

استكشف Mixtral-8x22B والفروع الأخرى لعائلة نماذج mixtral في مدونتنا.
مقدمة
في عالم معالجة اللغة الطبيعية (NLP)، أصبحت النماذج اللغوية الكبيرة حجر الزاوية لمختلف مهام معالجة اللغة الطبيعية. صُممت هذه النماذج لفهم النص الشبيه بالنص البشري وتوليده، مما يجعلها أدوات قيمة لتطبيقات مثل روبوتات المحادثة، وأنظمة الترجمة، وتوليد الكود. مؤخرًا، قدمت Mistral AI، مختبر أبحاث الذكاء الاصطناعي الرائد، نموذج Mixtral-8x22B، وهو أحدث وأكبر نموذج لغوي كبير مختلط من الخبراء (LLM) يدفع حدود النماذج مفتوحة المصدر.
Mixtral-8x22B هو نموذج لغوي مختلط متناثر من الخبراء (SMoE) يوفر أداءً فائقًا وكفاءة في التكلفة مقارنة بنماذج LLM الأخرى. يتفوق على Llama 2 70B مع سرعة استدلال أسرع بست مرات، ويضاهي أو حتى يتفوق على GPT-3.5 في العديد من المعايير. هذا النموذج مرخص بموجب Apache 2.0، مما يجعله في متناول المطورين والباحثين لاستخدامه في مشاريعهم.
بامتلاكه 47 مليار معلمة إجمالية، يُعد Mixtral-8x22B نموذجًا لغويًا قويًا يمكنه التعامل مع المهام المعقدة مثل التفكير الرياضي وتوليد الكود والفهم متعدد اللغات. يدعم لغات مثل الإنجليزية والفرنسية والإيطالية والألمانية والإسبانية، مما يجعله أداة متعددة الاستخدامات للتطبيقات العالمية. بالإضافة إلى ذلك، يتمتع Mixtral-8x22B بالقدرة على التعامل مع نافذة سياقية تصل إلى 32 ألف رمز، مما يتيح له معالجة وتوليد نصوص ذات مطالبات طويلة ومعقدة باستخدام تقنية GPU المتقدمة.
الكشف عن Mixtral-8x22B: عصر جديد من النماذج اللغوية الكبيرة
يمثل Mixtral-8x22B معيارًا جديدًا في مجال النماذج اللغوية الكبيرة. من خلال هندسته المتطورة وأدائه المذهل، يضع معيارًا جديدًا لقدرات وكفاءة النماذج اللغوية.
طورته Mistral AI، يقدم Mixtral-8x22B نهجًا جديدًا لنمذجة اللغة باستخدام تقنية الخبراء المختلطين المتناثرين (SMoE). تسمح هذه الهندسة المبتكرة بتحكم أفضل في التكلفة وزمن الاستجابة مع تقديم نتائج استثنائية. صدر في ديسمبر 2023، Mixtral-8x22B هو أحدث وأكبر إضافة لعائلة نماذج Mixtral، حيث يقدم مفهوم خبراء Mixtral ويجلب معه مجموعة من التحسينات والتطويرات التي تزيد من أدائه وقدراته.
نشأة Mixtral-8x22B
تطوير Mixtral-8x22B هو نتيجة بحث مكثف وتعاون داخل مجتمع الذكاء الاصطناعي. شرعت Mistral AI، مع فريق من الباحثين والمهندسين الموهوبين، بمن فيهم William El Sayed، في رحلة لإنشاء نموذج لغوي يدفع حدود الممكن في مجال معالجة اللغة الطبيعية.
تضمن نشأة Mixtral-8x22B استكشاف بنى وتقنيات جديدة، بالإضافة إلى تحليل مجموعات بيانات كبيرة لتدريب النموذج. لعب مجتمع الذكاء الاصطناعي دورًا حاسمًا في هذه العملية، حيث ساهم الباحثون والمطورون بخبراتهم ومعرفتهم لتحسين النموذج وتطويره. والنتيجة هي نموذج لغوي متطور يمثل تتويجًا لسنوات من البحث والتطوير. Mixtral-8x22B هو دليل على قوة التعاون والابتكار في مجال الذكاء الاصطناعي.
