

- Warum Qwen3-Next-80B-A3B mit weit weniger VRAM mit einem 235B-Modell mithalten kann
- VRAM-Anforderungen für die Inferenz von Qwen3-Next-80B-A3B
- VRAM-Anforderungen für verschiedene Aufgaben
- GPU-Empfehlungen für den reibungslosen Betrieb von Qwen3-Next-80B-A3B
- Minimierung des VRAM-Verbrauchs bei gleichbleibender Leistung
- Testen Sie Qwen3-Next-80B-A3B auf einfache Weise: Nutzen Sie die API
Warum kann ein Modell mit „nur“ 80 Milliarden Parametern mit einem riesigen 235B-Modell mithalten? Die gängige Meinung besagt, dass größere Modelle immer mehr Leistung, höhere Genauigkeit und bessere Schlussfolgerungsfähigkeit bedeuten. Dennoch stellt Qwen3-Next-80B-A3B diese Annahme infrage.
Dieser Artikel geht der zentralen Frage nach: Wie schafft es ein kleineres Modell, mit einem fast dreimal so großen System und mit deutlich weniger VRAM zu konkurrieren? Wir untersuchen die architektonischen Entscheidungen, Effizienztechniken und Leistungskompromisse, die dies möglich machen, und was das für Entwickler und Organisationen bedeutet, die das richtige Gleichgewicht zwischen Geschwindigkeit, Kosten und Leistungsfähigkeit suchen.
Warum Qwen3-Next-80B-A3B mit weit weniger VRAM mit einem 235B-Modell mithalten kann
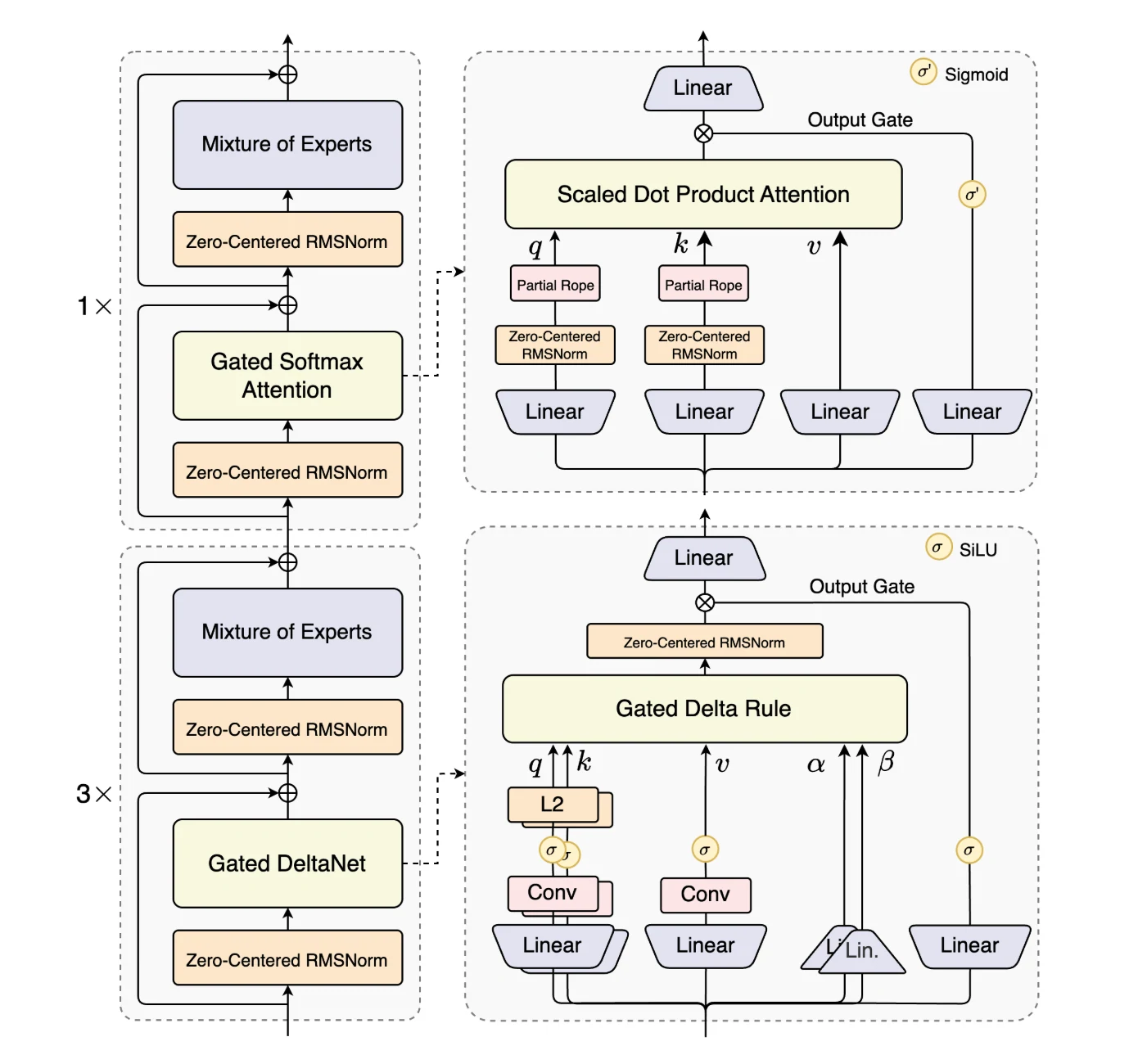
Die Fähigkeit des 80-Milliarden-Parameter-Modells Qwen3-Next-80B-A3B, mit einem kolossalen 235-Milliarden-Parameter-Modell zu konkurrieren, liegt in seiner hocheffizienten Architektur, vor allem in der Verwendung eines High-Sparsity Mixture-of-Experts (MoE)-Designs.
Von Hugging Face
Qwen3-Next-80B-A3B ist das erste Modell der Qwen3-Next-Serie und zeichnet sich durch architektonische Innovationen aus, die die Effizienz und den Durchsatz bei langen Kontexten maximieren.
