

- لماذا يمكن لنموذج Qwen3-Next-80B-A3B منافسة نموذج 235B بذاكرة VRAM أقل بكثير
- متطلبات ذاكرة الوصول العشوائي للفيديو (VRAM) لاستدلال نموذج Qwen3-Next-80B-A3B
- متطلبات ذاكرة الوصول العشوائي للفيديو (VRAM) لمهام مختلفة
- توصيات وحدات معالجة الرسوميات (GPU) لتشغيل نموذج Qwen3-Next-80B-A3B بسلاسة
- تقليل استخدام ذاكرة الوصول العشوائي للفيديو (VRAM) مع الحفاظ على الأداء
- اختبر نموذج Qwen3-Next-80B-A3B بطريقة بسيطة: استخدم واجهة برمجة التطبيقات (API)
كيف يمكن لنموذج يحتوي على «فقط» 80 مليار معامل أن ينافس نموذجًا ضخمًا من 235 مليار معامل؟ تشير الحكمة التقليدية إلى أن النماذج الأكبر حجمًا تعني دائمًا قوة أكبر، ودقة أعلى، وقدرة استدلال أفضل. ومع ذلك، يتحدى نموذج Qwen3-Next-80B-A3B هذا الافتراض.
تستكشف هذه المقالة السؤال الجوهري: كيف يدير النموذج الأصغر حجمًا منافسة نظام يبلغ حجمه ثلاثة أضعاف حجمه، وبذاكرة وصول عشوائي للفيديو (VRAM) أقل بكثير؟ سنفحص الخيارات المعمارية، وتقنيات الكفاءة، وتجارب الأداء التي تجعل هذا ممكنًا، وما يعنيه ذلك للمطورين والمنظمات التي تسعى إلى تحقيق التوازن الصحيح بين السرعة والتكلفة والقدرات.
لماذا يمكن لنموذج Qwen3-Next-80B-A3B منافسة نموذج 235B بذاكرة VRAM أقل بكثير
تنبع قدرة نموذج Qwen3-Next-80B-A3B الذي يحتوي على 80 مليار معامل على منافسة نموذج ضخم من 235 مليار معامل من معماريته عالية الكفاءة، والتي تعتمد بشكل أساسي على تصميم مزيج الخبراء عالي التشتت (MoE).
من Hugging Face
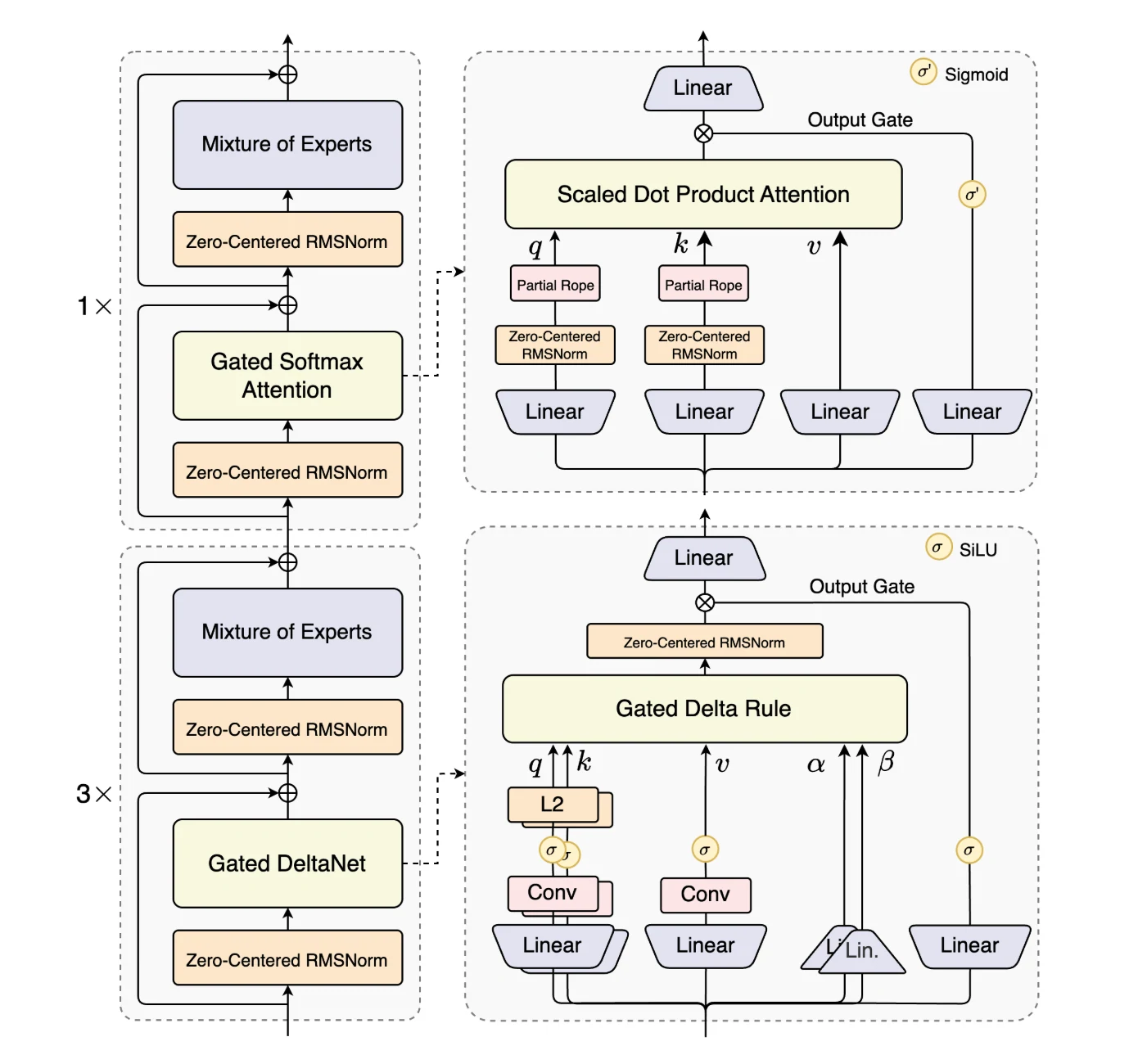
يعد نموذج Qwen3-Next-80B-A3B أول نموذج في سلسلة Qwen3-Next، ويتميز بالابتكارات المعمارية التي تعظم كفاءة السياقات الطويلة والإنتاجية.
يقدم النموذج انتباهًا هجينًا (Hybrid Attention)، الذي يجمع بين Gated DeltaNet والانتباه المقيد لاستبدال الانتباه القياسي، مما يتيح نمذجة سياق فعالة لطول تسلسل فائق الطول.
