

主なハイライト
AI推論: 中規模デプロイにはL40S、ハイパースケール推論タスクには H100 を選択。
AIトレーニング: L40S は30Bパラメータまでのモデルに最適、H100 は70B以上のモデルトレーニングに必要。
グラフィックス&ビジュアライゼーション: L40S はRTコア搭載で明らかに優位、H100 はグラフィックスアクセラレーションを完全に欠く。
科学計算: 高精度FP64ワークロードには H100、L40S は基本的なシミュレーションを効率的に処理。

Novita AI

Runpod
Novita AIでのL40Sの使用コストは、RunPodの約半額です。
L40SとH100の選択は簡単ではありません。大規模AIトレーニングと科学的高精度を重視したH100の生のパワーを優先しますか?それとも推論、トレーニング、ビジュアライゼーションにおけるL40Sの汎用性と効率性を選びますか?
各GPUには独自の強みがありますが、どれが本当にあなたのニーズに適しているのでしょうか?以下の分析で詳細を分解し、決定を支援します。
NVIDIA L40SとH100はどちらも要求の厳しいワークロード向けに設計された強力なGPUですが、役割が異なります。L40SはAI推論、グラフィックスレンダリング、汎用コンピューティングに最適化された多用途で電力効率の高いGPUです。一方、H100は大規模AIトレーニングとHPC向けのNVIDIAのフラッグシップであり、比類のないテンソルおよび倍精度演算性能を提供します。
L40S vs H100:実際のAIワークロード
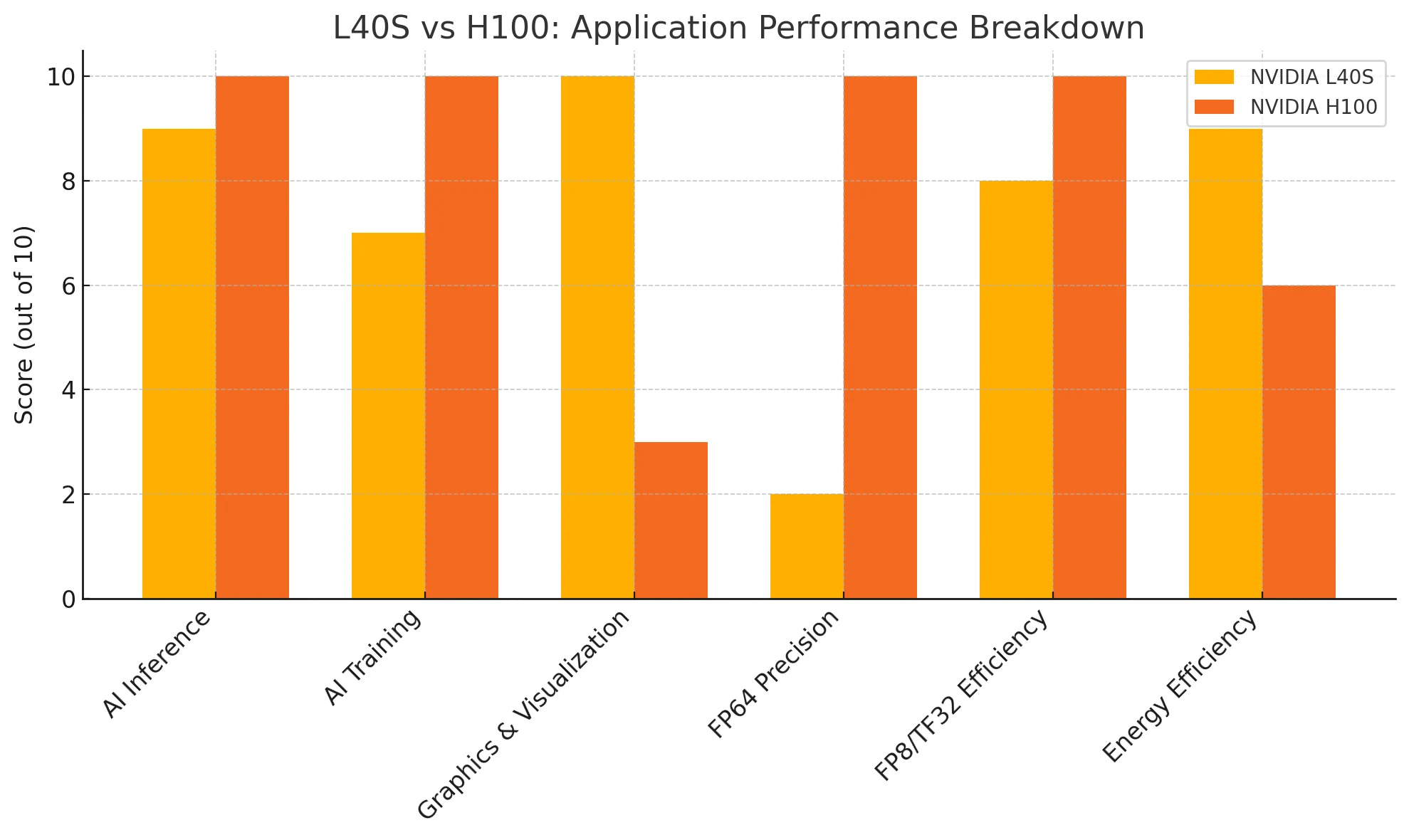
AI推論:
H100は生の推論性能でわずかに優れていますが、L40Sはより高いエネルギー効率で優れた結果を提供します。
AIトレーニング:
H100は超大規模モデルに対して比類のない性能を発揮します。L40Sはそれほど強力ではありませんが、中規模から大規模のトレーニングタスクでは非常にコスト効率が高いです。
グラフィックス&ビジュアライゼーション:
L40Sが明らかに勝利します。専用のRTコアと最適化されたドライバを備え、プロフェッショナルなレンダリングおよびビジュアライゼーションワークロードに適しています。
FP64精度:
H100は科学計算と高精度ワークロードに最適な選択肢です。L40Sは基本的なFP64タスクをサポートします。
FP8/TF32効率:
H100は高精度テンソルコンピューティングでリードしますが、L40SのFP8推論能力はほとんどのデプロイシナリオで十分です。
L40Sは、推論、グラフィックス、バランスの取れたトレーニングを求めるユーザーにとって、多用途で電力効率の高いGPUとして最適な選択です。H100は大規模AIトレーニングと高精度コンピューティングに優れていますが、その利点にはより高い電力とコストの要件が伴います。適切な選択は、特定のワークロードとスケーラビリティのニーズによって異なります。
開発者がL40SまたはH100を選ぶ理由
AI推論
| Metric | L40S | H100 |
|---|---|---|
| FP8 Tensor (Sparse) | 733|1466 PFLOPS | 3958|3341 |
| TDP | 300W–350W | 最大700W (SXM5) |
| MIG | なし | あり |
✅ 推奨:
- 非常に大規模なモデル(70Bパラメータ以上)に最高の単一ノード推論スループットが必要で、データセンターの予算と電力制限がGPUあたり700Wに対応できる場合は、H100 を選択。
- 電力、設備投資、またはスロット数に制約がある場合、またはMIGを使用して多数の中規模モデル(40B以下)をホストする予定がある場合は、L40S を選択。L40Sは最高の性能対コスト比と優れた性能対ワット数を提供し、FP8とMIGもサポート。
AIトレーニング
| Metric | L40S | H100 |
|---|---|---|
| TF32 Tensor (Sparse) | 183|366 | 989|835 |
| メモリ帯域幅 | 864 GB/s (GDDR6) | 最大3.9TB/s (NVL) |
| メモリ容量 | 48 GB | 80 |98GB |
✅ 推奨:
- H100 は、優れたメモリ帯域幅 ** とTransformer Engine** により、巨大モデル(例:70Bパラメータ超)のトレーニング に最適。
- L40S は、最新アーキテクチャと第4世代テンソルコアを備え、30B~40Bまでのモデル ** に強力。コスト重視のラボやスタートアップは、許容できる速度でFP8/TF32混合精度トレーニング** にL40Sを好むことが多い。
