

- Introducción a Novita AI
- Introducción a RunPod
- Comparativa de escalabilidad entre RunPod y Novita AI
- Comparativa de usabilidad entre RunPod y Novita AI (ejemplo con instancias de GPU)
- Comparativa de planes de precios de RunPod y Novita AI
- ¿RunPod o Novita AI es mejor para equipos pequeños?
- ¿Cómo acceder a RunPod?
- ¿Cómo acceder a Novita AI?
Para los desarrolladores, elegir la plataforma de IA en la nube adecuada suele reducirse a tres cosas: costo, facilidad de uso y escalabilidad. Tanto Novita AI como RunPod ofrecen infraestructura y herramientas potentes respaldadas por GPU para implementar, entrenar o ejecutar modelos de IA, pero satisfacen necesidades de desarrolladores ligeramente diferentes.
- Novita AI destaca por su inferencia rápida y económica mediante APIs listas para usar y acceso a GPU sin servidor, ideal para desarrolladores independientes, startups y equipos de producto que necesitan una integración rápida de IA sin preocuparse por el hardware o la configuración.
El principal atractivo de Novita es su bajo costo. Las GPUs equivalentes suelen costar la mitad que en RunPod o en competidores.
- RunPod destaca por su entorno de desarrollo maduro, pods configurables y soporte robusto tanto para cargas de trabajo de inferencia como de entrenamiento: ideal para ingenieros de ML o equipos de desarrollo que construyen y ajustan modelos, y necesitan control, escalabilidad y flexibilidad de infraestructura.
En esta publicación, analizamos las fortalezas y desventajas de cada plataforma para ayudarte a decidir cuál se adapta a tu proyecto.
Introducción a Novita AI

Novita AI es una plataforma en la nube que facilita la implementación de modelos de IA de forma sencilla y económica.
Ofrece más de 200 APIs listas para usar para lenguaje, visión, audio y más, además de infraestructura de GPU en la nube para modelos personalizados.
Los desarrolladores pueden integrar la IA rápidamente mediante APIs REST sencillas o lanzar instancias de GPU sin tener que lidiar con el hardware. Con su enfoque en la inferencia fiable y de bajo costo, Novita AI ayuda a desarrolladores independientes y empresas a lanzar funcionalidades impulsadas por IA sin esfuerzo.
Introducción a RunPod
RunPod es una plataforma en la nube todo en uno para IA que brinda a los desarrolladores acceso bajo demanda a GPUs potentes para entrenar, ajustar e implementar modelos. Con pods de GPU disponibles en más de 30 regiones globales (tanto bajo demanda como spot), los usuarios pueden lanzar en minutos desde un cuaderno Jupyter hasta un clúster de GPU multinodo. Diseñada para ingenieros de ML y equipos de desarrollo, RunPod hace que escalar la IA sea fácil y económico, sin necesidad de DevOps.
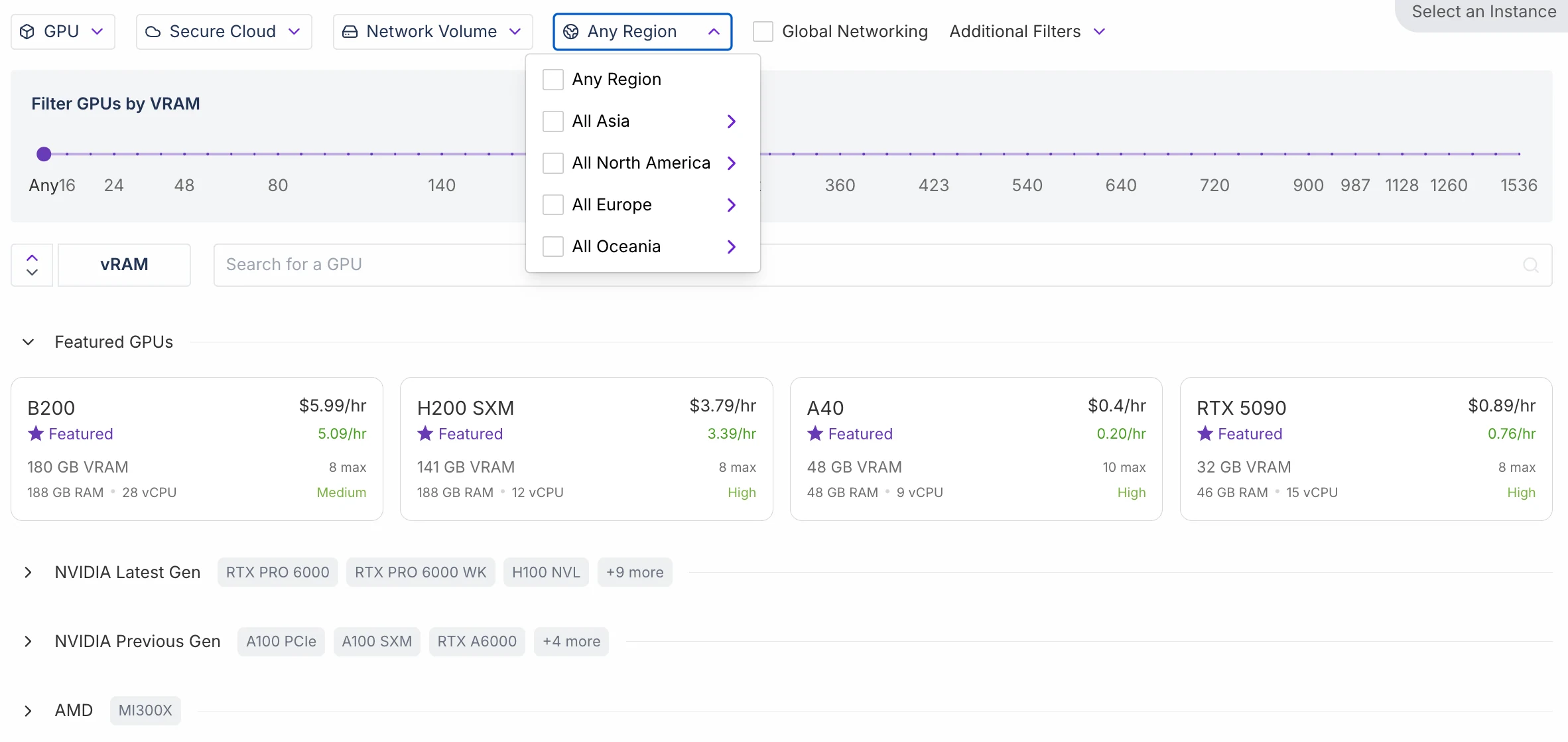
Comparativa de escalabilidad entre RunPod y Novita AI
Novita AI ofrece decenas de APIs, incluyendo APIs de LLM, imagen y vídeo, con nuevas que se añaden continuamente. Puedes probarlas de forma gratuita directamente en el Playground. RunPod, si bien no proporciona APIs de LLM de serie, te permite implementar un modelo de lenguaje grande (LLM) mediante sus workers vLLM preconfigurados.
