

- Introdução à Novita AI
- Introdução ao RunPod
- Compare a Escalabilidade do RunPod e da Novita AI
- Compare a Usabilidade do RunPod e da Novita AI (Instância GPU como Exemplo)
- Compare os Planos de Preços do RunPod e da Novita AI
- O RunPod ou a Novita AI é Melhor para Pequenas Equipes?
- Como Acessar o RunPod?
- Como Acessar a Novita AI?
- Quando Escolher a Novita AI
- Quando Escolher o RunPod
- Leitura Recomendada
Para desenvolvedores, escolher a plataforma de cloud AI certa geralmente se resume a três coisas: custo, facilidade de uso e escalabilidade. Tanto a Novita AI quanto o RunPod oferecem infraestrutura e ferramentas potentes com suporte a GPU para implantar, treinar ou executar modelos de IA — mas atendem a necessidades de desenvolvedores ligeiramente diferentes.
- A Novita AI se destaca em inferência rápida e acessível por meio de APIs plug-and-play e acesso Serverless a GPUs — ideal para desenvolvedores independentes, startups e equipes de produto que precisam de integração rápida de IA sem se preocupar com hardware ou configuração.
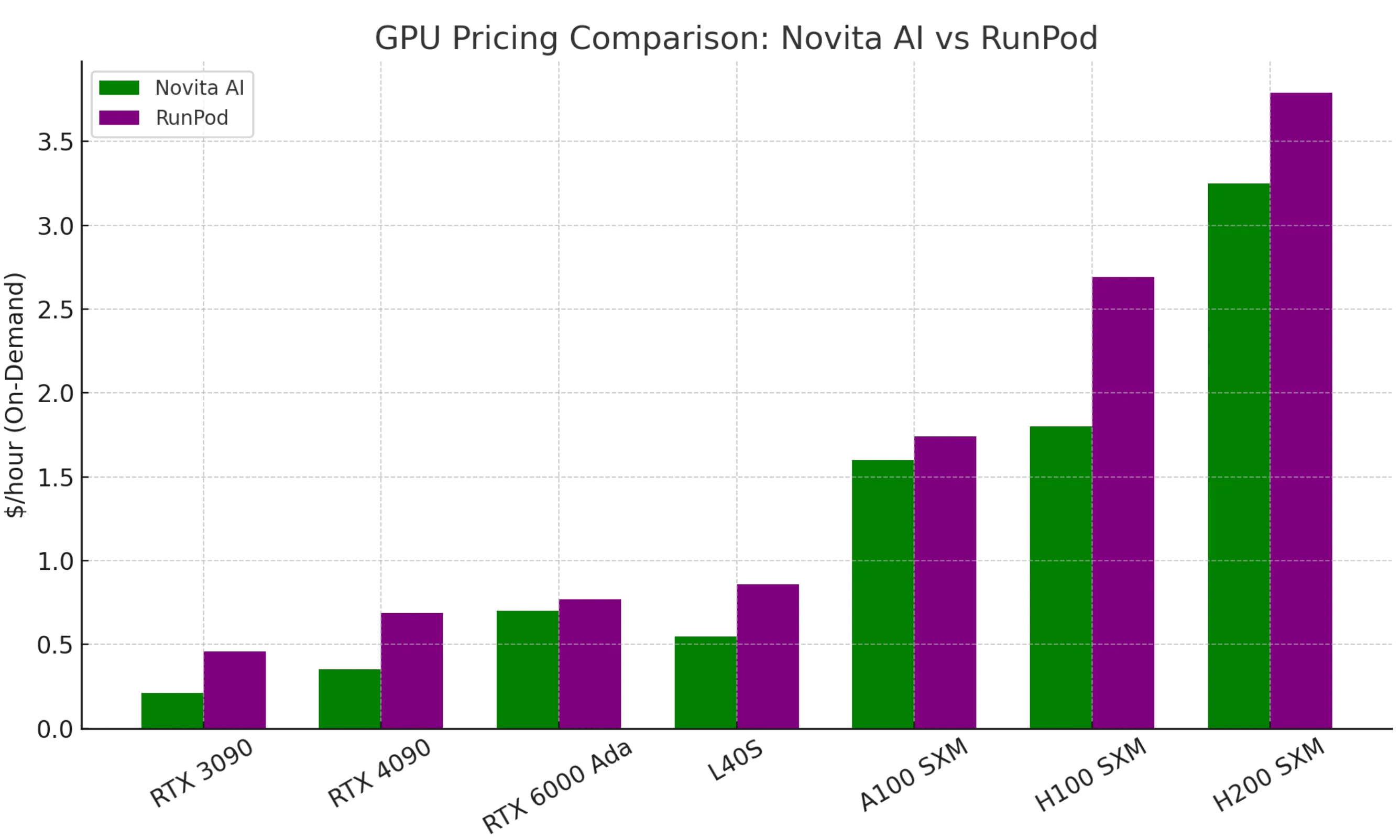
O principal ponto de venda da Novita é o baixo custo. GPUs equivalentes geralmente custam metade do preço em comparação com o RunPod ou concorrentes.
- O RunPod se destaca com seu ambiente de desenvolvimento maduro, pods configuráveis e suporte robusto para cargas de trabalho de inferência e treinamento — ideal para engenheiros de ML ou equipes de desenvolvimento que constroem e ajustam modelos, precisando de controle, escalabilidade e flexibilidade de infraestrutura.
Neste post, detalhamos as vantagens e desvantagens de cada plataforma para ajudá-lo a decidir qual se adapta ao seu projeto.
Introdução à Novita AI

A Novita AI é uma plataforma de cloud que torna a implantação de modelos de IA fácil e acessível.
Ela fornece mais de 200 APIs prontas para uso para linguagem, visão, áudio e muito mais, além de infraestrutura de cloud GPU para modelos personalizados.
Os desenvolvedores podem integrar a IA rapidamente com APIs REST simples ou iniciar instâncias GPU sem lidar com hardware. Com seu foco em inferência confiável e de baixo custo, a Novita AI ajuda desenvolvedores independentes e empresas a lançar recursos alimentados por IA sem esforço.
Introdução ao RunPod
O RunPod é uma plataforma de cloud tudo-em-um para IA que oferece aos desenvolvedores acesso sob demanda a GPUs potentes para treinar, ajustar e implantar modelos. Com pods GPU disponíveis em mais de 30 regiões globais (sob demanda e spot), os usuários podem iniciar rapidamente qualquer coisa, de um notebook Jupyter a um cluster GPU multinó em minutos. Projetado para engenheiros de ML e equipes de desenvolvimento, o RunPod torna a escalabilidade da IA fácil e acessível — sem necessidade de DevOps.
