

なぜ「わずか」800億パラメータのモデルが、巨大な235Bモデルと肩を並べられるのか?従来の通説では、モデルが大きいほど性能が高く、精度が良く、推論能力も優れていると考えられてきました。しかしQwen3-Next-80B-A3Bはこの前提を覆します。
本記事では、なぜ小規模モデルがサイズが約3倍のシステムに匹敵し、はるかに少ないVRAMで動作できるのかという核心的な疑問を解説します。アーキテクチャの選択、効率化技術、性能のトレードオフを検証し、開発者や組織が速度、コスト、性能のバランスを取る上で何を意味するのかを探ります。
なぜQwen3-Next-80B-A3Bははるかに少ないVRAMで235Bモデルに匹敵できるのか
800億パラメータのQwen3-Next-80B-A3Bが2350億パラメータの巨大モデルと競合できる理由は、**高スパース混合専門家(MoE: Mixture-of-Experts)**設計を採用した極めて効率的なアーキテクチャにあります。
Qwen3-Next-80B-A3BはQwen3-Nextシリーズ初のモデルで、長文コンテキストの効率性とスループットを最大化するアーキテクチャの革新により際立っています。
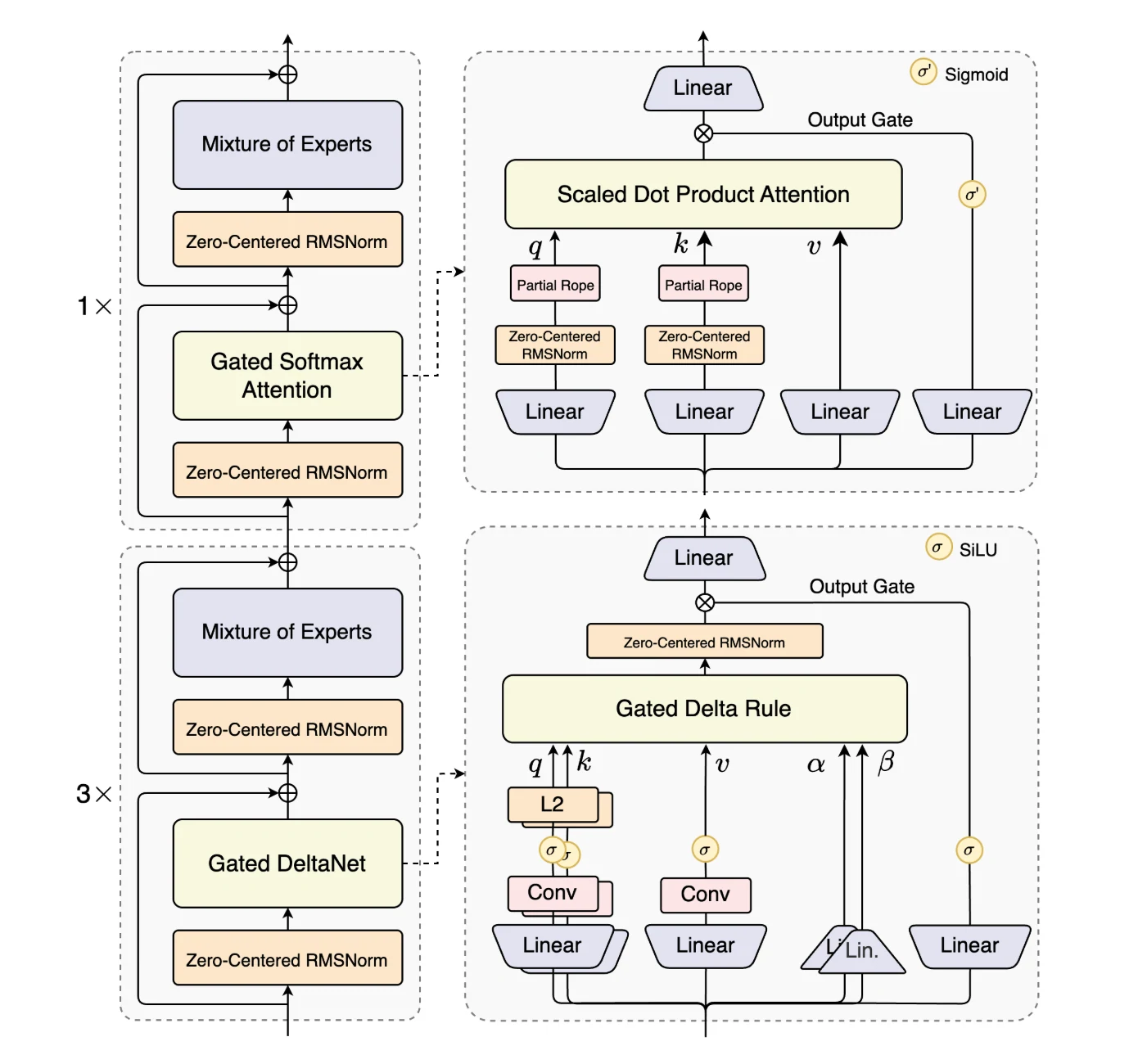
標準アテンションに代えてゲート付きデルタネットとゲート付きアテンションを組み合わせたハイブリッドアテンションを導入し、超長シーケンス長での効率的なコンテキストモデリングを実現しています。
**高スパース混合専門家(MoE)**設計により、アクティベーション率を大幅に削減し、トークンあたりのFLOPsを削減しながらモデルの容量を維持しています。
ロバスト性を確保するため、安定性最適化(ゼロ中心化・重み減衰レイヤー正規化など)を統合しています。
最後に、**マルチトークン予測(MTP)**により事前学習の効率が向上し、推論が高速化されます。これらの機能により、Qwen3-Next-80B-A3Bは大規模・長文コンテキストのワークロードを、効率性と安定性を両立して処理するのに特に適しています。
Qwen3-Next-80B-A3B推論時のVRAM要件
理解しておくべき重要な点は、推論時にアクティブになるパラメータは一部のみであるものの、GPUのビデオVRAMには80億のパラメータ全体を読み込む必要があるということです。
推論に必要なVRAMは主にモデルのサイズと重みの精度によって決まります。以下にモデル重みを読み込むための基本的な計算を示します:
FP16/BF16(16bit精度):推論で一般的に使用される精度で、パラメータ1つあたり2バイトを使用します。800億パラメータ × 2バイト/パラメータ = 160GBのVRAM
この160GBはモデル重みのみの容量です。KVキャッシュ(コンテキストのアテンション情報を保存するもの)、アクティベーション、その他のオーバーヘッド用に追加のVRAMが必要です。そのため、実際に量子化されていないモデルを実行するには、特に長文コンテキストの場合、160GB以上のVRAMが必要になります。
タスクごとのVRAM要件
モデル読み込み時の基本VRAMは固定ですが、動的VRAM使用量は実行するタスクの詳細に応じて変動します。これは主にKVキャッシュ、コンテキスト長、バッチサイズによるものです。KVキャッシュは入力シーケンスの各トークンのアテンションキーと値を保存するもので、そのサイズは動的VRAM消費の大きな要因となります。
テキスト生成(チャットボット、要約、創作など)
- 典型的なコンテキスト長:対話AIや短い文書の要約の場合、コンテキスト長は比較的小さく(数千トークン程度)なることが多く、KVキャッシュも小さくなるため動的VRAM使用量は低くなります。
- 長文生成:長い記事の執筆や非常に長い対話履歴の維持などのタスクでは、コンテキストが長くなるにつれてKVキャッシュも増加します。Qwen3-Nextモデルは最大256,000トークルの非常に長いコンテキストをサポートしていますが、この最大容量を活用するとVRAM要件が大幅に増加します。
例えば、2台のH20 GPU(96GB each)という強力な環境でも、256kトークルの入力はメモリ不足の問題を引き起こす可能性があります。
Hugging Faceより
コード生成
- リポジトリレベルのコンテキスト:高度なコード生成モデルの主要な用途の1つが、新機能の追加や複雑なバグの修正などのタスクのためにコードベース全体を理解することです。このようなシナリオでは、入力コンテキストは複数のファイルや数万行のコードで構成される非常に大規模なものになり、KVキャッシュに必要なVRAMが大幅に増加します。
- シンプルなコードスニペット:逆に、小さな独立した関数の生成や1行のコード補完などの場合は、短いテキスト生成と同様に動的VRAMへの影響は最小限です。
モデルバリアント(Instruct版とThinking版)
Instruct版とThinking版のQwen3-Next-80B-A3Bのコアアーキテクチャは同じで、総パラメータ数80B、アクティブパラメータ数3Bです。そのため、モデル読み込み時の基本VRAM要件は同じです。ただしThinking版は複雑な問題解決タスクでより長い中間推論ステップを生成する可能性があるため、動的VRAM使用量が若干高くなる場合があります。