Es führt Hybrid Attention ein, das Gated DeltaNet und Gated Attention kombiniert, um die Standard-Attention zu ersetzen, und ermöglicht so eine effiziente Kontextmodellierung bei ultra-langen Sequenzlängen.
Ein High-Sparsity Mixture-of-Experts (MoE)-Design senkt das Aktivierungsverhältnis drastisch, reduziert die FLOPs pro Token und erhält gleichzeitig die Modellkapazität.
Um Robustheit zu gewährleisten, integriert das Modell Stabilitätsoptimierungen wie zentrierte und gewichtsdekayierte Layer-Normalisierung.
Schließlich verbessert Multi-Token Prediction (MTP) die Effizienz des Vortrainings und beschleunigt die Inferenz. Zusammen machen diese Erweiterungen Qwen3-Next-80B-A3B einzigartig geeignet für die Verarbeitung von groß angelegten, langen Kontext-Workloads mit sowohl Effizienz als auch Stabilität.
Von Hugging Face
VRAM-Anforderungen für die Inferenz von Qwen3-Next-80B-A3B
Ein entscheidender Punkt, den es zu verstehen gilt: Obwohl während der Inferenz nur ein Bruchteil der Parameter aktiv ist, müssen dennoch alle 80 Milliarden Parameter in den VRAM der GPU geladen werden.
Der für die Inferenz benötigte VRAM wird in erster Linie durch die Größe des Modells und die Genauigkeit seiner Gewichte bestimmt. Hier ist eine grundlegende Berechnung für das Laden der Modellgewichte:
FP16/BF16 (16-Bit-Genauigkeit): Dies ist eine gängige Genauigkeit für die Inferenz, die 2 Byte pro Parameter verwendet. 80 Milliarden Parameter × 2 Byte/Parameter = 160 GB VRAM
Diese 160 GB sind nur für die Modellgewichte. Zusätzlicher VRAM wird für den KV-Cache (der Aufmerksamkeitsinformationen für den Kontext speichert), Aktivierungen und anderen betrieblichen Overhead benötigt. In der Praxis benötigen Sie also mehr als 160 GB VRAM, um das unquantisierte Modell auszuführen, insbesondere bei langen Kontextlängen.
