

关键亮点
AI 推理: 中型部署使用 L40S;超大规模推理任务选择 H100。
AI 训练: L40S 适用于参数不超过 30B 的模型;H100 是训练 70B+ 参数模型的必备之选。
图形与可视化: L40S 凭借 RT 核心明显胜出;H100 完全缺乏图形加速能力。
科学计算: 高精度 FP64 工作负载选择 H100;L40S 可高效处理基础仿真任务。

Novita AI

Runpod
在 Novita AI 上使用 L40S 的成本大约是 RunPod 的一半。
在 L40S 和 H100 之间做出选择并非易事。您更看重 H100 在大规模 AI 训练和科学计算精度方面的原始算力,还是 L40S 在推理、训练和可视化方面的多功能性与效率?
每一款 GPU 都有其独特优势——但哪一款才是您真正需要的?在下面的分析中,我们将详细拆解,帮助您做出决定。
NVIDIA L40S 和 H100 都是为高负载工作设计的强大 GPU,但它们的定位有所不同。L40S 是一款功能全面、能效优越的 GPU,专为 AI 推理、图形渲染和通用计算优化。而 H100 则是 NVIDIA 面向大规模 AI 训练和高性能计算(HPC)的旗舰产品,在张量计算和双精度计算性能上无与伦比。
L40S vs H100:真实 AI 工作负载
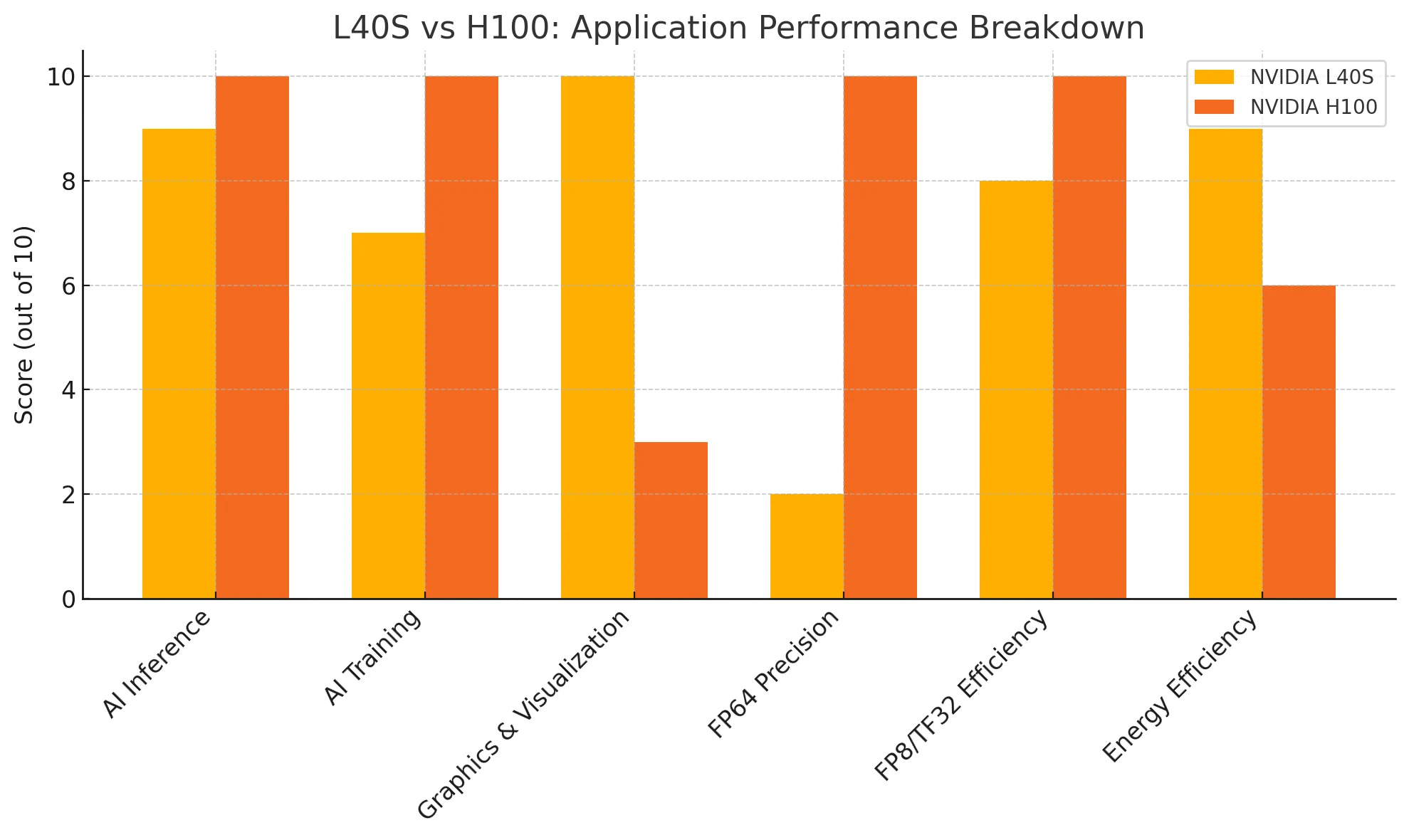
AI 推理:
H100 在原始推理性能上略占优势,但 L40S 以更高的能效仍能提供出色的结果。
AI 训练:
H100 在超大规模模型训练中表现无与伦比。L40S 虽性能不及,但对于中大型训练任务而言极具成本效益。
图形与可视化:
L40S 明显胜出,它具备专用 RT 核心以及针对专业渲染和可视化工作负载优化的驱动。
FP64 精度:
H100 是科学计算和高精度工作负载的首选。L40S 支持基本的 FP64 任务。
FP8/TF32 效率:
H100 在高精度张量计算上领先,但 L40S 的 FP8 推理能力已足以满足大多数部署场景。
L40S 是寻求全能型、高能效 GPU 进行推理、图形和均衡训练用户的最佳选择。H100 在大规模 AI 训练和高精度计算方面表现出色,但其优势伴随更高的功耗和成本需求。正确的选择取决于您的具体工作负载和扩展需求。
为什么开发者选择 L40S 或 H100?
AI 推理
| 指标 | L40S | H100 |
|---|---|---|
| FP8 张量(稀疏) | 733|1466 PFLOPS | 3958|3341 PFLOPS |
| TDP | 300W–350W | 最高 700W(SXM5) |
| MIG | 不支持 | 支持 |
✅ 建议:
- 如果您需要为超大型模型(≥ 70B 参数)提供最高的单节点推理吞吐量,且您的数据中心预算和功耗能够承受每 GPU 700W,则选择 H100。
- 当功耗、资本支出或插槽数量受限,或您计划托管多个中等规模模型(≤ 40B)且需要 MIG 时,选择 L40S。它在每美元性能和每瓦性能方面表现最佳,同时仍支持 FP8 和 MIG。
AI 训练
| 指标 | L40S | H100 |
|---|---|---|
| TF32 张量(稀疏) | 183|366 TFLOPS | 989|835 TFLOPS |
| 内存带宽 | 864 GB/s(GDDR6) | 最高 3.9TB/s(NVL) |
| 内存容量 | 48 GB | 80 | 98GB |
✅ 建议:
- H100 是 ** 训练大规模模型 **(例如 >70B 参数)的首选,得益于其 ** 卓越的内存带宽 ** 和 Transformer Engine。
- L40S 非常适用于 30B–40B 规模模型,拥有现代架构和第 4 代张量核心。
成本敏感的实验室和初创企业通常倾向于将 L40S 用于 FP8/TF32 混合精度训练,速度尚可接受。
图形、可视化与实时仿真
| 指标 | L40S | H100 |
