

- Por que o Qwen3-Next-80B-A3B pode rivalizar com um modelo de 235B com muito menos VRAM
- Requisitos de VRAM para inferência do Qwen3-Next-80B-A3B
- Requisitos de VRAM para diferentes tarefas
- Recomendações de GPU para executar o Qwen3-Next-80B-A3B sem problemas
- Minimizando o uso de VRAM mantendo o desempenho
- Teste o Qwen3-Next-80B-A3B de forma simples: Use a API
Por que um modelo com “apenas” 80 bilhões de parâmetros pode ficar ombro a ombro com um modelo gigante de 235B? O conhecimento convencional sugere que modelos maiores sempre significam mais poder, mais precisão e melhor raciocínio. No entanto, o Qwen3-Next-80B-A3B desafia essa premissa.
Este artigo explora a questão central: como um modelo de escala menor consegue rivalizar com um sistema quase três vezes maior, e com muito menos VRAM? Vamos examinar as escolhas arquitetônicas, técnicas de eficiência e trade-offs de desempenho que tornam isso possível, e o que isso significa para desenvolvedores e organizações que buscam o equilíbrio certo entre velocidade, custo e capacidade.
Por que o Qwen3-Next-80B-A3B pode rivalizar com um modelo de 235B com muito menos VRAM
A capacidade do Qwen3-Next-80B-A3B, com 80 bilhões de parâmetros, de competir com um modelo colossal de 235 bilhões de parâmetros vem de sua arquitetura altamente eficiente, principalmente o uso do design High-Sparsity Mixture-of-Experts (MoE).
De Hugging Face
O Qwen3-Next-80B-A3B é o primeiro modelo da série Qwen3-Next e se destaca por suas inovações arquitetônicas que maximizam a eficiência e o throughput em contextos longos.
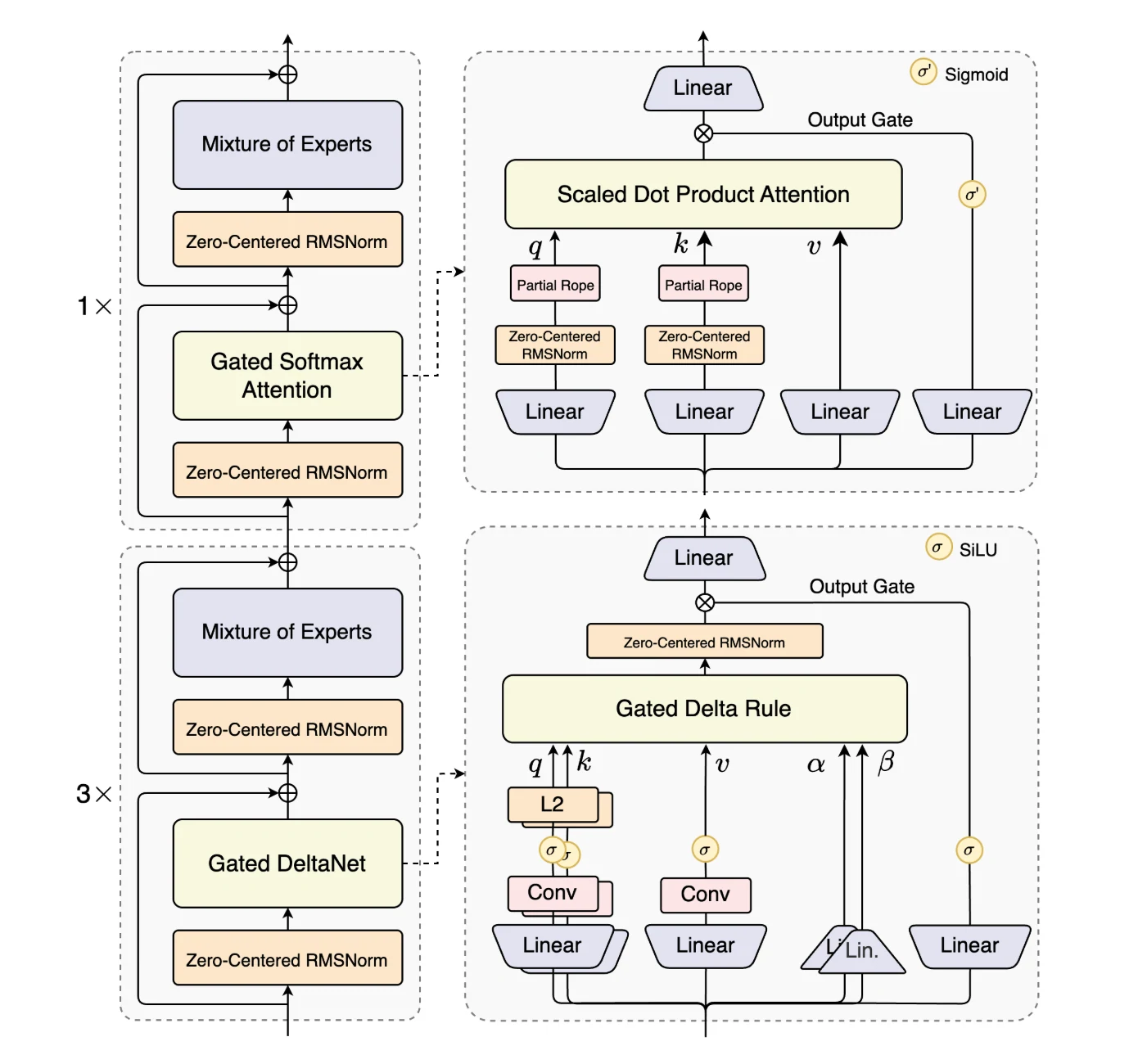
Ele introduz o Hybrid Attention, que combina Gated DeltaNet e Gated Attention para substituir a atenção padrão, permitindo modelagem de contexto eficiente em comprimentos de sequência ultra longos.
Um design High-Sparsity Mixture-of-Experts (MoE) reduz drasticamente a proporção de ativação, diminuindo os FLOPs por token enquanto preserva a capacidade do modelo.
Para garantir robustez, o modelo integra Stability Optimizations como normalização de camada centrada em zero e com decaimento de peso.
