

- Einleitung
- Enthüllung von Mixtral-8x22B: Eine neue Ära der Large Language Models
- Tiefer Einblick in die Architektur von Mixtral-8x22B
- Leistung und Fähigkeiten von Mixtral
- Betriebseffizienz von Mixtral-8x22B
- Benutzerleitfaden: Implementierung von Mixtral-8x22B
- Best Practices für die Integration von Mixtral-8x22B
- Zweige der Mixtral-Modellfamilie
- Fazit
- Häufig gestellte Fragen
Erkunden Sie Mixtral-8x22B und andere Zweige der Mixtral-Modellfamilie in unserem Blog.
Einleitung
In der Welt der NLP sind große Sprachmodelle zum Eckpfeiler für verschiedene Aufgaben der natürlichen Sprachverarbeitung geworden. Diese Modelle wurden entwickelt, um menschenähnlichen Text zu verstehen und zu generieren, was sie zu wertvollen Werkzeugen für Anwendungen wie Chatbots, Übersetzungssysteme und Codegenerierung macht. Mistral AI, ein führendes KI-Forschungslabor, hat kürzlich Mixtral-8x22B vorgestellt, das neueste und größte Mixture-of-Experts Large Language Model (LLM), das die Grenzen von Open-Source-Modellen erweitert.
Mixtral-8x22B ist ein Sparse Mixture of Experts (SMoE)-Sprachmodell, das im Vergleich zu anderen LLMs eine überlegene Leistung und Kosteneffizienz bietet. Es übertrifft Llama 2 70B mit 6x schnellerer Inferenz und erreicht oder übertrifft GPT-3.5 in verschiedenen Benchmarks. Dieses Modell ist unter der Apache 2.0-Lizenz lizenziert, sodass es für Entwickler und Forscher in ihren Projekten nutzbar ist.
Mit insgesamt 47 Milliarden Parametern ist Mixtral-8x22B ein leistungsstarkes Sprachmodell, das komplexe Aufgaben wie mathematisches Denken, Codegenerierung und mehrsprachiges Verständnis bewältigen kann. Es unterstützt Sprachen wie Englisch, Französisch, Italienisch, Deutsch und Spanisch, was es zu einem vielseitigen Werkzeug für globale Anwendungen macht. Darüber hinaus kann Mixtral-8x22B einen Kontextfenster von 32.000 Token verarbeiten, sodass es mit seiner fortschrittlichen GPU-Technologie Text mit langen und komplexen Prompts verarbeiten und generieren kann.
Enthüllung von Mixtral-8x22B: Eine neue Ära der Large Language Models
Mixtral-8x22B repräsentiert einen neuen Standard im Bereich der Large Language Models. Mit seiner modernen Architektur und beeindruckenden Leistung setzt es einen neuen Maßstab für die Fähigkeiten und Effizienz von Sprachmodellen.
Entwickelt von Mistral AI, bietet Mixtral-8x22B einen neuen Ansatz für die Sprachmodellierung unter Verwendung der Sparse Mixture of Experts (SMoE)-Technik. Diese innovative Architektur ermöglicht eine bessere Kontrolle von Kosten und Latenz, während sie dennoch außergewöhnliche Ergebnisse liefert. Mixtral-8x22B wurde im Dezember 2023 veröffentlicht und ist die neueste und größte Ergänzung der Mixtral-Modellfamilie. Es führt das Konzept der Mixtral of Experts ein und bringt eine Reihe von Verbesserungen mit sich, die seine Leistung und Fähigkeiten weiter steigern.
Die Entstehung von Mixtral-8x22B
Die Entwicklung von Mixtral-8x22B ist das Ergebnis umfangreicher Forschung und Zusammenarbeit innerhalb der KI-Community. Mistral AI hat zusammen mit einem Team talentierter Forscher und Ingenieure, darunter William El Sayed, eine Reise unternommen, um ein Sprachmodell zu schaffen, das die Grenzen des Möglichen im Bereich der natürlichen Sprachverarbeitung erweitert.