| Módulo GPU | RunPod | Novita AI |
|---|---|---|
| Sin servidor | ✅ Inferencia a corto plazo | ✅ Inferencia a corto plazo |
| Instancia | ✅ Instancias de GPU | ✅ Instancias de GPU |
| Almacenamiento | ✅ Almacenamiento persistente y almacenamiento en red | ✅ Almacenamiento persistente y almacenamiento en red |
| Bare Metal | ❌ No disponible | ✅ Servidores físicos dedicados |
| Ajuste fino | ✅ Servicio de ajuste fino integrado | ❌ No disponible directamente |
| Clústeres | ✅ Distribuido mult GPU | ✅ Distribuido mult GPU |
| Región | ✅ La mayoría de los clústeres de región son compatibles | ⚠️ Solo dos clústeres de región son compatibles |
Diferencia en el servicio sin servidor
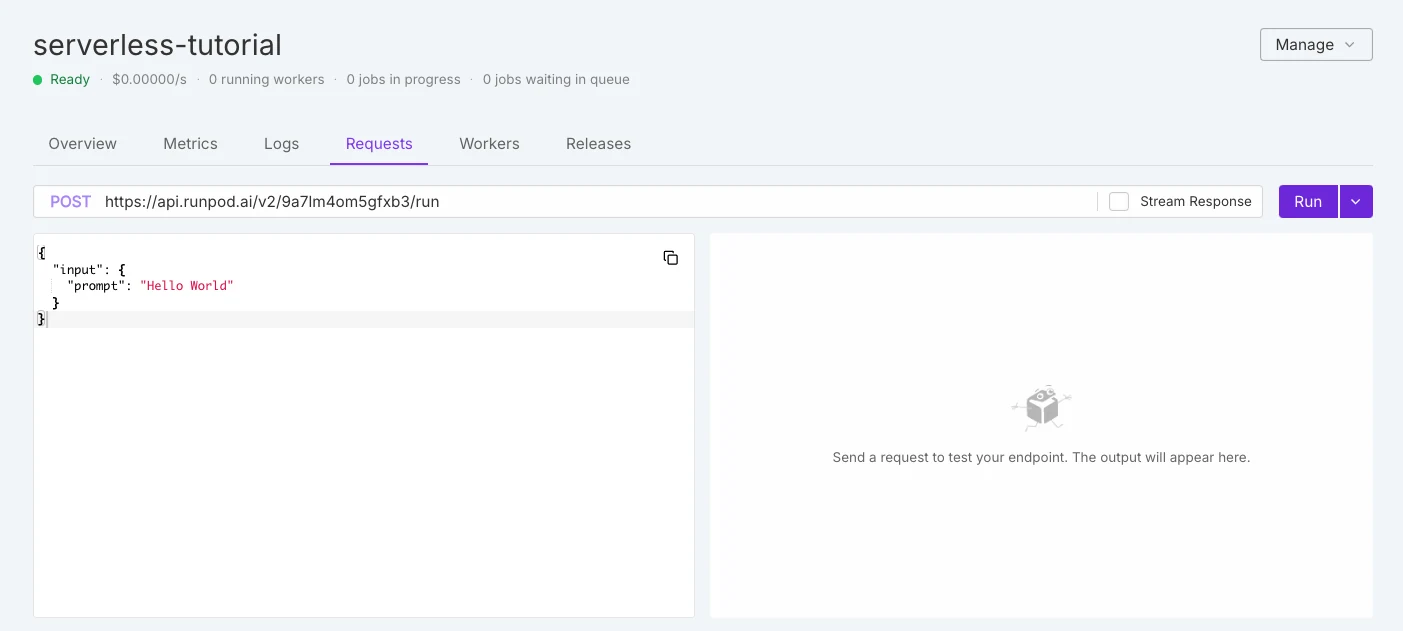
RunPod sin servidor
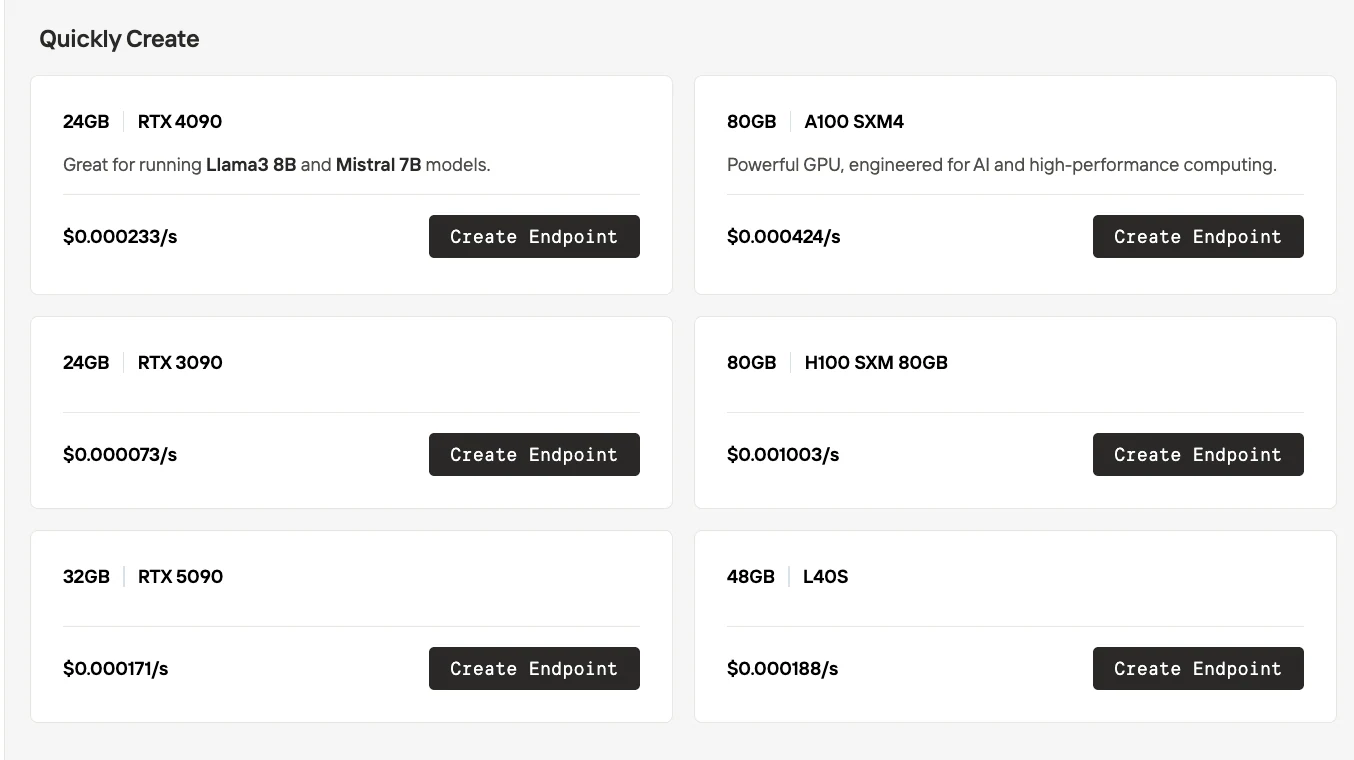
Novita AI sin servidor
| Aspecto | RunPod sin servidor | Novita AI sin servidor |
|---|---|---|
| Selección de GPU | Modelo caja negra: las GPUs son asignadas automáticamente por la plataforma. Los usuarios no pueden elegir el tipo de GPU exacto. | Modelo caja blanca: los usuarios seleccionan explícitamente el tipo de GPU (por ejemplo, RTX 3090, 4090, 5090, A100, H100, L40S) antes de crear un endpoint. |
| Precios | Se factura según el tipo de GPU asignado automáticamente en tiempo de ejecución. | Los precios son transparentes y se muestran por tipo de GPU (por ejemplo, $0.000073/s para RTX 3090, $0.000233/s para RTX 4090, etc.). |
| Control | Más fácil para implementaciones rápidas, pero menos flexibilidad para la optimización de relación costo-rendimiento. | Más flexible: los equipos pueden equilibrar las necesidades de costo, rendimiento y VRAM eligiendo la GPU. |
Diferencia de regiones
- RunPod: La mayoría de las regiones admiten tanto nodos de región como de clúster.