VRAM-Anforderungen für verschiedene Aufgaben
Während der Basis-VRAM für das Laden des Modells statisch ist, schwankt die dynamische VRAM-Nutzung je nach den spezifischen Gegebenheiten der jeweiligen Aufgabe. Dies liegt vor allem am KV-Cache, der Kontextlänge und der Batch-Größe. Der KV-Cache speichert die Aufmerksamkeitsschlüssel und -werte für jedes Token der Eingabesequenz, und seine Größe ist ein Hauptfaktor für den dynamischen VRAM-Verbrauch.
Textgenerierung (z. B. Chatbots, Zusammenfassung, Kreatives Schreiben)
- Typische Kontextlänge: Bei Konversations-KI oder der Zusammenfassung kürzerer Dokumente ist die Kontextlänge relativ gering (z. B. ein paar tausend Token). Dies führt zu einem kleineren KV-Cache und damit zu einer geringeren dynamischen VRAM-Nutzung.
- Langform-Generierung: Bei Aufgaben wie dem Schreiben langer Artikel oder der Führung einer sehr langen Konversationshistorie wächst der Kontext und damit auch der KV-Cache. Das Qwen3-Next-Modell unterstützt einen sehr langen Kontext von bis zu 256.000 Token, und die Nutzung dieser vollen Kapazität würde zu einem deutlichen Anstieg der VRAM-Anforderungen führen.
So kann es beispielsweise selbst bei einem leistungsstarken Setup mit 2 H20-GPUs (je 96 GB) bei 256k Eingaben zu Speicherproblemen kommen.
Von Hugging Face
Codegenerierung
- Repository-weiter Kontext: Eine zentrale Anwendung fortschrittlicher Codegenerierungsmodelle ist das Verständnis einer gesamten Codebasis für Aufgaben wie das Hinzufügen neuer Funktionen oder das Debuggen komplexer Probleme. In solchen Szenarien kann der Eingabekontext sehr groß sein, bestehend aus mehreren Dateien und zehntausenden Zeilen Code. Dies erhöht den für den KV-Cache benötigten VRAM erheblich.
- Einfache Code-Snippets: Umgekehrt hat die Generierung einer kleinen, eigenständigen Funktion oder die Vervollständigung einer einzelnen Codezeile nur minimale Auswirkungen auf den dynamischen VRAM, ähnlich wie bei der Kurzform-Textgenerierung.
Modellvarianten (Instruct vs. Thinking):
- Die Kernarchitektur der „Instruct“- und „Thinking“-Versionen von Qwen3-Next-80B-A3B ist identisch, mit insgesamt 80B und 3B aktiven Parametern. Daher sind ihre grundlegenden VRAM-Anforderungen für das Laden des Modells identisch. Das „Thinking“-Modell kann jedoch längere Zwischenschlussfolgerungsschritte generieren, was bei komplexen Problemlösungsaufgaben zu leicht höherer dynamischer VRAM-Nutzung führen kann.
Zusammenfassend lässt sich sagen, dass der VRAM-Bedarf für „Textgenerierung“ und „Codegenerierung“ nicht grundsätzlich unterschiedlich ist, sondern vielmehr von dem Umfang der Ein- und Ausgabe für eine bestimmte Aufgabe abhängt. Eine komplexe, mehrdateiige Codegenerierungsaufgabe erfordert mehr dynamischen VRAM als eine einfache, einabsätzige Textzusammenfassung und umgekehrt.
GPU-Empfehlungen für den reibungslosen Betrieb von Qwen3-Next-80B-A3B
CPU-Leistung
Ja, das Qwen3-Next 80B-Modell kann auf einer CPU ausgeführt werden. In der Demo erklärte der Moderator, dass obwohl das Modell 80 Milliarden Parameter hat, während der Inferenz nur etwa 3 Milliarden aktiviert werden. Dies macht die CPU-Ausführung möglich – etwas, das noch vor wenigen Wochen unmöglich schien.
