

Points clés
Inférence IA : Utilisez L40S pour des déploiements à moyenne échelle ; choisissez H100 pour les tâches d’inférence à très grande échelle.
Entraînement IA : L40S est idéal pour les modèles jusqu’à 30 milliards de paramètres ; H100 est nécessaire pour l’entraînement de modèles de 70+ milliards de paramètres.
Graphiques et visualisation : L40S est le grand gagnant avec ses RT Cores ; H100 ne dispose d’aucune accélération graphique.
Calcul scientifique : Choisissez H100 pour les charges de travail FP64 de haute précision ; L40S gère efficacement les simulations de base.

Novita AI

Runpod
Le coût d’utilisation du L40S sur Novita AI est environ la moitié du prix de RunPod.
Choisir entre le L40S et le H100 n’est pas une tâche simple. Donnez-vous la priorité à la puissance brute du H100 pour l’entraînement IA à grande échelle et la précision scientifique, ou à la polyvalence et l’efficacité du L40S pour l’inférence, l’entraînement et la visualisation ?
Chaque GPU a ses propres atouts, mais lequel correspond vraiment à vos besoins ? Dans l’analyse suivante, nous détaillerons tout pour vous aider à décider.
Le NVIDIA L40S et le H100 sont tous deux des GPU puissants conçus pour des charges de travail exigeantes, mais ils jouent des rôles différents. Le L40S est un GPU polyvalent et économe en énergie, optimisé pour l’inférence IA, le rendu graphique et le calcul généraliste. Le H100, quant à lui, est le fleuron de NVIDIA pour l’entraînement IA à grande échelle et le HPC, offrant des performances inégalées en calcul tensoriel et en double précision.
L40S vs H100 : Charges de travail IA réelles
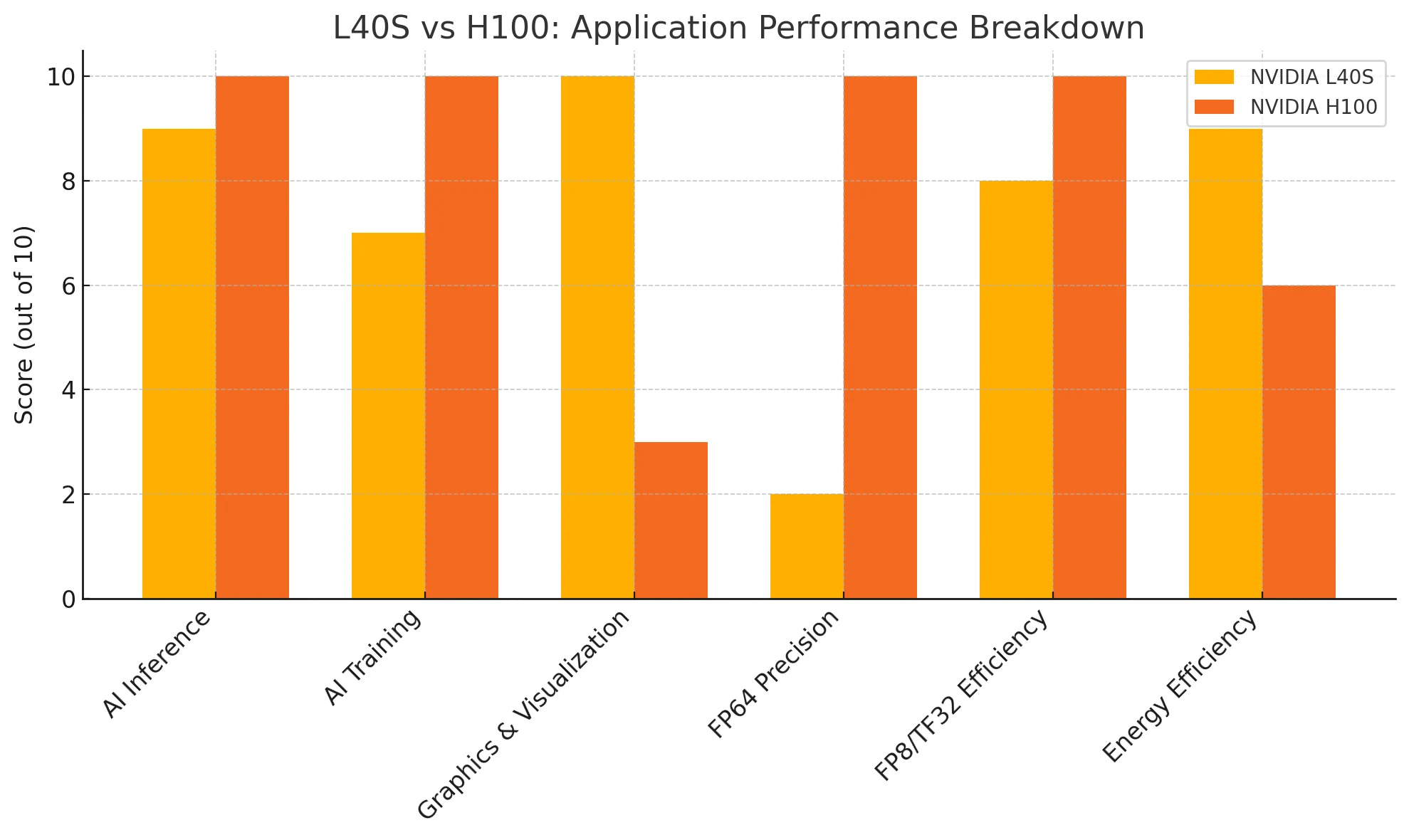
Inférence IA :
Le H100 a un léger avantage en termes de performances brutes d’inférence, mais le L40S offre d’excellents résultats avec une meilleure efficacité énergétique.
Entraînement IA :
Le H100 offre des performances inégalées pour les modèles ultra-larges. Le L40S, bien que moins puissant, est très rentable pour les tâches d’entraînement de taille moyenne à grande.
Graphiques et visualisation :
Le L40S gagne clairement, avec des RT Cores dédiés et des pilotes optimisés pour les charges de travail professionnelles de rendu et de visualisation.
Précision FP64 :
Le H100 est l’option privilégiée pour le calcul scientifique et les charges de travail de haute précision. Le L40S prend en charge les tâches FP64 de base.
Efficacité FP8/TF32 :
Le H100 domine dans le calcul tensoriel de haute précision, mais les capacités d’inférence FP8 du L40S sont plus que suffisantes pour la plupart des scénarios de déploiement.
Le L40S est le meilleur choix pour les utilisateurs recherchant un GPU polyvalent et économe en énergie pour l’inférence, les graphiques et un entraînement équilibré. Le H100 excelle dans l’entraînement IA à grande échelle et le calcul de haute précision, mais ses avantages s’accompagnent de besoins plus élevés en puissance et en coût. Le bon choix dépend de votre charge de travail spécifique et de vos besoins d’évolutivité.
Pourquoi les développeurs choisissent le L40S ou le H100 ?
Inférence IA
| Mesure | L40S | H100 |
|---|---|---|
| FP8 Tensor (Sparse) | 733|1466 PFLOPS | 3958|3341 |
| TDP | 300W–350W | Jusqu’à 700W (SXM5) |
| MIG | Non | Oui |
✅ Recommandation :
- Choisissez H100 si vous avez besoin du débit d’inférence monocœur le plus élevé pour des modèles très volumineux (≥ 70 milliards de paramètres) et que votre budget centre de données et votre enveloppe énergétique peuvent supporter 700 W par GPU.
- Choisissez L40S lorsque la puissance, le budget d’investissement ou le nombre d’emplacements est limité, ou lorsque vous prévoyez d’héberger de nombreux modèles de taille moyenne (≤ 40 milliards) avec MIG. Il offre le meilleur rapport performance/prix et une bonne performance par watt, tout en supportant FP8 et MIG.
Entraînement IA