Compare a Escalabilidade do RunPod e da Novita AI
A Novita AI oferece dezenas de APIs, incluindo APIs de LLM, imagem e vídeo, com novas sendo adicionadas continuamente. Você pode testá-las gratuitamente diretamente no Playground. O RunPod, embora não forneça APIs de LLM prontas para uso, permite implantar um modelo de linguagem grande (LLM) usando seus workers vLLM pré-configurados.
| Módulo GPU | RunPod | Novita AI |
|---|---|---|
| Serverless | ✅ Inferência de curto prazo | ✅ Inferência de curto prazo |
| Instância | ✅ Instâncias GPU | ✅ Instâncias GPU |
| Armazenamento | ✅ Armazenamento persistente e armazenamento de rede | ✅ Armazenamento persistente e armazenamento de rede |
| Bare Metal | ❌ Não disponível | ✅ Servidores físicos dedicados |
| Ajuste Fino | ✅ Serviço de ajuste fino integrado | ❌ Não disponível diretamente |
| Clusters | ✅ Distribuído multi-GPU | ✅ Distribuído multi-GPU |
| Região | ✅ A maioria dos Clusters de Região são suportados | ⚠️ Apenas dois Clusters de Região são suportados |
Diferença Serverless
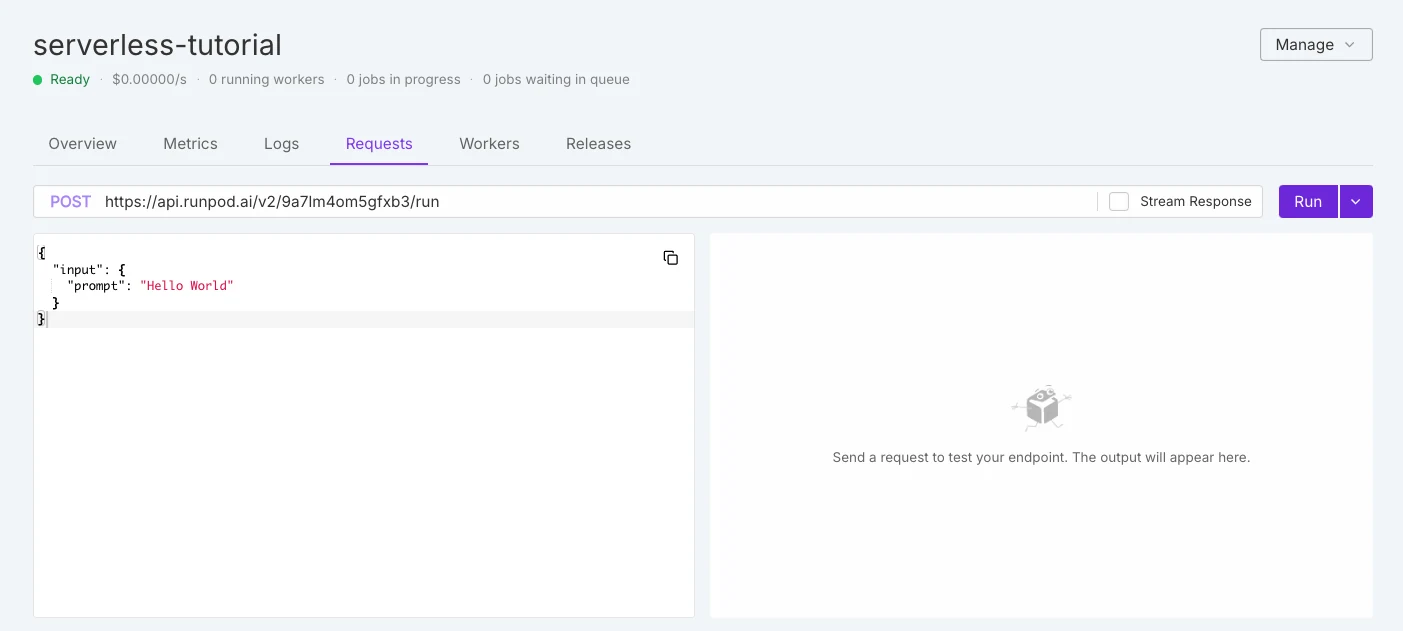
Runpod Serverless
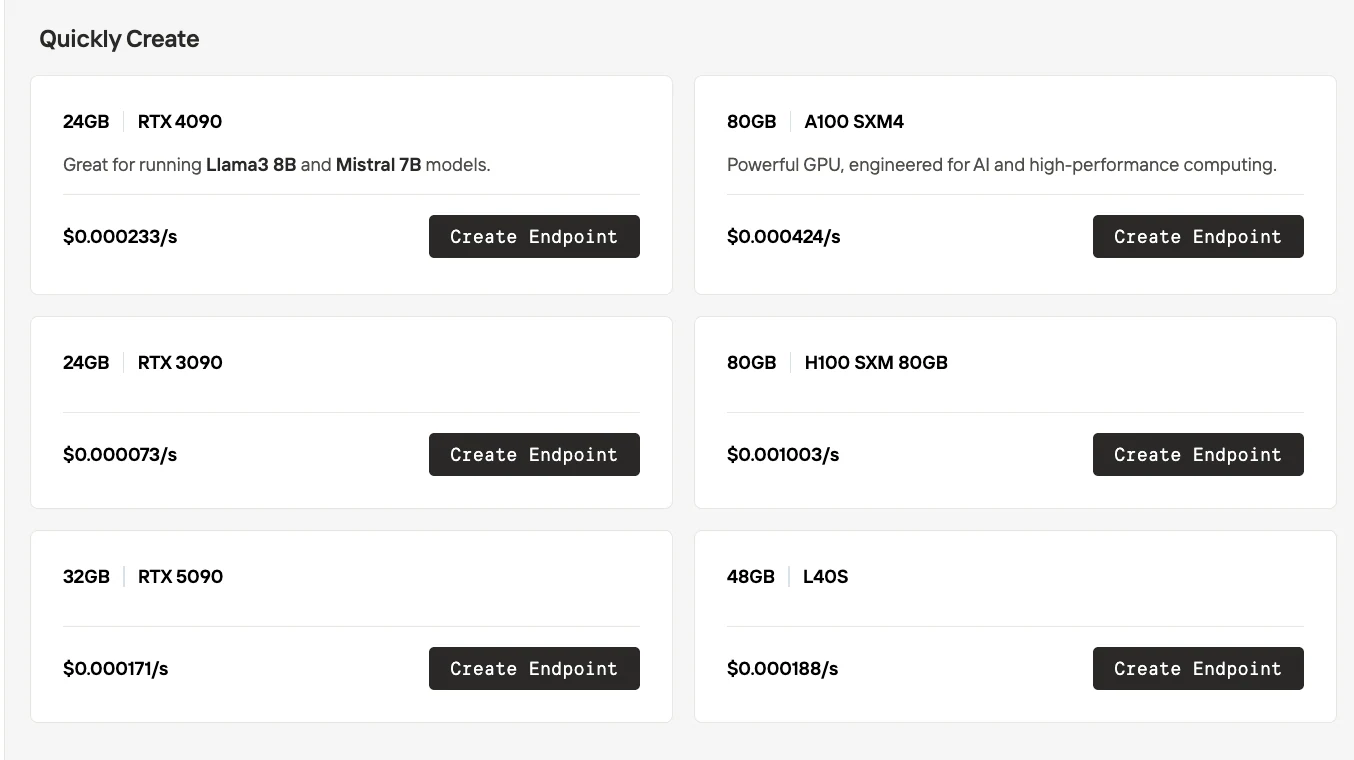
Novita AI serverless
| Aspecto | RunPod Serverless | Novita AI Serverless |
|---|---|---|
| Seleção de GPU | Modelo caixa-preta — as GPUs são atribuídas automaticamente pela plataforma. Os usuários não podem escolher o tipo exato de GPU. | Modelo caixa-branca — os usuários selecionam explicitamente o tipo de GPU (ex: RTX 3090, 4090, 5090, A100, H100, L40S) antes de criar um endpoint. |
| Preço | Cobrado de acordo com o tipo de GPU atribuído automaticamente em tempo de execução. | O preço é transparente e exibido por tipo de GPU (ex: $0,000073/s para RTX 3090, $0,000233/s para RTX 4090, etc.). |
| Controle | Mais fácil para implantação rápida, mas menos flexível para otimização de custo-desempenho. | Mais flexível: as equipes podem equilibrar as necessidades de custo, desempenho e VRAM escolhendo a GPU. |
Diferença de Região
- RunPod: A maioria das regiões suporta tanto nós de Região quanto de Cluster.
