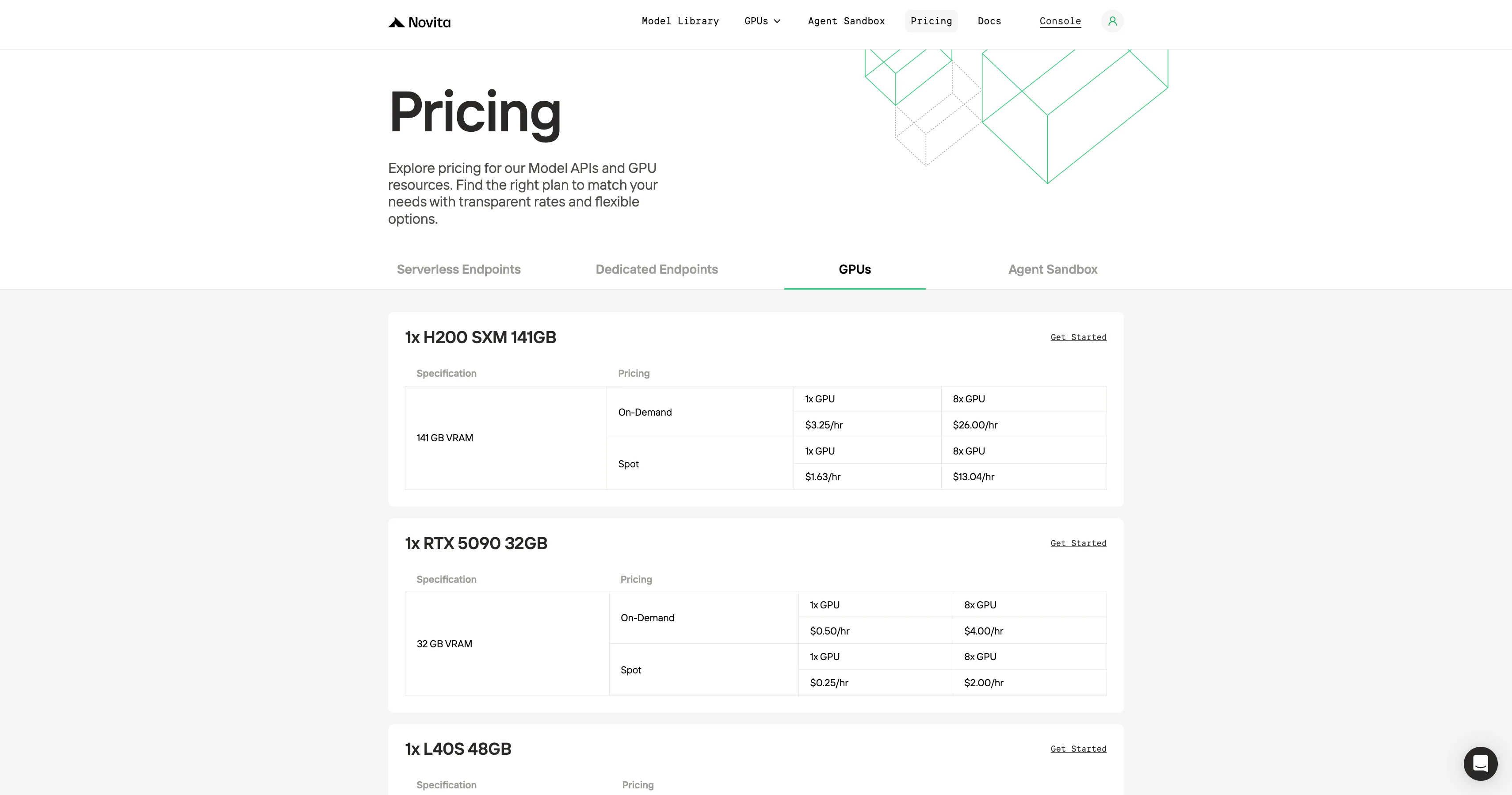
GPU 온디맨드 가격 비교
Novita AI의 주요 selling point는 저렴한 가격입니다. 동등한 성능의 GPU는 RunPod나 경쟁사 제품에 비해通常 절반 수준의 가격으로 제공됩니다.
