

النقاط الرئيسية
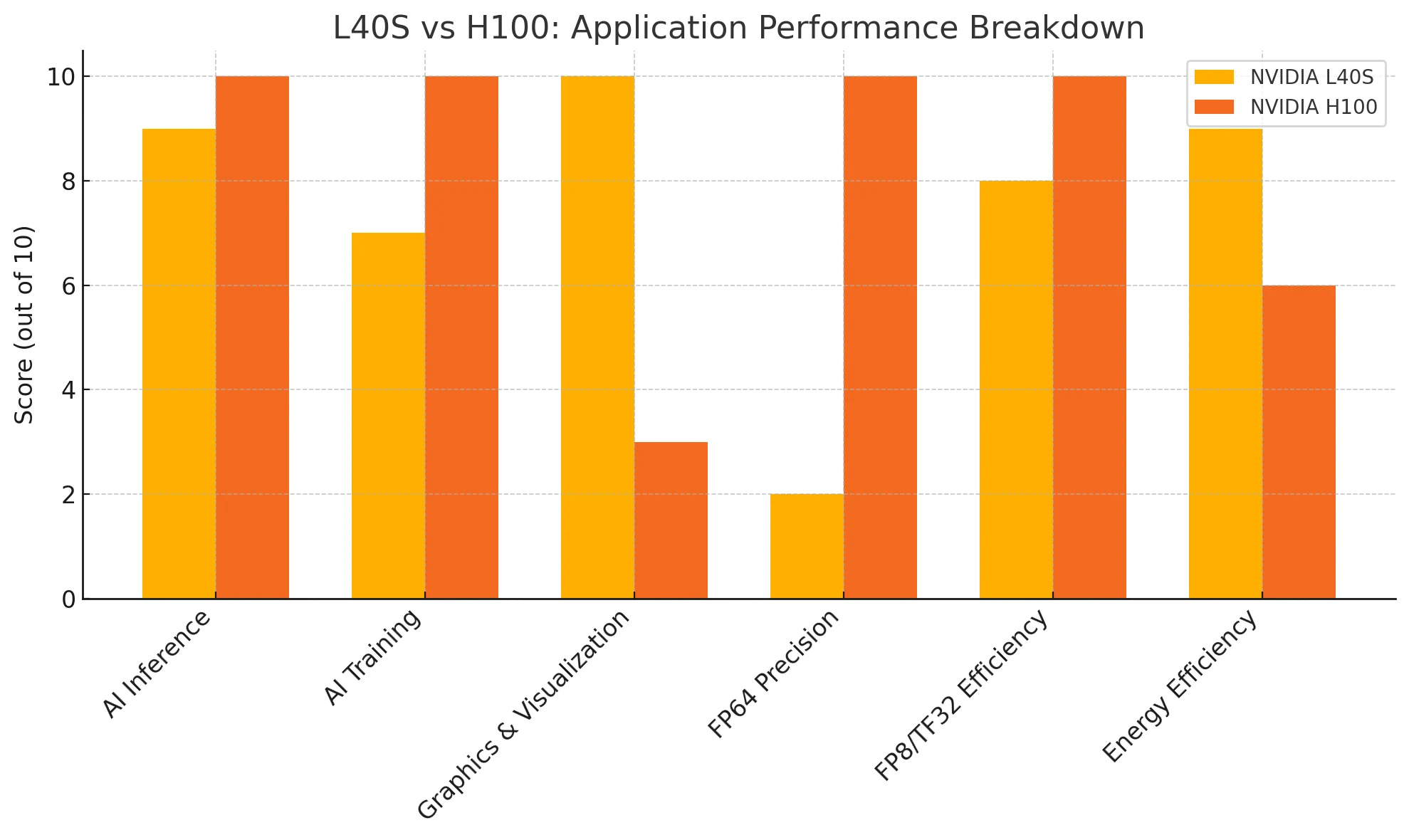
استدلال الذكاء الاصطناعي: استخدم L40S للنشر في النطاق المتوسط؛ اختر H100 لمهام الاستدلال فائقة الاتساع.
تدريب الذكاء الاصطناعي: L40S مثالي للنماذج حتى 30 مليار معامل؛ H100 ضروري لتدريب النماذج التي تتجاوز 70 مليار معامل.