まとめると、VRAM要件は「テキスト生成」と「コード生成」で本質的に異なるわけではなく、タスクの入力・出力の規模によります。複雑な複数ファイルのコード生成タスクは、シンプルな1段落のテキスト要約よりも多くの動的VRAMを必要とし、その逆も同様です。
Qwen3-Next-80B-A3Bをスムーズに実行するためのGPU推奨環境
CPUでの実行性能
はい、Qwen3-Next 80BモデルはCPUで実行可能です。デモでは、モデルが800億パラメータを持つものの、推論時にアクティブになるのは約30億パラメータのみであるため、CPU実行が可能であることが説明されました。これは数週間前までは不可能だと思われていたことです。
欠点は速度です。例えば「世界で最も小さい国はどこか」という質問に対して、このモデルは回答(バチカン市国)を出すのに55分かかりました。
https://www.youtube.com/watch?v=F0dBClZ33R4
GPUでの実行性能
Qwen3-Next 80Bモデルは単一GPUでも実行可能です。4台以上のGPUを使用すると、特に長文コンテキストの場合の速度が非常に高速になります。メモリの観点では、フル精度でモデルを実行するには68GB以上のVRAMが必要です。
| 項目 | NVIDIA A100 SXM | NVIDIA H100 SXM | NVIDIA H200 SXM | NVIDIA B200 |
|---|---|---|---|---|
| GPUアーキテクチャ | Ampere | Hopper | Hopper | Blackwell |
| 発売年 | 2020 | 2022 | 2023 | 2024 |
| メモリ(VRAM) | 40GBまたは80GB HBM2e | 80GB HBM3 | 141GB HBM3e | 192GB HBM3e |
| メモリ帯域幅 | 2.0 TB/s(80GBモデル向け) | 3.35 TB/s | 4.8 TB/s | 8.0 TB/s |
| インターコネクト | NVLink 3.0(合計帯域幅600 GB/s) | NVLink 4.0(合計帯域幅900 GB/s) | NVLink 4.0(合計帯域幅900 GB/s) | NVLink 5.0(合計帯域幅1.8 TB/s) |