- Novita AI: Solo dos regiones admiten actualmente ambos tipos. Sin embargo, Novita AI lanzará este trimestre su función de GPU de región con caché mejorada, una capacidad que antes solo estaba disponible para clientes empresariales.
Nodos de región Definición: Nodos centralizados de alta calidad diseñados para cargas de trabajo estables a largo plazo. Características clave:
- Cómputo fiable y de alto rendimiento con capacidad sostenida.
- Incluye NAS (almacenamiento adjunto a la red) para acceso compartido a datos, adecuado para cargas de trabajo que requieren acceso repetido a conjuntos de datos.
- Líneas dedicadas y servicios auxiliares para una fiabilidad de nivel empresarial.
- Ideal para tareas a largo plazo como entrenamiento de modelos y servicios de inferencia continua.
- Nota: El NAS aquí es almacenamiento en caché/compartido, no almacenamiento permanente: los usuarios aún deben realizar copias de seguridad de los datos de forma externa. Analogía: Como un espacio de oficina dedicado: totalmente equipado y estable, ideal para proyectos a largo plazo.
Nodos de clúster Definición: Nodos de cómputo elásticos y distribuidos diseñados para uso a corto plazo o bajo demanda. Características clave:
- Sin NAS, sin almacenamiento en caché o almacenamiento a largo plazo.
- Sin líneas dedicadas; los nodos son más distribuidos y flexibles.
- Optimizados para cómputo elástico a gran escala a corto plazo (por ejemplo, experimentos únicos, tareas paralelas temporales).
- Más rentables, pero menos adecuados para cargas de trabajo permanentes. Analogía: Como un espacio de coworking compartido: fácil de usar, flexible y económico, pero no está pensado para residencia permanente.
Comparativa de usabilidad entre RunPod y Novita AI (ejemplo con instancias de GPU)
Novita AI
Paso 1. Elige una plantilla / Crea una plantilla y selecciona la GPU
- Selecciona una plantilla predefinida (con controladores de GPU, CUDA/cuDNN, frameworks y entorno de ejecución ya configurados) o crea tu propia plantilla personalizada y elige los tipos de GPU y las cantidades.
Paso 2. Confirma el disco y la configuración
- Revisa y ajusta la configuración técnica: tipo de GPU (por ejemplo, RTX 4090, VRAM, CPU, RAM), imagen de contenedor, comando de inicio, variables de entorno, puertos expuestos y tamaño de disco.
Paso 3. Confirma el pago
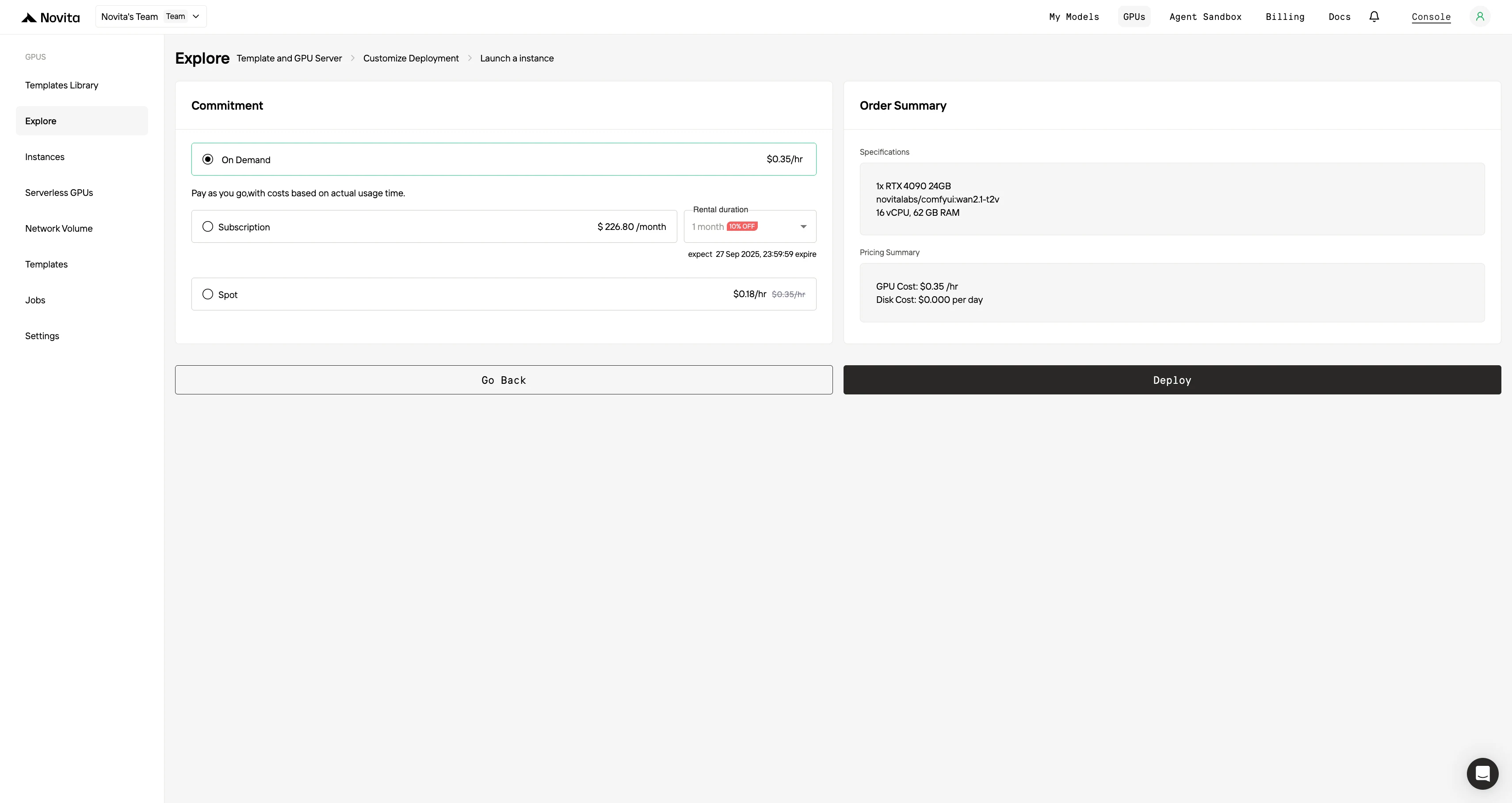
- Elige el modo de facturación (bajo demanda o spot, o suscripción de 1 a 12 meses) y revisa el resumen de precios (costo de la GPU por hora, costo del disco por día, totales mensuales).