Die Entstehung von Mixtral-8x22B umfasste die Erforschung neuer Architekturen und Techniken sowie die Analyse großer Datensätze, um das Modell zu trainieren. Die KI-Community spielte in diesem Prozess eine entscheidende Rolle, denn Forscher und Entwickler trugen mit ihrem Fachwissen und Wissen zur Verfeinerung und Verbesserung des Modells bei. Das Ergebnis ist ein hochmodernes Sprachmodell, das den Höhepunkt jahrelanger Forschung und Entwicklung darstellt. Mixtral-8x22B ist ein Beweis für die Kraft von Zusammenarbeit und Innovation im Bereich der KI.
Kernkomponenten von Mixtral-8x22B
Das Mixtral-8x22B-Modell besteht aus mehreren Kernkomponenten, die zusammenarbeiten, um seine außergewöhnliche Leistung zu erzielen. Dazu gehören:
- Mixtral-Modell: Mixtral-8x22B ist ein Sparse Mixture of Experts (SMoE)-Modell, was bedeutet, dass es eine Kombination verschiedener Expert-Netzwerke verwendet, um Text zu verarbeiten und zu generieren.
- Router-Netzwerk: Auf jeder Ebene des Mixtral-Modells wählt ein Router-Netzwerk zwei Experten aus einer Reihe unterschiedlicher Parametergruppen aus, um jedes Token zu verarbeiten.
- Aktive Parameter: Obwohl Mixtral-8x22B insgesamt 47 Milliarden Parameter hat, werden während der Inferenz nur 13 Milliarden Parameter pro Token verwendet, was zu einer besseren Kosten- und Latenzkontrolle führt.
- Additive Kombination: Die von den Expert-Netzwerken erzeugten Ausgaben werden additiv kombiniert, was zu einer gewichteten Summe führt, die die Ausgabe des gesamten Mixture-of-Experts-Moduls darstellt.
Diese Kernkomponenten ermöglichen es Mixtral-8x22B, Text effektiv zu verarbeiten und zu generieren und den Benutzern genaue und qualitativ hochwertige Ergebnisse zu liefern. Die Architektur von Mixtral-8x22B ist darauf ausgelegt, sowohl Leistung als auch Effizienz zu optimieren, was es zu einem leistungsstarken Werkzeug für eine breite Palette von Sprachverarbeitungsaufgaben macht.
Tiefer Einblick in die Architektur von Mixtral-8x22B
Die Architektur von Mixtral-8x22B basiert auf dem Konzept eines Mixture of Experts, insbesondere eines Sparse Mixture-of-Experts (SMoE)-Modells. Dieses Decoder-Only-Modell verwendet ein Router-Netzwerk, um aus jeder der 8 verschiedenen Parametergruppen zwei Experten auszuwählen, die jedes Token verarbeiten. Die Ausgaben der ausgewählten Experten werden dann additiv kombiniert, um die endgültige Ausgabe zu erzeugen. Diese Architektur ermöglicht es Mixtral-8x22B, die Grenzen offener Modelle zu erweitern und eine hochmoderne Leistung und Genauigkeit zu erreichen.
Verständnis von Mixture of Experts (MoE)
Ein Mixture of Experts (MoE) ist eine Modellierungstechnik, die die Ausgaben mehrerer Expert-Netzwerke kombiniert, um Text zu generieren. Im Kontext von Mixtral-8x22B wird die MoE-Architektur genutzt, um die Stärken und das Fachwissen verschiedener Netzwerke zu nutzen, um genauen und qualitativ hochwertigen Text zu verarbeiten und zu generieren. Das Router-Netzwerk spielt in dieser Architektur eine entscheidende Rolle, indem es zwei Experten aus jedem Parametersatz auswählt, um jedes Token zu verarbeiten.
Diese Auswahl basiert auf der Präferenzoptimierung des Routers, die die am besten geeigneten Experten für jedes Token bestimmt. Durch die additive Kombination der Ausgaben der ausgewählten Experten ist Mixtral-8x22B in der Lage, Text zu generieren, der das kollektive Wissen und Fachwissen der Expert-Netzwerke widerspiegelt, was zu überlegener Leistung und Genauigkeit führt.
