

- Introducción
- Revelando Mixtral-8x22B: Una nueva era de modelos de lenguaje grandes
- Profundizando en la arquitectura de Mixtral-8x22B
- Rendimiento y capacidades de Mixtral
- Eficiencia operativa de Mixtral-8x22B
- Guía de usuario: Implementando Mixtral-8x22B
- Mejores prácticas para integrar Mixtral-8x22B
- Ramas de la familia de modelos Mixtral
- Conclusión
- Preguntas frecuentes
Explora Mixtral-8x22B y otras ramas de la familia de modelos mixtral en nuestro blog.
Introducción
En el mundo del procesamiento de lenguaje natural (PLN), los modelos de lenguaje grandes se han convertido en la base de diversas tareas de PLN. Estos modelos están diseñados para comprender y generar texto similar al humano, lo que los convierte en herramientas valiosas para aplicaciones como chatbots, sistemas de traducción y generación de código. Mistral AI, un laboratorio de investigación en IA líder, ha presentado recientemente Mixtral-8x22B, la última y más grande mezcla de modelos de lenguaje de expertos (LLM) que amplía los límites de los modelos de código abierto.
Mixtral-8x22B es un modelo de lenguaje basado en una mezcla escasa de expertos (SMoE) que ofrece un rendimiento superior y eficiencia de costos en comparación con otros LLM. Supera a Llama 2 70B con una inferencia 6 veces más rápida y iguala o incluso supera a GPT-3.5 en varios benchmarks. Este modelo tiene licencia Apache 2.0, lo que lo hace accesible para que desarrolladores e investigadores lo utilicen en sus proyectos.
Con 47 mil millones de parámetros totales, Mixtral-8x22B es un modelo de lenguaje potente que puede manejar tareas complejas como razonamiento matemático, generación de código y comprensión multilingüe. Soporta idiomas como inglés, francés, italiano, alemán y español, lo que lo convierte en una herramienta versátil para aplicaciones globales. Además, Mixtral-8x22B tiene la capacidad de manejar una ventana de contexto de 32k tokens, lo que le permite procesar y generar texto con indicaciones largas y complejas utilizando su avanzada tecnología de GPU.
Revelando Mixtral-8x22B: Una nueva era de modelos de lenguaje grandes
Mixtral-8x22B representa un nuevo estándar en el campo de los modelos de lenguaje grandes. Con su arquitectura de vanguardia y rendimiento impresionante, establece un nuevo punto de referencia para las capacidades y eficiencia de los modelos de lenguaje.
Desarrollado por Mistral AI, Mixtral-8x22B ofrece un enfoque novedoso para el modelado de lenguaje al utilizar una técnica de mezcla escasa de expertos (SMoE). Esta arquitectura innovadora permite un mejor control de costos y latencia mientras sigue ofreciendo resultados excepcionales. Lanzado en diciembre de 2023, Mixtral-8x22B es la adición más reciente y grande a la familia de modelos Mixtral, introduciendo el concepto de mezcla de expertos de mixtral y trayendo consigo una serie de mejoras y perfeccionamientos que potencian aún más su rendimiento y capacidades.
El génesis de Mixtral-8x22B
El desarrollo de Mixtral-8x22B es el resultado de una extensa investigación y colaboración dentro de la comunidad de IA. Mistral AI, junto con un equipo de talentosos investigadores e ingenieros, incluyendo a William El Sayed, se embarcó en un viaje para crear un modelo de lenguaje que ampliara los límites de lo posible en el campo del procesamiento de lenguaje natural.
El génesis de Mixtral-8x22B implicó la exploración de nuevas arquitecturas y técnicas, así como el análisis de grandes conjuntos de datos para entrenar el modelo. La comunidad de IA desempeñó un papel crucial en este proceso, con investigadores y desarrolladores contribuyendo con su experiencia y conocimiento para refinar y mejorar el modelo. El resultado es un modelo de lenguaje de vanguardia que representa la culminación de años de investigación y desarrollo. Mixtral-8x22B es un testimonio del poder de la colaboración y la innovación en el campo de la IA.