Por fim, o Multi-Token Prediction (MTP) melhora a eficiência do pré-treinamento e acelera a inferência. Juntas, essas melhorias tornam o Qwen3-Next-80B-A3B especialmente adequado para lidar com cargas de trabalho em larga escala e de contexto longo, com eficiência e estabilidade.
De Hugging Face
Requisitos de VRAM para inferência do Qwen3-Next-80B-A3B
Um ponto crucial a entender é que, embora apenas uma fração dos parâmetros esteja ativa durante a inferência, todos os 80 bilhões de parâmetros ainda precisam ser carregados na VRAM do GPU.
A VRAM necessária para inferência é determinada principalmente pelo tamanho do modelo e a precisão de seus pesos. Veja um cálculo básico para carregar os pesos do modelo:
Precisão FP16/BF16 (16 bits): Essa é uma precisão comum para inferência, que usa 2 bytes por parâmetro. 80 bilhões de parâmetros × 2 bytes/parâmetro = 160 GB de VRAM
Esses 160 GB são apenas para os pesos do modelo. VRAM adicional é necessária para o KV cache (que armazena informações de atenção para o contexto), ativações e outras sobrecargas operacionais. Portanto, na prática, você precisará de mais de 160 GB de VRAM para executar o modelo não quantizado, especialmente com comprimentos de contexto longos.
Requisitos de VRAM para diferentes tarefas
Enquanto a VRAM base para carregamento do modelo é estática, o uso dinâmico de VRAM flutua dependendo das especificidades da tarefa em questão. Isso se deve principalmente ao KV Cache, ao comprimento do contexto e ao tamanho do lote. O KV Cache armazena as chaves e valores de atenção para cada token na sequência de entrada, e seu tamanho é um dos principais contribuintes para o consumo dinâmico de VRAM.
Geração de texto (ex: chatbots, sumarização, escrita criativa)
- Comprimento de contexto típico: Para IA conversacional ou sumarização de documentos mais curtos, o comprimento do contexto pode ser relativamente pequeno (ex: alguns milhares de tokens). Isso resulta em um KV Cache menor e, portanto, menor uso dinâmico de VRAM.
- Geração de texto longo: Para tarefas como escrever artigos longos ou manter um histórico de conversa muito longo, o contexto cresce, e o KV Cache também. O modelo Qwen3-Next suporta um contexto muito longo de até 256.000 tokens, e usar essa capacidade total levaria a um aumento significativo nos requisitos de VRAM.