グラフィックス、ビジュアライゼーション、リアルタイムシミュレーション
| Metric | L40S | H100 |
|---|---|---|
| RT Cores | 142 (第3世代) | なし |
✅ 推奨:
- L40Sがデフォルトで勝利 。 専用RTコアによりリアルタイムレイトレーシングとプロフェッショナルグラフィックスワークロードをサポート。
- H100 にはRTコアがなく、レンダリング、シミュレーションエンジン、Omniverseベースのパイプラインには不向き。
科学計算/HPC
| Metric | L40S | H100 |
|---|---|---|
| FP64性能 | 1.4 TFLOPS | 26|34TFLOPS |
✅ 推奨:
- H100は必須 。量子力学、流体力学、材料科学などの 倍精度浮動小数点ワークロードに。
- L40S は基本的なFP64が可能だが、高精度が必須の場合は 使用すべきではない。
| Metric | NVIDIA L40S (PCIe) | NVIDIA H100 (SXM5) |
|---|---|---|
| アーキテクチャ | Ada Lovelace | Hopper |
| CUDA Cores | 18,176 | 16,896 |
| Tensor Cores | 568 (第4世代) | 528 (第4世代 + Transformer Engine) |
| RT Cores | 142 (第3世代) | 0 |
| FP32 Peak | 91.6 TFLOPS | 66.9 TFLOPS |
| TF32 Tensor (dense) | 366 TFLOPS | 989 TFLOPS |
| TF32 Tensor (sparse ×2) | 733 PFLOPS | 1.979 PFLOPS |
| FP8 Tensor (dense) | 1.466 PFLOPS | 3.958 PFLOPS |
| FP8 Tensor (sparse ×2) | 2.93 PFLOPS | 7.91 PFLOPS |
| FP64 Scalar | 1.43 TFLOPS | 34 TFLOPS |
| FP64 Tensor | — | 60 TFLOPS |
| メモリ帯域幅 | 864 TB/s (GDDR6) | 3.35 TB/s (HBM3) |
| TDP | 300 – 350 W | 700 W |
L40S vs H100:電力効率
| アプリケーションシナリオ | GPU | ハードウェアコスト (USD) | 月間電力コスト (USD) | 主な強み |
|---|---|---|---|---|
| AI推論 | L40S | $7,569 – $10,750 | ~$32.10 | L40SはH100の約80%の性能を提供 |
| H100 | $27,000 – $40,000 | ~$64.25 | ||
| AIトレーニング | L40S | $7,569 – $10,750 | ~$32.10 | 約30Bパラメータまでのモデルに効率的 |
| H100 | $27,000 – $40,000 | ~$64.25 | 70B以上のスケールモデルに必要 | |
| グラフィックス&ビジュアライゼーション | L40S | $7,569 – $10,750 | ~$32.10 | 142 RTコア、最適化Adaドライバ、Omniverse、Blender、3Dパイプラインに最適 |
| H100 | $27,000 – $40,000 | ~$64.25 | ❌ RTコアなし、レンダリング最適化なし | |
| 科学計算 (FP64) | L40S | $7,569 – $10,750 | ~$32.10 | 基本FP64 (1.4 TFLOPS) |
| H100 | $27,000 – $40,000 | ~$64.25 | 高精度ワークロードに優れたFP64性能 |
L40SとH100を格安で実行する方法
Novita AIは、高性能GPUインスタンスを備えたクラウドベースのプラットフォームを提供します。強力なGPUにより、複雑なタスクの効率的なパフォーマンスを保証し、さまざまなハードウェアへのデプロイのアクセス性を高め、大規模AIデプロイのためのローカルハードウェアの維持と比較してコスト効率の高いソリューションを提供します。
ステップ1:アカウント登録
ウェブサイトからNovita AIアカウントを作成します。登録後、左サイドバーの「Explore」セクションに移動して、当社のGPU製品を確認し、AI開発の旅を始めましょう。