Der Nachteil ist die Geschwindigkeit. Zum Beispiel brauchte das Modell 55 Minuten, um auf die Frage „Was ist das kleinste Land der Welt?“ zu antworten (Vatikanstadt ).
https://www.youtube.com/watch?v=F0dBClZ33R4
GPU-Leistung
Das Qwen3-Next 80B-Modell läuft auch auf einer einzelnen GPU. Mit vier oder mehr GPUs wird die Geschwindigkeit – insbesondere bei langen Kontexten – extrem schnell, geradezu blitzschnell. Speicherseitig erfordert die Ausführung des Modells in voller Genauigkeit etwas über 68 GB VRAM.
| Merkmal | NVIDIA A100 SXM | NVIDIA H100 SXM | NVIDIA H200 SXM | NVIDIA B200 |
|---|---|---|---|---|
| GPU-Architektur | Ampere | Hopper | Hopper | Blackwell |
| Erscheinungsjahr | 2020 | 2022 | 2023 | 2024 |
| Speicher (VRAM) | 40 GB oder 80 GB HBM2e | 80 GB HBM3 | 141 GB HBM3e | 192 GB HBM3e |
| Speicherbandbreite | 2,0 TB/s (für 80-GB-Modell) | 3,35 TB/s | 4,8 TB/s | 8,0 TB/s |
| Interconnect | NVLink 3.0 (600 GB/s Gesamtbandbreite) | NVLink 4.0 (900 GB/s Gesamtbandbreite) | NVLink 4.0 (900 GB/s Gesamtbandbreite) | NVLink 5.0 (1,8 TB/s Gesamtbandbreite) |
| Maximale FP16/BF16-Leistung | 312 TFLOPS (Sparsity: 624 TFLOPS) | 989 TFLOPS (Sparsity: 1.979 TFLOPS) | 989 TFLOPS (Sparsity: 1.979 TFLOPS) | 2.250 TFLOPS (Sparsity: 4.500 TFLOPS) |
| Unterstützung für neue Genauigkeiten | TF32 | FP8 | FP8 | FP4, FP6 |
| Wichtigste Innovation | Multi-Instance GPU (MIG), TF32 | Transformer Engine (FP8-Unterstützung), DPX | Erhöhter HBM3e-Speicher und -Bandbreite | 2. Generation Transformer Engine (FP4/FP6), Blackwell-Chiplet-Design |
| Typische maximale Leistungsaufnahme (TDP) | Bis zu 400 W | Bis zu 700 W | Bis zu 1000 W | Bis zu 1200 W |
- A100 SXM: Die auf Ampere basierende GPU, die die KI durch die Einführung von TF32-Genauigkeit und Multi-Instance GPU (MIG) für bessere Leistung und Ressourcennutzung revolutioniert hat.
- H100 SXM: Aufgerüstet auf die Hopper-Architektur, war ihr wichtigstes Update die Transformer Engine mit FP8-Unterstützung, die das KI-Training für Transformer-Modelle drastisch beschleunigt.
- H200 SXM: Als Weiterentwicklung der H100 ist ihr größtes Update der Einsatz von schnellerem und größerem HBM3e-Speicher (141 GB), der die Speicherbandbreite für die Inferenz großer Modelle deutlich erhöht.
- B200: Ein großer Sprung zur Blackwell-Architektur, sie führt ein Dual-Chiplet-Design und eine Transformer Engine der 2. Generation mit neuer FP4/FP6-Genauigkeitsunterstützung ein, die massive Leistungsgewinne für KI-Modelle mit Billionen von Parametern liefert.
Wenn Sie das Modell durch lokale Bereitstellung testen möchten, bietet Novita AI erschwingliche und stabile GPU-Instanzdienste. Es bietet auch eine Spot-Preis-Option, um Kosten weiter zu senken und Ihnen zu helfen, die Fähigkeiten des Modells zu testen.