| Mesure | L40S | H100 |
|---|---|---|
| TF32 Tensor (Sparse) | 183|366 | 989|835 |
| Bande passante mémoire | 864 Go/s (GDDR6) | Jusqu’à 3,9 To/s (NVL) |
| Capacité mémoire | 48 Go | 80 | 98 Go |
✅ Recommandation :
- H100 est la référence pour l’entraînement de modèles massifs (par ex., >70 milliards de paramètres) grâce à sa bande passante mémoire supérieure et à son Transformer Engine.
- L40S est un bon choix pour les modèles jusqu’à 30–40 milliards de paramètres, avec une architecture moderne et des Tensor Cores de 4e génération.
Les laboratoires et start-ups sensibles aux coûts privilégient souvent le L40S pour l’entraînement en précision mixte FP8/TF32 à une vitesse acceptable.
Graphiques, visualisation et simulation en temps réel
| Mesure | L40S | H100 |
|---|---|---|
| RT Cores | 142 (3e génération) | Aucun |
✅ Recommandation :
- L40S gagne par défaut. Avec des RT Cores dédiés, il prend en charge le ray tracing en temps réel et les charges de travail graphiques professionnelles.
- H100 n’a pas de RT Cores et ne convient pas pour le rendu, les moteurs de simulation ou les pipelines basés sur Omniverse.
Calcul scientifique / HPC
| Mesure | L40S | H100 |
|---|---|---|
| Performance FP64 | 1,4 TFLOPS | 26|34 TFLOPS |
✅ Recommandation :
- H100 est essentiel pour les charges de travail en virgule flottante double précision, comme la mécanique quantique, la dynamique des fluides ou la science des matériaux.
- L40S, bien que capable de FP64 de base, ne doit pas être utilisé là où une haute précision est obligatoire.
| Mesure | NVIDIA L40S (PCIe) | NVIDIA H100 (SXM5) |
|---|---|---|
| Architecture | Ada Lovelace | Hopper |
| CUDA Cores | 18 176 | 16 896 |
| Tensor Cores | 568 (4e génération) | 528 (4e génération + Transformer Engine) |
| RT Cores | 142 (3e génération) | 0 |
| FP32 Pic | 91,6 TFLOPS | 66,9 TFLOPS |
| TF32 Tensor (dense) | 366 TFLOPS | 989 TFLOPS |
| TF32 Tensor (sparse ×2) | 733 PFLOPS | 1,979 PFLOPS |
| FP8 Tensor (dense) | 1,466 PFLOPS | 3,958 PFLOPS |
| FP8 Tensor (sparse ×2) | 2,93 PFLOPS | 7,91 PFLOPS |
| FP64 Scalaire | 1,43 TFLOPS | 34 TFLOPS |
| FP64 Tensor | — | 60 TFLOPS |
| Bande passante mémoire | 864 To/s (GDDR6) | 3,35 To/s (HBM3) |
| TDP | 300 – 350 W | 700 W |
L40S vs H100 : Efficacité énergétique
| Scénario d’application | GPU | Coût matériel (USD) | Coût électrique mensuel (USD) | Points forts |
|---|---|---|---|---|
| Inférence IA | L40S | 7 569 $ – 10 750 $ | ~32,10 $ | Le L40S offre environ 80 % des performances du H100 |
| H100 | 27 000 $ – 40 000 $ | ~64,25 $ | ||
| Entraînement IA | L40S | 7 569 $ – 10 750 $ | ~32,10 $ | Efficace pour les modèles jusqu’à ~30 milliards de paramètres |
| H100 | 27 000 $ – 40 000 $ | ~64,25 $ | Nécessaire pour les modèles de 70+ milliards | |
| Graphiques et visualisation | L40S | 7 569 $ – 10 750 $ | ~32,10 $ | 142 RT Cores, pilotes Ada optimisés ; idéal pour Omniverse, Blender, pipelines 3D |
| H100 | 27 000 $ – 40 000 $ | ~64,25 $ | ❌ Pas de RT Cores, pas d’optimisation de rendu | |
| Calcul scientifique (FP64) | L40S | 7 569 $ – 10 750 $ | ~32,10 $ | FP64 de base (1,4 TFLOPS) |
| H100 | 27 000 $ – 40 000 $ | ~64,25 $ | Performance FP64 supérieure pour les charges de travail de haute précision |
Comment exécuter L40S et H100 à très bas prix ?
Novita AI propose une plateforme cloud avec des instances GPU haute performance. Grâce à des GPU puissants, elle garantit des performances efficaces pour les tâches complexes, améliore l’accessibilité pour le déploiement sur divers matériels et offre une solution rentable par rapport au maintien d’un matériel local pour les déploiements IA à grande échelle.
Étape 1 : Créez un compte
Créez votre compte Novita AI via notre site Web. Après l’inscription, naviguez vers la section “Explorer” dans la barre latérale gauche pour voir nos offres GPU et commencer votre parcours de développement IA.