소규모 팀에는 RunPod와 Novita AI 중 어느 쪽이 더 적합할까요?
| 항목 | RunPod | Novita AI | 소규모 팀에 더 적합한 옵션 |
|---|---|---|---|
| GPU 인스턴스 (사용 편의성) | 1단계: GPU 선택 2단계: 인스턴스 구성. 50개 이상의 사전 구성 템플릿 3단계: 요금제 선택 |
1단계: 템플릿 선택/생성 + GPU 선택 2단계: 디스크, 런타임, 환경 변수 구성 3단계: 결제 확인 |
둘 다 사용하기 쉽습니다. RunPod는 템플릿이 더 많고, Novita AI는 커스텀과 저렴한 가격을 강조합니다. |
| 서버리스 | 블랙박스 GPU 할당, 빠른 배포지만 가격이 덜 투명합니다. | 화이트박스 GPU 선택, GPU별 투명한 가격, 비용 제어 가능 | Novita AI — 가격이 명확하고 비용 대비 성능 균형이 더 좋습니다. |
| 리전 | 다양한 리전에서 성숙한 커버리지를 제공하며 장기 워크로드에 안정적이지만, GPU 선택이 제한적이고 가격이 불투명합니다. | GPU 가격이 투명한 리전 노드, 곧 캐싱 기능 출시 예정이지만 현재 지원 리전이 적습니다. | 안정성과 글로벌 커버리지가 필요하다면 → RunPod. |
| 확장성 | 다중 GPU 클러스터, 미세 조정 서비스, 영구 스토리지를 지원합니다. 분산 학습에 적합합니다. | 다중 GPU 클러스터, 영구 스토리지를 지원합니다. | 대규모 학습 및 미세 조정에는 RunPod가 더 적합합니다 |
| 가격 | GPU 인스턴스는 분 단위로 과금됩니다. 스팟이 온디맨드보다 저렴합니다. |
일반적으로 RunPod보다 50% 저렴합니다. | Novita AI가 전반적으로 훨씬 저렴하여 예산이 제한된 소규모 팀에 유리합니다. |
| API | ❌기본 제공 LLM API는 없지만 vLLM 워커 배포를 지원합니다. | ✅200개 이상의 즉시 사용 가능한 API(LLM, 이미지, 비디오, 임베딩 등)를 제공하며 REST로 직접 호출할 수 있습니다. | 학습 없이 빠르게 AI 기능을 도입하려는 팀에는 Novita AI가 더 적합합니다. |
소규모 팀/스타트업의 경우, 저렴한 가격, GPU 유연성, 방대한 사전 구성 API로 인해 일반적으로 Novita AI가 더 나은 선택입니다.
대규모 학습, 미세 조정, GitHub 연동 워크플로우에 중점을 둔 팀에는 RunPod가 더 강점이 있습니다.
RunPod에 어떻게 접속할 수 있나요?
RunPod를 시작하는 것은 간단합니다. 개발자를 위한 단계별 가이드를 소개합니다:
- 가입하기: runpod.io로 이동하여 계정을 생성하세요(이메일로 가입하거나 Google/GitHub 등의 싱글 사인온을 사용할 수 있습니다). 계정 인증 후 RunPod 대시보드에 접근할 수 있습니다.
- GPU 포드 실행: RunPod 콘솔에서 “Cloud GPUs” 또는 “Pods” 섹션으로 이동하여 첫 번째 GPU 인스턴스를 배포하세요. 일반적으로 다음과 같이 진행합니다:
- 사용 가능한 인스턴스 목록에서 리전(예: 미국 서부, EU 등)과 GPU 종류(예: RTX 4090, A100)를 선택하세요. 선택 시 각 인스턴스의 가격이 표시됩니다.
