

Wichtige Highlights
KI-Inferenz: Verwenden Sie L40S für mittelgroße Bereitstellungen; wählen Sie H100 für Hyperscale-Inferenzaufgaben.
KI-Training: L40S eignet sich ideal für Modelle mit bis zu 30B Parametern; H100 ist für das Training von Modellen mit 70B+ erforderlich.
Grafik und Visualisierung: L40S ist mit RT-Kernen der klare Gewinner; H100 hat überhaupt keine Grafikbeschleunigung.
Wissenschaftliches Rechnen: Wählen Sie H100 für hochpräzise FP64-Workloads; L40S bewältigt grundlegende Simulationen effizient.

Novita AI

Runpod
Die Kosten für die Nutzung von L40S bei Novita AI betragen etwa die Hälfte des Preises von RunPod.
Die Wahl zwischen L40S und H100 ist keine leichte Aufgabe. Legen Sie Wert auf die Rohleistung des H100 für groß angelegtes KI-Training und wissenschaftliche Präzision oder auf die Vielseitigkeit und Effizienz des L40S für Inferenz, Training und Visualisierung?
Jede GPU hat ihre eigenen Stärken – aber welche ist wirklich die richtige für Ihre Anforderungen? In der folgenden Analyse werden wir alles aufschlüsseln und Ihnen bei der Entscheidung helfen.
Die NVIDIA L40S und H100 sind beide leistungsstarke GPUs, die für anspruchsvolle Workloads entwickelt wurden, aber unterschiedliche Rollen erfüllen. Die L40S ist eine vielseitige, energieeffiziente GPU, die für KI-Inferenz, Grafik-Rendering und allgemeine Rechenaufgaben optimiert ist. Die H100 hingegen ist NVIDIAs Flaggschiff für groß angelegtes KI-Training und HPC und bietet eine unübertroffene Tensor- und doppelt genaue Rechenleistung.
L40S vs H100: Echte KI-Workloads
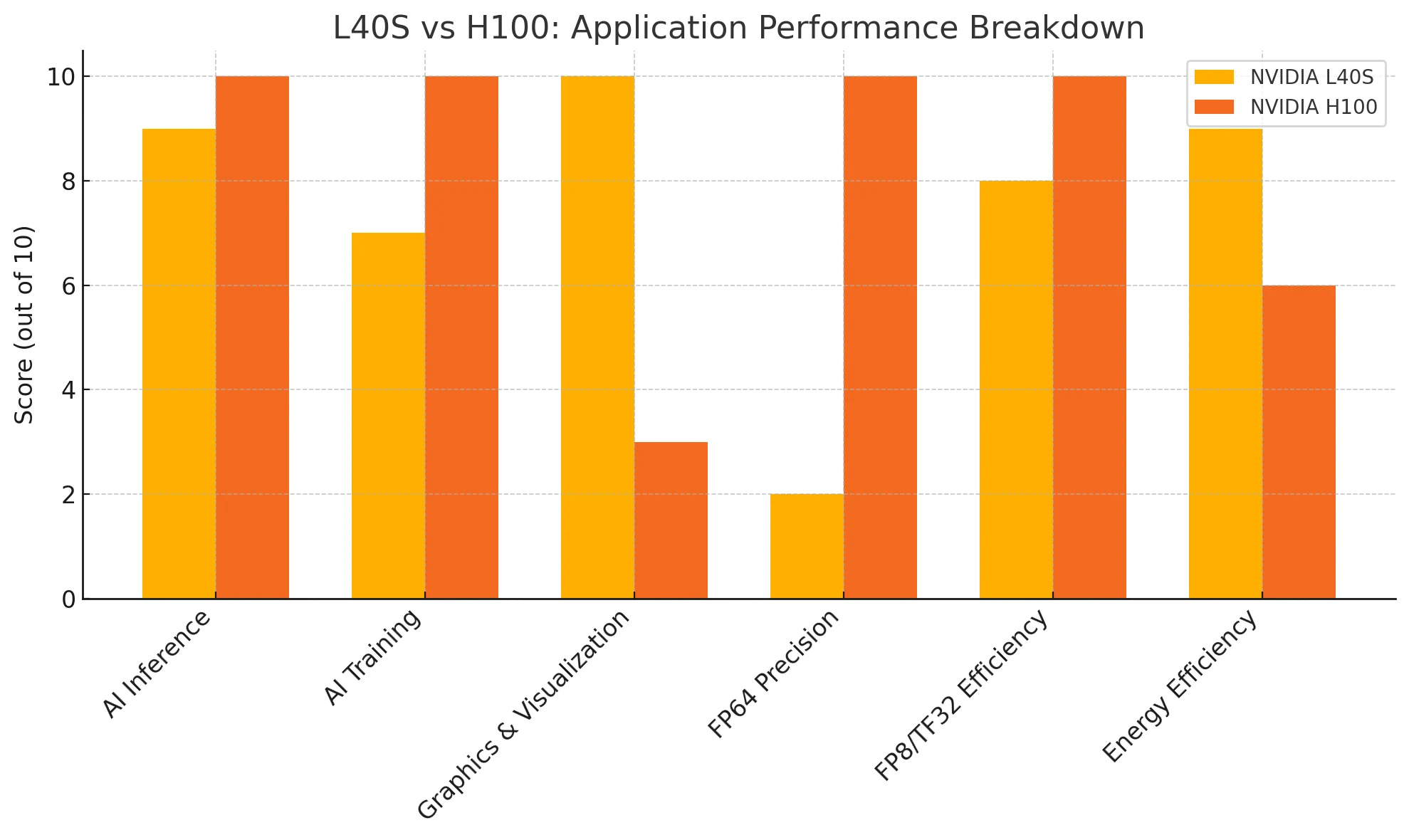
KI-Inferenz:
H100 hat einen leichten Vorteil bei der rohen Inferenzleistung, aber L40S liefert dennoch hervorragende Ergebnisse bei höherer Energieeffizienz.
KI-Training:
H100 bietet eine unübertroffene Leistung für extrem große Modelle. L40S ist zwar nicht so leistungsstark, aber für mittlere bis große Trainingsaufgaben äußerst kosteneffizient.
Grafik und Visualisierung:
L40S gewinnt eindeutig, verfügt über dedizierte RT-Kerne und optimierte Treiber für professionelles Rendering und Visualisierungsworkloads.
FP64-Präzision:
H100 ist die erste Wahl für wissenschaftliches Rechnen und hochpräzise Workloads. L40S unterstützt grundlegende FP64-Aufgaben.
FP8/TF32-Effizienz:
H100 führt bei hochpräzisem Tensor-Computing, aber die FP8-Inferenzfähigkeiten von L40S sind für die meisten Bereitstellungsszenarien mehr als ausreichend.
L40S ist die beste Wahl für Benutzer, die eine vielseitige, energieeffiziente GPU für Inferenz, Grafik und ausgewogenes Training suchen. H100 zeichnet sich durch groß angelegtes KI-Training und hochpräzises Rechnen aus, aber seine Vorteile sind mit höheren Strom- und Kostenanforderungen verbunden. Die richtige Wahl hängt von Ihrem spezifischen Workload und Ihren Skalierungsanforderungen ab.
Warum Entwickler L40S oder H100 wählen
KI-Inferenz
| Metrik | L40S | H100 |
|---|---|---|
| FP8 Tensor (Sparse) | 733|1466 PFLOPS | 3958|3341 |
| TDP | 300W–350W | Bis zu 700W (SXM5) |
| MIG | Nein | Ja |
✅ Empfehlung:
- Wählen Sie H100, wenn Sie den höchsten Single-Node-Inferenzdurchsatz für sehr große Modelle (≥ 70B Parameter) benötigen und Ihr Rechenzentrums-Budget und Strombudget 700 W pro GPU verkraften können.