Por exemplo, mesmo em uma configuração potente com 2 GPUs H20 (96GB cada), entradas de 256k tokens podem causar problemas de memória.
De Hugging Face
Geração de código
- Contexto em nível de repositório: Uma aplicação chave de modelos avançados de geração de código é entender uma base de código inteira para tarefas como adicionar novas funcionalidades ou depurar problemas complexos. Nesses cenários, o contexto de entrada pode ser muito grande, consistindo em vários arquivos e dezenas de milhares de linhas de código. Isso aumentará substancialmente a VRAM necessária para o KV Cache.
- Snippets de código simples: Por outro lado, gerar uma função pequena e autônoma ou completar uma única linha de código terá um impacto mínimo na VRAM dinâmica, semelhante à geração de texto curto.
Variantes do modelo (Instruct vs. Thinking):
- A arquitetura central das versões “Instruct” e “Thinking” do Qwen3-Next-80B-A3B é a mesma, com 80B de parâmetros totais e 3B de parâmetros ativos. Portanto, seus requisitos base de VRAM para carregamento do modelo são idênticos. No entanto, o modelo “Thinking” pode gerar passos de raciocínio intermediários mais longos, o que pode levar a um uso dinâmico de VRAM ligeiramente maior durante tarefas de resolução de problemas complexos.
Em resumo, o requisito de VRAM não é inerentemente diferente para “geração de texto” versus “geração de código”, mas depende da escala da entrada e saída para uma determinada tarefa. Uma tarefa complexa de geração de código com vários arquivos exigirá mais VRAM dinâmica do que uma sumarização simples de um único parágrafo de texto, e vice-versa.
Recomendações de GPU para executar o Qwen3-Next-80B-A3B sem problemas
Desempenho em CPU
Sim, o modelo Qwen3-Next 80B pode ser executado em uma CPU. Na demonstração, o apresentador explicou que, embora o modelo tenha 80 bilhões de parâmetros, apenas cerca de 3 bilhões são ativados durante a inferência. Isso torna a execução em CPU possível—algo que parecia impossível há apenas algumas semanas.
A desvantagem é a velocidade. Por exemplo, quando perguntado “Qual é o menor país do mundo?”, o modelo levou 55 minutos para responder (Cidade do Vaticano).
https://www.youtube.com/watch?v=F0dBClZ33R4
Desempenho em GPU