يقلل تصميم مزيج الخبراء عالي التشتت (MoE) من نسبة التنشيط بشكل كبير، مما يقلل من عدد العمليات الحسابية لكل رمز مع الحفاظ على سعة النموذج.
لضمان المتانة، يدمج النموذج تحسينات الاستقرار مثل تطبيع الطبقات المركزي عند الصفر والمُخفَّف بالوزن.
أخيرًا، يحسّن التنبؤ متعدد الرموز (MTP) من كفاءة التدريب المسبق ويُسرع عملية الاستدلال. معًا، تجعل هذه التحسينات نموذج Qwen3-Next-80B-A3B مناسبًا بشكل فريد للتعامل مع أحمال العمل واسعة النطاق وذات السياقات الطويلة بكفاءة واستقرار.
من Hugging Face
متطلبات ذاكرة الوصول العشوائي للفيديو (VRAM) لاستدلال نموذج Qwen3-Next-80B-A3B
من النقاط الأساسية التي يجب فهمها أنه على الرغم من أن جزءًا صغيرًا فقط من المعاملات يكون نشطًا أثناء الاستدلال، إلا أنه لا يزال يجب تحميل جميع المعاملات البالغ عددها 80 مليار معامل إلى ذاكرة الوصول العشوائي للفيديو (VRAM) الخاصة بوحدة معالجة الرسوميات (GPU).
يتم تحديد كمية ذاكرة الوصول العشوائي للفيديو (VRAM) المطلوبة للاستدلال بشكل أساسي من خلال حجم النموذج ودقة أوزانه. إليك حسابًا أساسيًا لتحميل أوزان النموذج:
دقة FP16/BF16 (دقة 16 بت): هذه هي دقة شائعة للاستدلال، تستخدم 2 بايت لكل معامل. 80 مليار معامل × 2 بايت/معامل = 160 جيجابايت من ذاكرة الوصول العشوائي للفيديو (VRAM)
هذه الـ 160 جيجابايت مخصصة فقط لأوزان النموذج. مطلوب كمية إضافية من ذاكرة الوصول العشوائي للفيديو (VRAM) لذاكرة التخزين المؤقت KV (التي تخزن معلومات الانتباه للسياق)، والتنشيطات، والنفقات العامة التشغيلية الأخرى. لذلك، في الممارسة العملية، ستحتاج إلى أكثر من 160 جيجابايت من ذاكرة الوصول العشوائي للفيديو (VRAM) لتشغيل النموذج غير المكمم، خاصة مع أطوال السياقات الطويلة.