RunPod
Paso 1. Selecciona la GPU
- Explora los tipos de GPU disponibles (por ejemplo, B200, H200, A40, RTX 5090). Puedes filtrar por VRAM, región u otros atributos.
Paso 2. Configura la instancia
- Qué es: Ajusta las opciones de entorno y tiempo de ejecución, el tamaño del volumen de disco y opciones adicionales como Volumen cifrado, Acceso a terminal SSH y si se debe iniciar automáticamente un cuaderno Jupyter.
RunPod tiene más de 50 plantillas preconfiguradas para que no tengas que personalizar parámetros complejos.
Paso 3. Elige el plan de precios
- Selecciona cómo quieres pagar por la instancia.
- Opciones disponibles:
- Bajo demanda
- Plan de ahorro de 3 meses
- Plan de ahorro de 6 meses
- Plan de ahorro de 12 meses
- Spot
Comparativa de planes de precios de RunPod y Novita AI
| Aspecto de precios | RunPod | Novita AI |
|---|---|---|
| Capa gratuita / Créditos | No tiene capa gratuita permanente de GPU. Los nuevos usuarios pueden obtener créditos de prueba, y las startups que cumplan los requisitos pueden recibir hasta 1000 horas gratuitas de H100 a través del Programa para Startups |
No tiene capa gratuita permanente. Novita también cuenta con un programa para startups (anuncian hasta $10k en créditos gratuitos para startups que cumplan los requisitos) |
| Precio de instancia de GPU | Las instancias de GPU tienen tarifas por hora (facturadas por minuto). | Las instancias de GPU tienen tarifas por hora (facturadas por minuto). |
| Precio spot | Más bajo que el precio de GPU bajo demanda | 50% del precio de GPU bajo demanda |
| Precio sin servidor | /por trabajador/segundo |
| Tipo de almacenamiento | Novita AI (Por GB/día) | RunPod (Por GB/mes) |
|---|---|---|
| Disco de contenedor | $0.005/GB/día, incluye 60 GB de cuota gratuita | $0.10/GB/mes |
| Disco persistente (volumen) | $0.005/GB/día | $0.10/GB/mes para pods en ejecución (igual que el disco de contenedor) $0.20/GB/mes para pods detenidos |
| Volumen de red (almacenamiento en la nube) | $0.002/GB/día | $0.07/GB/mes (<1 TB) $0.05/GB/mes (≥1 TB) |
En RunPod, el almacenamiento se factura por segundo, no como una tarifa mensual fija. La tarifa de “$0.10 por GB al mes” es solo una referencia: si mantienes 1 GB durante 30 días completos, cuesta aproximadamente $0.10. Si solo lo mantienes durante unos días u horas, el costo se prorratea por segundo, por lo que pagas mucho menos.
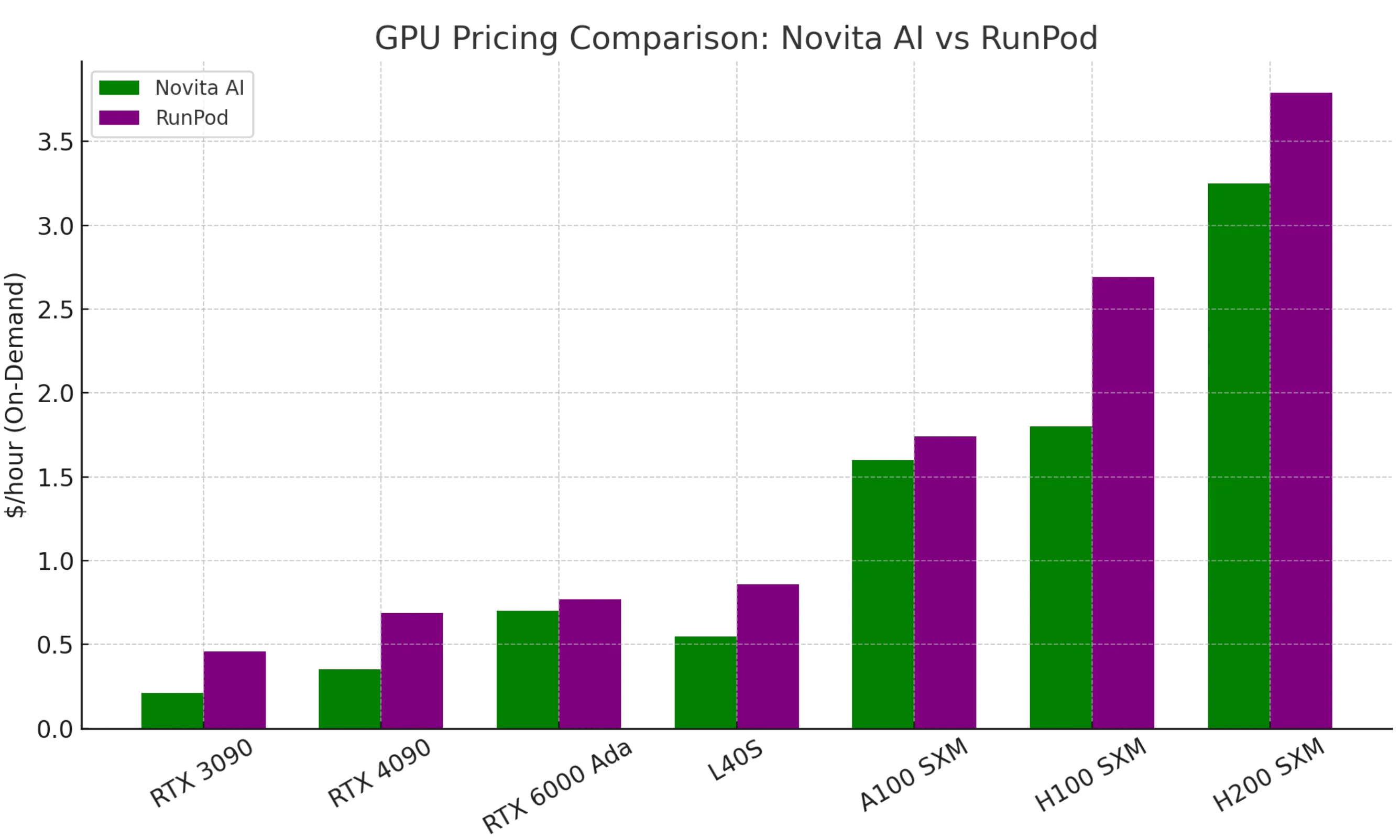