المكونات الأساسية لـ Mixtral-8x22B
يتكون نموذج Mixtral-8x22B من عدة مكونات أساسية تعمل معًا لتقديم أدائه الاستثنائي. وتشمل هذه:
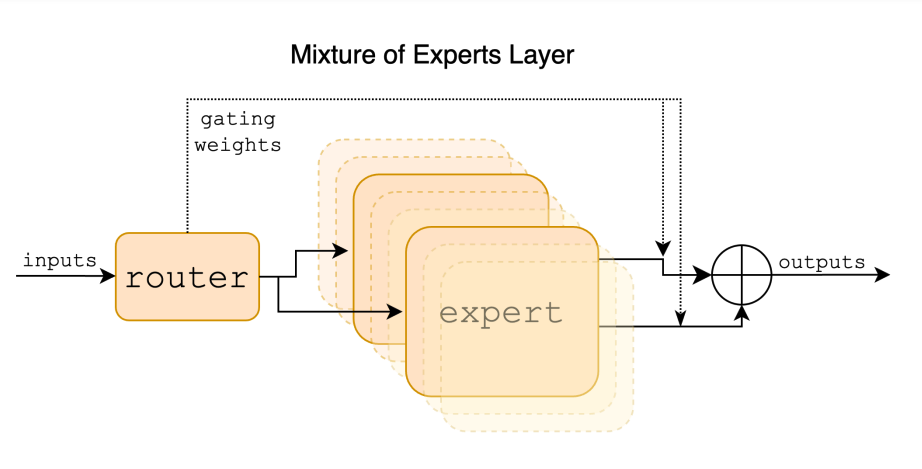
- نموذج Mixtral: Mixtral-8x22B هو نموذج خبراء مختلطين متناثرين (SMoE)، مما يعني أنه يستخدم مجموعة من شبكات الخبراء المختلفة لمعالجة النص وتوليده.
- شبكة التوجيه (Router Network): في كل طبقة من نموذج Mixtral، تختار شبكة التوجيه خبيرين من مجموعة متميزة من المعلمات لمعالجة كل رمز.
- المعلمات النشطة: بينما يمتلك Mixtral-8x22B إجمالي 47 مليار معلمة، فإنه يستخدم فقط 13 مليار معلمة لكل رمز أثناء الاستدلال، مما يؤدي إلى تحكم أفضل في التكلفة وزمن الاستجابة.
- المزيج الجمعي: يتم دمج المخرجات التي تنتجها شبكات الخبراء بشكل جمعي، مما ينتج عنه مجموع مرجح يمثل مخرجات وحدة الخبراء المختلطين بأكملها.
تسمح هذه المكونات الأساسية لـ Mixtral-8x22B بمعالجة النص وتوليده بفعالية، مما يوفر للمستخدمين نتائج دقيقة وعالية الجودة. صُممت بنية Mixtral-8x22B لتحسين كل من الأداء والكفاءة، مما يجعله أداة قوية لمجموعة واسعة من مهام معالجة اللغة.
الغوص العميق في بنية Mixtral-8x22B
تعتمد بنية Mixtral-8x22B على مفهوم الخبراء المختلطين، وتحديدًا نموذج الخبراء المختلطين المتناثرين (SMoE). يستخدم هذا النموذج الذي يعتمد على وحدة فك التشفير فقط شبكة توجيه لاختيار خبيرين من كل مجموعة من 8 مجموعات متميزة من المعلمات لمعالجة كل رمز. ثم يتم دمج مخرجات الخبراء المختارين بشكل جمعي لإنتاج المخرجات النهائية. تسمح هذه البنية لـ Mixtral-8x22B بدفع حدود النماذج المفتوحة وتحقيق أداء ودقة متطورين.
فهم الخبراء المختلطين (MoE)
الخبراء المختلطين (MoE) هي تقنية نمذجة تجمع بين مخرجات شبكات خبراء متعددة لتوليد النص. في سياق Mixtral-8x22B، يتم استخدام بنية MoE للاستفادة من نقاط القوة والخبرة لشبكات مختلفة لمعالجة وتوليد نص دقيق وعالي الجودة. تلعب شبكة التوجيه دورًا حاسمًا في هذه البنية من خلال اختيار خبيرين من كل مجموعة معلمات لمعالجة كل رمز.