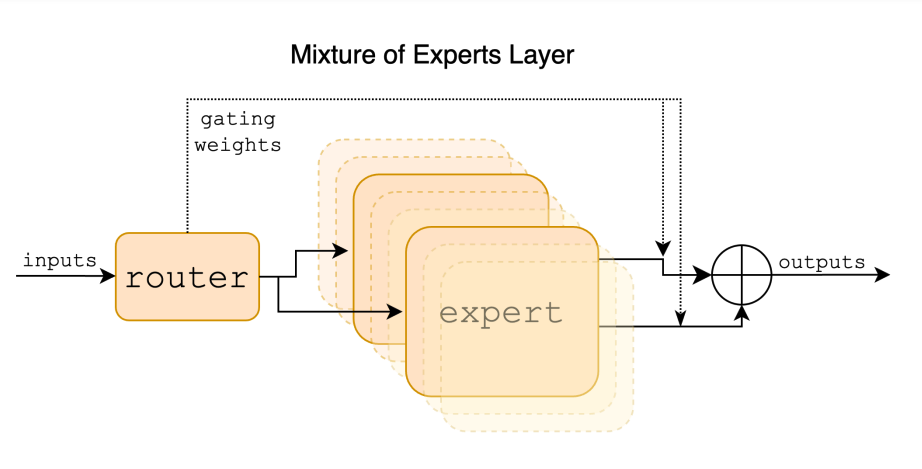
Die Rolle der 22b-Modelle in Mixtral-8x22B
Die 22b-Modelle spielen eine entscheidende Rolle für die Leistung von Mixtral-8x22B. Diese Modelle sind dafür verantwortlich, das Fachwissen und Wissen bereitzustellen, das erforderlich ist, um genauen und qualitativ hochwertigen Text zu generieren. Durch die Nutzung der Stärken und Fähigkeiten der 22b-Modelle ist Mixtral-8x22B in der Lage, in einer Vielzahl von Sprachverarbeitungsaufgaben überlegene Leistungen zu erbringen.
Die 22b-Modelle tragen zur Gesamtleistung von Mixtral-8x22B bei, indem sie spezialisiertes Wissen und Fachwissen in bestimmten Bereichen wie Codegenerierung, mathematischem Denken und mehrsprachigem Verständnis bereitstellen. Diese Kombination von Fachwissen ermöglicht es Mixtral-8x22B, genauen und kontextuell relevanten Text zu liefern, was es zu einem leistungsstarken Werkzeug für Entwickler und Forscher im Bereich der natürlichen Sprachverarbeitung macht.
Leistung und Fähigkeiten von Mixtral
Mixtral-8x22B zeigt eine starke Leistung in einer Vielzahl von Benchmarks und Sprachverarbeitungsaufgaben. Es übertrifft Llama 2 70B in mehreren Benchmarks, einschließlich des Bias Benchmark for QA (BBQ), und erreicht oder übertrifft GPT-3.5, ein weithin anerkanntes Large Language Model. Die Leistung des Modells ist besonders bemerkenswert in Bereichen wie mathematischem Denken, Codegenerierung und mehrsprachigem Verständnis. Es wurde auf einer riesigen Menge offener Webdaten trainiert und hat außergewöhnliche Leistung bei der Bewältigung komplexer Aufgaben gezeigt. Mit seiner beeindruckenden Leistung und vielseitigen Fähigkeiten wird Mixtral-8x22B, unterstützt durch die PyTorch-Bibliothek, zur ersten Wahl für Entwickler und Forscher im Bereich der natürlichen Sprachverarbeitung.