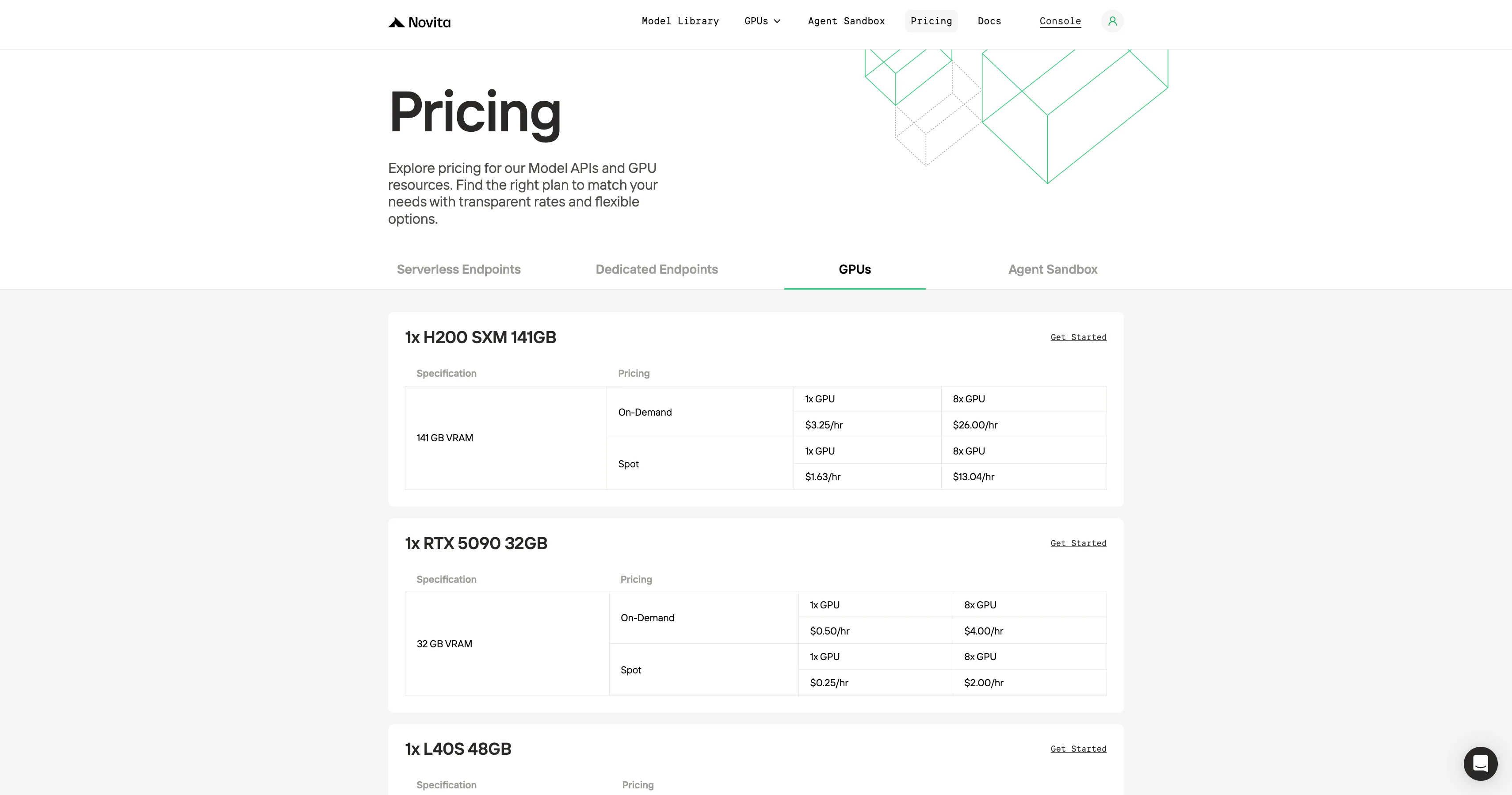
Comparativa de precios bajo demanda de GPU
El principal atractivo de Novita es su bajo costo. Las GPUs equivalentes suelen costar la mitad que en RunPod o en competidores.
¿RunPod o Novita AI es mejor para equipos pequeños?
| Aspecto | RunPod | Novita AI | ¿Cuál es mejor para equipos pequeños? |
|---|---|---|---|
| Instancias de GPU (usabilidad) | Paso 1: Selecciona GPU Paso 2: Configura la instancia. Más de 50 plantillas predefinidas Paso 3: Selecciona el plan de precios |
Paso 1: Elige o crea una plantilla + GPU. Paso 2: Configura el disco, el entorno de ejecución, las variables de entorno. Paso 3: Confirma el pago |
Ambos son sencillos. RunPod tiene más plantillas; Novita hace hincapié en la personalización y el menor costo. |
| Sin servidor | Asignación de GPU en caja negra, implementación rápida, pero los precios son menos transparentes. | Selección de GPU en caja blanca, precios transparentes por tipo de GPU, permite controlar costos. | Novita AI: precios más claros, mejor relación costo-rendimiento. |
| Región | Cobertura madura en muchas regiones, estable para cargas de trabajo a largo plazo, pero la elección de GPU es limitada y los precios son opacos. | Nodos de región con precios de GPU transparentes, funciones de caché próximamente, pero menos regiones admitidas actualmente. | Si necesitas estabilidad y cobertura global → RunPod. |
| Escalabilidad | Admite clústeres mult GPU, servicio de ajuste fino, almacenamiento persistente. Adecuado para entrenamiento distribuido. | Admite clústeres mult GPU, almacenamiento persistente. | RunPod es mejor para entrenamiento a gran escala y ajuste fino |
| Precios | Instancias de GPU facturadas por minuto. Spot más barato que bajo demanda. |
Generalmente un 50% más barato que RunPod. | Novita es generalmente mucho más económico: ventajoso para equipos pequeños con presupuesto limitado. |
| APIs | ❌ No tiene APIs de LLM predefinidas, pero admite la implementación de workers vLLM. | ✅ Más de 200 APIs listas para usar (LLM, imagen, vídeo, embeddings, etc.), directamente invocables mediante REST. | Novita AI es mejor para equipos que quieren funcionalidades de IA rápidas sin necesidad de entrenamiento. |
Para equipos pequeños o startups, Novita AI es generalmente la mejor opción debido a sus precios más bajos, flexibilidad de GPU y extensas APIs predefinidas.