- 환경 템플릿을 선택하세요. RunPod는 사전 구성된 템플릿(CUDA가 설치된 Ubuntu, Jupyter Notebook, Stable Diffusion 등)을 제공하거나 직접 Docker 이미지를 사용할 수도 있습니다. 빠르게 시작하려면 Jupyter Notebook 템플릿을 선택하여 IDE를 바로 사용할 수 있도록 하세요.
- 배포를 클릭하세요. 몇 초에서 1분 내에 RunPod가 선택한 GPU에 컨테이너를 실행합니다. 대시보드에서 포드 상태가 "실행 중"으로 표시되는 것을 확인할 수 있습니다.
- 연결 및 사용: 포드가 실행되면 연결할 수 있습니다. Jupyter 템플릿인 경우 브라우저에서 Jupyter 인터페이스를 열 수 있는 URL이 제공됩니다(GPU가 지원됩니다). 다른 환경의 경우 웹 셸을 열거나 SSH를 사용할 수 있습니다(RunPod가 UI에 연결 정보를 제공합니다). 이제 이 원격 GPU에서 코드를 실행하거나 모델을 학습할 수 있습니다.
- 서버리스 엔드포인트 (선택 사항): **추론 엔드포인트(서버리스)**를 배포하는 것이 목표인 경우 RunPod의 서버리스 섹션을 이용하세요. 새 엔드포인트를 생성하고 모델을 지정하거나 사전 구성된 모델 서빙 템플릿을 사용하여 배포합니다. RunPod가 API 엔드포인트 URL을 제공합니다. 이 엔드포인트는 요청이 들어오면 자동으로 확장되므로, 포드를 24시간 실행하지 않고 앱에 API를 제공하기에 적합합니다.
- 관리 및 모니터링: 대시보드에서 실행 중인 포드, 사용률, 크레딧/과금 정보를 확인할 수 있습니다. 사용하지 않을 때 포드를 중지하거나 종료하여 비용을 절약할 수 있습니다(초 단위로 과금되기 때문입니다). 또한 유휴 시간 1시간 후 포드를 종료하는 등의 자동 종료 정책을 설정할 수도 있습니다. 초기에는 웹 UI로 모든 것을 관리할 수 있으며, 고급 사용의 경우 팀이 성장함에 따라 RunPod CLI와 API를 사용하여 배포를 스크립팅하는 것을 탐색해 보세요.
Novita AI에 어떻게 접속할 수 있나요?
GPU 가이드
1단계: 계정 등록
웹사이트에서 Novita AI 계정을 생성하세요. 등록 후 왼쪽 사이드바의 “탐색” 섹션으로 이동하여 제공되는 GPU를 확인하고 AI 개발 여정을 시작하세요.

2단계: 템플릿 및 GPU 서버 탐색
프로젝트 요구사항에 맞는 PyTorch, TensorFlow, CUDA 등의 템플릿을 선택하세요.
그 다음 선호하는 GPU 구성과 GPU 수량을 선택하세요. 강력한 L40S, RTX 4090, A100 SXM4 등 다양한 VRAM, RAM, 스토리지 사양의 옵션이 있습니다.