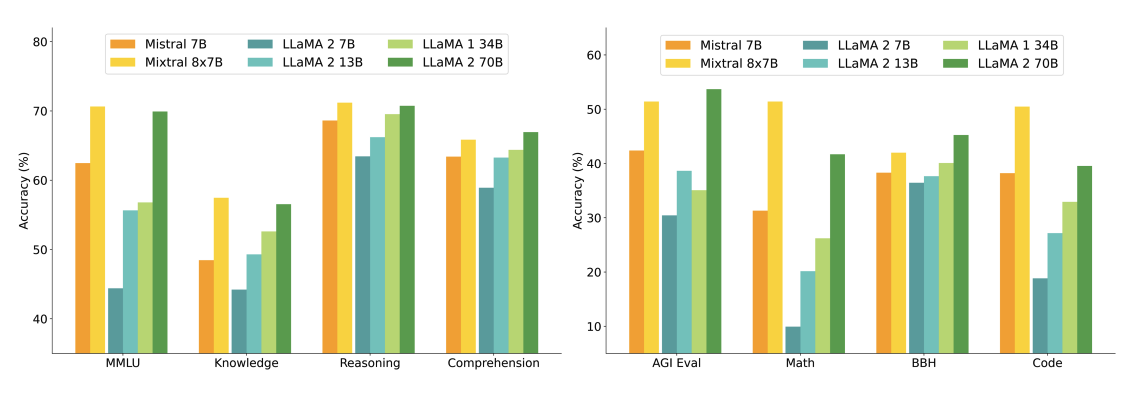
Die folgende Grafik zeigt die Leistung im Vergleich zu verschiedenen Größen von Llama 2-Modellen in einem breiteren Spektrum von Fähigkeiten und Benchmarks. Mixtral erreicht oder übertrifft Llama 2 70B und zeigt eine überlegene Leistung in Mathematik und Codegenerierung.
Wie in der folgenden Abbildung zu sehen, übertrifft Mixtral 8x7B auch oder erreicht die Leistung der Llama 2-Modelle in verschiedenen gängigen Benchmarks wie MMLU und GSM8K. Diese Ergebnisse werden erzielt, während während der Inferenz 5x weniger aktive Parameter verwendet werden.
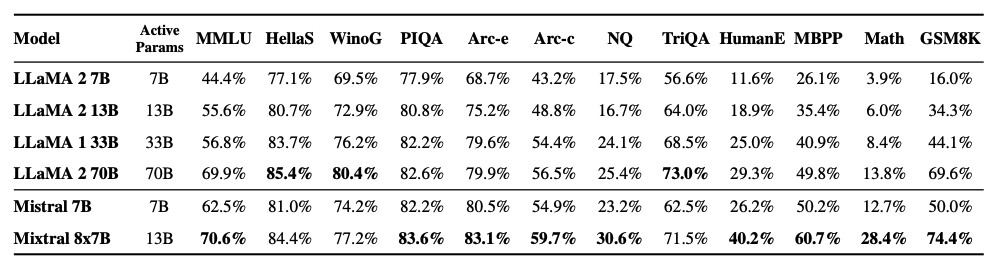
Die folgende Abbildung zeigt den Trade-off zwischen Qualität und Inferenzbudget. Mixtral übertrifft Llama 2 70B in mehreren Benchmarks, während es 5x weniger aktive Parameter verwendet.