O modelo Qwen3-Next 80B também é executado em uma única GPU. Com quatro ou mais GPUs, a velocidade—especialmente com contextos longos—fica extremamente rápida, quase impressionante. Em termos de memória, executar o modelo em precisão total requer um pouco mais de 68 GB de VRAM.
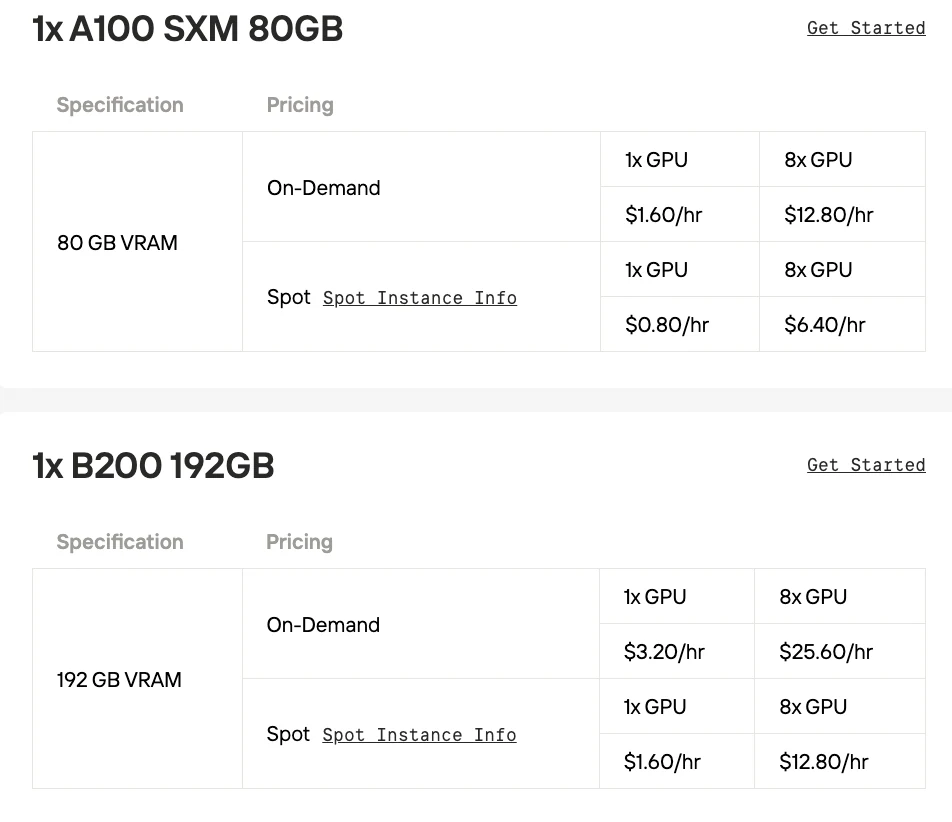
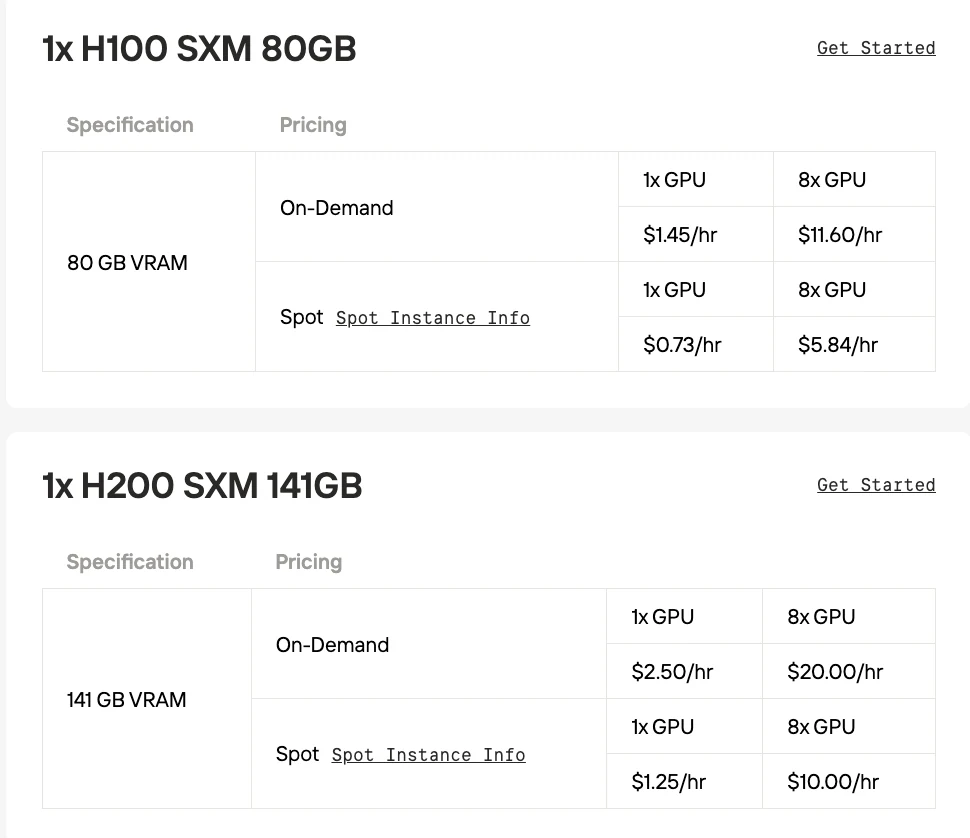
| Característica | NVIDIA A100 SXM | NVIDIA H100 SXM | NVIDIA H200 SXM | NVIDIA B200 |
|---|---|---|---|---|
| Arquitetura de GPU | Ampere | Hopper | Hopper | Blackwell |
| Ano de lançamento | 2020 | 2022 | 2023 | 2024 |
| Memória (VRAM) | 40GB ou 80GB HBM2e | 80GB HBM3 | 141GB HBM3e | 192GB HBM3e |
| Largura de banda de memória | 2,0 TB/s (para modelo de 80GB) | 3,35 TB/s | 4,8 TB/s | 8,0 TB/s |
| Interconexão | NVLink 3.0 (largura de banda total de 600 GB/s) | NVLink 4.0 (largura de banda total de 900 GB/s) | NVLink 4.0 (largura de banda total de 900 GB/s) | NVLink 5.0 (largura de banda total de 1,8 TB/s) |
| Desempenho máximo FP16/BF16 | 312 TFLOPS (Esparsidade: 624 TFLOPS) | 989 TFLOPS (Esparsidade: 1.979 TFLOPS) | 989 TFLOPS (Esparsidade: 1.979 TFLOPS) | 2.250 TFLOPS (Esparsidade: 4.500 TFLOPS) |
| Suporte a nova precisão | TF32 | FP8 | FP8 | FP4, FP6 |
| Inovação principal | Multi-Instance GPU (MIG), TF32 | Transformer Engine (suporte a FP8), DPX | Memória e largura de banda HBM3e aumentadas | 2ª Geração do Transformer Engine (suporte a FP4/FP6), Design Chiplet Blackwell |
| Potência máxima típica (TDP) | Até 400W | Até 700W | Até 1000W | Até 1200W |
- A100 SXM: A GPU baseada em Ampere que revolucionou a IA ao introduzir a precisão TF32 e a Multi-Instance GPU (MIG) para melhor desempenho e utilização de recursos.
- H100 SXM: Atualizada para a arquitetura Hopper, sua principal atualização foi o Transformer Engine com suporte a FP8, acelerando drasticamente o treinamento de IA para modelos Transformer.
- H200 SXM: Uma evolução da H100, sua principal atualização é a adoção de memória HBM3e mais rápida e maior (141GB), aumentando significativamente a largura de banda de memória para inferência de modelos grandes.
- B200: Um grande salto para a arquitetura Blackwell, ela introduz um design dual-chiplet e um Transformer Engine de 2ª geração com suporte à nova precisão FP4/FP6, oferecendo ganhos de desempenho massivos para modelos de IA com trilhões de parâmetros.