- Wählen Sie L40S, wenn Strom, CapEx oder Slot-Anzahl begrenzt sind oder Sie viele mittelgroße Modelle (≤ 40B) mit MIG hosten möchten. Es bietet das beste Preis-Leistungs-Verhältnis und eine starke Leistung pro Watt und unterstützt dennoch FP8 und MIG.
KI-Training
| Metrik | L40S | H100 |
|---|---|---|
| TF32 Tensor (Sparse) | 183|366 | 989|835 |
| Speicherbandbreite | 864 GB/s (GDDR6) | Bis zu 3,9 TB/s (NVL) |
| Speicherkapazität | 48 GB | 80 |98GB |
✅ Empfehlung:
- H100 ist die erste Wahl für das Training massiver Modelle (z. B. >70B Parameter) dank seiner überlegenen Speicherbandbreite und Transformer Engine.
- L40S ist eine gute Wahl für Modelle bis zu 30B–40B mit moderner Architektur und Tensor-Kernen der 4. Generation.
Kostenbewusste Labore und Startups bevorzugen oft L40S für FP8/TF32 Mixed-Precision-Training mit akzeptabler Geschwindigkeit.
Grafik, Visualisierung und Echtzeitsimulation
| Metrik | L40S | H100 |
|---|---|---|
| RT-Kerne | 142 (3. Gen) | Keine |
✅ Empfehlung:
- L40S gewinnt standardmäßig. Mit dedizierten RT-Kernen unterstützt es Echtzeit-Raytracing und professionelle Grafik-Workloads.
- H100 hat keine RT-Kerne und ist für Rendering, Simulations-Engines oder Omniverse-basierte Pipelines ungeeignet.
Wissenschaftliches Rechnen / HPC
| Metrik | L40S | H100 |
|---|---|---|
| FP64-Leistung | 1,4 TFLOPS | 26|34TFLOPS |
✅ Empfehlung:
- H100 ist unerlässlich für doppelt genaue Gleitkomma-Workloads wie Quantenmechanik, Strömungsdynamik oder Materialwissenschaften.
- L40S, obwohl zu grundlegender FP64 fähig, sollte nicht verwendet werden, wenn hohe Präzision erforderlich ist.
| Metrik | NVIDIA L40S (PCIe) | NVIDIA H100 (SXM5) |
|---|---|---|
| Architektur | Ada Lovelace | Hopper |
| CUDA-Kerne | 18.176 | 16.896 |
| Tensor-Kerne | 568 (4. Gen) | 528 (4. Gen + Transformer Engine) |
| RT-Kerne | 142 (3. Gen) | 0 |
| FP32-Spitze | 91,6 TFLOPS | 66,9 TFLOPS |
| TF32 Tensor (dense) | 366 TFLOPS | 989 TFLOPS |
| TF32 Tensor (sparse ×2) | 733 PFLOPS | 1.979 PFLOPS |
| FP8 Tensor (dense) | 1.466 PFLOPS | 3.958 PFLOPS |
| FP8 Tensor (sparse ×2) | 2,93 PFLOPS | 7,91 PFLOPS |
| FP64-Skalar | 1,43 TFLOPS | 34 TFLOPS |
| FP64 Tensor | — | 60 TFLOPS |
| Speicherbandbreite | 864 TB/s (GDDR6) | 3,35 TB/s (HBM3) |
| TDP | 300 – 350 W | 700 W |
L40S vs H100: Energieeffizienz
| Anwendungsszenario | GPU | Hardwarekosten (USD) | Monatliche Stromkosten (USD) | Hauptvorteile |
|---|---|---|---|---|
| KI-Inferenz | L40S | 7.569 – 10.750 USD | ~32,10 USD | L40S bietet etwa 80 % der Leistung von H100 |
| H100 | 27.000 – 40.000 USD | ~64,25 USD | ||
| KI-Training | L40S | 7.569 – 10.750 USD | ~32,10 USD | Effizient für Modelle bis ~30B Parameter |
| H100 | 27.000 – 40.000 USD | ~64,25 USD | Erforderlich für Modelle im Bereich 70B+ | |
| Grafik und Visualisierung | L40S | 7.569 – 10.750 USD | ~32,10 USD | 142 RT-Kerne, optimierte Ada-Treiber; ideal für Omniverse, Blender, 3D-Pipelines |