- Novita AI: Apenas duas regiões atualmente suportam ambos os tipos. No entanto, a Novita AI lançará este trimestre seu recurso de GPU de Região com cache aprimorado, uma capacidade que antes estava disponível apenas para clientes empresariais.
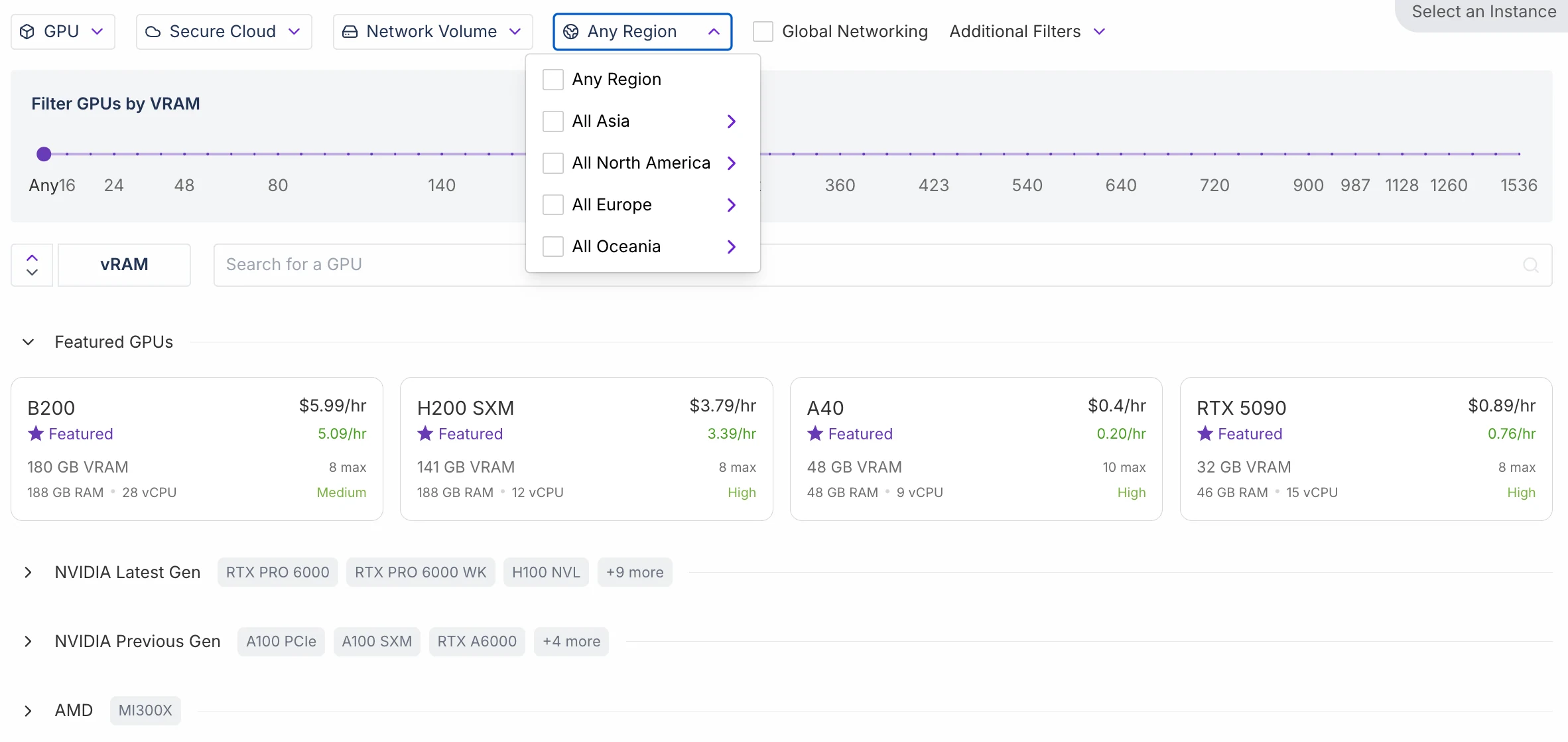
Nós de Região
Definição: Nós centralizados e de alta qualidade projetados para cargas de trabalho de longo prazo e estáveis.
Principais Características:
- Computação confiável e de alto desempenho com capacidade sustentável.
- Inclui NAS (armazenamento conectado à rede) para acesso compartilhado a dados — adequado para cargas de trabalho que exigem acesso repetido a conjuntos de dados.
- Linhas dedicadas e serviços auxiliares para confiabilidade de nível empresarial.
- Mais adequado para tarefas de longo prazo, como treinamento de modelos e serviços de inferência contínua.
- Observação: o NAS aqui é armazenamento em cache/compartilhado, não armazenamento permanente — os usuários ainda precisam fazer backup dos dados externamente.
Analogia: Como um espaço de escritório dedicado — totalmente equipado e estável, ideal para projetos de longo prazo.
Nós de Cluster
Definição: Nós de computação distribuídos e elásticos projetados para uso de curto prazo ou sob demanda.
Principais Características:
- Sem NAS, sem armazenamento de longo prazo ou cache.
- Sem linhas dedicadas; os nós são mais distribuídos e flexíveis.
- Otimizado para computação elástica de curto prazo e em larga escala (ex: experimentos únicos, tarefas paralelas temporárias).
- Mais econômico, mas menos adequado para cargas de trabalho permanentes.
Analogia: Como um espaço de coworking compartilhado — fácil de usar, flexível e acessível, mas não destinado a residência permanente.
Compare a Usabilidade do RunPod e da Novita AI (Instância GPU como Exemplo)
Novita AI
Passo 1. Escolha o Modelo / Crie um Modelo e Escolha a GPU
- Selecione um modelo pré-configurado (com drivers GPU, CUDA/cuDNN, frameworks e runtime já configurados) ou crie seu próprio modelo personalizado e escolha os tipos de GPU e as quantidades!
Passo 2. Confirme o Disco e a Configuração
- Revise e ajuste a configuração técnica: tipo de GPU (ex: RTX 4090, VRAM, CPU, RAM), imagem do contêiner, comando de inicialização, variáveis de ambiente, portas expostas e tamanho do disco.