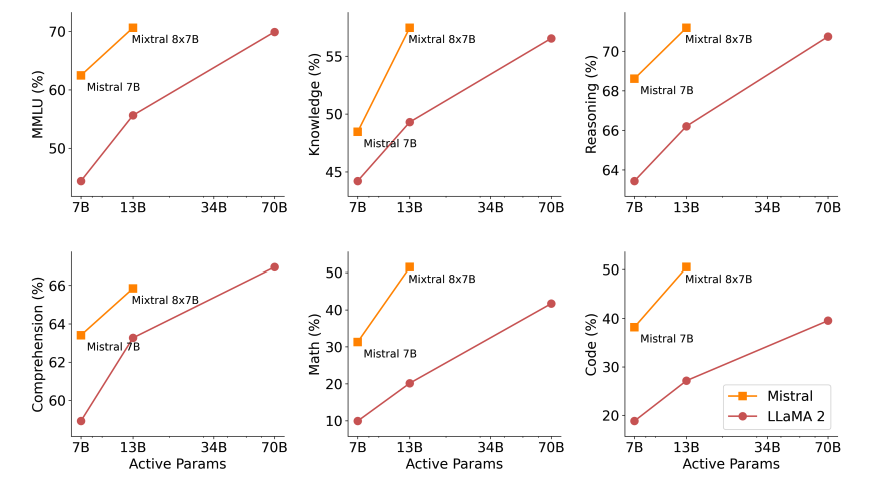
Benchmarking von Mixtral-8x22B im Vergleich zu anderen LLMs
Mixtral-8x22B wurde mit mehreren anderen Large Language Models (LLMs) verglichen, um seine Leistung und Fähigkeiten zu bewerten. Die Ergebnisse dieser Benchmarks zeigen die überlegene Leistung von Mixtral-8x22B in verschiedenen Sprachverarbeitungsaufgaben. Hier ist ein Vergleich von Mixtral-8x22B mit anderen LLMs in verschiedenen Standard-Benchmarks:

Diese Benchmark-Ergebnisse heben deutlich die starke Leistung von Mixtral-8x22B im Vergleich zu anderen LLMs hervor. Seine Fähigkeit, komplexe Aufgaben zu bewältigen und genaue Ergebnisse zu liefern, hebt es als führende Wahl für Entwickler und Forscher im Bereich der natürlichen Sprachverarbeitung hervor.
Praxisnahe Anwendungen und Fallstudien
Mixtral-8x22B hat zahlreiche praxisnahe Anwendungen in verschiedenen Branchen und Bereichen. Seine Vielseitigkeit und leistungsstarken Fähigkeiten machen es zu einem wertvollen Werkzeug für eine breite Palette von Anwendungsfällen. Einige Beispiele für reale Anwendungen von Mixtral-8x22B sind:
- Chatbots: Mixtral-8x22B kann zur Entwicklung von Chatbots verwendet werden, die menschenähnliche Gespräche effektiv verstehen und darauf reagieren können, was nahtlosen Kundensupport und -hilfe bietet.
- Übersetzungssysteme: Mit seinen mehrsprachigen Verständnisfähigkeiten kann Mixtral-8x22B genutzt werden, um Übersetzungssysteme zu bauen, die Text genau zwischen verschiedenen Sprachen übersetzen.
- Codegenerierung: Die starken Codegenerierungsfähigkeiten von Mixtral-8x22B machen es zu einer idealen Wahl für die Entwicklung von Systemen, die automatisch Code-Snippets basierend auf Benutzeranforderungen generieren können.
Dies sind nur einige Beispiele dafür, wie Mixtral-8x22B in realen Szenarien angewendet werden kann. Seine Betriebseffizienz und hohen Leistungsfähigkeiten machen es zu einem wertvollen Gut für Unternehmen und Forscher, die fortschrittliche Sprachverarbeitungslösungen benötigen.
Betriebseffizienz von Mixtral-8x22B
Betriebseffizienz ist ein entscheidender Faktor für die Leistung von Large Language Models. Mixtral-8x22B wurde mit einem Fokus auf Betriebseffizienz entwickelt und bietet erhebliche Vorteile in Bezug auf Kosten- und Latenzkontrolle. Das Modell verwendet eine Sparse Mixture of Experts (SMoE)-Architektur, die eine bessere Kontrolle von Kosten und Latenz ermöglicht, indem während der Inferenz nur ein Bruchteil der Gesamtparameter pro Token verwendet wird. Dieser Ansatz stellt sicher, dass Mixtral-8x22B qualitativ hochwertige Ergebnisse liefert und gleichzeitig die Ressourcennutzung durch direkte Präferenzoptimierung optimiert. Die Betriebseffizienz von Mixtral-8x22B, kombiniert mit seiner fortschrittlichen Chat-Vorlage, macht es zu einer idealen Wahl für Anwendungen, die schnelle und kosteneffiziente Sprachverarbeitungsfähigkeiten erfordern.