الرسوميات والتصور: L40S هو الفائز الواضح بفضل أنوية تتبع الأشعة (RT Cores)؛ H100 يفتقر تمامًا لتسريع الرسوميات.
الحوسبة العلمية: اختر H100 لأعباء العمل عالية الدقة FP64؛ L40S يعالج عمليات المحاكاة الأساسية بكفاءة.

Novita AI

Runpod
تبلغ تكلفة استخدام L40S على Novita AI حوالي نصف سعر RunPod.
الاختيار بين L40S و H100 ليس بالمهمة السهلة. هل تفضل القوة الخام لـ H100 لتدريب الذكاء الاصطناعي على نطاق واسع والدقة العلمية، أم تنوع وكفاءة L40S في الاستدلال والتدريب والتصور؟
لكل وحدة معالجة رسومية نقاط قوة فريدة – ولكن أيهما مناسب حقًا لاحتياجاتك؟ في التحليل التالي، سنقوم بتفصيل كل شيء ونساعدك على اتخاذ القرار.
كل من NVIDIA L40S و H100 هما وحدتا معالجة رسومية قويتان مصممتان لأعباء العمل الصعبة، لكنهما تختلفان في الأدوار. L40S هي وحدة معالجة رسومية متعددة الاستخدامات وفعالة من حيث الطاقة ومُحسّنة لاستدلال الذكاء الاصطناعي وعرض الرسوميات والحوسبة العامة. من ناحية أخرى، H100 هي الرائدة من NVIDIA لتدريب الذكاء الاصطناعي على نطاق واسع والحوسبة عالية الأداء (HPC)، وتقدم أداءً لا يُضاهى في عمليات التنسور والحوسبة مزدوجة الدقة.
L40S مقابل H100: أعباء عمل الذكاء الاصطناعي الواقعية
استدلال الذكاء الاصطناعي:
H100 لها أفضلية طفيفة في أداء الاستدلال الخام، لكن L40S لا تزال تقدم نتائج ممتازة مع كفاءة طاقة أعلى.
تدريب الذكاء الاصطناعي:
H100 تقدم أداءً لا يُضاهى للنماذج فائقة الضخامة. L40S، على الرغم من أنها ليست بنفس القوة، إلا أنها فعالة من حيث التكلفة لمهام التدريب المتوسطة إلى الكبيرة.
الرسوميات والتصور:
L40S تفوز بوضوح، حيث تحتوي على أنوية تتبع الأشعة مخصصة وبرامج تشغيل مُحسّنة لأعباء عمل العرض والتصور المهني.
دقة FP64:
H100 هي الخيار الأمثل للحوسبة العلمية وأعباء العمل عالية الدقة. L40S تدعم مهام FP64 الأساسية.
كفاءة FP8/TF32:
H100 تتصدر في الحوسبة التنسورية عالية الدقة، لكن قدرات FP8 الاستدلالية لـ L40S كافية لمعظم سيناريوهات النشر.
L40S هي الخيار الأفضل للمستخدمين الذين يبحثون عن وحدة معالجة رسومية متعددة الاستخدامات وفعالة من حيث الطاقة للاستدلال والرسوميات والتدريب المتوازن. H100 تتفوق في تدريب الذكاء الاصطناعي على نطاق واسع والحوسبة عالية الدقة، لكن مزاياها تأتي مع متطلبات طاقة وتكلفة أعلى. يعتمد الاختيار الصحيح على عبء العمل الخاص بك واحتياجات قابلية التوسع.
لماذا يختار المطورون L40S أو H100؟
استدلال الذكاء الاصطناعي
| المقياس | L40S | H100 |
|---|---|---|
| FP8 Tensor (متناثر) | 733|1466 PFLOPS | 3958|3341 |
| TDP | 300W–350W | حتى 700W (SXM5) |
| MIG | لا | نعم |
✅ التوصية:
- اختر H100 إذا كنت بحاجة إلى أعلى إنتاجية استدلال لعقدة واحدة للنماذج الكبيرة جدًا (≥ 70 مليار معامل) وكانت ميزانية مركز البيانات والطاقة تتحمل 700 واط لكل GPU.