Passo 3. Confirme o Pagamento
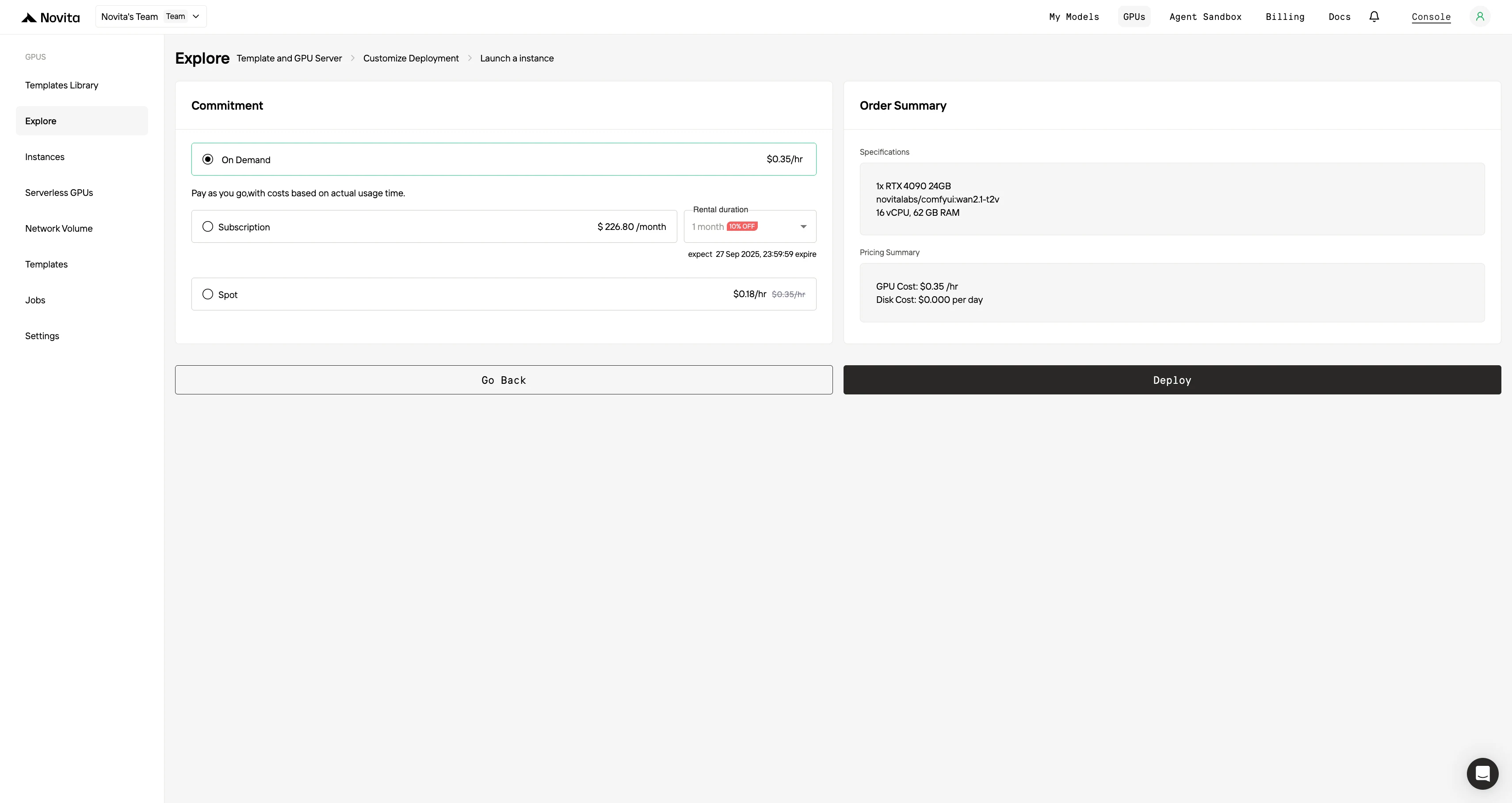
- Escolha o modo de cobrança (Sob Demanda vs. Spot, ou assinatura de 1 a 12 meses) e revise o resumo de preços (custo da GPU por hora, custo do disco por dia, totais mensais).
RunPod
Passo 1. Selecione a GPU
- Navegue pelos tipos de GPU disponíveis (ex: B200, H200, A40, RTX 5090). Você pode filtrar por VRAM, região ou outros atributos.
Passo 2. Configure a Instância
- O que é: Ajuste as opções de ambiente e runtime, tamanho do volume de disco e opções adicionais como Criptografar Volume, Acesso a Terminal SSH e se deve iniciar automaticamente um Notebook Jupyter.
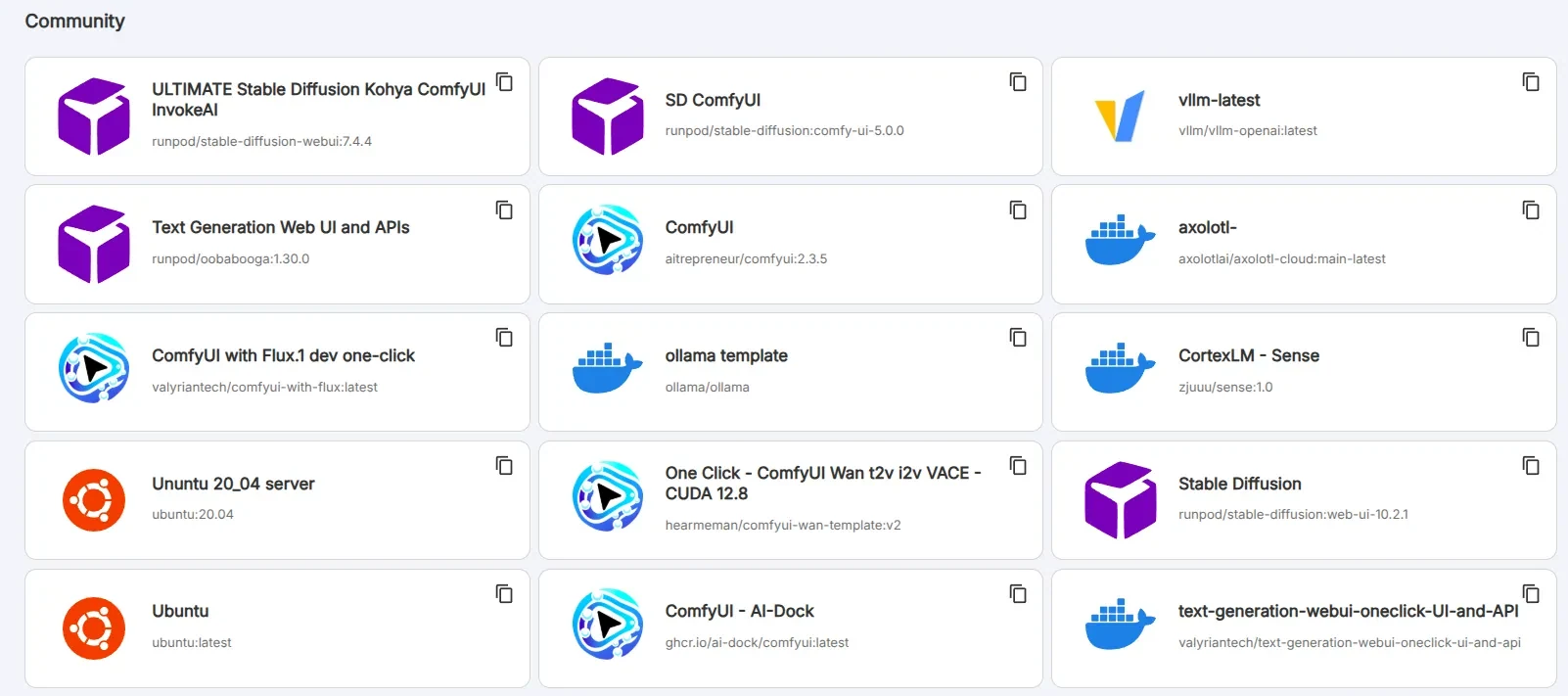
O Runpod tem mais de 50 modelos pré-configurados para que você não precise personalizar parâmetros complexos
Passo 3. Escolha o Plano de Preços
-
Selecione como deseja pagar pela instância.