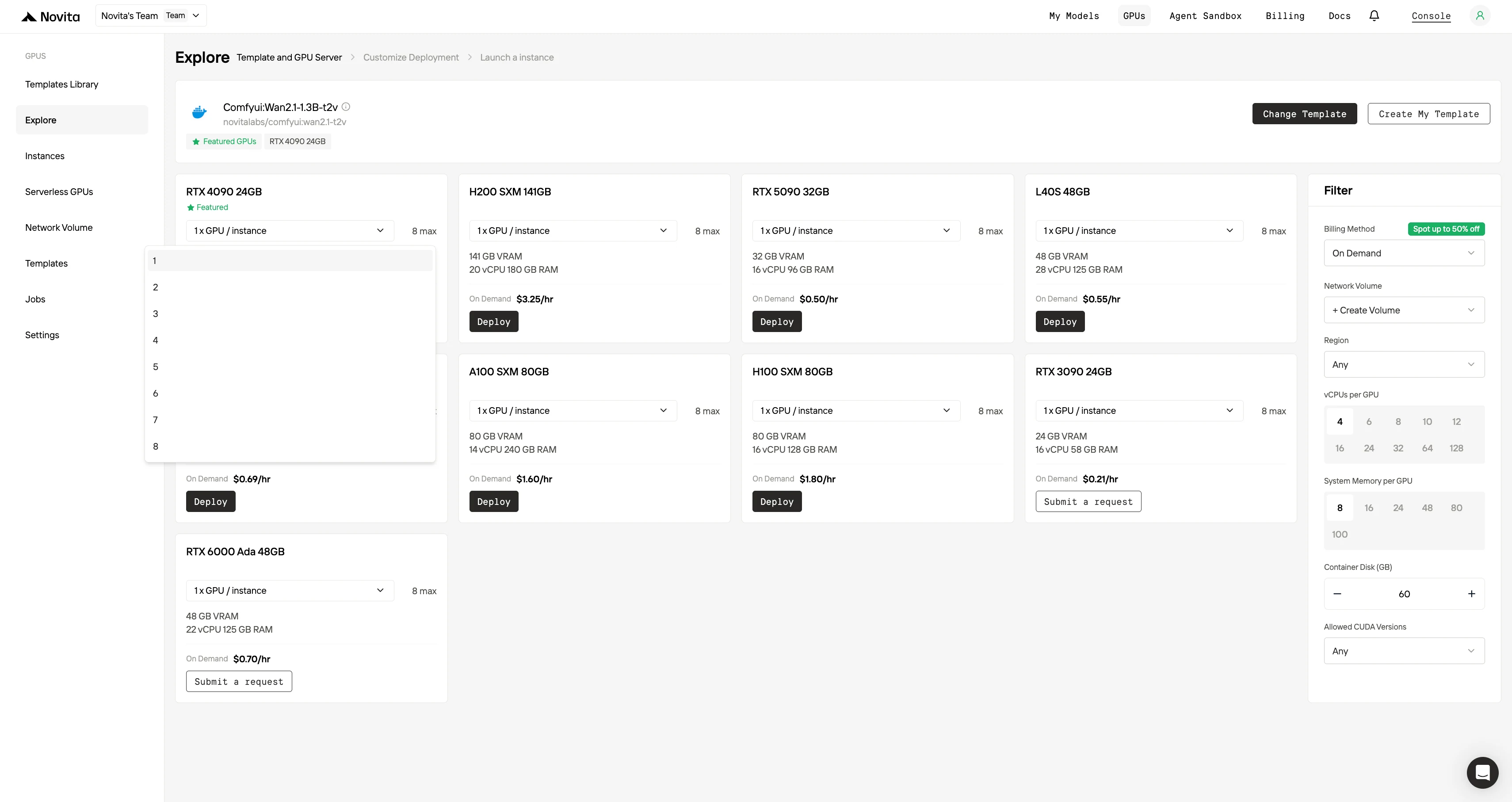
3단계: 배포 맞춤 설정
선호하는 운영 체제와 구성 옵션을 선택하여 환경을 커스텀하고, 특정 AI 워크로드와 개발 요구사항에 최적의 성능을 확보하세요.