متطلبات ذاكرة الوصول العشوائي للفيديو (VRAM) لمهام مختلفة
بينما يظل الأساس الخاص بذاكرة الوصول العشوائي للفيديو (VRAM) لتحميل النموذج ثابتًا، ي fluctuate استخدام الذاكرة الديناميكي اعتمادًا على تفاصيل المهمة المعنية. يرجع ذلك بشكل أساسي إلى ذاكرة التخزين المؤقت KV، وطول السياق، وحجم الدفعة. تخزن ذاكرة التخزين المؤقت KV مفاتيح وقيم الانتباه لكل رمز في تسلسل الإدخال، ويعد حجمها مساهمًا رئيسيًا في استهلاك ذاكرة الوصول العشوائي للفيديو (VRAM) الديناميكي.
توليد النصوص (مثل: روبوتات الدردشة، التلخيص، الكتابة الإبداعية)
- طول السياق النموذجي: للذكاء الاصطناعي الحواري أو تلخيص المستندات الأقصر، قد يكون طول السياق صغيرًا نسبيًا (مثل: بضعة آلاف من الرموز). هذا يؤدي إلى ذاكرة تخزين مؤقت KV أصغر، وبالتالي استخدام أقل لذاكرة الوصول العشوائي للفيديو (VRAM) الديناميكية.
- توليد النصوص الطويلة: للمهام مثل كتابة المقالات الطويلة أو الحفاظ على سجل محادثة طويل جدًا، ينمو السياق، وكذلك ذاكرة التخزين المؤقت KV. يدعم نموذج Qwen3-Next سياقًا طويلًا جدًا يصل إلى 256 ألف رمز، وسيؤدي استخدام هذه السعة الكاملة إلى زيادة كبيرة في متطلبات ذاكرة الوصول العشوائي للفيديو (VRAM).
على سبيل المثال، حتى على إعداد قوي يتكون من وحدتي معالجة رسوميات H20 (96 جيجابايت لكل منهما)، يمكن أن تؤدي المدخلات ذات الـ 256 ألف رمز إلى مشاكل في الذاكرة.
من Hugging Face
توليد الأكواد
- سياق مستوى المستودع: أحد التطبيقات الرئيسية لنماذج توليد الأكواد المتقدمة هو فهم قاعدة أكواد كاملة للمهام مثل إضافة ميزات جديدة أو تصحيح أخطاء مشاكل معقدة. في هذه السيناريوهات، يمكن أن يكون سياق الإدخال كبيرًا جدًا، ويتكون من ملفات متعددة وعشرات الآلاف من أسطر الأكواد. هذا سيزيد بشكل كبير من كمية ذاكرة الوصول العشوائي للفيديو (VRAM) المطلوبة لذاكرة التخزين المؤقت KV.
- قصاصات أكواد بسيطة: على العكس، سيؤدي توليد دالة صغيرة مستقلة أو إكمال سطر أكواد واحد إلى تأثير ضئيل على ذاكرة الوصول العشوائي للفيديو (VRAM) الديناميكية، على غرار توليد النصوص القصيرة.
متغيرات النموذج (Instruct مقابل Thinking):
- المعمارية الأساسية لإصدارات “Instruct” و “Thinking” من نموذج Qwen3-Next-80B-A3B هي نفسها، مع 80 مليار معامل إجمالي و 3 مليار معامل نشط. لذلك، فإن متطلبات ذاكرة الوصول العشوائي للفيديو (VRAM) الأساسية لتحميل النموذج متطابقة. ومع ذلك، قد يولد نموذج “Thinking” خطوات استدلال وسيطة أطول، مما قد يؤدي إلى استخدام أعلى قليلاً لذاكرة الوصول العشوائي للفيديو (VRAM) الديناميكية أثناء مهام حل المشاكل المعقدة.
باختصار، لا يختلف متطلب ذاكرة الوصول العشوائي للفيديو (VRAM) بشكل جوهري بين “توليد النصوص” و “توليد الأكواد”، بل يعتمد على حجم الإدخال والإخراج للمهمة المعنية. ستتطلب مهام توليد الأكواد المعقدة متعددة الملفات كمية أكبر من ذاكرة الوصول العشوائي للفيديو (VRAM) الديناميكية مقارنة بتلخيص نص بسيط من فقرة واحدة، والعكس صحيح.
توصيات وحدات معالجة الرسوميات (GPU) لتشغيل نموذج Qwen3-Next-80B-A3B بسلاسة
أداء وحدة المعالجة المركزية (CPU)
نعم، يمكن تشغيل نموذج Qwen3-Next 80B على وحدة المعالجة المركزية (CPU). في العرض التوضيحي، أوضح المقدم أنه على الرغم من أن النموذج يحتوي على 80 مليار معامل، إلا أن حوالي 3 مليار معامل فقط يتم تنشيطها أثناء الاستدلال. هذا يجعل التنفيذ على وحدة المعالجة المركزية ممكنًا - وهو ما بدا مستحيلًا قبل بضعة أسابيع فقط.