- اختر L40S عندما تكون الطاقة أو التكلفة الرأسمالية أو عدد الفتحات محدودة، أو عندما تخطط لاستضافة العديد من النماذج متوسطة الحجم (≤ 40 مليار) مع MIG. إنها تقدم أفضل أداء مقابل الدولار وأداء قوي لكل واط، مع دعم FP8 و MIG.
تدريب الذكاء الاصطناعي
| المقياس | L40S | H100 |
|---|---|---|
| TF32 Tensor (متناثر) | 183|366 | 989|835 |
| عرض النطاق الترددي للذاكرة | 864 GB/s (GDDR6) | حتى 3.9TB/s (NVL) |
| سعة الذاكرة | 48 GB | 80 |98GB |
✅ التوصية:
- H100 هي الخيار الأمثل لتدريب النماذج الضخمة (مثل >70 مليار معامل) بفضل عرض النطاق الترددي للذاكرة الفائق و محرك التحويل (Transformer Engine).
- L40S مناسبة بقوة للنماذج حتى 30B–40B، مع بنية حديثة وأنوية تنسور من الجيل الرابع.
غالبًا ما تفضل المختبرات والشركات الناشئة الحساسة للتكلفة L40S لـ التدريب المختلط الدقة FP8/TF32 بسرعة مقبولة.
الرسوميات والتصور والمحاكاة في الوقت الفعلي
| المقياس | L40S | H100 |
|---|---|---|
| أنوية RT | 142 (الجيل الثالث) | لا يوجد |
✅ التوصية:
- L40S تفوز افتراضيًا. مع أنوية RT المخصصة، تدعم تتبع الأشعة في الوقت الفعلي وأعباء عمل الرسوميات المهنية.
- H100 لا تحتوي على أنوية RT وهي غير مناسبة لعرض الرسوميات أو محركات المحاكاة أو أنابيب العمل المستندة إلى Omniverse.
الحوسبة العلمية / HPC
| المقياس | L40S | H100 |
|---|---|---|
| أداء FP64 | 1.4 TFLOPS | 26|34TFLOPS |
✅ التوصية:
- H100 ضرورية لأعباء العمل ذات الفاصلة العائمة مزدوجة الدقة، مثل ميكانيكا الكم أو ديناميكيات الموائع أو علوم المواد.
- L40S، رغم قدرتها على FP64 الأساسي، لا ينبغي استخدامها حيث تكون الدقة العالية إلزامية.
| المقياس | NVIDIA L40S (PCIe) | NVIDIA H100 (SXM5) |
|---|---|---|
| الهندسة المعمارية | Ada Lovelace | Hopper |
| أنوية CUDA | 18,176 | 16,896 |
| أنوية التنسور | 568 (الجيل الرابع) | 528 (الجيل الرابع + محرك التحويل) |
| أنوية RT | 142 (الجيل الثالث) | 0 |
| ذروة FP32 | 91.6 TFLOPS | 66.9 TFLOPS |
| TF32 Tensor (كثيف) | 366 TFLOPS | 989 TFLOPS |
| TF32 Tensor (متناثر ×2) | 733 PFLOPS | 1.979 PFLOPS |
| FP8 Tensor (كثيف) | 1.466 PFLOPS | 3.958 PFLOPS |
| FP8 Tensor (متناثر ×2) | 2.93 PFLOPS | 7.91 PFLOPS |
| FP64 Scalar | 1.43 TFLOPS | 34 TFLOPS |
| FP64 Tensor | — | 60 TFLOPS |
| عرض النطاق الترددي للذاكرة | 864 TB/s (GDDR6) | 3.35 TB/s (HBM3) |
| TDP | 300 – 350 W | 700 W |
L40S مقابل H100: كفاءة الطاقة
| سيناريو التطبيق | GPU | التكلفة المادية (بالدولار الأمريكي) | تكلفة الطاقة الشهرية (بالدولار الأمريكي) | المزايا الرئيسية |
|---|---|---|---|---|
| استدلال الذكاء الاصطناعي | L40S | $7,569 – $10,750 | ~$32.10 | توفر L40S حوالي 80% من أداء H100 |
| H100 | $27,000 – $40,000 | ~$64.25 | ||
| تدريب الذكاء الاصطناعي | L40S | $7,569 – $10,750 | ~$32.10 | فعالة للنماذج حتى ~30 مليار معامل |
| H100 | $27,000 – $40,000 | ~$64.25 | مطلوبة للنماذج بحجم 70 مليار+ | |
| الرسوميات والتصور | L40S | $7,569 – $10,750 | ~$32.10 | 142 نواة RT، برامج تشغيل Ada مُحسّنة؛ مثالية لـ Omniverse و Blender وأنابيب العمل ثلاثية الأبعاد |
| H100 | $27,000 – $40,000 | ~$64.25 | ❌ لا توجد أنوية RT، لا تحسين للعرض | |
| الحوسبة العلمية (FP64) | L40S | $7,569 – $10,750 | ~$32.10 | FP64 أساسي (1.4 TFLOPS) |
| H100 | $27,000 – $40,000 | ~$64.25 | أداء FP64 فائق لأعباء العمل عالية الدقة |
كيفية تشغيل L40S و H100 بسعر منخفض جدًا؟
توفر Novita AI منصة سحابية مع مثيلات GPU عالية الأداء. مع وحدات معالجة رسومية قوية، تضمن أداءً فعالاً للمهام المعقدة، وتعزز إمكانية الوصول للنشر عبر أجهزة مختلفة، وتقدم حلاً فعالاً من حيث التكلفة مقارنة بصيانة الأجهزة المحلية لنشر الذكاء الاصطناعي على نطاق واسع.