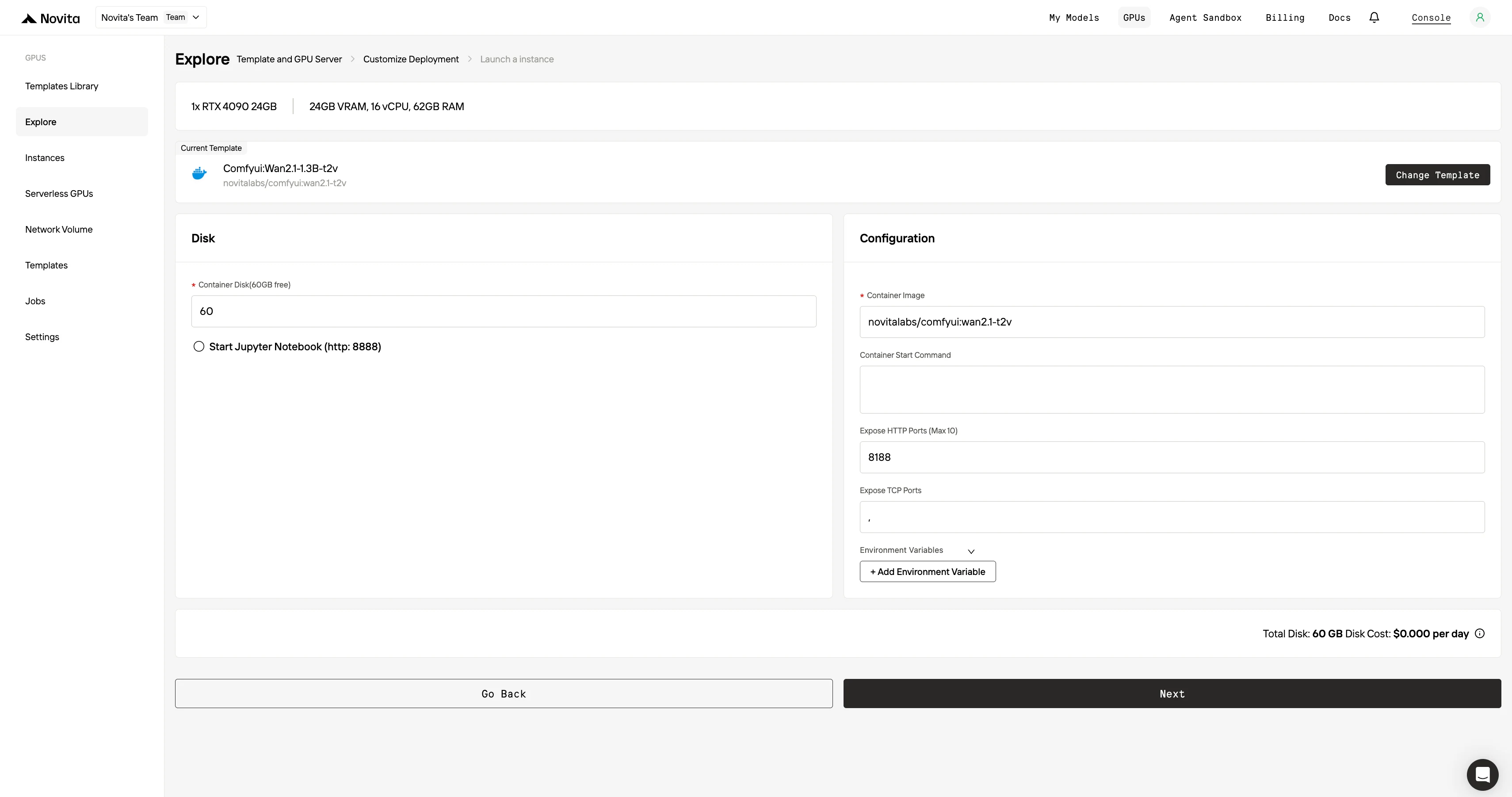
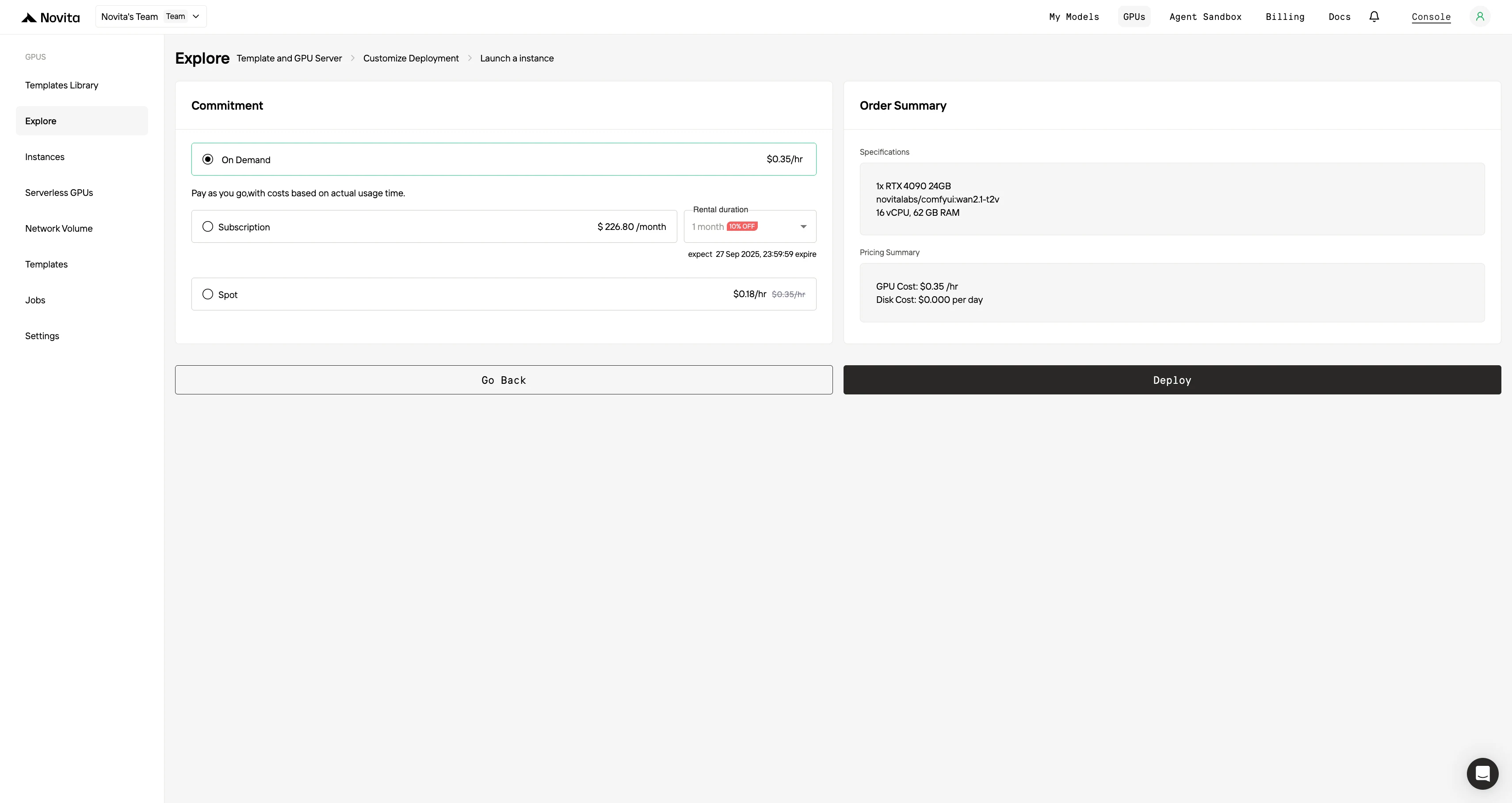
4단계: 인스턴스 실행
"인스턴스 실행"을 선택하여 배포를 시작하세요. 고성능 GPU 환경이 몇 분 내에 준비되므로 머신러닝, 렌더링, 연산 프로젝트를 즉시 시작할 수 있습니다.
API 가이드 (Kimi K2 예시)
1단계: 로그인 및 모델 라이브러리 접근
계정에 로그인한 후 모델 라이브러리 버튼을 클릭하세요.

2단계: 모델 선택
이용 가능한 옵션을 둘러보고 요구사항에 맞는 모델을 선택하세요.
3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하려면 무료 체험을 시작하세요.