|---|---|---|
| RT 核心 | 142(第 3 代) | 无 |
✅ 建议:
- **L40S 默认胜出 。凭借 ** 专用 RT 核心,它支持实时光线追踪和专业图形工作负载。
- H100 没有 RT 核心,不适用于渲染、仿真引擎或基于 Omniverse 的管线。
科学计算 / HPC
| 指标 | L40S | H100 |
|---|---|---|
| FP64 性能 | 1.4 TFLOPS | 26|34 TFLOPS |
✅ 建议:
- **H100 是必备 ,用于 ** 双精度浮点工作负载,如量子力学、流体动力学或材料科学。
- L40S 虽然能满足基本的 FP64 需求,但在要求高精度的场合 ** 不应使用**。
| **指标 ** | NVIDIA L40S(PCIe) | NVIDIA H100(SXM5) |
|---|---|---|
| 架构 | Ada Lovelace | Hopper |
| CUDA 核心 | 18,176 | 16,896 |
| 张量核心 | 568(第 4 代) | 528(第 4 代 + Transformer Engine) |
| RT 核心 | 142(第 3 代) | 0 |
| FP32 峰值 | 91.6 TFLOPS | 66.9 TFLOPS |
| TF32 张量(密集) | 366 TFLOPS | 989 TFLOPS |
| TF32 张量(稀疏 ×2) | 733 PFLOPS | 1.979 PFLOPS |
| FP8 张量(密集) | 1.466 PFLOPS | 3.958 PFLOPS |
| FP8 张量(稀疏 ×2) | 2.93 PFLOPS | 7.91 PFLOPS |
| FP64 标量 | 1.43 TFLOPS | 34 TFLOPS |
| FP64 张量 | — | 60 TFLOPS |
| 内存带宽 | 864 TB/s(GDDR6) | 3.35 TB/s(HBM3) |
| TDP | 300 – 350 W | 700 W |
L40S vs H100:能效对比
| 应用场景 | GPU | 硬件成本(美元) | 月度电费(美元) | 核心优势 |
|---|---|---|---|---|
| AI 推理 | L40S | $7,569 – $10,750 | ~$32.10 | L40S 性能约为 H100 的 80% |
| H100 | $27,000 – $40,000 | ~$64.25 | ||
| AI 训练 | L40S | $7,569 – $10,750 | ~$32.10 | 适用于约 30B 参数模型 |
| H100 | $27,000 – $40,000 | ~$64.25 | 70B+ 规模模型所需 | |
| 图形与可视化 | L40S | $7,569 – $10,750 | ~$32.10 | 142 个 RT 核心,优化的 Ada 驱动;适合 Omniverse、Blender、3D 管线 |
| H100 | $27,000 – $40,000 | ~$64.25 | ❌ 无 RT 核心,无渲染优化 | |
| 科学计算(FP64) | L40S | $7,569 – $10,750 | ~$32.10 | 基础 FP64(1.4 TFLOPS) |
| H100 | $27,000 – $40,000 | ~$64.25 | 适用于高精度工作负载的卓越 FP64 性能 |
如何以极低价格运行 L40S 和 H100?
Novita AI 提供一个基于云的平台,配备高性能 GPU 实例。凭借强大的 GPU,它能确保复杂任务的高效性能,增强跨多种硬件部署的可访问性,并相较于维护本地硬件用于大规模 AI 部署提供更具成本效益的解决方案。
步骤 1:注册账户
通过我们的网站创建您的 Novita AI 账户。注册后,导航至左侧边栏中的“探索”区域,查看我们的 GPU 产品,并开始您的 AI 开发之旅。