| 最大FP16/BF16性能 | 312 TFLOPS(スパース時:624 TFLOPS) | 989 TFLOPS(スパース時:1,979 TFLOPS) | 989 TFLOPS(スパース時:1,979 TFLOPS) | 2,250 TFLOPS(スパース時:4,500 TFLOPS) |
| 新精度サポート | TF32 | FP8 | FP8 | FP4、FP6 |
| 主要な革新 | マルチインスタンスGPU(MIG)、TF32 | Transformer Engine(FP8サポート)、DPX | 高速かつ大容量のHBM3eメモリ(141GB)の採用 | 2世代目Transformer Engine(FP4/FP6サポート)、Blackwellチップレット設計 |
| 典型的な最大消費電力(TDP) | 最大400W | 最大700W | 最大1000W | 最大1200W |
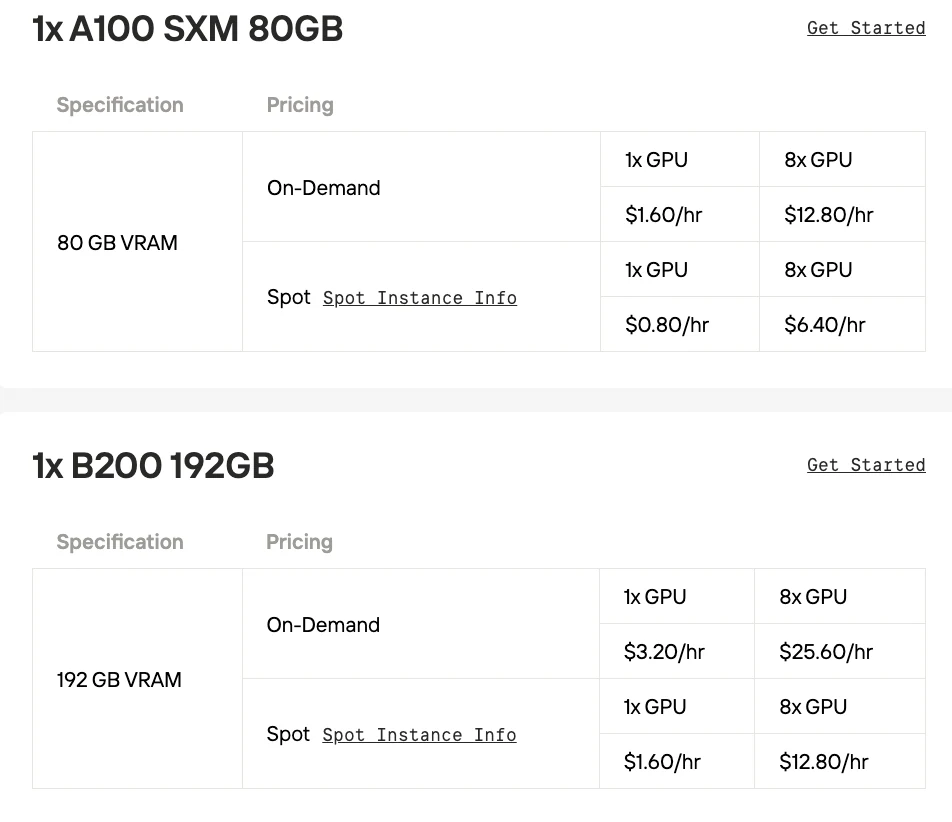
- A100 SXM:AmpereアーキテクチャをベースとしたGPUで、**TF32精度とマルチインスタンスGPU(MIG)**を導入し、性能とリソース利用率を向上させてAIに革命をもたらしました。
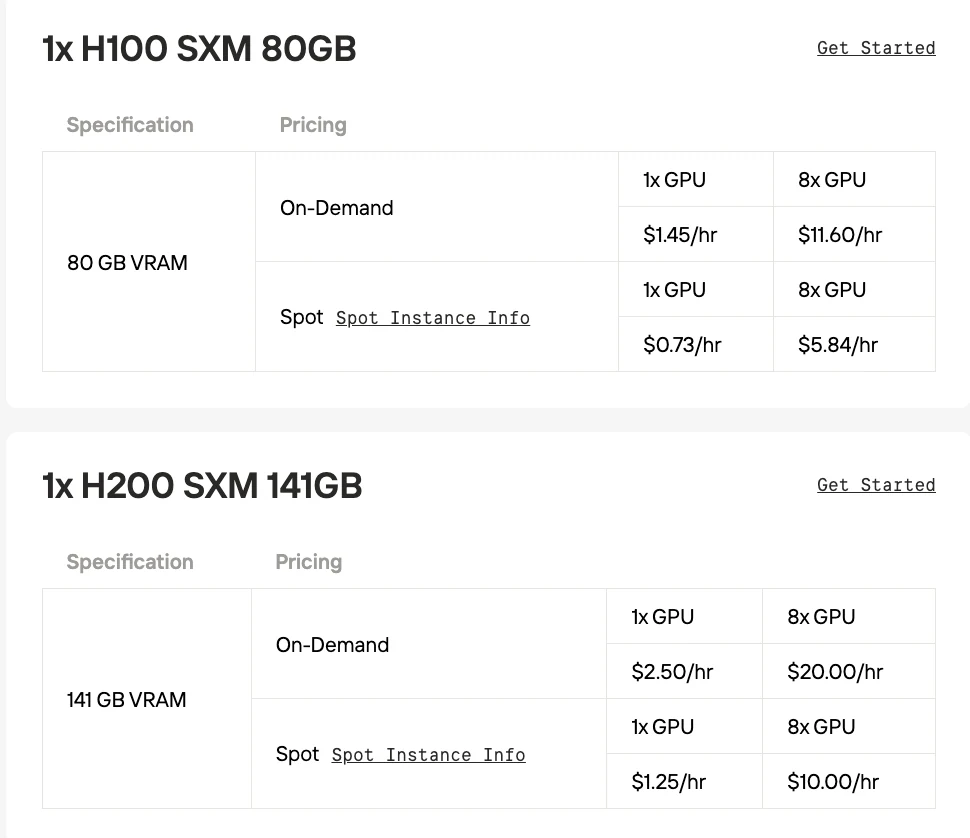
- H100 SXM:Hopperアーキテクチャにアップグレードされ、主要なアップデートはTransformer EngineによるFP8サポートで、TransformerモデルのAI学習を大幅に高速化しました。
- H200 SXM:H100の進化版で、主なアップデートは**より高速で大容量なHBM3eメモリ(141GB)**の採用で、大規模モデルの推論におけるメモリ帯域幅を大幅に向上させています。
- B200:Blackwellアーキテクチャへの大きな飛躍で、デュアルチップレット設計と新FP4/FP6精度をサポートする2世代目Transformer Engineを導入し、兆パラメータ級のAIモデルに圧倒的な性能向上を実現しています。
ローカルデプロイでモデルを試してみたい場合は、Novita AIが手頃で安定したGPUインスタンスサービスを提供しています。スポット価格オプションも利用可能で、コストをさらに削減しながらモデルの性能をテストできます。
性能を維持しつつVRAM使用量を削減する手法
Qwen3-Next-80B-A3BのVRAMフットプリントを削減し、より幅広いハードウェアで実行可能にするための手法をいくつか紹介します。
量子化は最も効果的なアプローチです。モデルの重みを高精度フォーマット(FP16など)から低精度フォーマットに変換することで、メモリ使用量を大幅に削減できます。