| H100 | 27.000 – 40.000 USD | ~64,25 USD | ❌ Keine RT-Kerne, keine Rendering-Optimierung | |
| Wissenschaftliches Rechnen (FP64) | L40S | 7.569 – 10.750 USD | ~32,10 USD | Grundlegende FP64 (1,4 TFLOPS) |
| H100 | 27.000 – 40.000 USD | ~64,25 USD | Überlegene FP64-Leistung für hochpräzise Workloads |
Wie man L40S und H100 zu einem sehr günstigen Preis betreibt
Novita AI bietet eine cloudbasierte Plattform mit leistungsstarken GPU-Instanzen. Dank leistungsstarker GPUs gewährleistet es effiziente Leistung für komplexe Aufgaben, verbessert die Zugänglichkeit für die Bereitstellung auf verschiedenen Hardwareplattformen und bietet eine kosteneffiziente Lösung im Vergleich zur lokalen Hardwarewartung für große KI-Bereitstellungen.
Schritt 1: Registrieren Sie ein Konto
Erstellen Sie Ihr Novita AI-Konto über unsere Website. Navigieren Sie nach der Registrierung zum Bereich “Erkunden” in der linken Seitenleiste, um unsere GPU-Angebote zu sehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2: Vorlagen und GPU-Server erkunden
Wählen Sie aus Vorlagen wie PyTorch, TensorFlow oder CUDA, die zu Ihren Projektanforderungen passen. Wählen Sie dann Ihre bevorzugte GPU-Konfiguration – Optionen umfassen die leistungsstarke L40S, RTX 4090 oder A100 SXM4, jede mit unterschiedlichen VRAM-, RAM- und Speicherspezifikationen.

Schritt 3: Passen Sie Ihre Bereitstellung an
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um eine optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen zu gewährleisten.

Schritt 4: Starten Sie eine Instanz
Wählen Sie “Instanz starten”, um Ihre Bereitstellung zu beginnen. Ihre leistungsstarke GPU-Umgebung ist innerhalb weniger Minuten einsatzbereit, sodass Sie sofort mit Ihren Machine Learning-, Rendering- oder Rechenprojekten beginnen können.
Wenn Ihr Workload Effizienz, Flexibilität und Bereitstellungsskala betont, ist die L40S die intelligentere Investition. Wenn Sie große LLMs, HPC-Cluster oder latenzkritische KI-Systeme aufbauen und das Budget dafür haben, liefert die H100 branchenführende Leistung.
Häufig gestellte Fragen
Welche GPU ist besser für KI-Inferenz?
Beide schneiden gut ab, aber L40S ist aufgrund der nativen FP8-Unterstützung und des geringeren Stromverbrauchs effizienter und kostengünstiger. H100 lohnt sich nur, wenn Sie extrem hohen Durchsatz oder die niedrigste Latenz in großem Maßstab benötigen.
Kann ich große Modelle auf L40S trainieren?
Ja – für mittleres bis großes Training ist L40S mit ausgezeichneter TF32-Leistung eine solide Wahl. Für massive Foundation-Modelle oder Multi-GPU-Cluster ist H100 besser.
Welche GPU hat eine bessere Energieeffizienz?
L40S. Seine TDP von 300–350 W und starke Leistung pro Watt machen es zu einer besseren Option für stromsensible Bereitstellungen. H100 (bis zu 700 W SXM5) erfordert erhebliche Infrastruktur.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.
Empfohlene Lektüre