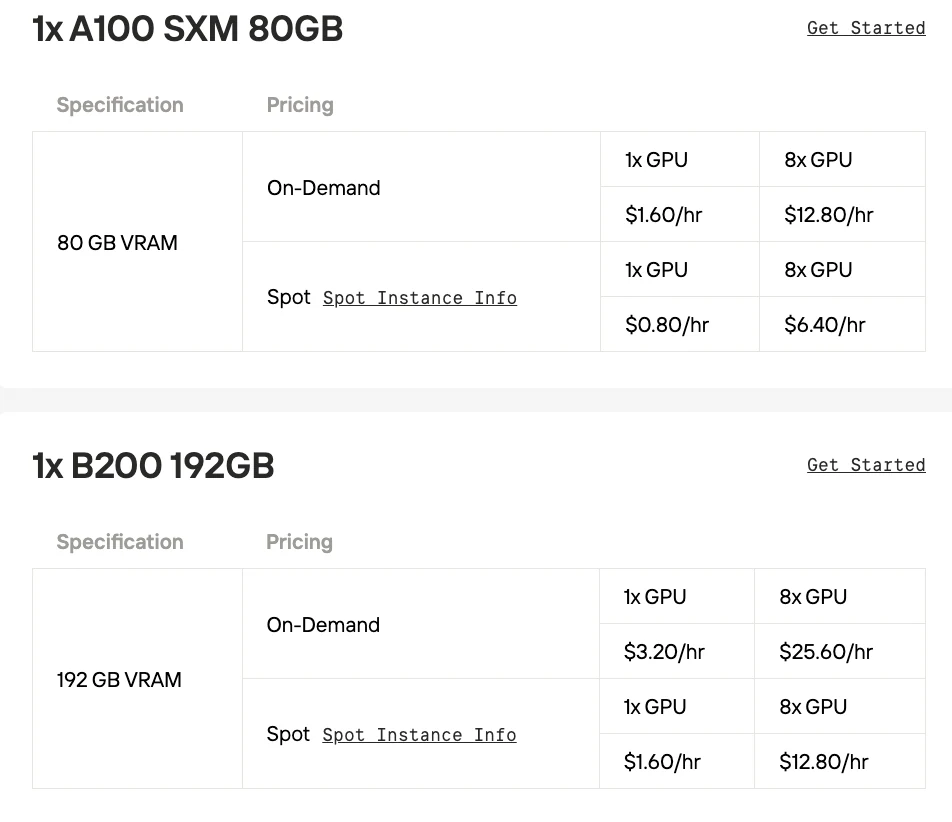
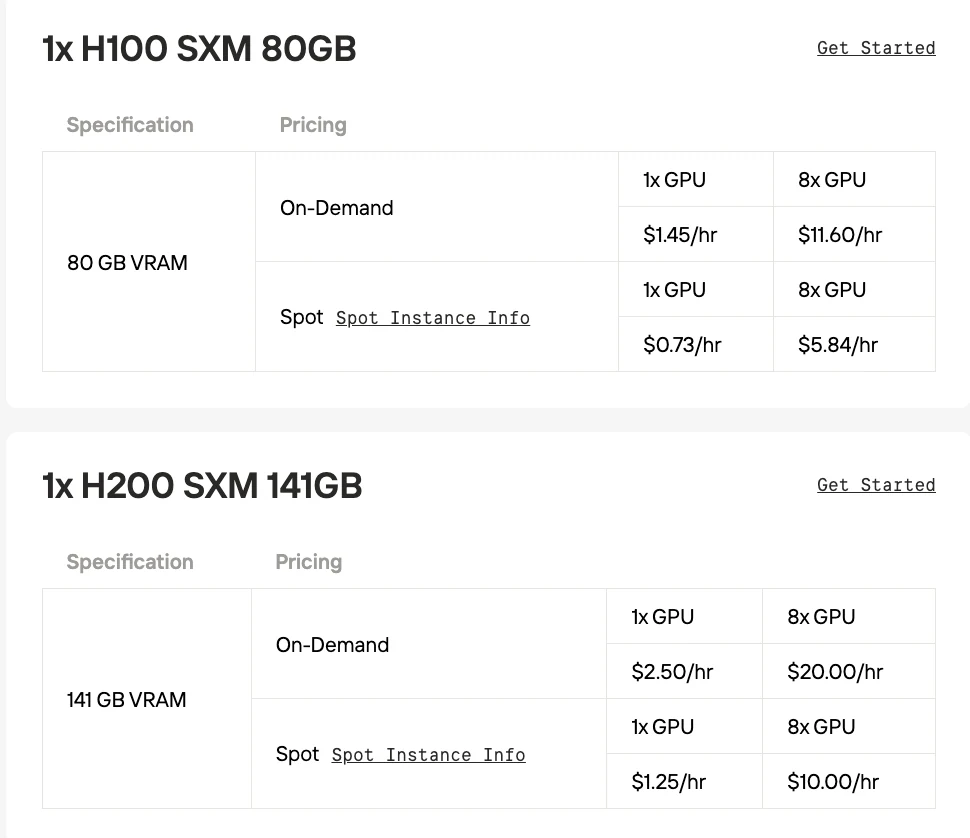
Minimierung des VRAM-Verbrauchs bei gleichbleibender Leistung
Mehrere Techniken können helfen, den VRAM-Fußabdruck von Qwen3-Next-80B-A3B zu reduzieren, sodass das Modell auf einer breiteren Palette von Hardware einfacher ausgeführt werden kann.
Quantisierung ist der effektivste Ansatz. Durch die Umwandlung der Gewichte des Modells von höhergenauen Formaten (wie FP16) in niedrigergenauere Formate sinkt der Speicherverbrauch deutlich.
- INT8 (8-Bit): Senkt den VRAM-Bedarf für Gewichte im Vergleich zu FP16 um etwa die Hälfte. Für das 80B-Modell liegt die Anforderung damit bei etwa 80 GB.
- INT4 (4-Bit): Reduziert den VRAM für Gewichte im Vergleich zu FP16 um etwa 75 %, wodurch die Anforderung auf rund 40 GB sinkt.
Das GGUF-Format wird weit verbreitet für die Ausführung von Modellen auf CPUs und Macs verwendet, hat aber auch GPU-Anwendungsfälle. Ein entscheidender Vorteil für Mixture-of-Experts-Modelle wie Qwen3-Next ist, dass GGUF es ermöglicht, einige Expertenebenen in den Systemspeicher auszulagern, was die VRAM-Anforderungen senkt, jedoch auf Kosten einer langsameren Leistung, wenn diese Ebenen aktiviert werden.