- INT8(8bit):FP16と比較して重みのVRAM要件を約半分に削減します。80Bモデルの場合、要件は約80GBになります。
- INT4(4bit):FP16と比較して重みのVRAMを約75%削減し、要件を約40GBに抑えます。
GGUFフォーマットはCPUやMacでのモデル実行に広く使用されていますが、GPUでの用途もあります。Qwen3-Nextのような混合専門家モデルの大きな利点は、GGUFが一部の専門家レイヤーをシステムRAMにオフロードできることで、VRAM要件を削減できる一方、それらのレイヤーがアクティブな場合はパフォーマンスが低下するというトレードオフがあります。
CPUオフロードはこれをさらに推し進める手法で、特に使用頻度の低い専門家レイヤーなどをシステムRAMに配置し、必要な場合にのみVRAMに移動させます。これによりVRAM要件を大幅に削減できますが、RAMとGPUメモリ間の転送が遅いためレイテンシが発生します。
vLLMやSGLangなどの専用推論エンジンの使用を強く推奨します。これらのフレームワークは大規模言語モデル向けに構築されており、効率的なKVキャッシュ管理などの最適化によりメモリオーバーヘッドを削減します。
Flash Attentionも有効な手法で、GPUの高速SRAMをより効果的に活用することで、メモリ効率が高く高速なアテンションアルゴリズムを提供します。
最後に、コンテキスト長の短縮も実用的な解決策です。アプリケーションで非常に長いコンテキストが必要ない場合は、最大コンテキスト長を下げることでKVキャッシュサイズを直接縮小し、VRAMを節約できます。
Qwen3-Next-80B-A3Bを簡単に試す方法:APIを利用する
Novita AIは、シンプルなAPIでAIモデルをデプロイしたい開発者に最適なAIクラウドプラットフォームです。
Qwen3-Next-80B-A3B Instructは入力$0.15/100万トークン、出力$1.5/100万トークンで、コンテキスト長は65,536トークンです。
Qwen3-Next-80B-A3B Thinkingも入力$0.15/100万トークン、出力$1.5/100万トークンで、同じく65,536トークルのコンテキストをサポートしています。
ステップ1:ログインしてモデルライブラリにアクセスする
アカウントにログインし、モデルライブラリボタンをクリックしてください。

ステップ2:モデルを選択する
利用可能なオプションから、ニーズに合ったモデルを選択してください。
ステップ3:無料トライアルを開始する