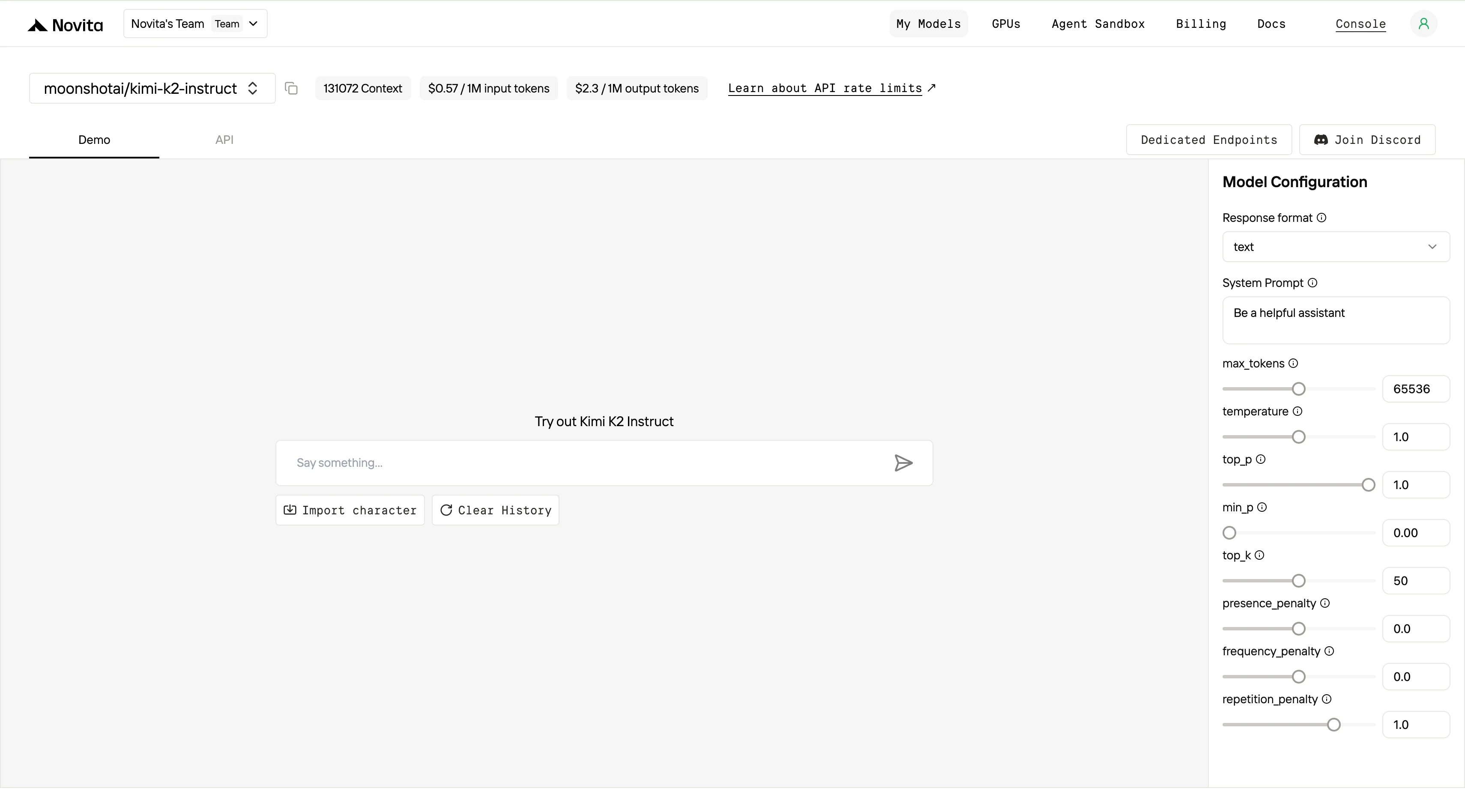
4단계: API 키 발급
API 인증을 위해 새로운 API 키를 발급해 드립니다. “설정” 페이지에 접속하면 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치
사용 중인 프로그래밍 언어에 맞는 패키지 매니저를 사용하여 API를 설치하세요.