Componentes centrales de Mixtral-8x22B
El modelo Mixtral-8x22B consta de varios componentes centrales que trabajan juntos para ofrecer su rendimiento excepcional. Estos incluyen:
- Modelo Mixtral: Mixtral-8x22B es un modelo de mezcla escasa de expertos (SMoE), lo que significa que utiliza una combinación de diferentes redes expertas para procesar y generar texto.
- Red de enrutamiento: En cada capa del modelo Mixtral, una red de enrutamiento selecciona dos expertos de un conjunto de grupos distintos de parámetros para procesar cada token.
- Parámetros activos: Si bien Mixtral-8x22B tiene un total de 47 mil millones de parámetros, solo utiliza 13 mil millones de parámetros por token durante la inferencia, lo que resulta en un mejor control de costos y latencia.
- Combinación aditiva: Las salidas producidas por las redes expertas se combinan de forma aditiva, dando como resultado una suma ponderada que representa la salida de todo el módulo de mezcla de expertos.
Estos componentes centrales permiten a Mixtral-8x22B procesar y generar texto de manera efectiva, proporcionando a los usuarios resultados precisos y de alta calidad. La arquitectura de Mixtral-8x22B está diseñada para optimizar tanto el rendimiento como la eficiencia, convirtiéndolo en una herramienta potente para una amplia gama de tareas de procesamiento de lenguaje.
Profundizando en la arquitectura de Mixtral-8x22B
La arquitectura de Mixtral-8x22B se basa en el concepto de mezcla de expertos, específicamente un modelo de mezcla escasa de expertos (SMoE). Este modelo solo con decodificador utiliza una red de enrutamiento para seleccionar dos expertos de cada uno de los 8 grupos distintos de parámetros para procesar cada token. Las salidas de los expertos seleccionados se combinan de forma aditiva para producir la salida final. Esta arquitectura permite a Mixtral-8x22B avanzar en la frontera de los modelos abiertos y lograr un rendimiento y precisión de última generación.
Entendiendo la Mezcla de Expertos (MoE)
Una mezcla de expertos (MoE) es una técnica de modelado que combina las salidas de múltiples redes expertas para generar texto. En el contexto de Mixtral-8x22B, la arquitectura MoE se utiliza para aprovechar las fortalezas y la experiencia de diferentes redes para procesar y generar texto preciso y de alta calidad. La red de enrutamiento desempeña un papel crucial en esta arquitectura al seleccionar dos expertos de cada conjunto de parámetros para procesar cada token.
Esta selección se basa en la optimización de preferencias del enrutador, que determina los expertos más adecuados para cada token. Al combinar las salidas de los expertos seleccionados de forma aditiva, Mixtral-8x22B puede generar texto que exhibe el conocimiento colectivo y la experiencia de las redes expertas, lo que resulta en un rendimiento y precisión superiores.
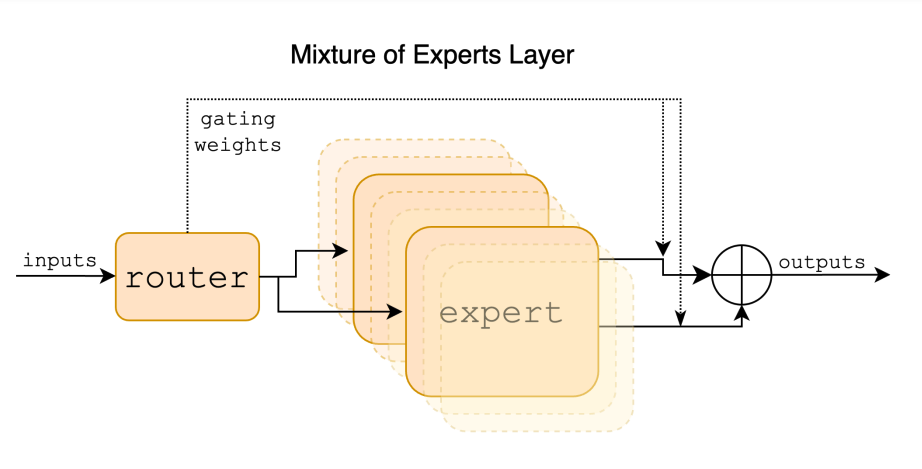
El papel de los modelos 22b en Mixtral-8x22B
Los modelos 22b desempeñan un papel crucial en el rendimiento de Mixtral-8x22B. Estos modelos son responsables de proporcionar la experiencia y el conocimiento necesarios para generar texto preciso y de alta calidad. Al aprovechar las fortalezas y capacidades de los modelos 22b, Mixtral-8x22B puede ofrecer un rendimiento superior en una amplia gama de tareas de procesamiento de lenguaje.