Geschwindigkeits- und Kosteneffizienz bei der Inferenz
Einer der Hauptvorteile von Mixtral-8x22B ist seine Geschwindigkeits- und Kosteneffizienz bei der Inferenz. Durch die Verwendung einer Sparse Mixture of Experts (SMoE)-Architektur kann Mixtral-8x22B Text schneller verarbeiten und generieren als andere große Sprachmodelle. Dieser Geschwindigkeitsvorteil führt zu Kosteneffizienz, da weniger Ressourcen erforderlich sind, um das gleiche Leistungsniveau zu erreichen. Die Verwendung aktiver Parameter, bei der nur ein Bruchteil der Gesamtparameter pro Token verwendet wird, trägt weiter zur Kosteneffizienz des Basismodells Mixtral-8x22B bei. Diese Faktoren machen Mixtral-8x22B zu einer attraktiven Wahl für Anwendungen, die schnelle und kostengünstige Sprachverarbeitungsfähigkeiten erfordern.
Navigation durch die Auswahl von Experten während der Inferenz
Während des Inferenzprozesses navigiert Mixtral-8x22B durch die Auswahl von Experten, um jedes Token zu verarbeiten. Das Router-Netzwerk, eine Schlüsselkomponente der Architektur, ist dafür verantwortlich, zwei Experten aus jedem Parametersatz auszuwählen, die jedes Token verarbeiten. Die Auswahl der Experten basiert auf den Präferenzen des Router-Netzwerks, das die am besten geeigneten Experten für jedes Token bestimmt. Diese Navigation durch die Auswahl von Experten ermöglicht es Mixtral-8x22B, die Stärken und das Fachwissen verschiedener Netzwerke zu nutzen, was zu einer genauen und qualitativ hochwertigen Textgenerierung führt. Das Router-Netzwerk spielt eine entscheidende Rolle dabei, sicherzustellen, dass die ausgewählten Experten in der Lage sind, jedes Token effektiv zu verarbeiten und zur Gesamtleistung von Mixtral-8x22B während der Inferenz beizutragen.
Benutzerleitfaden: Implementierung von Mixtral-8x22B
Die Implementierung von Mixtral-8x22B in Ihren Projekten ist ein unkomplizierter Prozess, der einige wichtige Schritte erfordert. Hier ist ein Benutzerleitfaden, der Ihnen den Einstieg in Mixtral-8x22B erleichtert:
- Erste Schritte mit Mixtral-8x22B: Machen Sie sich mit der Dokumentation und den Ressourcen von Mistral AI vertraut. Diese Ressourcen führen Sie durch den Implementierungsprozess und geben wertvolle Einblicke in die Fähigkeiten von Mixtral-8x22B.
- Best Practices für die Integration von Mixtral-8x22B: Befolgen Sie bewährte Methoden für die Integration von Mixtral-8x22B in Ihre Codebasis. Dazu gehört die Optimierung der Ressourcennutzung, die Handhabung von Eingabe- und Ausgabeformaten und die Nutzung der Fähigkeiten von Mixtral-8x22B, um die gewünschten Ergebnisse zu erzielen.
Wenn Sie diese Schritte befolgen, können Sie Mixtral-8x22B erfolgreich in Ihren Projekten implementieren und seine leistungsstarken Sprachverarbeitungsfähigkeiten nutzen.
Erste Schritte mit Mixtral-8x22B
Der Einstieg in Mixtral-8x22B ist ein einfacher Prozess, der das Vertrautmachen mit der Dokumentation und den Ressourcen von Mistral AI umfasst. Die Dokumentation führt Sie durch die Installation und Verwendung von Mixtral-8x22B, einschließlich der Verwendung von PEFT (Preference-based Fine-tuning) zur Optimierung der Modellleistung.
Darüber hinaus bietet Mistral AI vortrainierte Modelle an, die Sie direkt verwenden können, sodass Sie Mixtral-8x22B schnell in Ihre Projekte integrieren können. Durch Bezugnahme auf die Konfiguration und Dokumentation sowie die Nutzung der vortrainierten Modelle können Sie problemlos mit Mixtral-8x22B beginnen und seine leistungsstarken Sprachverarbeitungsfähigkeiten nutzen. Stellen Sie sicher, dass Sie sich auch mit den PEFT-Config-Klassen und Basis-Modellklassen vertraut machen, um ein besseres Verständnis dafür zu bekommen, wie PEFT in NeMo-Modellen funktioniert.