RunPod es más fuerte para equipos centrados en entrenamiento a gran escala, ajuste fino y flujos de trabajo integrados con GitHub.
¿Cómo acceder a RunPod?
Empezar a usar RunPod es sencillo. Aquí tienes una guía paso a paso para desarrolladores:
- Regístrate: Ve a runpod.io y crea una cuenta (puedes registrarte con un correo electrónico o usar inicio de sesión único con servicios como Google/GitHub). Después de verificar tu cuenta, accederás al panel de control de RunPod.
- Lanza un pod de GPU: En la consola de RunPod, ve a la sección “GPUs en la nube” o “Pods” para implementar tu primera instancia de GPU. Normalmente:
- Elige una región (por ejemplo, Oeste de EE. UU., UE, etc.) y un tipo de GPU (por ejemplo, RTX 4090, A100) de la lista de instancias disponibles. El precio de cada una se muestra al seleccionarla.
- Selecciona una plantilla de entorno. RunPod proporciona plantillas predefinidas (como Ubuntu con CUDA, cuaderno Jupyter, Stable Diffusion, etc.), o puedes usar tu propia imagen de Docker. Para un inicio rápido, elige algo como una plantilla de cuaderno Jupyter para tener un IDE listo para usar.
- Haz clic en Implementar. En segundos o un minuto, RunPod iniciará tu contenedor en la GPU elegida. Verás que el estado del pod pasa a “En ejecución” en el panel de control.
- Conéctate y usa: Una vez que el pod esté en ejecución, puedes conectarte a él. Si es una plantilla de Jupyter, se proporcionará una URL para abrir la interfaz de Jupyter en tu navegador (con respaldo de GPU). Para otros entornos, puedes abrir un shell web o usar SSH (RunPod proporciona los detalles de conexión en la interfaz de usuario). Ahora puedes ejecutar tu código o entrenar tu modelo en esta GPU remota.
- Endpoints sin servidor (opcional): Si tu objetivo es implementar un endpoint de inferencia (sin servidor), RunPod tiene una sección para Sin servidor. Debes crear un nuevo Endpoint, especificar un modelo o usar una plantilla de servicio de modelos predefinida, e implementarla. RunPod te proporcionará una URL de endpoint de API. Este endpoint se escalará automáticamente a medida que lleguen solicitudes. Esto es ideal para ofrecer una API a tu aplicación sin tener que mantener un pod en ejecución 24/7.
- Gestiona y supervisa: En el panel de control, puedes ver tus pods en ejecución, su utilización y la información de créditos/facturación. Puedes detener o terminar pods cuando no los uses para ahorrar dinero (ya que la facturación es por segundo). También puedes configurar políticas de apagado automático (por ejemplo, terminar un pod después de una hora de inactividad). Al principio, todo se puede gestionar mediante la interfaz web. Para usos avanzados, explora la CLI y la API de RunPod para scriptar implementaciones a medida que tu equipo crezca.
¿Cómo acceder a Novita AI?
Guía de GPU
Paso 1: Registra una cuenta Crea tu cuenta de Novita AI a través de nuestro sitio web. Después del registro, ve a la sección “Explorar” en la barra lateral izquierda para ver nuestra oferta de GPUs y comenzar tu viaje en el desarrollo de IA.

Paso 2: Explora plantillas y servidores GPU Elige entre plantillas como PyTorch, TensorFlow o CUDA que se adapten a las necesidades de tu proyecto. Luego selecciona tu configuración de GPU preferida y las cantidades de GPU: las opciones incluyen las potentes L40S, RTX 4090 o A100 SXM4, cada una con diferentes especificaciones de VRAM, RAM y almacenamiento.
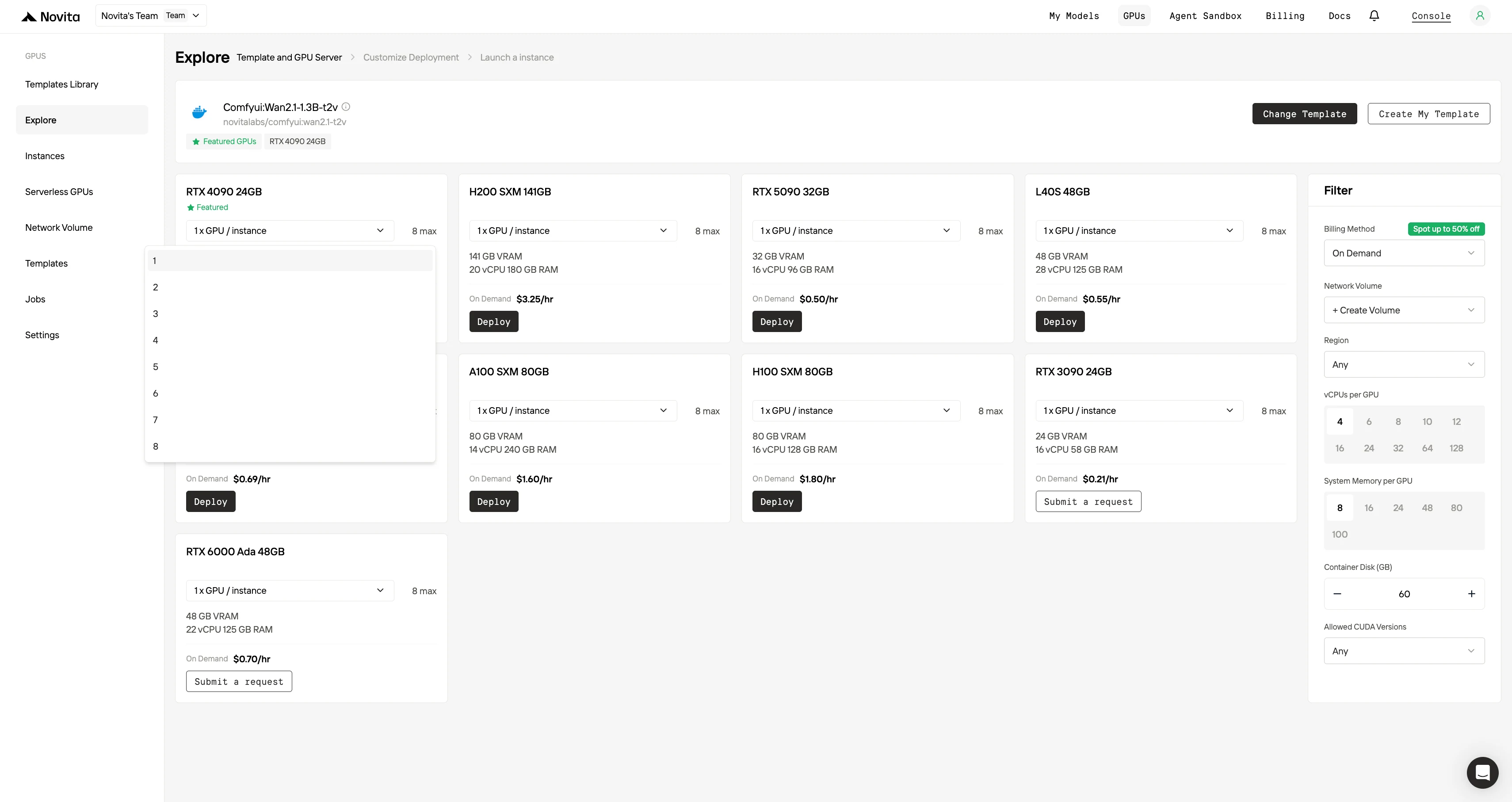
Paso 3: Personaliza tu implementación Personaliza tu entorno seleccionando tu sistema operativo preferido y las opciones de configuración para garantizar un rendimiento óptimo para tus cargas de trabajo de IA específicas y tus necesidades de desarrollo.