يعتمد هذا الاختيار على تحسين تفضيلات جهاز التوجيه، الذي يحدد أنسب الخبراء لكل رمز. من خلال الجمع بين مخرجات الخبراء المختارين بشكل جمعي، يستطيع Mixtral-8x22B توليد نصوص تُظهر المعرفة الجماعية وخبرة شبكات الخبراء، مما يؤدي إلى أداء ودقة فائقين.
دور نماذج 22b في Mixtral-8x22B
تلعب نماذج 22b دورًا حاسمًا في أداء Mixtral-8x22B. هذه النماذج مسؤولة عن توفير الخبرة والمعرفة اللازمتين لتوليد نص دقيق وعالي الجودة. من خلال الاستفادة من نقاط القوة والقدرات لنماذج 22b، يستطيع Mixtral-8x22B تقديم أداء فائق عبر مجموعة واسعة من مهام معالجة اللغة.
تساهم نماذج 22b في الأداء العام لـ Mixtral-8x22B من خلال توفير المعرفة والخبرة المتخصصة في مجالات محددة، مثل توليد الكود والتفكير الرياضي والفهم متعدد اللغات. يسمح هذا المزيج من الخبرات لـ Mixtral-8x22B بتقديم نص دقيق وذو صلة سياقية، مما يجعله أداة قوية للمطورين والباحثين في مجال معالجة اللغة الطبيعية.
أداء Mixtral وقدراته
يُظهر Mixtral-8x22B أداءً قويًا عبر مجموعة واسعة من المعايير ومهام معالجة اللغة. يتفوق على Llama 2 70B في عدة معايير، بما في ذلك معيار التحيز لأسئلة وأجوبة (BBQ)، ويضاهي أو حتى يتفوق على GPT-3.5، وهو نموذج لغوي كبير معروف على نطاق واسع. أداء النموذج ملحوظ بشكل خاص في مجالات مثل التفكير الرياضي وتوليد الكود والفهم متعدد اللغات. تم تدريبه على كمية هائلة من بيانات الويب المفتوحة وأظهر أداءً استثنائيًا في التعامل مع المهام المعقدة. بفضل أدائه المذهل وقدراته المتنوعة، فإن Mixtral-8x22B، المدعوم بمكتبة PyTorch، مهيأ ليصبح الخيار الأول للمطورين والباحثين في مجال معالجة اللغة الطبيعية.
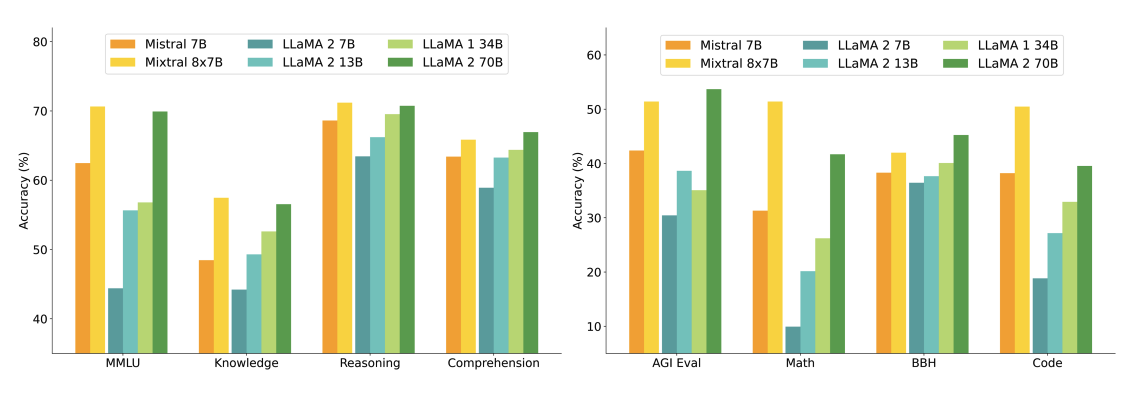
يوضح الرسم البياني أدناه الأداء مقارنة بأحجام مختلفة من نماذج Llama 2 عبر مجموعة واسعة من القدرات والمعايير. يضاهي Mixtral أو يتفوق على Llama 2 70B ويظهر أداءً فائقًا في الرياضيات وتوليد الكود.