الخطوة 1: إنشاء حساب
أنشئ حسابك في Novita AI من خلال موقعنا الإلكتروني. بعد التسجيل، انتقل إلى قسم “Explore” في الشريط الجانبي الأيسر لعرض عروض GPU الخاصة بنا وابدأ رحلة تطوير الذكاء الاصطناعي.

الخطوة 2: استكشاف القوالب وخوادم GPU
اختر من بين القوالب مثل PyTorch أو TensorFlow أو CUDA التي تناسب احتياجات مشروعك. ثم حدد تكوين GPU المفضل لديك—تتضمن الخيارات L40S القوية أو RTX 4090 أو A100 SXM4، لكل منها مواصفات مختلفة من VRAM و RAM والتخزين.

الخطوة 3: تخصيص النشر الخاص بك
خصص بيئتك عن طريق اختيار نظام التشغيل المفضل لديك وخيارات التكوين لضمان الأداء الأمثل لأعباء عمل الذكاء الاصطناعي الخاصة بك واحتياجات التطوير.

الخطوة 4: إطلاق مثيل
اختر “Launch Instance” لبدء النشر الخاص بك. ستكون بيئة GPU عالية الأداء جاهزة في غضون دقائق، مما يسمح لك بالبدء فورًا في مشاريع التعلم الآلي أو العرض أو الحوسبة.
إذا كان عبء العمل الخاص بك يركز على الكفاءة والمرونة وحجم النشر، فإن L40S هو الاستثمار الأذكى. إذا كنت تبني LLMs كبيرة أو عناقيد HPC أو أنظمة AI حساسة لزمن الاستجابة وكانت لديك الميزانية المناسبة، فإن H100 تقدم أداءً رائدًا في الصناعة.
الأسئلة الشائعة
أي GPU أفضل لاستدلال الذكاء الاصطناعي؟
كلاهما يؤدي بشكل جيد، لكن L40S أكثر كفاءة وفعالية من حيث التكلفة بفضل دعم FP8 الأصلي وانخفاض استهلاك الطاقة. H100 تستحق العناء فقط إذا كنت بحاجة إلى إنتاجية فائقة أو أقل زمن استجابة على نطاق واسع.
هل يمكنني تدريب نماذج كبيرة على L40S؟
نعم—لتدريب النطاق المتوسط إلى الكبير، L40S خيار قوي مع أداء TF32 ممتاز. بالنسبة للنماذج الأساسية الضخمة أو عناقيد GPU المتعددة، H100 أفضل.
أي GPU لديه كفاءة طاقة أفضل؟
L40S. إن استهلاكها 300–350 واط وأداءها القوي لكل واط يجعلها خيارًا أفضل للنشر الحساس للطاقة. H100 (حتى 700 واط SXM5) تتطلب بنية تحتية كبيرة.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج AI باستخدام واجهة برمجة التطبيقات البسيطة لدينا، مع توفير سحابة GPU موثوقة وبأسعار معقولة لبناء وتوسيع النطاق.
قراءة موصى بها