步骤 2:浏览模板和 GPU 服务器
从 PyTorch、TensorFlow 或 CUDA 等模板中选择与您的项目需求匹配的模板。然后选择您首选的 GPU 配置——选项包括强大的 L40S、RTX 4090 或 A100 SXM4,每一种都提供不同的显存、内存和存储规格。

步骤 3:定制部署
通过选择操作系统和配置选项来定制您的环境,以确保针对您的特定 AI 工作负载和开发需求获得最佳性能。

步骤 4:启动实例
选择“启动实例”开始部署。您的高性能 GPU 环境将在几分钟内准备就绪,您可以立即开始机器学习、渲染或计算项目。
如果您的负载更看重 **效率、灵活性和部署规模 **,那么 L40S 是更明智的投资。如果您正在构建 ** 大型 LLM、HPC 集群或对延迟敏感的 AI 系统 **,并且预算充裕,那么 H100 能够提供行业领先的性能。
常见问题
哪一款 GPU 更适合 AI 推理?
两者表现都不错,但 L40S 凭借原生 FP8 支持和更低功耗,在效率与成本效益方面更胜一筹。H100 仅在需要超高吞吐量或最低延迟的大规模场景下才值得考虑。
能否在 L40S 上训练大型模型?
可以——对于中大型训练任务,L40S 凭借其出色的 TF32 性能是一个可靠的选择。但对于大规模的基础模型或多 GPU 集群,H100 更优。
哪一款 GPU 能效更高?
L40S。 其 300–350W TDP 和较高的性能功耗比使其成为功耗敏感部署的更好选择。H100(SXM5 最高 700W)需要更强大的基础设施支持。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云服务用于构建和扩展。
推荐阅读