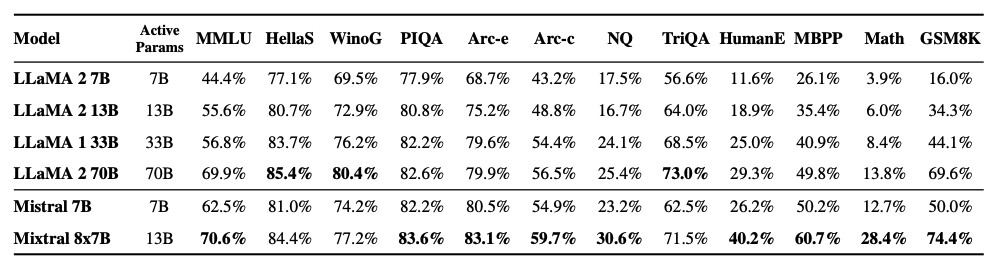
كما هو موضح في الشكل أدناه، يتفوق Mixtral 8x7B أيضًا على نماذج Llama 2 أو يضاهيها عبر معايير شائعة مختلفة مثل MMLU وGSM8K. يحقق هذه النتائج باستخدام معلمات نشطة أقل بمقدار 5 مرات أثناء الاستدلال.
يوضح الشكل أدناه المفاضلة بين الجودة وميزانية الاستدلال. يتفوق Mixtral على Llama 2 70B في العديد من المعايير باستخدام معلمات نشطة أقل بمقدار 5 مرات.
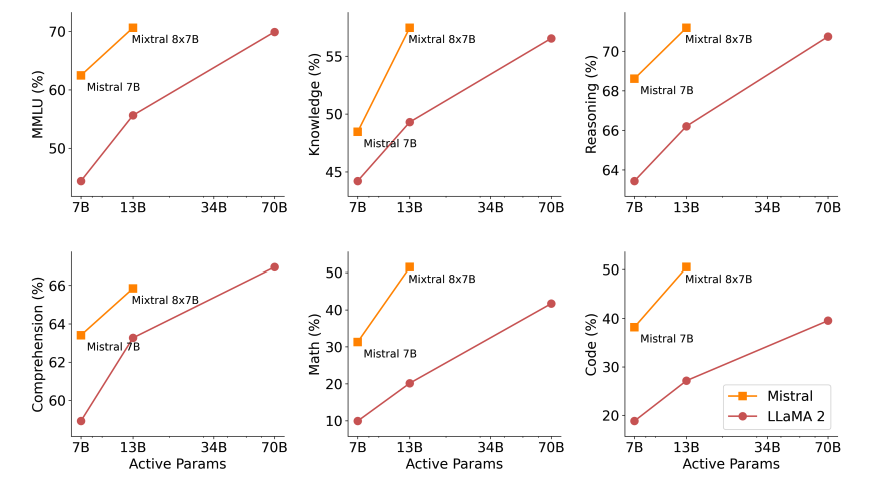
قياس أداء Mixtral-8x22B مقابل نماذج LLM الأخرى
تم قياس أداء Mixtral-8x22B مقابل عدة نماذج لغوية كبيرة أخرى (LLM) لتقييم أدائه وقدراته. تُظهر نتائج هذه المقاييس الأداء الفائق لـ Mixtral-8x22B في مهام معالجة اللغة المختلفة. إليك مقارنة بين Mixtral-8x22B ونماذج LLM الأخرى عبر معايير قياسية مختلفة:

تسلط نتائج المقارنة هذه الضوء بوضوح على الأداء القوي لـ Mixtral-8x22B مقارنة بنماذج LLM الأخرى. قدرته على التعامل مع المهام المعقدة وتقديم نتائج دقيقة تميزه كخيار رائد للمطورين والباحثين في مجال معالجة اللغة الطبيعية.
التطبيقات الواقعية ودراسات الحالة
يمتلك Mixtral-8x22B العديد من التطبيقات الواقعية عبر مختلف الصناعات والمجالات. تنوعه وقدراته القوية تجعله أداة قيمة لمجموعة واسعة من حالات الاستخدام. بعض الأمثلة على التطبيقات الواقعية لـ Mixtral-8x22B تشمل:
- روبوتات المحادثة: يمكن استخدام Mixtral-8x22B لتطوير روبوتات محادثة يمكنها فهم والرد على المحادثات الشبيهة بالبشر بفعالية، مما يوفر دعمًا ومساعدة سلسة للعملاء.
- أنظمة الترجمة: بفضل قدراته في الفهم متعدد اللغات، يمكن استخدام Mixtral-8x22B لبناء أنظمة ترجمة تترجم النص بدقة بين اللغات المختلفة.