Los modelos 22b contribuyen al rendimiento general de Mixtral-8x22B al proporcionar conocimiento y experiencia especializados en áreas específicas, como generación de código, razonamiento matemático y comprensión multilingüe. Esta combinación de experiencia permite a Mixtral-8x22B generar texto preciso y contextualmente relevante, lo que lo convierte en una herramienta potente para desarrolladores e investigadores en el campo del procesamiento de lenguaje natural.
Rendimiento y capacidades de Mixtral
Mixtral-8x22B demuestra un rendimiento sólido en una amplia gama de benchmarks y tareas de procesamiento de lenguaje. Supera a Llama 2 70B en varios benchmarks, incluido el Bias Benchmark for QA (BBQ), e iguala o incluso supera a GPT-3.5, un modelo de lenguaje grande ampliamente reconocido. El rendimiento del modelo es particularmente notable en áreas como razonamiento matemático, generación de código y comprensión multilingüe. Ha sido entrenado en una gran cantidad de datos web abiertos y ha mostrado un rendimiento excepcional en el manejo de tareas complejas. Con su impresionante rendimiento y versátiles capacidades, Mixtral-8x22B, impulsado por la biblioteca PyTorch, está destinado a convertirse en la opción preferida para desarrolladores e investigadores en el campo del procesamiento de lenguaje natural.
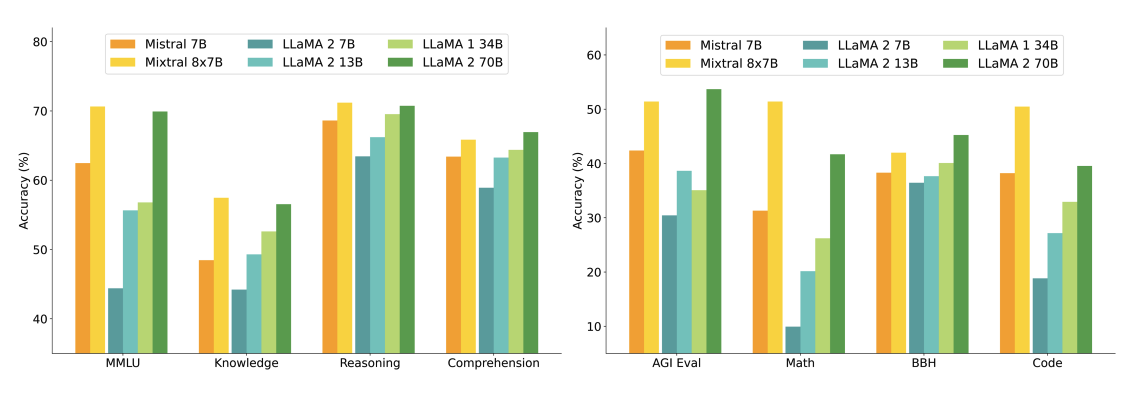
El siguiente gráfico muestra el rendimiento en comparación con diferentes tamaños de modelos Llama 2 en una gama más amplia de capacidades y benchmarks. Mixtral iguala o supera a Llama 2 70B y muestra un rendimiento superior en matemáticas y generación de código.