العيب هو السرعة. على سبيل المثال، عند السؤال عن “ما هي أصغر دولة في العالم؟”، استغرق النموذج 55 دقيقة للإجابة (مدينة الفاتيكان).
https://www.youtube.com/watch?v=F0dBClZ33R4
أداء وحدات معالجة الرسوميات (GPU)
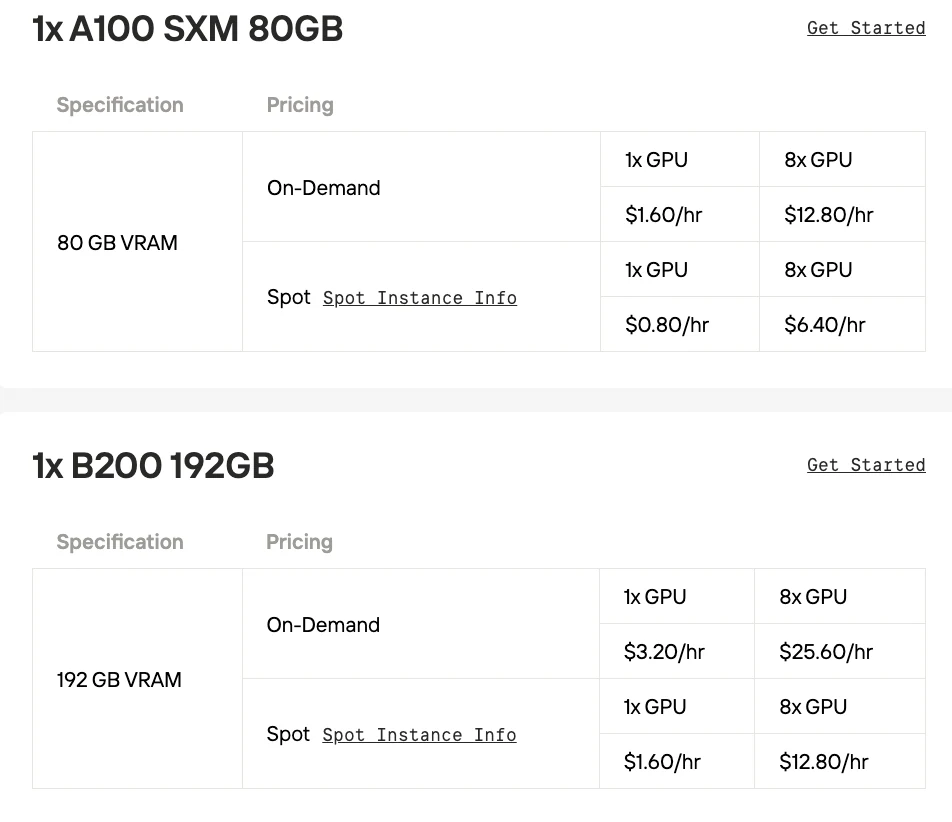
يمكن أيضًا تشغيل نموذج Qwen3-Next 80B على وحدة معالجة رسوميات (GPU) واحدة. مع أربع وحدات معالجة رسوميات أو أكثر، تصبح السرعة - خاصة مع السياقات الطويلة - سريعة للغاية، تكاد تكون خاطفة. من حيث الذاكرة، يتطلب تشغيل النموذج بالدقة الكاملة أكثر من 68 جيجابايت بقليل من ذاكرة الوصول العشوائي للفيديو (VRAM).
| الميزة | NVIDIA A100 SXM | NVIDIA H100 SXM | NVIDIA H200 SXM | NVIDIA B200 |
|---|---|---|---|---|
| معمارية وحدة معالجة الرسوميات (GPU) | Ampere | Hopper | Hopper | Blackwell |
| سنة الإصدار | 2020 | 2022 | 2023 | 2024 |
| الذاكرة (VRAM) | 40 جيجابايت أو 80 جيجابايت HBM2e | 80 جيجابايت HBM3 | 141 جيجابايت HBM3e | 192 جيجابايت HBM3e |
| عرض النطاق للذاكرة | 2.0 تيرابايت/ثانية (لنموذج 80 جيجابايت) | 3.35 تيرابايت/ثانية | 4.8 تيرابايت/ثانية | 8.0 تيرابايت/ثانية |
| الموصل البيني | NVLink 3.0 (عرض نطاق إجمالي 600 جيجابايت/ثانية) | NVLink 4.0 (عرض نطاق إجمالي 900 جيجابايت/ثانية) | NVLink 4.0 (عرض نطاق إجمالي 900 جيجابايت/ثانية) | NVLink 5.0 (عرض نطاق إجمالي 1.8 تيرابايت/ثانية) |
| أقصى أداء لـ FP16/BF16 | 312 TFLOPS (تشتت: 624 TFLOPS) | 989 TFLOPS (تشتت: 1,979 TFLOPS) | 989 TFLOPS (تشتت: 1,979 TFLOPS) | 2,250 TFLOPS (تشتت: 4,500 TFLOPS) |
| دعم الدقة الجديدة | TF32 | FP8 | FP8 | FP4, FP6 |
| الابتكار الرئيسي | Multi-Instance GPU (MIG), TF32 | Transformer Engine (دعم FP8), DPX | ذاكرة HBM3e وعرض نطاق ذاكرة متزايدين | محرك المحولات من الجيل الثاني (دعم FP4/FP6)، تصميم شيبليت بلاكويل |
| الطاقة القصوى النموذجية (TDP) | حتى 400 وات | حتى 700 وات | حتى 1000 وات | حتى 1200 وات |
- A100 SXM: وحدة معالجة الرسوميات (GPU) المعتمدة على معمارية Ampere التي أحدثت ثورة في الذكاء الاصطناعي من خلال إدخال دقة TF32 ووحدة معالجة الرسوميات متعددة المثيلات (MIG) لتحقيق أداء أفضل واستخدام أفضل للموارد.