- توليد الكود: قدرات توليد الكود القوية لـ Mixtral-8x22B تجعله خيارًا مثاليًا لتطوير الأنظمة التي يمكنها إنشاء أجزاء من الكود تلقائيًا بناءً على متطلبات المستخدم.
هذه مجرد أمثلة قليلة لكيفية تطبيق Mixtral-8x22B في السيناريوهات الواقعية. كفاءته التشغيلية وقدراته عالية الأداء تجعله أصلًا قيمًا للشركات والباحثين الذين يحتاجون إلى حلول متقدمة لمعالجة اللغة.
الكفاءة التشغيلية لـ Mixtral-8x22B
الكفاءة التشغيلية هي عامل رئيسي في أداء النماذج اللغوية الكبيرة. صُمم Mixtral-8x22B مع التركيز على الكفاءة التشغيلية، مما يوفر فوائد كبيرة من حيث التحكم في التكلفة وزمن الاستجابة. يستخدم النموذج بنية خبراء مختلطين متناثرين (SMoE)، والتي تسمح بتحكم أفضل في التكلفة وزمن الاستجابة باستخدام جزء صغير من إجمالي مجموعة المعلمات لكل رمز أثناء الاستدلال. يضمن هذا النهج أن Mixtral-8x22B يقدم نتائج عالية الجودة مع تحسين استخدام الموارد من خلال تحسين التفضيل المباشر. الكفاءة التشغيلية لـ Mixtral-8x22B، جنبًا إلى جنب مع قالب الدردشة المتقدم، تجعله خيارًا مثاليًا للتطبيقات التي تتطلب قدرات معالجة لغة سريعة وفعالة من حيث التكلفة.
السرعة وكفاءة التكلفة في الاستدلال
إحدى المزايا الرئيسية لـ Mixtral-8x22B هي سرعته وكفاءته من حيث التكلفة أثناء الاستدلال. باستخدام بنية الخبراء المختلطين المتناثرين (SMoE)، يستطيع Mixtral-8x22B معالجة النص وتوليده بمعدل أسرع مقارنة بالنماذج اللغوية الكبيرة الأخرى. تترجم ميزة السرعة هذه إلى كفاءة في التكلفة، حيث يلزم عدد أقل من الموارد لتحقيق نفس المستوى من الأداء. يساهم استخدام المعلمات النشطة، حيث يتم استخدام جزء صغير فقط من إجمالي مجموعة المعلمات لكل رمز، في كفاءة التكلفة للنموذج الأساسي Mixtral-8x22B. تجعل هذه العوامل Mixtral-8x22B خيارًا جذابًا للتطبيقات التي تتطلب قدرات معالجة لغة سريعة وفعالة من حيث التكلفة.
التنقل عبر اختيار الخبراء أثناء الاستدلال
أثناء عملية الاستدلال، يتنقل Mixtral-8x22B عبر اختيار الخبراء لمعالجة كل رمز. شبكة التوجيه، وهي مكون رئيسي في البنية، مسؤولة عن اختيار خبيرين من كل مجموعة معلمات للتعامل مع كل رمز. يعتمد اختيار الخبراء على تفضيلات شبكة التوجيه، التي تحدد أنسب الخبراء لكل رمز. يسمح هذا التنقل عبر اختيار الخبراء لـ Mixtral-8x22B بالاستفادة من نقاط القوة والخبرة لشبكات مختلفة، مما يؤدي إلى توليد نص دقيق وعالي الجودة. تلعب شبكة التوجيه دورًا حاسمًا في ضمان قدرة الخبراء المختارين على معالجة كل رمز بفعالية والمساهمة في الأداء العام لـ Mixtral-8x22B أثناء الاستدلال.
دليل المستخدم: تنفيذ Mixtral-8x22B
تنفيذ Mixtral-8x22B في مشاريعك هو عملية مباشرة تتطلب بضع خطوات رئيسية. إليك دليل مستخدم لمساعدتك على البدء مع Mixtral-8x22B:
- البدء مع Mixtral-8x22B: تعرف على الوثائق والموارد التي تقدمها Mistral AI. ستوجهك هذه الموارد خلال عملية التنفيذ وتوفر رؤى قيمة حول قدرات Mixtral-8x22B.