選択したモデルの機能を探索するために、無料トライアルを開始してください。
ステップ4:APIキーを取得する
APIでの認証のために、新しいAPIキーを提供します。「設定」ページに入ると、画像の指示に従ってAPIキーをコピーできます。

ステップ5:APIをインストールする
使用するプログラミング言語に対応したパッケージマネージャーでAPIをインストールしてください。
インストール後、開発環境に必要なライブラリをインポートします。APIキーでAPIを初期化することで、Novita AI LLMとの連携を開始できます。以下はPythonユーザー向けのチャット補完APIの使用例です。
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)
Trae、Claude Code、Qwen CodeなどのCLIツールの使用
ローカル環境やIDEでNovita AIのトップモデル(Qwen3-Coder、Kimi K2、DeepSeek R1など)をAIコーディングアシスタントとして使用したい場合は、手順は簡単です:APIキーを取得し、ツールをインストールし、環境変数を設定してコーディングを開始してください。
詳細なセットアップコマンドと例については、公式チュートリアルを確認してください:
- Trae:IDEでAIモデルにアクセスするためのステップバイステップガイド
- Claude Code:Windows、Mac、LinuxでClaude Code上でKimi-K2を使用する方法
- Qwen Code:Qwen CodeでOpenAI互換APIを使用する方法(60秒でセットアップ!)
OpenAI Agents SDKを用いたマルチエージェントワークフローの構築
Novita AIをOpenAI Agents SDKと統合することで、高度なマルチエージェントシステムを構築できます:
- プラグアンドプレイ:Novita AIのLLMを任意のOpenAI Agentsワークフローで使用可能です。
- ハンドオフ、ルーティング、ツール使用をサポート:Novita AIのモデルを搭載したエージェントを設計し、委譲、トリアージ、関数実行などを実現できます。
- Python統合:SDKのエンドポイントを
https://api.novita.ai/v3/openaiに設定し、APIキーを使用するだけで簡単に統合できます。
サードパーティプラットフォームでのAPI接続
OpenAI互換API:ClineやCursorなど、OpenAI API標準に対応したツールとのシームレスな移行・統合が可能です。