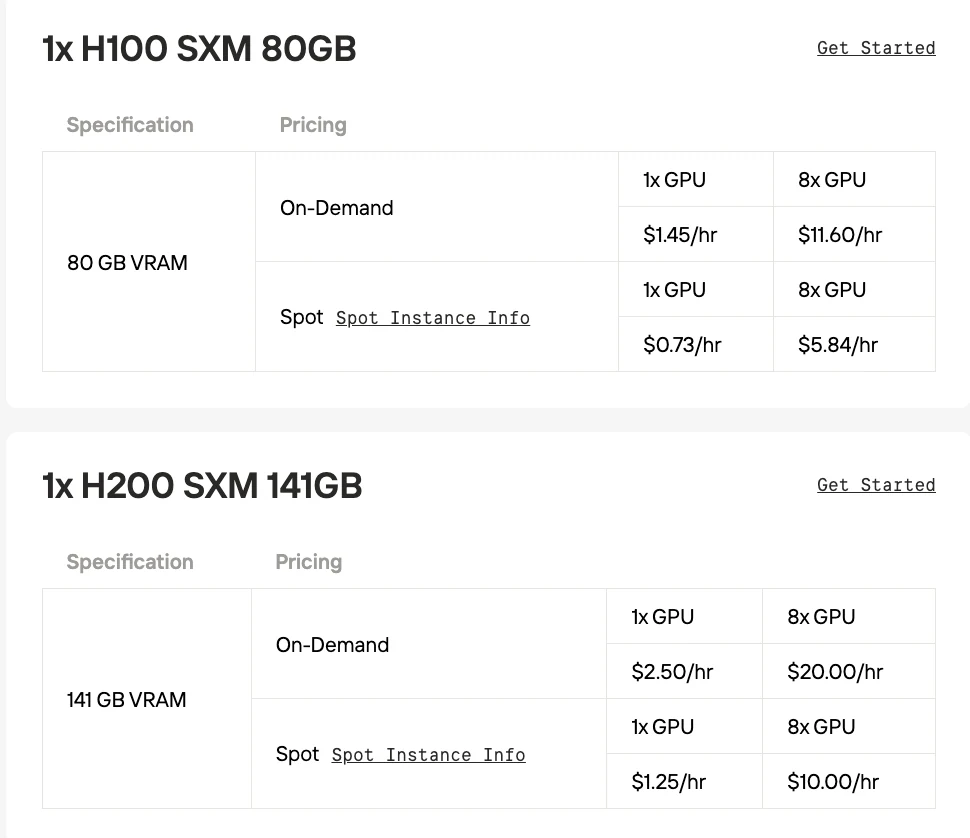
- H100 SXM: تم ترقيتها إلى معمارية Hopper، وكان تحديثها الرئيسي هو محرك المحولات (Transformer Engine) مع دعم FP8، مما يسرع بشكل كبير تدريب نماذج الذكاء الاصطناعي من نوع المحولات.
- H200 SXM: تطور لنموذج H100، يتمثل تحديثها الرئيسي في اعتماد ذاكرة HBM3e الأسرع والأكبر (141 جيجابايت)، مما يعزز بشكل كبير عرض نطاق الذاكرة لاستدلال النماذج الكبيرة.
- B200: قفزة كبيرة إلى معمارية Blackwell، تقدم تصميم شيبليت مزدوج ومحرك محولات من الجيل الثاني مع دعم دقة FP4/FP6 الجديدة، مما يحقق مكاسب أداء هائلة لنماذج الذكاء الاصطناعي ذات التريليون من المعاملات.
إذا كنت ترغب في تجربة النموذج من خلال النشر المحلي، تقدم Novita AI خدمات مثيلات وحدات معالجة الرسوميات (GPU) المستقرة بأسعار معقولة. كما تقدم خيار تسعير فوري لتقليل التكاليف بشكل أكبر، مما يساعدك على اختبار قدرات النموذج.