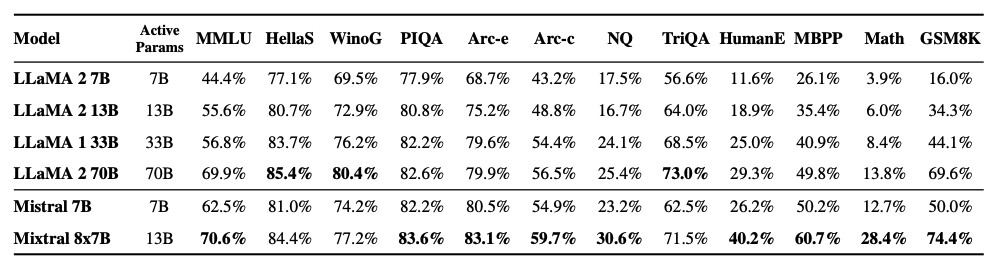
Como se ve en la figura a continuación, Mixtral 8x7B también supera o iguala a los modelos Llama 2 en diferentes benchmarks populares como MMLU y GSM8K. Logra estos resultados mientras utiliza 5 veces menos parámetros activos durante la inferencia.
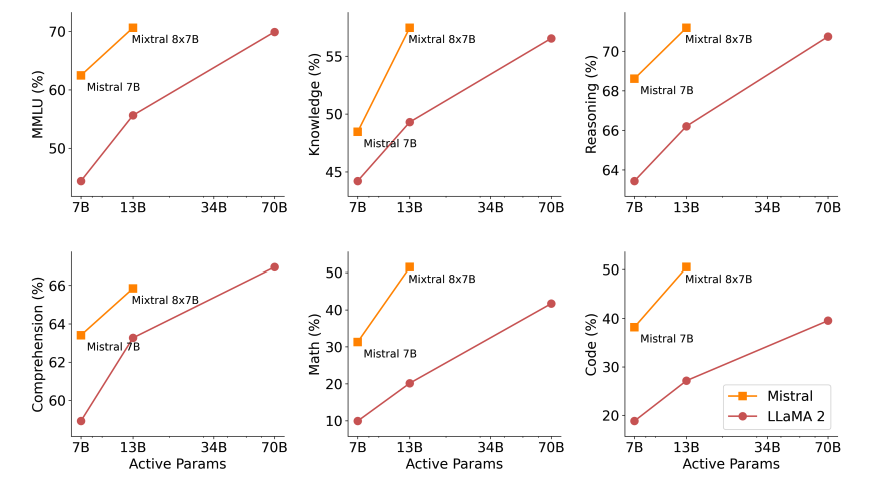
La siguiente figura demuestra la relación calidad vs. presupuesto de inferencia. Mixtral supera a Llama 2 70B en varios benchmarks mientras utiliza 5 veces menos parámetros activos.
Comparando Mixtral-8x22B con otros LLMs
Mixtral-8x22B ha sido comparado con varios otros modelos de lenguaje grandes (LLM) para evaluar su rendimiento y capacidades. Los resultados de estas comparaciones demuestran el rendimiento superior de Mixtral-8x22B en diversas tareas de procesamiento de lenguaje. A continuación se muestra una comparación de Mixtral-8x22B con otros LLM en diferentes benchmarks estándar:

Estos resultados de benchmarks destacan claramente el fuerte rendimiento de Mixtral-8x22B en comparación con otros LLM. Su capacidad para manejar tareas complejas y ofrecer resultados precisos lo distingue como una opción líder para desarrolladores e investigadores en el campo del procesamiento de lenguaje natural.
Aplicaciones del mundo real y casos de estudio
Mixtral-8x22B tiene numerosas aplicaciones del mundo real en diversas industrias y dominios. Su versatilidad y potentes capacidades lo convierten en una herramienta valiosa para una amplia gama de casos de uso. Algunos ejemplos de aplicaciones del mundo real de Mixtral-8x22B incluyen:
- Chatbots: Mixtral-8x22B se puede utilizar para desarrollar chatbots que comprendan y respondan eficazmente a conversaciones similares a las humanas, brindando soporte y asistencia al cliente sin problemas.