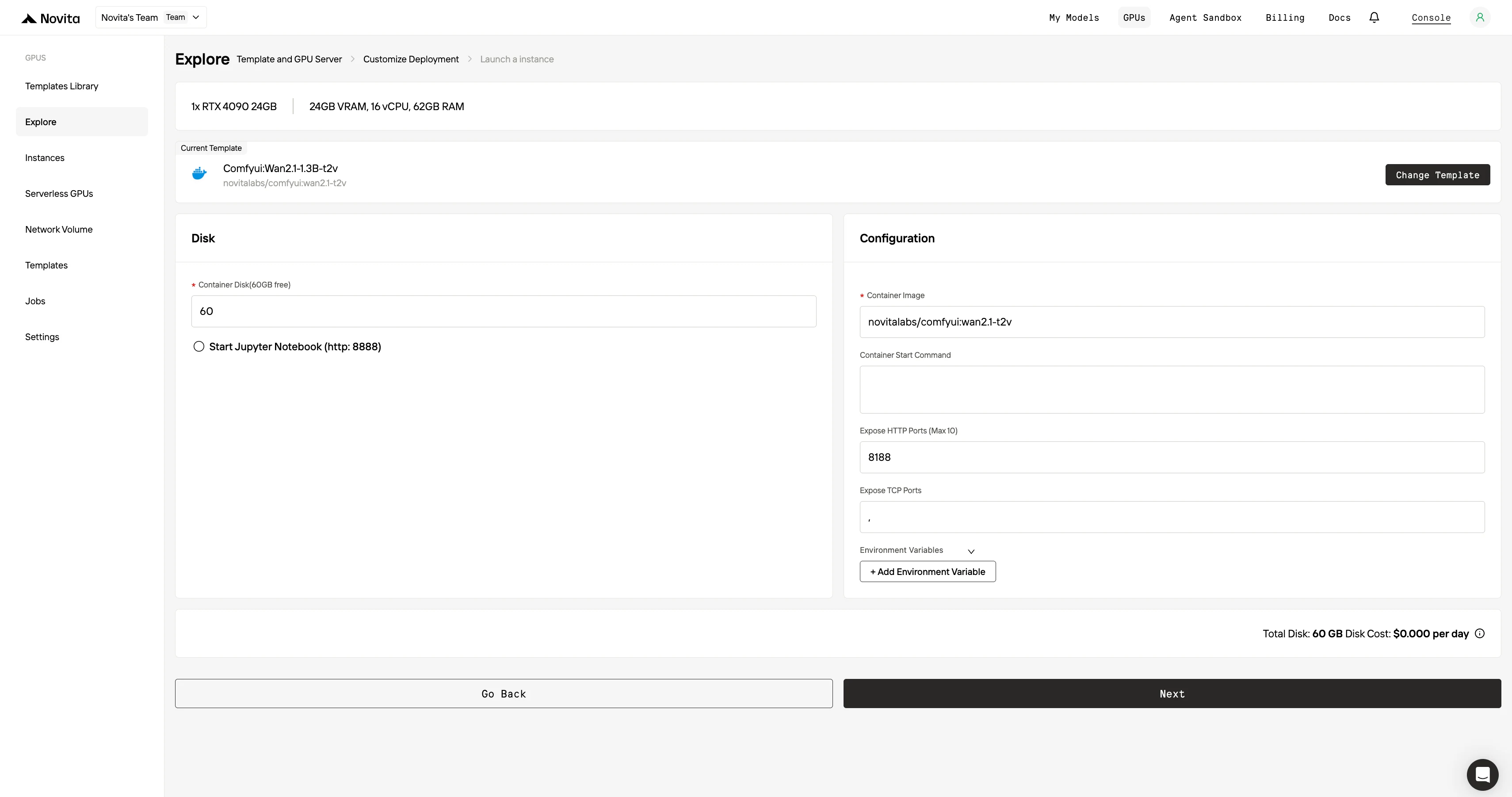
Paso 4: Lanza una instancia Selecciona “Lanzar instancia” para iniciar tu implementación. Tu entorno de GPU de alto rendimiento estará listo en minutos, lo que te permitirá comenzar inmediatamente tus proyectos de aprendizaje automático, renderizado o computación.