-
Opções disponíveis:
- Sob Demanda
- Plano de Economia de 3 Meses
- Plano de Economia de 6 Meses
- Plano de Economia de 1 Ano
- Spot
Compare os Planos de Preços do RunPod e da Novita AI
| Aspecto de Preço | RunPod | Novita AI |
|---|---|---|
| Camada Gratuita / Créditos | Sem camada gratuita permanente de GPU. Novos usuários podem obter créditos de teste, e startups qualificadas podem receber até 1.000 horas gratuitas de H100 por meio do Programa para Startups |
Sem camada gratuita permanente. A Novita também tem um programa para startups (eles anunciam até $10k em créditos gratuitos para startups qualificadas) |
| Preço da Instância GPU | Instâncias GPU têm taxas horárias (cobradas por minuto). | Instâncias GPU têm taxas horárias (cobradas por minuto). |
| Preço Spot | Menor que o Preço de GPU Sob Demanda | 50% do Preço de GPU Sob Demanda |
| Preço Serverless | /Worker/segundo |
| Tipo de Armazenamento | Novita AI (Por GB/Dia) | RunPod (Por GB/Mês) |
|---|---|---|
| Disco do Contêiner | $0,005/GB/dia, inclui cota gratuita de 60 GB | $0,10/GB/mês |
| Disco Persistente (Volume) | $0,005/GB/dia | $0,10/GB/mês para pods em execução (mesmo que disco do contêiner) $0,20/GB/mês para pods encerrados |
| Volume de Rede (Armazenamento em Cloud) | $0,002/GB/dia | $0,07/GB/mês (<1 TB) $0,05/GB/mês (≥1 TB) |
No RunPod, o armazenamento é cobrado por segundo, não como uma taxa mensal fixa. A taxa de “$0,10 por GB por mês” é apenas uma referência: se você mantiver 1 GB por 30 dias completos, custa cerca de $0,10. Se você mantê-lo apenas por alguns dias ou horas, o custo é rateado por segundo, então você paga muito menos.
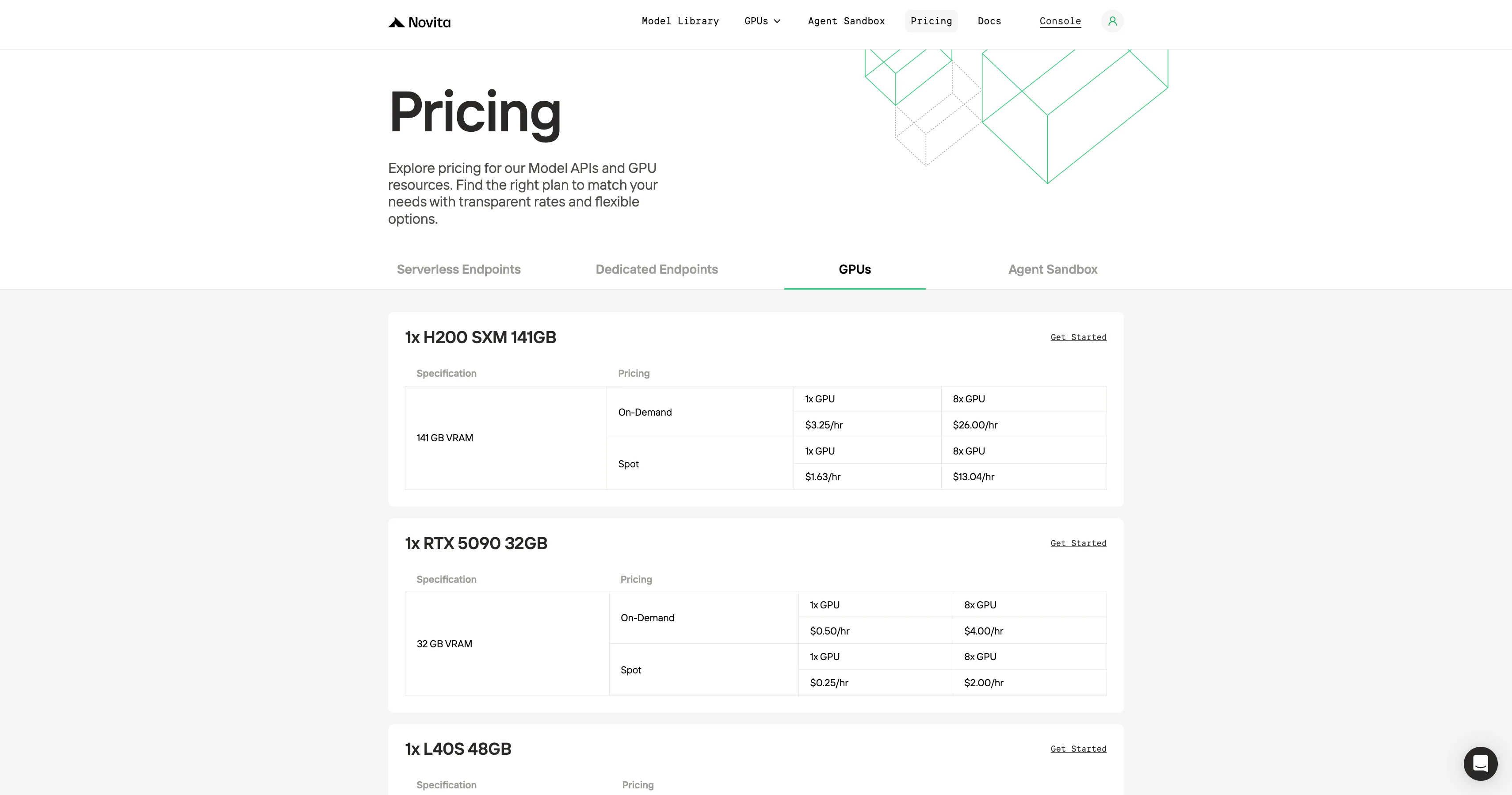
Comparação de Preço Sob Demanda de GPU
O principal ponto de venda da Novita é o baixo custo. GPUs equivalentes geralmente custam metade do preço em comparação com o RunPod ou concorrentes.