Se você quiser experimentar o modelo por meio de implantação local, a Novita AI oferece serviços de instâncias de GPU acessíveis e estáveis. Ela também oferece uma opção de preço spot para minimizar ainda mais os custos, ajudando você a testar as capacidades do modelo.
Minimizando o uso de VRAM mantendo o desempenho
Várias técnicas podem ajudar a reduzir a pegada de VRAM do Qwen3-Next-80B-A3B, tornando o modelo mais fácil de executar em uma gama mais ampla de hardware.
Quantização é a abordagem mais eficaz. Ao converter os pesos do modelo de formatos de precisão mais alta (como FP16) para formatos de precisão mais baixa, o uso de memória cai significativamente.
- INT8 (8 bits): Reduz as necessidades de VRAM para os pesos em cerca de metade em comparação com o FP16. Para o modelo de 80B, isso reduz o requisito para cerca de 80 GB.
- INT4 (4 bits): Reduz a VRAM para os pesos em cerca de 75% em comparação com o FP16, reduzindo o requisito para aproximadamente 40 GB.
O formato GGUF é amplamente utilizado para executar modelos em CPUs e Macs, mas também tem aplicações em GPU. Uma vantagem chave para modelos de mistura de especialistas como o Qwen3-Next é que o GGUF permite que algumas camadas de especialistas sejam transferidas para a RAM do sistema, reduzindo os requisitos de VRAM à custa de um desempenho mais lento quando essas camadas são ativadas.
O offloading de CPU vai além: partes do modelo, especialmente camadas de especialistas raramente usadas, podem residir na RAM do sistema e ser movidas para a VRAM apenas quando necessário. Isso reduz as demandas de VRAM significativamente, mas gera latência devido a transferências mais lentas entre a RAM e a memória da GPU.
Motores de inferência especializados como vLLM ou SGLang são altamente recomendados. Esses frameworks são construídos para modelos de linguagem grandes e usam otimizações como gerenciamento eficiente de KV cache para reduzir a sobrecarga de memória.
O Flash Attention oferece outro caminho, fornecendo uma versão mais eficiente em memória e mais rápida do algoritmo de atenção, aproveitando a SRAM de alta velocidade da GPU de forma mais eficaz.