CPU-Auslagerung geht noch weiter: Teile des Modells, insbesondere selten genutzte Expertenebenen, können im Systemspeicher verbleiben und nur bei Bedarf in den VRAM verschoben werden. Dies reduziert die VRAM-Anforderungen deutlich, erzeugt aber Latenz aufgrund langsamerer Übertragungen zwischen RAM und GPU-Speicher.
Spezialisierte Inferenz-Engines wie vLLM oder SGLang werden dringend empfohlen. Diese Frameworks sind für große Sprachmodelle entwickelt und verwenden Optimierungen wie effizientes KV-Cache-Management, um den Speicher-Overhead zu reduzieren.
Flash Attention bietet einen weiteren Weg und stellt eine speichereffizientere und schnellere Version des Aufmerksamkeitsalgorithmus dar, indem es den Hochgeschwindigkeits-SRAM der GPU effektiver nutzt.
Schließlich kann die Verkürzung der Kontextlänge eine praktische Lösung sein. Wenn Ihre Anwendung keine sehr langen Kontexte benötigt, verkleinert eine niedrigere maximale Kontextlänge direkt die Größe des KV-Caches und spart VRAM.
Testen Sie Qwen3-Next-80B-A3B auf einfache Weise: Nutzen Sie die API
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen.
Qwen3-Next-80B-A3B Instruct kostet $0,15 pro M Eingabetoken und $1,5 pro M Ausgabetoken, bei einem Kontext von 65.536 Token.
Qwen3-Next-80B-A3B Thinking kostet ebenfalls $0,15 pro M Eingabetoken und $1,5 pro M Ausgabetoken, bei dem gleichen Kontext von 65.536 Token.