Você pode verificar se este é o menor preço?
O RunPod ou a Novita AI é Melhor para Pequenas Equipes?
| Aspecto | RunPod | Novita AI | Qual é Melhor para Pequenas Equipes? |
|---|---|---|---|
| Instâncias GPU (Usabilidade) | Passo 1: Selecione a GPU Passo 2: Configure a instância. Mais de 50 modelos pré-configurados Passo 3: Selecione o preço |
Passo 1: Escolha ou crie o modelo + GPU. Passo 2: Configure disco, runtime, variáveis de ambiente. Passo 3: Confirme o pagamento |
Ambos são intuitivos. O RunPod tem mais modelos; A Novita enfatiza personalização e menor custo. |
| Serverless | Atribuição de GPU em caixa-preta, implantação rápida, mas preço menos transparente. | Seleção de GPU em caixa-branca, preço transparente por GPU, permite controle de custos. | Novita AI — preço mais claro, melhor relação custo-desempenho. |
| Região | Cobertura madura em muitas regiões, estável para cargas de trabalho de longo prazo, mas a escolha de GPU é limitada e o preço opaco. | Nós de Região com preço de GPU transparente, recurso de cache chegando em breve, mas menos regiões suportadas atualmente. | Se você precisa de estabilidade e cobertura global → RunPod. |
| Escalabilidade | Suporta clusters multi-GPU, serviço de ajuste fino, armazenamento persistente. Adequado para treinamento distribuído. | Suporta clusters multi-GPU, armazenamento persistente. | RunPod é melhor para treinamento em larga escala e ajuste fino |
| Preço | Instâncias GPU cobradas por minuto. Spot mais barato que Sob Demanda. |
Geralmente 50% mais barato que o RunPod. | A Novita é geralmente muito mais barata — vantajosa para pequenas equipes com orçamento limitado. |
| APIs | ❌Sem APIs de LLM pré-construídas, mas suporta implantação de workers vLLM. | ✅Mais de 200 APIs prontas para uso (LLM, imagem, vídeo, embeddings, etc.), chamáveis diretamente via REST. | A Novita AI é melhor para equipes que desejam recursos de IA rápidos sem treinamento. |
Para pequenas equipes/startups, a Novita AI é geralmente a melhor opção devido ao menor preço, flexibilidade de GPU e extensas APIs pré-construídas.
O RunPod é mais forte para equipes focadas em treinamento em larga escala, ajuste fino e fluxos de trabalho integrados ao GitHub.
Como Acessar o RunPod?
Começar a usar o RunPod é simples. Aqui está um guia passo a passo para desenvolvedores:
- Cadastre-se: Acesse runpod.io e crie uma conta (você pode se cadastrar com um e-mail ou usar login único com serviços como Google/GitHub). Após verificar sua conta, você acessará o painel do RunPod.
- Inicie um Pod GPU: No console do RunPod, navegue até a seção “Cloud GPUs” ou “Pods” para implantar sua primeira instância GPU. Você geralmente:
- Escolhe uma região (por exemplo, Oeste dos EUA, UE, etc.) e um tipo de GPU (ex: RTX 4090, A100) na lista de instâncias disponíveis. O preço de cada uma é exibido conforme você seleciona.
- Seleciona um modelo de ambiente. O RunPod fornece modelos pré-configurados (como Ubuntu com CUDA, Notebook Jupyter, Stable Diffusion, etc.), ou você pode usar sua própria imagem Docker. Para um início rápido, escolha algo como um modelo de Notebook Jupyter para ter uma IDE pronta para usar.
- Clique em Implantar. Em segundos a um minuto, o RunPod iniciará seu contêiner na GPU escolhida. Você verá o status do pod se tornar “Em execução” no painel.
- Conecte e Use: Assim que o pod estiver em execução, você pode se conectar a ele. Se for um modelo Jupyter, um URL será fornecido para abrir a interface Jupyter no seu navegador (com suporte a GPU). Para outros ambientes, você pode abrir um shell web ou usar SSH (o RunPod fornece detalhes de conexão na interface). Agora você pode executar seu código ou treinar seu modelo nesta GPU remota.
- Endpoints Serverless (opcional): Se seu objetivo é implantar um endpoint de inferência (Serverless), o RunPod tem uma seção para Serverless. Você criaria um novo Endpoint, especificaria um modelo ou usaria um modelo pré-configurado de serving, e implantaria. O RunPod fornecerá um URL de endpoint de API. Este endpoint escalará automaticamente conforme as solicitações chegarem. Isso é ótimo para servir uma API para seu aplicativo sem manter um pod rodando 24 horas por dia, 7 dias por semana.
- Gerencie e Monitore: No painel, você pode ver seus pods em execução, sua utilização e suas informações de crédito/cobrança. Você pode parar ou encerrar pods quando não estiverem em uso para economizar dinheiro (já que a cobrança é por segundo). Você também pode configurar políticas de desligamento automático (ex: encerrar um pod após uma hora de inatividade). Tudo pode ser gerenciado pela interface web inicialmente. Para uso avançado, explore a CLI e a API do RunPod para script de implantações conforme sua equipe cresce.
Como Acessar a Novita AI?
Guia de GPU
Passo 1: Registre uma conta
Crie sua conta Novita AI por meio do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para visualizar nossas ofertas de GPU e começar sua jornada de desenvolvimento de IA.

Experimente usar a Novita AI agora
Passo 2: Explore Modelos e Servidores GPU
Escolha entre modelos como PyTorch, TensorFlow ou CUDA que correspondam às necessidades do seu projeto.
Em seguida, selecione sua configuração de GPU preferida e as quantidades de GPU — as opções incluem as potentes L40S, RTX 4090 ou A100 SXM4, cada uma com diferentes especificações de VRAM, RAM e armazenamento.