Por fim, reduzir o comprimento do contexto pode ser uma solução prática. Se sua aplicação não precisa de contextos muito longos, diminuir o comprimento máximo do contexto reduz diretamente o tamanho do KV cache e economiza VRAM.
Teste o Qwen3-Next-80B-A3B de forma simples: Use a API
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples.
O Qwen3-Next-80B-A3B Instruct custa $0,15 por milhão de tokens de entrada e $1,5 por milhão de tokens de saída, com um contexto de 65.536 tokens.
O Qwen3-Next-80B-A3B Thinking também custa $0,15 por milhão de tokens de entrada e $1,5 por milhão de tokens de saída, com o mesmo contexto de 65.536 tokens.
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Experimente o Qwen 3 Next 80B A3B agora!
Passo 2: Escolha seu modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie seu teste gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha sua chave de API
Para autenticar com a API, forneceremos uma nova chave de API para você. Acessando a página de “Configurações“, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)
Usando CLI como Trae,Claude Code, Qwen Code
Se você quiser usar os principais modelos da Novita AI (como Qwen3-Coder, Kimi K2, DeepSeek R1) para assistência de codificação com IA em seu ambiente local ou IDE, o processo é simples: obtenha sua chave de API, instale a ferramenta, configure as variáveis de ambiente e comece a codificar.
Para comandos de configuração detalhados e exemplos, consulte os tutoriais oficiais:
- Trae: Guia passo a passo para acessar modelos de IA na sua IDE
- Claude Code: Como usar o Kimi-K2 no Claude Code no Windows, Mac e Linux
- Qwen Code: Como usar a API compatível com OpenAI no Qwen Code (Configuração em 60s!)
Fluxos de trabalho multiagente com o SDK OpenAI Agents
Construa sistemas multiagente avançados integrando a Novita AI com o SDK OpenAI Agents:
- Plug-and-play: Use os LLMs da Novita AI em qualquer fluxo de trabalho do OpenAI Agents.
- Suporta transferências, roteamento e uso de ferramentas: Projete agentes que podem delegar, triar ou executar funções, todos alimentados pelos modelos da Novita AI.
- Integração com Python: Basta definir o endpoint do SDK como
https://api.novita.ai/v3/openaie usar sua chave de API.
Conecte a API em plataformas de terceiros
API compatível com OpenAI: Aproveite uma migração e integração sem complicações com ferramentas como Cline e Cursor, projetadas para o padrão de API da OpenAI.
Hugging Face: Use modelos nos Spaces, pipelines ou com a biblioteca Transformers por meio dos endpoints da Novita AI.
Frameworks de agentes e orquestração: Conecte facilmente a Novita AI com plataformas parceiras como Continue, AnythingLLM,LangChain, Dify e Langflow por meio de conectores oficiais e guias de integração passo a passo.
O Qwen3-Next-80B-A3B é a prova de que a inovação na arquitetura pode superar o escalonamento de parâmetros por força bruta. Ao repensar como a atenção e os especialistas são ativados, ele oferece resultados que espelham ou superam modelos muito maiores, enquanto requer uma quantidade de memória dramaticamente menor.
Para os profissionais, isso significa experimentação mais acessível, custos de infraestrutura mais baixos e iteração mais rápida—tudo isso sem sacrificar o desempenho. A era dos 80B marca um ponto de virada em que um design mais inteligente, e não apenas o tamanho do modelo, dita a liderança na IA.
Perguntas frequentes
Como um modelo de 80B pode competir com um de 235B em benchmarks desafiadores?