- Sistemas de traducción: Con sus capacidades de comprensión multilingüe, Mixtral-8x22B se puede utilizar para construir sistemas de traducción que traduzcan texto con precisión entre diferentes idiomas.
- Generación de código: Las sólidas capacidades de generación de código de Mixtral-8x22B lo convierten en una opción ideal para desarrollar sistemas que puedan generar fragmentos de código automáticamente según los requisitos del usuario.
Estos son solo algunos ejemplos de cómo se puede aplicar Mixtral-8x22B en escenarios del mundo real. Su eficiencia operativa y capacidades de alto rendimiento lo convierten en un activo valioso para empresas e investigadores que necesitan soluciones avanzadas de procesamiento de lenguaje.
Eficiencia operativa de Mixtral-8x22B
La eficiencia operativa es un factor clave en el rendimiento de los modelos de lenguaje grandes. Mixtral-8x22B ha sido diseñado centrándose en la eficiencia operativa, ofreciendo beneficios significativos en términos de control de costos y latencia. El modelo utiliza una arquitectura de mezcla escasa de expertos (SMoE), que permite un mejor control de costos y latencia al utilizar una fracción del conjunto total de parámetros por token durante la inferencia. Este enfoque garantiza que Mixtral-8x22B ofrezca resultados de alta calidad mientras optimiza el uso de recursos mediante la optimización directa de preferencias. La eficiencia operativa de Mixtral-8x22B, combinada con su avanzada plantilla de chat, lo convierte en una opción ideal para aplicaciones que requieren capacidades de procesamiento de lenguaje rápidas y rentables.
Velocidad y eficiencia de costos en la inferencia
Una de las ventajas clave de Mixtral-8x22B es su velocidad y eficiencia de costos durante la inferencia. Al utilizar una arquitectura de mezcla escasa de expertos (SMoE), Mixtral-8x22B puede procesar y generar texto a un ritmo más rápido en comparación con otros modelos de lenguaje grandes. Esta ventaja de velocidad se traduce en eficiencia de costos, ya que se requieren menos recursos para lograr el mismo nivel de rendimiento. El uso de parámetros activos, donde solo una fracción del conjunto total de parámetros se utiliza por token, contribuye aún más a la eficiencia de costos del modelo base, Mixtral-8x22B. Estos factores hacen de Mixtral-8x22B una opción atractiva para aplicaciones que requieren capacidades de procesamiento de lenguaje rápidas y rentables.
Navegando a través de la selección de expertos durante la inferencia
Durante el proceso de inferencia, Mixtral-8x22B navega a través de la selección de expertos para procesar cada token. La red de enrutamiento, un componente clave de la arquitectura, es responsable de seleccionar dos expertos de cada conjunto de parámetros para manejar cada token. La selección de expertos se basa en las preferencias de la red de enrutamiento, que determina los expertos más adecuados para cada token. Esta navegación a través de la selección de expertos permite a Mixtral-8x22B aprovechar las fortalezas y la experiencia de diferentes redes, lo que resulta en una generación de texto precisa y de alta calidad. La red de enrutamiento desempeña un papel crucial para garantizar que los expertos seleccionados puedan procesar eficazmente cada token y contribuir al rendimiento general de Mixtral-8x22B durante la inferencia.
Guía de usuario: Implementando Mixtral-8x22B
Implementar Mixtral-8x22B en tus proyectos es un proceso sencillo que requiere algunos pasos clave. Aquí tienes una guía de usuario para ayudarte a comenzar con Mixtral-8x22B:
- Comienza con Mixtral-8x22B: Familiarízate con la documentación y los recursos proporcionados por Mistral AI. Estos recursos te guiarán a través del proceso de implementación y te proporcionarán información valiosa sobre las capacidades de Mixtral-8x22B.