설치 후 필요한 라이브러리를 개발 환경으로 가져오세요. API 키로 API를 초기화하여 Novita AI LLM과 상호작용을 시작할 수 있습니다. 아래는 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Agent 샌드박스 (선택 사항) 사용하기: Novita AI는 대시보드에서 접근할 수 있는 Agent 샌드박스 기능도 제공합니다. 이를 통해 인터넷이 격리된 완전 관리형 샌드박스 환경에서 AI 에이전트나 코드를 실행할 수 있습니다. AI 에이전트가 생성한 코드를 평가하는 등의 사용 사례에 유용합니다. 기본 기능에 익숙해지면 이 기능을 탐색해 보세요.
Novita AI를 선택해야 하는 경우
- 예산이 부족한 경우 — Novita AI는 GPU 사용에 대해 RunPod보다 일반적으로 50% 정도 저렴하며, 스토리지 비용도 매우 저렴하고 스타트업에게 관대한 무료 크레딧을 제공합니다.
- 빠르고 번거로움 없는 기능이 필요한 경우 — 200개 이상의 사전 구성 API(LLM, 이미지, 오디오, 비디오)를 제공하므로 인프라를 관리하지 않고 AI 기반 기능을 도입하려는 경우에 이상적입니다.
- 단순함과 속도를 선호하는 경우 — 특히 학습/미세 조정이 우선순위가 아닌 경우 AI를 빠르게 통합하기에 적합합니다.
적합 대상: 하드웨어나 설정에 신경 쓰지 않고 빠르게 AI를 통합해야 하는 인디 개발자, 스타트업, 제품 팀.
RunPod를 선택해야 하는 경우
- 복잡한 학습 워크플로우를 계획 중인 경우 — 다중 GPU 클러스터, 영구 스토리지,内置 미세 조정 서비스에 대한 강력한 지원을 제공합니다.
- 확장성이나 강력한 컴퓨팅 성능이 필요한 경우 — 대규모 모델 학습, 다중 노드 구성, 장기 실험에 적합합니다.
- 리전 간 표준화를 선호하는 경우 — 30개 이상의 글로벌 리전에 걸친 인프라와 방대한 템플릿 라이브러리로 배포가 간편합니다.
- 코드/GitHub 저장소와 긴밀하게 협업하는 경우 —内置 서버리스 리포 지원으로 오픈소스 프로젝트에서 직접 배포하기 쉽습니다.
자주 묻는 질문
다중 GPU 클러스터를 배포할 수 있나요?
RunPod만 Instant 클러스터 기능을 통해 기본적으로 이 기능을 지원합니다. Novita AI는 현재 서버리스 및 수직 확장을 통한 스케일링만 지원하며, 사용자 관리 클러스터는 지원하지 않습니다.
RTX 4090이나 A100 GPU를 실행할 때 어느 쪽이 더 저렴한가요?
Novita AI가 일반적으로 더 저렴합니다 — RTX 4090은 시간당 약 $0.35, A100은 시간당 약 $1.2에 제공되며(스팟 가격은 더 저렴합니다). RunPod는 더 많은 리전과 유연성을 제공하지만 시간당 비용이 약간 더 높습니다.
RunPod는 OpenAI와 같은 LLM API를 제공하나요?
L40S. 300~350W의 TDP와 와트당 성능이 뛰어나 전원에 민감한 배포에 더 나은 옵션입니다. H100(최대 700W SXM5)은 상당한 인프라가 필요합니다.네. RunPod는 vLLM을 사용한 서버리스 엔드포인트를 제공하여 Hugging Face 모델을 배포하고 OpenAI 스타일 API로 노출할 수 있습니다. REST로 이 엔드포인트를 호출하거나 LangChain과 통합할 수 있습니다.
Novita AI는 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있는 방법을 개발자에게 제공하는 동시에, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공하는 AI 클라우드 플랫폼입니다.
추천 읽기