Guía de API (ejemplo con Kimi K2)
Paso 1: Inicia sesión y accede a la biblioteca de modelos Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Paso 2: Elige tu modelo Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Inicia tu prueba gratuita Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
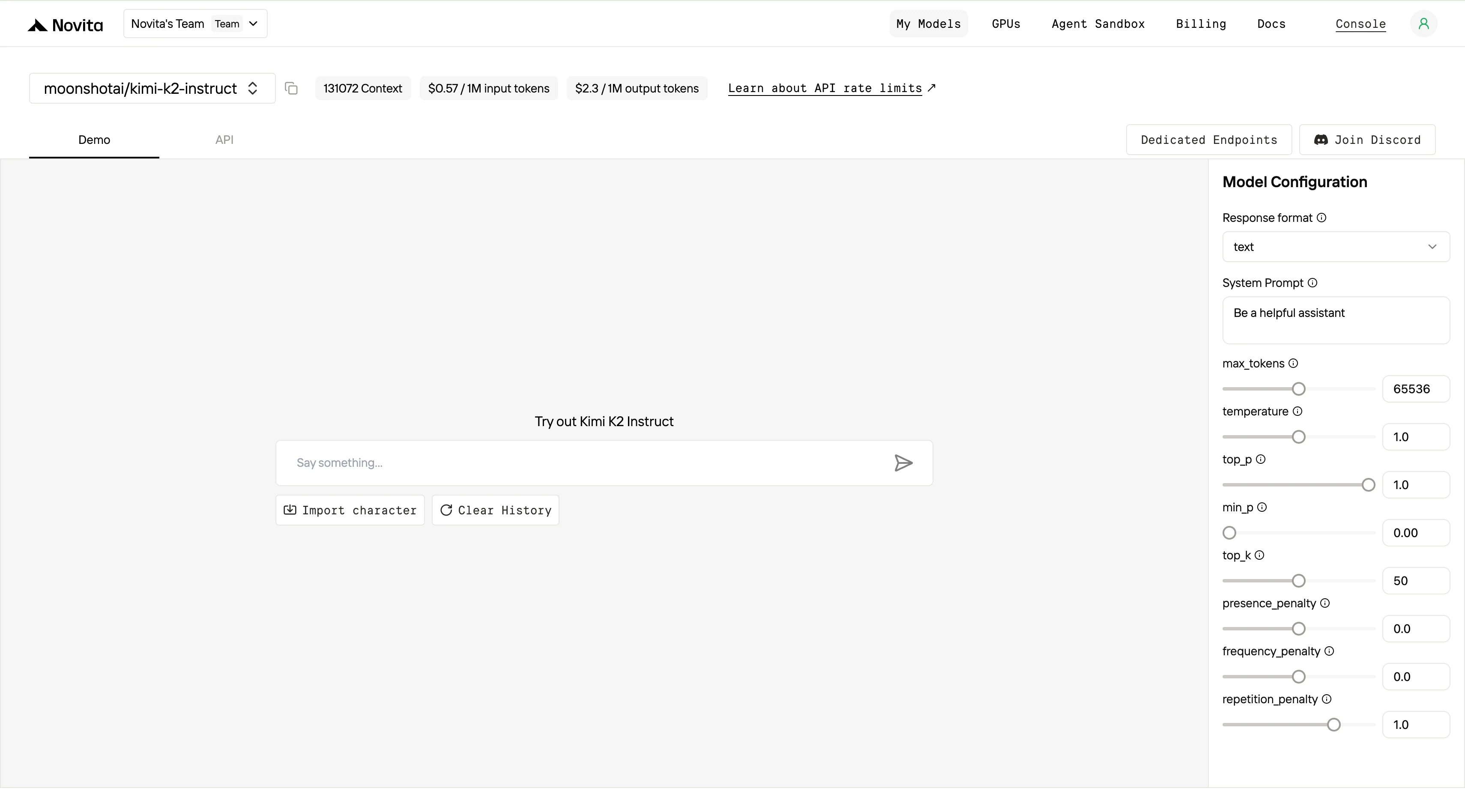
Paso 4: Obtén tu clave de API Para autenticarte con la API, te proporcionaremos una nueva clave de API. Entrando en la página “Configuración”, puedes copiar la clave de API como se indica en la imagen.

Paso 5: Instala la API Instala la API mediante el gestor de paquetes específico de tu lenguaje de programación. Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con el LLM de Novita AI. Este es un ejemplo de uso de la API de finalización de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Uso del Agent Sandbox (opcional): Novita también cuenta con una función Agent Sandbox accesible desde el panel de control. Esto te permite ejecutar agentes de IA o código en un entorno sandbox totalmente gestionado con aislamiento de internet. Si tu caso de uso implica cosas como evaluar código generado por un agente de IA, esto puede ser muy útil. Puedes explorarlo una vez que estés familiarizado con los conceptos básicos.
Cuándo elegir Novita AI
- Presupuesto ajustado: Novita es generalmente alrededor de un 50% más barato que RunPod por el uso de GPU, con almacenamiento muy económico y generosos créditos gratuitos para startups.
- Necesitas funcionalidad rápida y sin complicaciones: Con más de 200 APIs predefinidas (LLM, imagen, audio, vídeo), es ideal si quieres funcionalidades impulsadas por IA sin gestionar infraestructura.
- Prefieres simplicidad y velocidad: Genial para integrar la IA rápidamente, especialmente si el entrenamiento o ajuste fino no es una prioridad.
Ideal para: Desarrolladores independientes, startups y equipos de producto que necesitan una integración rápida de IA sin preocuparse por el hardware o la configuración.
Cuándo elegir RunPod
- Planificas flujos de trabajo de entrenamiento complejos: Ofrece un soporte fuerte para clústeres mult GPU, almacenamiento persistente y servicios de ajuste fino integrados.
- Necesitas escalabilidad o cómputo robusto: Genial para entrenar modelos grandes, configuraciones multinodo o experimentos a largo plazo.
- Prefieres estandarización entre regiones: Su presencia en más de 30 regiones globales y su extensa biblioteca de plantillas simplifican las implementaciones.
- Trabajas estrechamente con repositorios de código/GitHub: El soporte integrado para Repos sin servidor hace que sea sencillo implementar directamente desde proyectos de código abierto.
Preguntas frecuentes
¿Puedo implementar clústeres mult GPU? Solo RunPod admite esto de forma nativa mediante su función Instant Clusters. Novita AI actualmente admite escalado mediante sin servidor y escalado vertical, pero no clústeres gestionados por el usuario.
¿Cuál es más barato para ejecutar una GPU 4090 o A100? Novita AI es generalmente más barata: ofrece la RTX 4090 a ~$0.35/hora y la A100 alrededor de ~$1.2/hora (con precios spot aún más bajos). RunPod ofrece más regiones y flexibilidad, pero cuesta un poco más por hora.
¿RunPod ofrece una API de LLM como OpenAI? L40S. Su TDP de 300-350W y su fuerte rendimiento por vatio lo convierten en una opción mejor para implementaciones sensibles al consumo de energía. El H100 (hasta 700W SXM5) requiere una infraestructura significativa. Sí. RunPod proporciona Endpoints sin servidor mediante vLLM, lo que te permite implementar modelos de Hugging Face y exponerlos mediante APIs de estilo OpenAI. Puedes llamar a estos endpoints mediante REST o integrarlos con LangChain.
Novita AI es una plataforma de IA en la nube que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, además de proporcionar una GPU en la nube económica y fiable para construir y escalar.
Lecturas recomendadas