Darüber hinaus ist das Verständnis der Klassifikationsfähigkeiten von Mixtral-8x22B entscheidend, um sein volles Potenzial in verschiedenen Sprachverarbeitungsaufgaben auszuschöpfen.
Best Practices für die Integration von Mixtral-8x22B
Die Integration von Mixtral-8x22B in Ihre Projekte erfordert die Befolgung bewährter Verfahren, um eine optimale Leistung und Benutzerfreundlichkeit zu gewährleisten. Hier sind einige wichtige Best Practices für die Integration von Mixtral-8x22B:
- Ressourcennutzung optimieren: Achten Sie darauf, die Ressourcennutzung zu optimieren, indem Sie Speicher- und Rechenressourcen effizient verwalten. Dies wird dazu beitragen, die Leistung und Effizienz von Mixtral-8x22B in Ihren Anwendungen zu verbessern.
- Eingabe- und Ausgabeformate handhaben: Verstehen Sie die von Mixtral-8x22B erwarteten Eingabe- und Ausgabeformate und stellen Sie sicher, dass Ihre Anwendung diese angemessen handhaben kann. Dies umfasst die Vorverarbeitung von Eingabedaten und die Nachbearbeitung von generiertem Text.
- Fähigkeiten von Mixtral-8x22B nutzen: Erkunden und nutzen Sie die verschiedenen Fähigkeiten von Mixtral-8x22B, wie mathematisches Denken, Codegenerierung und mehrsprachiges Verständnis. Dadurch können Sie die Leistungsfähigkeit von Mixtral-8x22B in Ihren Anwendungen voll ausschöpfen.
Durch die Befolgung dieser Best Practices können Sie Mixtral-8x22B nahtlos in Ihre Projekte integrieren und sein volles Potenzial entfalten.
Zweige der Mixtral-Modellfamilie
Wie wir das Mixtral-8x22B-Modell vorgestellt haben, gibt es zwei weitere Zweige der Mixtral-Modellfamilie – Mistral 7B und Mixtral 8x7B.
Mistral 7B
Mistral AI verfolgte mit seinem ersten Modell, Mistral 7B, einen anderen Ansatz und entschied sich, nicht direkt mit größeren Modellen wie GPT-4 zu konkurrieren. Stattdessen wurde es auf einem kleineren Datensatz mit 7 Milliarden Parametern trainiert, was ein einzigartiges Angebot im Bereich der KI-Modelle darstellt. Um die Zugänglichkeit zu unterstreichen, hat Mistral AI dieses Modell zum kostenlosen Download zur Verfügung gestellt, sodass Entwickler es in ihre eigenen Systeme integrieren können. Mistral 7B ist ein kompaktes Sprachmodell, das im Vergleich zu Modellen wie GPT-4 zu deutlich geringeren Kosten erhältlich ist. Während GPT-4 umfassendere Fähigkeiten als solche kleineren Modelle bietet, bringt es auch höhere Kosten und eine komplexere Bedienung mit sich.
Mixtral 8x7B
Hier sind die wichtigsten Highlights von Mixtral:
- Es verarbeitet Kontexte mit bis zu 32.000 Token.
- Es unterstützt die Sprachen Englisch, Französisch, Italienisch, Deutsch und Spanisch.
- Mixtral zeigt Kenntnisse in Programmieraufgaben.
- Durch Fine-Tuning kann es in ein instruktionsfolgendes Modell umgewandelt werden und erreicht einen MT-Bench-Wert von 8.3.
Das Modell lässt sich nahtlos in etablierte Optimierungswerkzeuge wie Flash Attention 2, bitsandbytes und PEFT-Bibliotheken integrieren. Seine Checkpoints sind unter der Organisation mistralai im Hugging Face Hub verfügbar.
So wählen Sie das richtige Modell für Ihr Unternehmen
Berücksichtigen Sie bei Ihrer Entscheidung Folgendes:
- Verwendungszweck: Überlegen Sie, wofür Sie das Modell hauptsächlich nutzen möchten. Unterschiedliche Aktivitäten erfordern möglicherweise unterschiedliche Funktionen, wie etwa Modellkapazität, Kontextfenster und Leistung bei bestimmten Aufgaben.