Étape 2 : Explorez les modèles et les serveurs GPU
Choisissez parmi des modèles comme PyTorch, TensorFlow ou CUDA qui correspondent aux besoins de votre projet. Sélectionnez ensuite la configuration GPU de votre choix — les options incluent le puissant L40S, RTX 4090 ou A100 SXM4, chacun avec des spécifications différentes de VRAM, RAM et stockage.

Étape 3 : Personnalisez votre déploiement
Personnalisez votre environnement en sélectionnant votre système d’exploitation et vos options de configuration préférés pour garantir des performances optimales pour vos charges de travail IA spécifiques et vos besoins de développement.

Étape 4 : Lancez une instance
Sélectionnez “Lancer l’instance” pour démarrer votre déploiement. Votre environnement GPU haute performance sera prêt en quelques minutes, vous permettant de commencer immédiatement vos projets d’apprentissage automatique, de rendu ou de calcul.
Si votre charge de travail met l’accent sur l’efficacité, la flexibilité et l’échelle de déploiement, le L40S est l’investissement le plus judicieux. Si vous construisez de grands LLM, des clusters HPC ou des systèmes IA critiques en latence et que vous avez le budget correspondant, le H100 offre des performances de pointe dans le secteur.
Foire aux questions
Quel GPU est le meilleur pour l’inférence IA ?
Les deux fonctionnent bien, mais L40S est plus efficace et rentable grâce au support natif FP8 et à une consommation électrique plus faible. Le H100 ne vaut la peine que si vous avez besoin d’un débit ultra-élevé ou d’une latence minimale à grande échelle.
Puis-je entraîner de grands modèles sur L40S ?
Oui – pour un entraînement de taille moyenne à grande, le L40S est un choix solide avec d’excellentes performances TF32. Pour des modèles de base massifs ou des clusters multi-GPU, H100 est meilleur.
Quel GPU a la meilleure efficacité énergétique ?
L40S. Son TDP de 300–350W et ses bonnes performances par watt en font une meilleure option pour les déploiements sensibles à la consommation électrique. Le H100 (jusqu’à 700W SXM5) nécessite une infrastructure importante.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.
Lecture recommandée