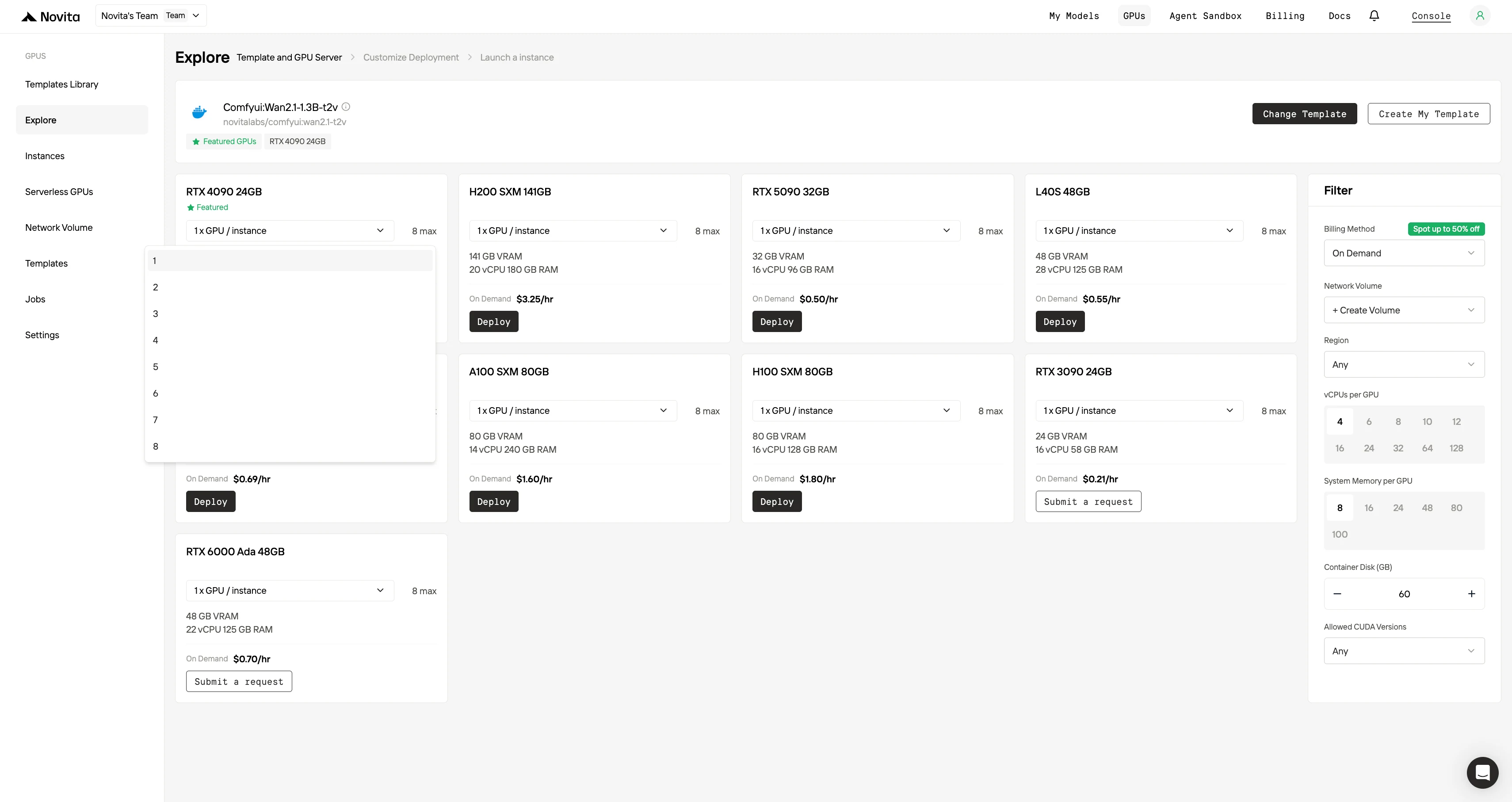
Passo 3: Personalize sua Implantação
Personalize seu ambiente selecionando seu sistema operacional preferido e opções de configuração para garantir o desempenho ideal para suas cargas de trabalho de IA e necessidades de desenvolvimento específicas.
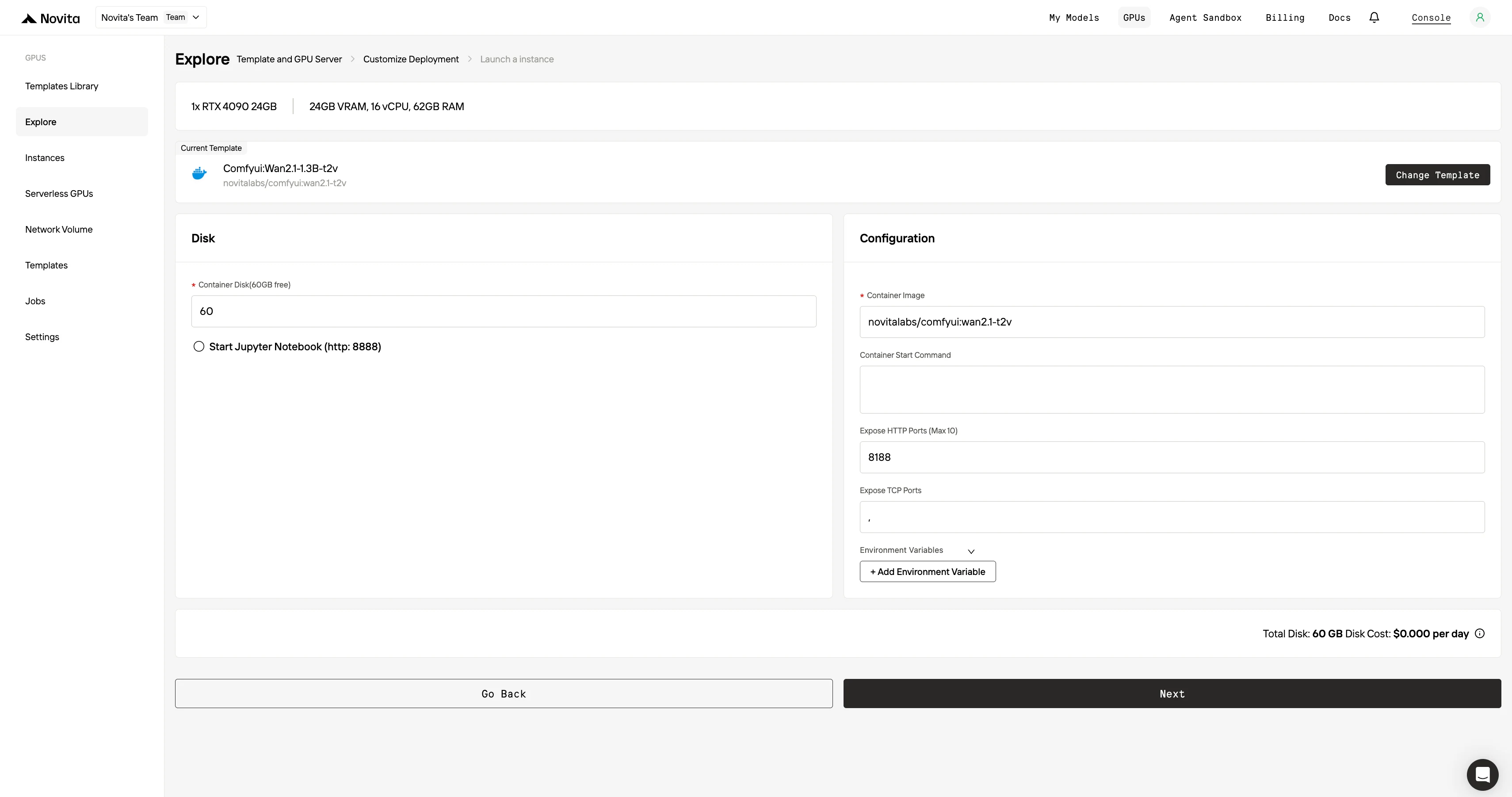
Passo 4: Inicie uma instância
Selecione “Iniciar Instância” para começar sua implantação. Seu ambiente GPU de alto desempenho estará pronto em minutos, permitindo que você comece imediatamente seus projetos de aprendizado de máquina, renderização ou computação.
Guia de API (Usando o Kimi K2 como Exemplo)
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atenda às suas necessidades.
Passo 3: Inicie seu Teste Gratuito
Comece seu teste gratuito para explorar os recursos do modelo selecionado.