Schritt 1: Melden Sie sich an und greifen Sie auf die Modellbibliothek zu
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Testen Sie Qwen 3 Next 80B A3B jetzt!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Um sich gegenüber der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completions-API für Python-Nutzer.
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)
Nutzung von CLIs wie Trae, Claude Code, Qwen Code
Wenn Sie die Top-Modelle von Novita AI (wie Qwen3-Coder, Kimi K2, DeepSeek R1) für KI-Codeunterstützung in Ihrer lokalen Umgebung oder IDE nutzen möchten, ist der Prozess einfach: Holen Sie sich Ihren API-Schlüssel, installieren Sie das Tool, konfigurieren Sie Umgebungsvariablen und fangen Sie an zu codieren.
Ausführliche Einrichtungsbefehle und Beispiele finden Sie in den offiziellen Tutorials:
- Trae: Schritt-für-Schritt-Anleitung für den Zugriff auf KI-Modelle in Ihrer IDE
- Claude Code: So verwenden Sie Kimi-K2 in Claude Code unter Windows, Mac und Linux
- Qwen Code: So verwenden Sie die OpenAI-kompatible API in Qwen Code (60-Sekunden-Einrichtung!)
Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstellen Sie fortschrittliche Multi-Agent-Systeme durch die Integration von Novita AI mit dem OpenAI Agents SDK:
- Plug-and-Play: Nutzen Sie die LLMs von Novita AI in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwerfen Sie Agenten, die delegieren, triagieren oder Funktionen ausführen können, alle angetrieben von den Modellen von Novita AI.
- Python-Integration: Setzen Sie einfach den SDK-Endpunkt auf
https://api.novita.ai/v3/openaiund verwenden Sie Ihren API-Schlüssel.
API auf Drittanbieterplattformen verbinden
OpenAI-kompatible API: Genießen Sie problemlose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI-API-Standard entwickelt wurden.
Hugging Face: Nutzen Sie Modelle in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