- Portabilität: Wenn Sie das Modell über längere Zeiträume oder häufig transportieren müssen, legen Sie möglicherweise Wert auf eine leichtere und kompaktere Option.
- Budget: Vergleichen Sie die Preise der einzelnen Modelle und überlegen Sie, welche Funktionen Ihnen im Verhältnis zu den Kosten am wichtigsten sind.
- Bewertungen und Empfehlungen: Suchen Sie nach Bewertungen oder holen Sie Empfehlungen von Freunden, Familie oder Online-Communities ein, die Erfahrung mit diesen spezifischen Modellen haben. Sie können wertvolle Einblicke in die reale Leistung und Haltbarkeit geben.
Unsere LLM-API ist sowohl mit Mistral 7B als auch mit Mixtral 8x7B-Modellen ausgestattet:

Andererseits kann die LLM-API von novita.ai nahtlos in Ihre LLMs integriert werden. Mit günstigsten Preisen und skalierbaren Modellen bietet die Novita AI LLM Inference API Ihrem LLM eine unglaubliche Stabilität und eine sehr geringe Latenz von unter 2 Sekunden.

Fazit
Zusammenfassend läutet Mixtral-8x22B eine neue Ära im Bereich der Large Language Models ein, mit bahnbrechenden Funktionen und Betriebseffizienzen. Durch seine ausgefeilte Architektur, einschließlich des innovativen Mixture-of-Experts-Konzepts, zeigt Mixtral-8x22B eine überlegene Leistung im Vergleich zu seinen Pendants, wie in verschiedenen realen Anwendungen und Benchmarks hervorgehoben. Der Benutzerleitfaden erleichtert eine nahtlose Implementierung, wobei die Geschwindigkeits- und Kosteneffizienz bei der Inferenz betont wird. Unternehmen können in hohem Maße von den transformativen Fähigkeiten von Mixtral-8x22B profitieren, das neue Maßstäbe für die Sprachmodelltechnologie setzt. Bleiben Sie gespannt auf zukünftige Updates und eine vielversprechende Roadmap, die kontinuierliche Verbesserungen und Fortschritte dieser modernen Lösung verspricht.
Häufig gestellte Fragen
Was zeichnet Mixtral-8x22B im Vergleich zu anderen LLMs aus?
Mixtral-8x22B zeichnet sich durch seine einzigartige Architektur und Herangehensweise aus. Das Modell verwendet eine Sparse Mixture of Experts (SMoE)-Technik, bei der jede Schicht aus unterschiedlichen Parametergruppen besteht.
Wie können Unternehmen von Mixtral-8x22B profitieren?
Das Modell bietet Kosteneffizienz, indem während der Inferenz nur ein Bruchteil der Gesamtparameter pro Token verwendet wird. Dadurch können Unternehmen qualitativ hochwertige Ergebnisse erzielen und gleichzeitig die Ressourcennutzung optimieren und Kosten senken.
Zukünftige Updates und Roadmap für Mixtral-8x22B
Das Entwicklungsteam ist bestrebt, die Leistung und Fähigkeiten des Modells basierend auf Benutzerfeedback kontinuierlich zu verbessern. Benutzer können regelmäßige Updates und Ergänzungen erwarten, die die Vielseitigkeit und Effizienz von Mixtral-8x22B weiter steigern.
novita.ai, die Komplettlösung für grenzenlose Kreativität, die Ihnen Zugang zu über 100 APIs bietet. Von Bildgenerierung und Sprachverarbeitung bis hin zu Audioverfeinerung und Videobearbeitung – mit dem günstigen Pay-as-you-go-Modell befreit es Sie von der Wartung von GPUs, während Sie Ihre eigenen Produkte entwickeln. Testen Sie es kostenlos.
Empfohlene Lektüre
Novita AI LLM Inference Engine: der größte Durchsatz und günstigste Inferenz verfügbar