استخدم وحدة معالجة الرسوميات (GPU) الآن!
تقليل استخدام ذاكرة الوصول العشوائي للفيديو (VRAM) مع الحفاظ على الأداء
هناك عدة تقنيات يمكن أن تساعد في تقليل البصمة الخاصة بذاكرة الوصول العشوائي للفيديو (VRAM) لنموذج Qwen3-Next-80B-A3B، مما يجعل تشغيل النموذج أسهل على مجموعة أوسع من الأجهزة.
التكميم (Quantization) هو النهج الأكثر فعالية. من خلال تحويل أوزان النموذج من تنسيقات الدقة الأعلى (مثل FP16) إلى تنسيقات الدقة الأقل، ينخفض استخدام الذاكرة بشكل كبير.
- INT8 (8 بت): يقلل من احتياجات ذاكرة الوصول العشوائي للفيديو (VRAM) للأوزان بنسبة تصل إلى النصف مقارنة بـ FP16. بالنسبة لنموذج 80B، يخفض هذا المتطلب إلى حوالي 80 جيجابايت.
- INT4 (4 بت): يقلل من ذاكرة الوصول العشوائي للفيديو (VRAM) للأوزان بنسبة تصل إلى 75% مقارنة بـ FP16، مما يخفض المتطلب إلى حوالي 40 جيجابايت.
يستخدم تنسيق GGUF على نطاق واسع لتشغيل النماذج على وحدات المعالجة المركزية (CPU) وأجهزة Mac، ولكنه يحتوي أيضًا على تطبيقات لوحدات معالجة الرسوميات (GPU). الميزة الرئيسية لنماذج مزيج الخبراء مثل Qwen3-Next هي أن GGUF يسمح بتحميل بعض طبقات الخبراء إلى ذاكرة الوصول العشوائي للنظام (RAM)، مما يخفض متطلبات ذاكرة الوصول العشوائي للفيديو (VRAM) على حساب أداء أبطأ عند تنشيط هذه الطبقات.
يأخذ تحميل وحدة المعالجة المركزية (CPU) هذا إلى أبعد من ذلك: يمكن أن توجد أجزاء من النموذج، خاصة طبقات الخبراء نادرة الاستخدام، في ذاكرة الوصول العشوائي للنظام (RAM) ويتم نقلها إلى ذاكرة الوصول العشوائي للفيديو (VRAM) فقط عند الحاجة. هذا يقلل من متطلبات ذاكرة الوصول العشوائي للفيديو (VRAM) بشكل كبير ولكنه يخلق زمن استجابة بسبب عمليات النقل الأبطأ بين ذاكرة الوصول العشوائي للنظام (RAM) وذاكرة الوصول العشوائي للفيديو (VRAM).
يوصى بشدة باستخدام محركات الاستدلال المتخصصة مثل vLLM أو SGLang. تم بناء هذه الأطر لأنظمة اللغات الكبيرة وتستخدم تحسينات مثل إدارة فعالة لذاكرة التخزين المؤقت KV لتقليل النفقات العامة للذاكرة.
يوفر انتباه فلاش (Flash Attention) مسارًا آخر، حيث يقدم نسخة أكثر كفاءة في استخدام الذاكرة وأسرع من خوارزمية الانتباه من خلال الاستفادة بشكل أكثر فعالية من الذاكرة العشوائية عالية السرعة (SRAM) الخاصة بوحدة معالجة الرسوميات (GPU).
أخيرًا، يمكن أن يكون تقليل طول السياق حلاً عمليًا. إذا لم تكن تطبيقاتك بحاجة إلى سياقات طويلة جدًا، فإن خفض أقصى طول للسياق يقلل مباشرة من حجم ذاكرة التخزين المؤقت KV ويوفر ذاكرة الوصول العشوائي للفيديو (VRAM).
اختبر نموذج Qwen3-Next-80B-A3B بطريقة بسيطة: استخدم واجهة برمجة التطبيقات (API)
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات (API) البسيطة الخاصة بنا.
تكلفة نموذج Qwen3-Next-80B-A3B Instruct هي 0.15 دولار لكل مليون رمز إدخال و 1.5 دولار لكل مليون رمز إخراج، مع سياق يصل إلى 65,536 رمزًا.
تكلفة نموذج Qwen3-Next-80B-A3B Thinking أيضًا 0.15 دولار لكل مليون رمز إدخال و 1.5 دولار لكل مليون رمز إخراج، مع نفس السياق البالغ 65,536 رمزًا.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

جرب نموذج Qwen 3 Next 80B A3B الآن!
الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح واجهة برمجة التطبيقات (API Key) الخاص بك
للمصادقة مع واجهة برمجة التطبيقات (API)، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت واجهة برمجة التطبيقات (API)
قم بتثبيت واجهة برمجة التطبيقات (API) باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة واجهة برمجة التطبيقات (API) باستخدام مفتاح API الخاص بك لبدء التفاعل مع نموذج اللغات الكبيرة (LLM) الخاص بـ Novita AI. هذا مثال على استخدام واجهة برمجة التطبيقات لإكمال الدردشة لمستخدمي لغة بايثون.
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)
استخدام واجهة سطر الأوامر (CLI) مثل Trae و Claude Code و Qwen Code
إذا كنت ترغب في استخدام النماذج الرائدة لـ Novita AI (مثل Qwen3-Coder و Kimi K2 و DeepSeek R1) لمساعدة الذكاء الاصطناعي في البرمجة في بيئتك المحلية أو بيئة التطوير المتكاملة (IDE)، فإن العملية بسيطة: احصل على مفتاح API الخاص بك، قم بتثبيت الأداة، قم بتكوين متغيرات البيئة، وابدأ البرمجة.
للحصول على أوامر الإعداد التفصيلية والأمثلة، راجع الدروس الرسمية:
- Trae : دليل خطوة بخطوة للوصول إلى نماذج الذكاء الاصطناعي في بيئة التطوير المتكاملة (IDE) الخاصة بك
- Claude Code:كيفية استخدام Kimi-K2 في Claude Code على أنظمة Windows و Mac و Linux
- Qwen Code:كيفية استخدام واجهة برمجة التطبيقات (API) المتوافقة مع OpenAI في Qwen Code (إعداد في 60 ثانية!)
سير عمل الوكلاء المتعددين باستخدام حزمة تطوير البرامج (SDK) لوكلاء OpenAI
قم ببناء أنظمة وكلاء متعددين متقدمة من خلال دمج Novita AI مع حزمة تطوير البرامج (SDK) لوكلاء OpenAI:
- التوصيل والتشغيل: استخدم نماذج اللغات الكبيرة (LLMs) الخاصة بـ Novita AI في أي سير عمل لوكلاء OpenAI.
- يدعم التسليمات، والتوجيه، واستخدام الأدوات: صمم وكلاء يمكنهم تفويض المهام، أو فرزها، أو تشغيل الوظائف، وكلها مدعومة بنماذج Novita AI.
- تكامل مع لغة بايثون: ببساطة اضبط نقطة نهاية حزمة تطوير البرامج (SDK) إلى
https://api.novita.ai/v3/openaiواستخدم مفتاح API الخاص بك.
توصيل واجهة برمجة التطبيقات (API) على منصات طرف ثالث
واجهة برمجة التطبيقات (API) المتوافقة مع OpenAI: استمتع بالهجرة والتكامل بدون متاعب مع أدوات مثل Cline و Cursor، المصممة لمعيار واجهة برمجة التطبيقات (API) الخاصة بـ OpenAI.
Hugging Face: استخدم النماذج في المساحات (Spaces)، أو خطوط الأنابيب (pipelines)، أو مع مكتبة Transformers عبر نقاط نهاية Novita AI.
أطر الوكلاء والتنسيق: قم بتوصيل Novita AI بسهولة بالمنصات الشريكة مثل Continue، و AnythingLLM,LangChain، و Dify و Langflow عبر موصلات رسمية وأدلة تكامل خطوة بخطوة.
يُعد نموذج Qwen3-Next-80B-A3B دليلًا على أن الابتكار في المعمارية يمكن أن يتفوق على زيادة المعاملات بالقوة الغاشمة. من خلال إعادة التفكير في كيفية تنشيط الانتباه والخبراء، يقدم النموذج نتائج تضاهي أو تتفوق على النماذج الأكبر حجمًا بكثير مع الحاجة إلى ذاكرة أقل بكثير.
للممارسين، هذا يعني تجارب أكثر سهولة، وتكاليف بنية تحتية أقل، وتكرار أسرع - كل ذلك دون التضحية بالأداء. يمثل عصر 80 مليار معامل نقطة تحول حيث يحدد التصميم الأذكى، وليس فقط حجم النموذج، القيادة في مجال الذكاء الاصطناعي.