ステップ2:テンプレートとGPUサーバーの探索
PyTorch、TensorFlow、CUDAなどのテンプレートからプロジェクトに合ったものを選択します。次に、希望するGPU構成を選択します。強力なL40S、RTX 4090、A100 SXM4などのオプションがあり、それぞれ異なるVRAM、RAM、ストレージ仕様があります。

ステップ3:デプロイのカスタマイズ
好みのオペレーティングシステムと構成オプションを選択して環境をカスタマイズし、特定のAIワークロードと開発ニーズに最適なパフォーマンスを確保します。

ステップ4:インスタンスの起動
「Launch Instance」を選択してデプロイを開始します。高性能GPU環境は数分で準備完了し、機械学習、レンダリング、計算プロジェクトをすぐに開始できます。
ワークロードが 効率性、柔軟性、デプロイ規模 を重視する場合、L40S がより賢い投資です。もし 大規模LLM、HPCクラスター、レイテンシ重視のAIシステム を構築しており、それに見合う予算があれば、H100 は業界をリードするパフォーマンスを提供します。
よくある質問
AI推論にはどのGPUが適していますか?
どちらも優れていますが、L40S はネイティブFP8サポートと低消費電力により、より効率的でコスト効果が高いです。H100は、超高スループットまたは大規模な最低レイテンシが必要な場合にのみ価値があります。
L40Sで大規模モデルをトレーニングできますか?
はい、中規模から大規模のトレーニングには、L40Sは優れたTF32性能を持つ堅実な選択です。大規模な基盤モデルやマルチGPUクラスターには、H100 の方が適しています。
どちらのGPUがエネルギー効率に優れていますか?
L40S。 その300〜350WのTDPと強力な性能対ワット数により、電力制約のあるデプロイに最適です。H100(最大700W SXM5)は重要なインフラを必要とします。
Novita AIは、シンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、同時に構築とスケーリングのための手頃で信頼性の高いGPUクラウドを提供します。
おすすめの記事