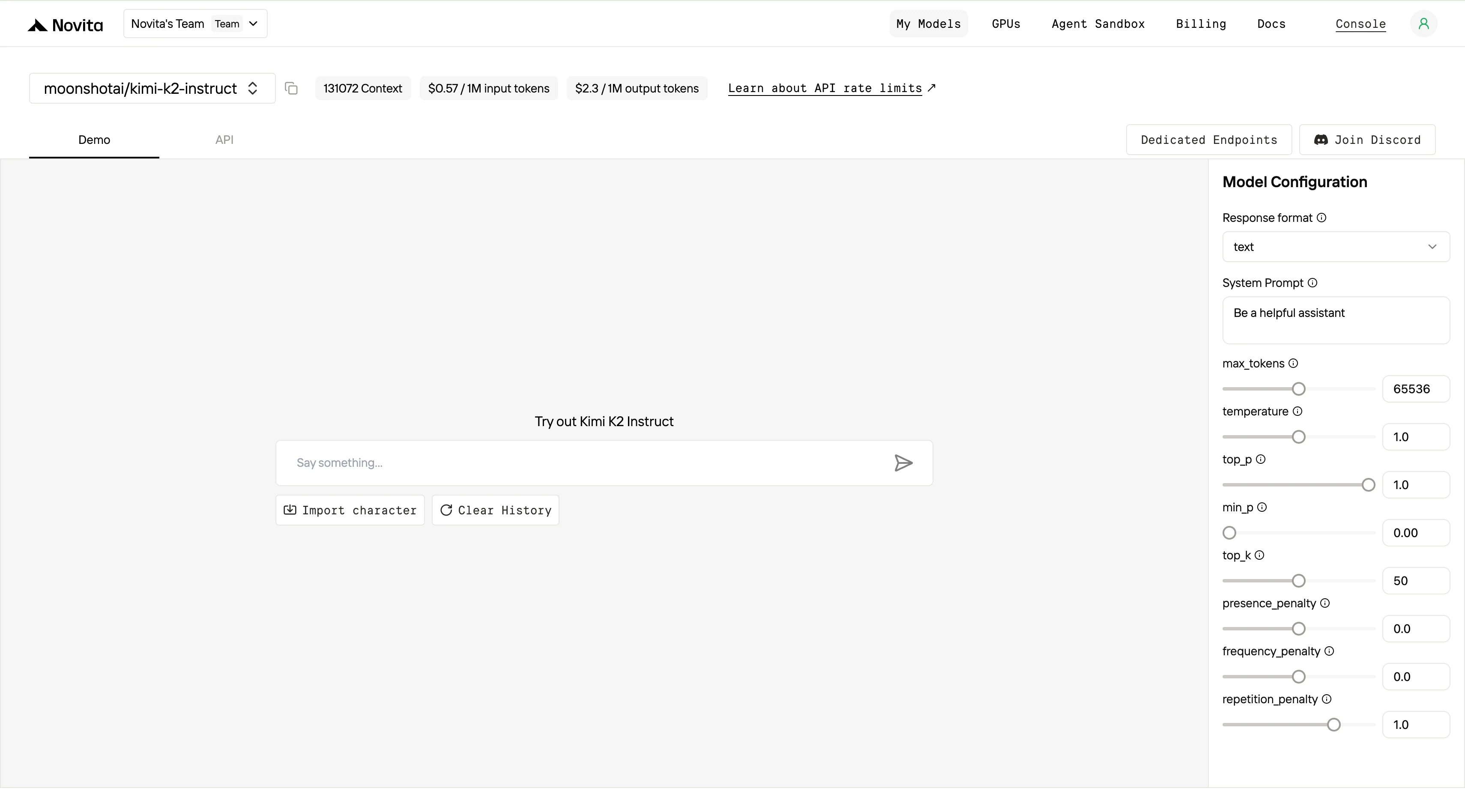
Passo 4: Obtenha sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusão de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_1g0vYAKH0Oir6vI6y4PZIGyFLVvuJiJDx0jZiEeYivQFmDr15mi83mWi-_bdrs0C-Q2hk281SCn1f4oUB49loQ==",
)
model = "moonshotai/kimi-k2-instruct"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Usando o Agent Sandbox (opcional): A Novita também tem um recurso Agent Sandbox acessível a partir do painel. Isso permite que você execute agentes de IA ou código em um ambiente sandbox totalmente gerenciado com isolamento de internet. Se seu caso de uso envolve coisas como avaliar código gerado por um agente de IA, isso pode ser útil. Você pode explorar isso assim que estiver confortável com o básico.
Quando Escolher a Novita AI
- Com orçamento apertado — A Novita é geralmente cerca de 50% mais barata que o RunPod para uso de GPU, com armazenamento muito acessível e créditos gratuitos generosos para startups.
- Precisa de funcionalidade rápida e sem complicações — Com mais de 200 APIs pré-construídas (LLM, imagem, áudio, vídeo), é ideal se você deseja recursos alimentados por IA sem gerenciar infraestrutura.
- Prefere simplicidade e velocidade — Ótimo para integrar a IA rapidamente, especialmente se treinamento/ajuste fino não for uma prioridade.
Melhor para: Desenvolvedores independentes, startups e equipes de produto que precisam de integração rápida de IA sem se preocupar com hardware ou configuração.
Quando Escolher o RunPod
- Planejando fluxos de trabalho de treinamento complexos — Oferece suporte forte para clusters multi-GPU, armazenamento persistente e serviços de ajuste fino integrados.
- Precisa de escalabilidade ou computação robusta — Ótimo para treinar modelos grandes, configurações multinó ou experimentos de longo prazo.
- Prefere padronização entre regiões — Sua presença em mais de 30 regiões globais e extensa biblioteca de modelos simplificam as implantações.
- Trabalha intimamente com repositórios de código/GitHub — O suporte integrado a Repositórios Serverless torna simples implantar diretamente de projetos de código aberto.
Perguntas Frequentes
Posso implantar clusters multi-GPU?
Apenas o RunPod suporta isso nativamente por meio do recurso Clusters Instantâneos. A Novita AI atualmente suporta escalabilidade via Serverless e escalabilidade vertical, mas não clusters gerenciados pelo usuário.
Qual é mais barato para executar uma GPU 4090 ou A100?
A Novita AI é geralmente mais barata — oferecendo RTX 4090 por ~$0,35/hora e A100 por ~$1,2/hora (com preços Spot ainda mais baixos). O RunPod oferece mais regiões e flexibilidade, mas custa um pouco mais por hora.
O RunPod oferece uma API de LLM como a OpenAI?
L40S. Sua TDP de 300–350W e forte desempenho por watt tornam uma opção melhor para implantações sensíveis a energia. O H100 (até 700W SXM5) requer infraestrutura significativa. Sim. O RunPod fornece Endpoints Serverless usando vLLM, permitindo que você implante modelos do Hugging Face e os exponha por meio de APIs no estilo OpenAI. Você pode chamar esses endpoints via REST ou integrá-los com o LangChain.
A Novita AI é uma plataforma de cloud de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a cloud GPU acessível e confiável para construir e escalar.