الأسئلة الشائعة
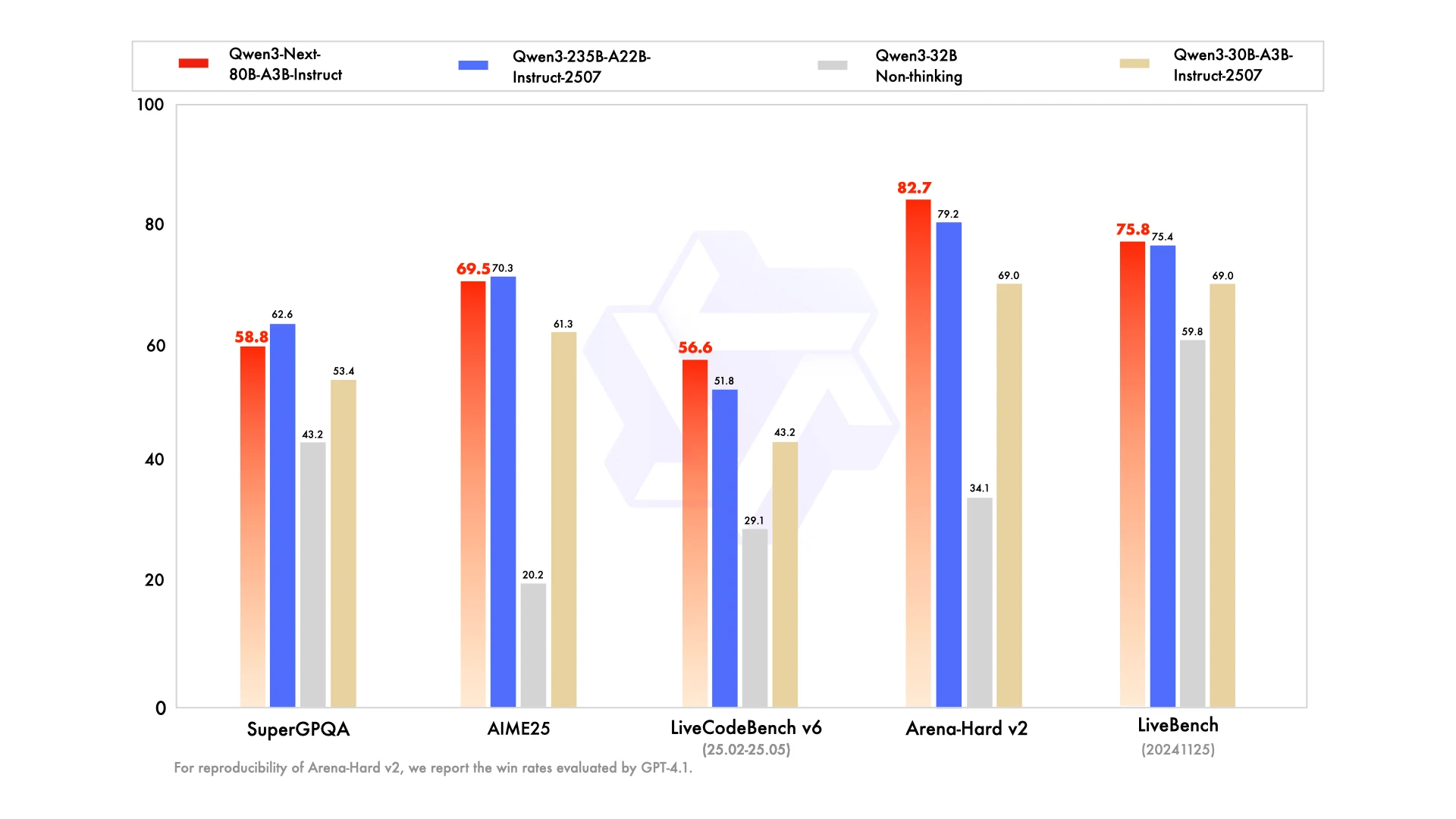
كيف يمكن لنموذج 80B منافسة نموذج 235B في معايير التقييم الصعبة؟
لأن نموذج Qwen3-Next-80B-A3B يستخدم انتباهًا هجينًا ومزيج خبراء متفرع (sparse MoE) لتقليل تكاليف الحساب دون فقدان القدرة التمثيلية. هذا يسمح له بمطابقة أو حتى تجاوز نماذج 235B في مهام مثل AIME25 و LiveBench و LiveCodeBench.
أي نموذج أفضل للمستندات الطويلة أو سجل المحادثات الممتد؟
يدعم متغير 235B بشكل أصلي سياقات تتراوح من 262 ألف رمز إلى 1 مليون رمز، ولكن نموذج Qwen3-Next-80B-A3B يعالج أيضًا ما يصل إلى 256 ألف رمز بكفاءة. لمعظم حالات الاستخدام في العالم الحقيقي، يوفر نموذج 80B معالجة سياق كافية مع أوقات استجابة أسرع وتكلفة أقل.
هل يتماشى نموذج Qwen3-Next-80B-A3B بشكل أفضل مع التفضيلات البشرية؟
نعم. في معايير التقييم مثل Arena-Hard v2، حصل إصدار Instruct من نموذج Qwen3-Next-80B-A3B على درجة أعلى من نموذج 235B، مما يدل على تماسك وموثوقية أقوى حتى على نطاق أصغر.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات (API) البسيطة الخاصة بنا، مع توفير سحابة وحدات معالجة رسوميات (GPU) بأسعار معقولة وموثوقة للبناء والتوسع.