Hugging Face:Novita AIのエンドポイントを介して、Spaces、パイプライン、Transformersライブラリでモデルを使用できます。
エージェント・オーケストレーションフレームワーク:Continue、AnythingLLM、LangChain、Dify、Langflowなどのパートナープラットフォームと、公式コネクタやステップバイステップの統合ガイドを通じて簡単に連携できます。
Qwen3-Next-80B-A3Bは、アーキテクチャの革新が力任せのパラメータ拡張よりも優れることを証明しています。アテンションと専門家のアクティベーション方法を再考することで、はるかに大規模なモデルに匹敵する、あるいはそれを超える結果を提供しながら、必要なメモリを大幅に削減しています。
実践者にとってこれは、よりアクセスしやすい実験、低いインフラコスト、高速なイテレーションを意味し、性能を犠牲にする必要はありません。80Bの時代は、モデルサイズだけでなく、よりスマートな設計がAIのリーダーシップを決定する転換点となります。
よくある質問
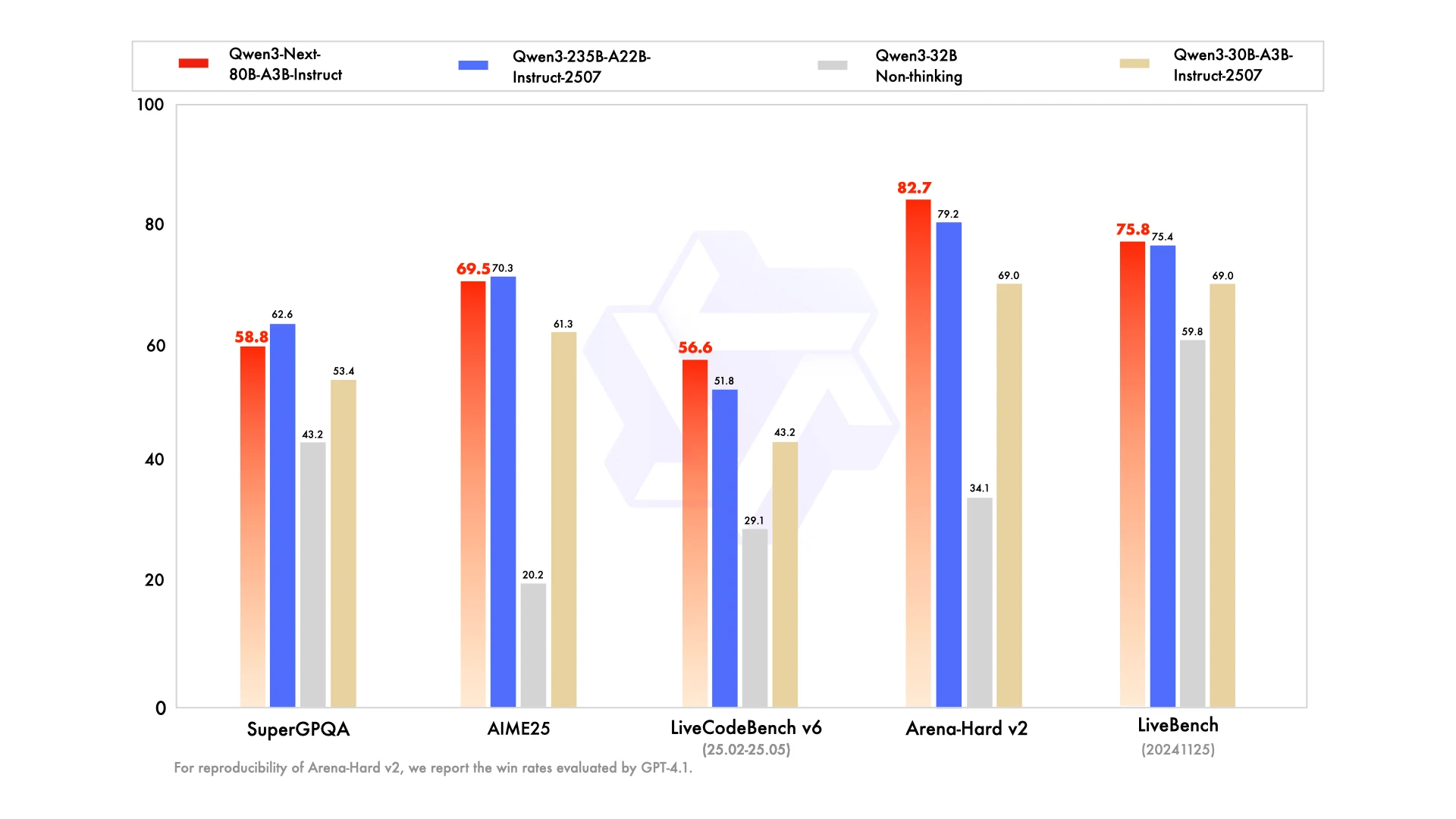
難しいベンチマークで80Bが235Bと競合できるのはなぜですか? Qwen3-Next-80B-A3BはハイブリッドアテンションとスパースMoEを採用して計算コストを削減し、表現能力を失わないため、AIME25、LiveBench、LiveCodeBenchなどのタスクで235Bモデルに匹敵する、あるいは超える性能を発揮します。
長文ドキュメントや長い対話履歴の処理にはどちらのモデルが適していますか? 235Bモデルは元々262K~100万トークルのコンテキストをサポートしていますが、Qwen3-Next-80B-A3Bも最大256Kトークルを効率的に処理できます。ほとんどの実用的なユースケースでは、80Bモデルは十分なコンテキスト処理能力を持ち、より高速な応答速度と低コストを実現しています。
Qwen3-Next-80B-A3Bは人間の嗜好により適していますか? はい。Arena-Hard v2などのベンチマークで、Qwen3-Next-80B-A3BのInstruct版は235Bモデルよりも高いスコアを記録しており、小規模でも強力なアライメントと信頼性を示しています。
Novita AIは、シンプルなAPIでAIモデルをデプロイしたい開発者に最適なAIクラウドプラットフォームで、構築・スケール向けの手頃で信頼性の高いGPUクラウドも提供しています。