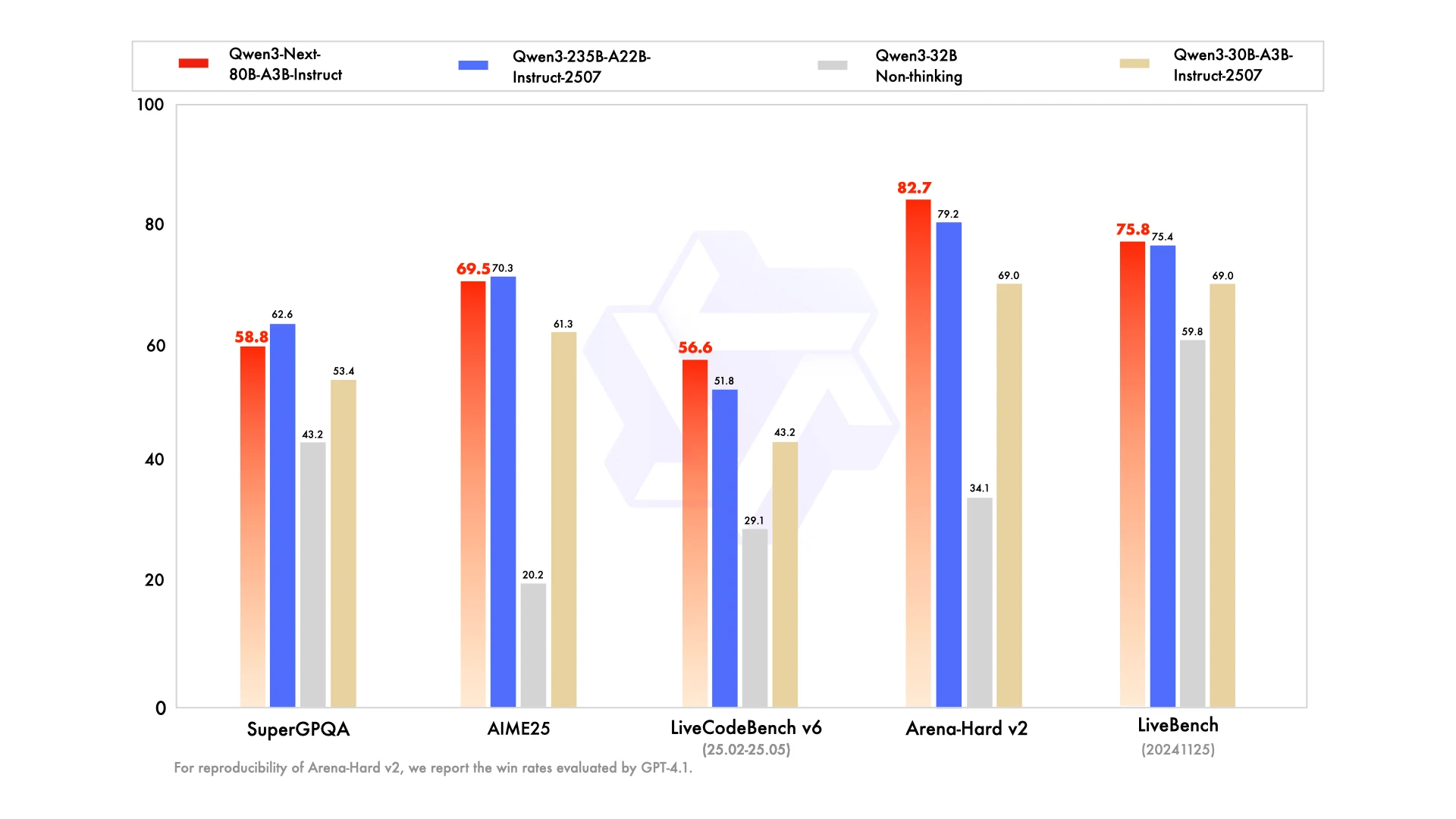
Porque o Qwen3-Next-80B-A3B usa Hybrid Attention e MoE esparso para reduzir os custos de computação sem perder capacidade de representação. Isso permite que ele iguale ou até supere modelos de 235B em tarefas como AIME25, LiveBench e LiveCodeBench.
Qual modelo é melhor para documentos longos ou histórico de conversa estendido?
A variante de 235B suporta nativamente contextos de 262K até 1M de tokens, mas o Qwen3-Next-80B-A3B também lida com até 256K tokens de forma eficiente. Para a maioria dos casos de uso do mundo real, o modelo de 80B oferece tratamento de contexto suficiente, com tempos de resposta mais rápidos e custo menor.
O Qwen3-Next-80B-A3B está mais alinhado com as preferências humanas?
Sim. Em benchmarks como o Arena-Hard v2, a versão Instruct do Qwen3-Next-80B-A3B obteve pontuação maior do que o modelo de 235B, mostrando alinhamento e confiabilidade mais fortes mesmo em uma escala menor.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.