- Mejores prácticas para integrar Mixtral-8x22B: Sigue las mejores prácticas para integrar Mixtral-8x22B en tu código. Esto incluye optimizar el uso de recursos, manejar formatos de entrada y salida, y aprovechar las capacidades de Mixtral-8x22B para lograr los resultados deseados.
Siguiendo estos pasos, puedes implementar con éxito Mixtral-8x22B en tus proyectos y aprovechar sus potentes capacidades de procesamiento de lenguaje.
Comenzando con Mixtral-8x22B
Comenzar con Mixtral-8x22B es un proceso simple que implica familiarizarse con la documentación y los recursos proporcionados por Mistral AI. La documentación te guiará a través de la instalación y el uso de Mixtral-8x22B, incluido el uso de PEFT (ajuste fino basado en preferencias) para optimizar el rendimiento del modelo.
Además, Mistral AI proporciona modelos preentrenados que puedes usar directamente, lo que te permite integrar rápidamente Mixtral-8x22B en tus proyectos. Al consultar la documentación de configuración y utilizar los modelos preentrenados, puedes comenzar fácilmente con Mixtral-8x22B y empezar a aprovechar sus potentes capacidades de procesamiento de lenguaje. Asegúrate también de familiarizarte con las clases de configuración de PEFT y las clases de modelo base para comprender mejor cómo funciona PEFT en los modelos NeMo.
Además, comprender las capacidades de clasificación de Mixtral-8x22B es crucial para aprovechar todo su potencial en diversas tareas de procesamiento de lenguaje.
Mejores prácticas para integrar Mixtral-8x22B
Integrar Mixtral-8x22B en tus proyectos requiere seguir las mejores prácticas para garantizar un rendimiento y usabilidad óptimos. Estas son algunas prácticas clave para integrar Mixtral-8x22B:
- Optimiza el uso de recursos: Asegúrate de optimizar el uso de recursos gestionando eficientemente la memoria y los recursos computacionales. Esto ayudará a mejorar el rendimiento y la eficiencia de Mixtral-8x22B en tus aplicaciones.
- Maneja los formatos de entrada y salida: Comprende los formatos de entrada y salida esperados por Mixtral-8x22B y asegúrate de que tu aplicación pueda manejarlos adecuadamente. Esto incluye preprocesar los datos de entrada y posprocesar el texto generado.
- Aprovecha las capacidades de Mixtral-8x22B: Explora y utiliza las diversas capacidades de Mixtral-8x22B, como razonamiento matemático, generación de código y comprensión multilingüe. Esto te permitirá aprovechar al máximo el poder de Mixtral-8x22B en tus aplicaciones.
Al seguir estas mejores prácticas, puedes integrar sin problemas Mixtral-8x22B en tus proyectos y desbloquear todo su potencial.
Ramas de la familia de modelos Mixtral
Como hemos presentado el modelo Mixtral-8x22B, existen otras dos ramas de la familia de modelos Mixtral: Mistral 7B y Mixtral 8x7B.
Mistral 7B
Mistral AI adoptó un enfoque distintivo con su modelo inicial, Mistral 7B, optando por no competir directamente con contrapartes más grandes como GPT-4. En su lugar, fue entrenado en un conjunto de datos más pequeño con 7 mil millones de parámetros, presentando una propuesta única en el dominio de los modelos de IA. En un esfuerzo por enfatizar la accesibilidad, Mistral AI ha puesto este modelo disponible para descarga gratuita, permitiendo a los desarrolladores integrarlo en sus propios sistemas. Mistral 7B es un modelo de lenguaje compacto que tiene un costo significativamente menor en comparación con modelos como GPT-4. Si bien GPT-4 cuenta con capacidades más amplias que modelos más pequeños como este, también conlleva mayores gastos y complejidad operativa.
Mixtral 8x7B
Estos son los aspectos clave de Mixtral:
- Procesa contexto con hasta 32k tokens.