Agenten- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM,LangChain, Dify und Langflow über offizielle Connectors und Schritt-für-Schritt-Integrationsanleitungen.
Qwen3-Next-80B-A3B ist der Beweis, dass architektonische Innovation das brute-force-Skalieren von Parametern übertreffen kann. Durch die Neudefinition, wie Aufmerksamkeit und Experten aktiviert werden, liefert es Ergebnisse, die mit viel größeren Modellen mithalten oder diese übertreffen, und das bei deutlich geringerem Speicherbedarf.
Für Praktiker bedeutet dies zugänglichere Experimente, niedrigere Infrastrukturkosten und schnellere Iterationen – alles ohne Leistungseinbußen. Die 80B-Ära markiert einen Wendepunkt, an dem clevereres Design, nicht nur die Modellgröße, die Führung in der KI bestimmt.
Häufig gestellte Fragen
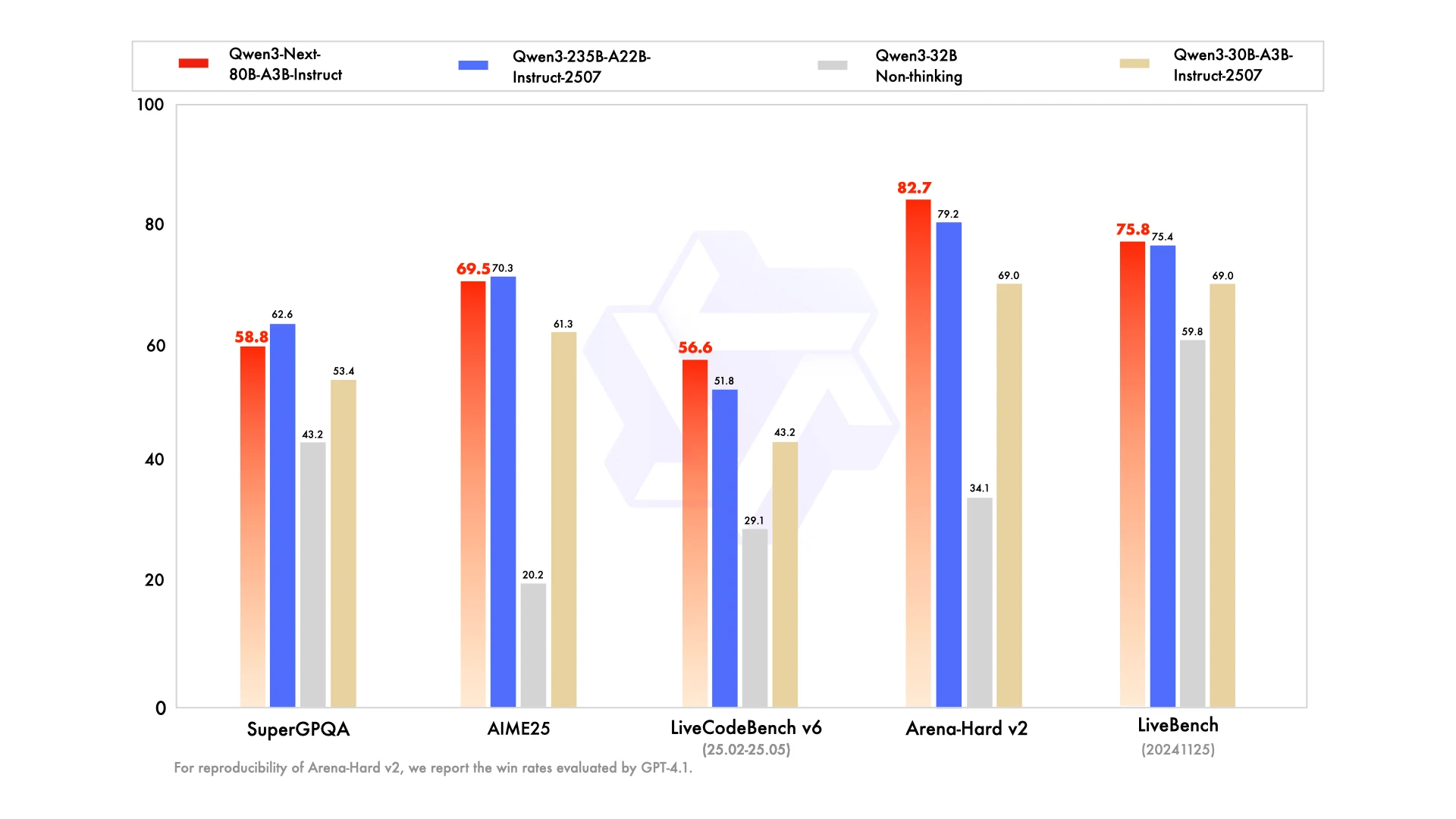
Wie kann 80B bei anspruchsvollen Benchmarks mit 235B mithalten?
Da Qwen3-Next-80B-A3B Hybrid Attention und sparsames MoE einsetzt, um Rechenkosten zu senken, ohne die Repräsentationskapazität zu verlieren. Dies ermöglicht es ihm, bei Aufgaben wie AIME25, LiveBench und LiveCodeBench mit 235B-Modellen gleichzuziehen oder diese sogar zu übertreffen.
Welches Modell eignet sich besser für lange Dokumente oder erweiterte Konversationshistorie?
Die 235B-Variante unterstützt nativ Kontexte von 262K bis zu 1M Token, aber Qwen3-Next-80B-A3B verarbeitet auch bis zu 256K Token effizient. Für die meisten realen Anwendungsfälle bietet 80B eine ausreichende Kontextverarbeitung mit schnelleren Antwortzeiten und niedrigeren Kosten.
Ist Qwen3-Next-80B-A3B besser an menschliche Präferenzen angepasst?
Ja. In Benchmarks wie Arena-Hard v2 erzielte die Instruct-Version von Qwen3-Next-80B-A3B höhere Werte als das 235B-Modell, was eine stärkere Angleichung und Zuverlässigkeit selbst in kleinerem Maßstab zeigt.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Erstellung und Skalierung bereitstellt.