- Soporta los idiomas inglés, francés, italiano, alemán y español.
- Mixtral demuestra competencia en tareas de codificación.
- Con ajuste fino, puede transformarse en un modelo que sigue instrucciones, logrando una puntuación MT-Bench de 8.3.
El modelo se integra perfectamente con herramientas de optimización establecidas como Flash Attention 2, bitsandbytes y las bibliotecas PEFT. Sus puntos de control están disponibles en la organización mistralai en el Hugging Face Hub.
Cómo elegir el modelo adecuado para tu negocio
Considera lo siguiente al tomar tu decisión:
- Uso previsto: Piensa en las actividades para las que utilizarás principalmente los prismáticos. Diferentes actividades pueden requerir características distintas, como el aumento, el campo de visión y el rendimiento con poca luz.
- Portabilidad: Si llevarás los prismáticos durante períodos prolongados o viajarás con frecuencia, es posible que priorices una opción más ligera y compacta.
- Presupuesto: Compara los precios de cada modelo y considera qué características son más importantes para ti en relación con el costo.
- Reseñas y recomendaciones: Busca reseñas o solicita recomendaciones de amigos, familiares o comunidades en línea que tengan experiencia con estos modelos específicos. Pueden proporcionar información valiosa sobre el rendimiento y la durabilidad en el mundo real.
Nuestra API de LLM está equipada con ambos modelos Mistral 7B y Mixtral 8x7B:

Por otro lado, la API de LLM de novita.ai, que se integra perfectamente con tus LLMs. Con precios económicos y modelos escalables, la API de inferencia de LLM de Novita AI ofrece a tu LLM una estabilidad increíble y una latencia bastante baja en menos de 2 segundos.

Conclusión
En conclusión, Mixtral-8x22B marca una nueva era en el dominio de los modelos de lenguaje grandes con sus características innovadoras y eficiencias operativas. A través de su arquitectura sofisticada, incluido el innovador concepto de Mezcla de Expertos, Mixtral-8x22B muestra un rendimiento superior en comparación con sus contrapartes, como se destaca en diversas aplicaciones del mundo real y benchmarks. La guía de usuario facilita una implementación sin problemas, enfatizando la velocidad y la eficiencia de costos durante la inferencia. Las empresas se beneficiarán enormemente de las capacidades transformadoras de Mixtral-8x22B, estableciendo nuevos estándares para la tecnología de modelos de lenguaje. Mantente atento a futuras actualizaciones y una hoja de ruta emocionante que promete mejoras y avances continuos en esta solución de vanguardia.
Preguntas frecuentes
¿Qué hace que Mixtral-8x22B se destaque de otros LLMs?
Mixtral-8x22B se destaca debido a su arquitectura y enfoque únicos. El modelo utiliza una técnica de mezcla escasa de expertos (SMoE), donde cada capa consta de grupos distintos de parámetros.
¿Cómo pueden las empresas beneficiarse de Mixtral-8x22B?
El modelo ofrece eficiencia de costos al utilizar una fracción del conjunto total de parámetros por token durante la inferencia. Esto permite a las empresas lograr resultados de alta calidad mientras optimizan el uso de recursos y reducen costos.
¿Actualizaciones futuras y hoja de ruta para Mixtral-8x22B?
El equipo de desarrollo está comprometido a mejorar continuamente el rendimiento y las capacidades del modelo en función de los comentarios de los usuarios. Los usuarios pueden esperar actualizaciones y adiciones regulares para mejorar aún más la versatilidad y eficiencia de Mixtral-8x22B.
novita.ai, la plataforma integral para la creatividad ilimitada que te da acceso a más de 100 API. Desde generación de imágenes y procesamiento de lenguaje hasta mejora de audio y manipulación de video, con precios económicos de pago por uso, te libera de las tareas de mantenimiento de GPU mientras construyes tus propios productos. Pruébalo gratis.
Lectura recomendada
Novita AI LLM Inference Engine: el mayor rendimiento y la inferencia más barata disponible