- أفضل الممارسات لدمج Mixtral-8x22B: اتبع أفضل الممارسات لدمج Mixtral-8x22B في قاعدة التعليمات البرمجية الخاصة بك. يتضمن ذلك تحسين استخدام الموارد، ومعالجة تنسيقات الإدخال والإخراج، والاستفادة من قدرات Mixtral-8x22B لتحقيق النتائج المرجوة.
باتباع هذه الخطوات، يمكنك تنفيذ Mixtral-8x22B بنجاح في مشاريعك والاستفادة من قدراته القوية في معالجة اللغة.
البدء مع Mixtral-8x22B
البدء مع Mixtral-8x22B هو عملية بسيطة تتضمن التعرف على الوثائق والموارد التي تقدمها Mistral AI. ستوجهك الوثائق خلال تثبيت واستخدام Mixtral-8x22B، بما في ذلك استخدام PEFT (الضبط الدقيق القائم على التفضيل) لتحسين أداء النموذج.
بالإضافة إلى ذلك، توفر Mistral AI نماذج مدربة مسبقًا يمكنك استخدامها مباشرة، مما يسمح لك بدمج Mixtral-8x22B بسرعة في مشاريعك. من خلال الرجوع إلى وثائق التكوين واستخدام النماذج المدربة مسبقًا، يمكنك بسهولة البدء مع Mixtral-8x22B والبدء في الاستفادة من قدراته القوية في معالجة اللغة. تأكد أيضًا من التعرف على فئات تكوين PEFT وفئات النموذج الأساسي لفهم أفضل لكيفية عمل PEFT في نماذج NeMo.
علاوة على ذلك، فإن فهم قدرات التصنيف لـ Mixtral-8x22B أمر بالغ الأهمية لاستخدام إمكاناته الكاملة في مهام معالجة اللغة المختلفة.
أفضل الممارسات لدمج Mixtral-8x22B
يتطلب دمج Mixtral-8x22B في مشاريعك اتباع أفضل الممارسات لضمان الأداء الأمثل وسهولة الاستخدام. فيما يلي بعض أفضل الممارسات الرئيسية لدمج Mixtral-8x22B:
- تحسين استخدام الموارد: تأكد من تحسين استخدام الموارد من خلال إدارة الذاكرة والموارد الحسابية بكفاءة. سيساعد ذلك في تحسين أداء وكفاءة Mixtral-8x22B في تطبيقاتك.
- معالجة تنسيقات الإدخال والإخراج: افهم تنسيقات الإدخال والإخراج المتوقعة من قبل Mixtral-8x22B وتأكد من أن تطبيقك يمكنه التعامل معها بشكل مناسب. يتضمن ذلك معالجة بيانات الإدخال مسبقًا ومعالجة النص المولد لاحقًا.
- الاستفادة من قدرات Mixtral-8x22B: استكشف واستخدم القدرات المختلفة لـ Mixtral-8x22B، مثل التفكير الرياضي وتوليد الكود والفهم متعدد اللغات. سيسمح لك ذلك بالاستفادة الكاملة من قوة Mixtral-8x22B في تطبيقاتك.
باتباع أفضل الممارسات هذه، يمكنك دمج Mixtral-8x22B بسلاسة في مشاريعك وإطلاق العنان لإمكاناته الكاملة.
فروع عائلة نماذج Mixtral
كما قدمنا نموذج Mixtral-8x22B، هناك فرعين آخرين لعائلة نماذج Mixtral - Mistral 7B و Mixtral 8x7B.
Mistral 7B
اتخذت Mistral AI نهجًا مميزًا مع نموذجها الأولي Mistral 7B، حيث اختارت عدم التنافس مباشرة مع النماذج الأكبر مثل GPT-4. بدلاً من ذلك، تم تدريبه على مجموعة بيانات أصغر تضم 7 مليارات معلمة، مما يقدم عرضًا فريدًا في مجال نماذج الذكاء الاصطناعي. في محاولة لتأكيد إمكانية الوصول، جعلت Mistral AI هذا النموذج متاحًا للتنزيل مجانًا، مما يتيح للمطورين دمجه في أنظمتهم الخاصة. Mistral 7B هو نموذج لغوي مضغوط يأتي بتكلفة أقل بكثير مقارنة بالنماذج مثل GPT-4. بينما يفتخر GPT-4 بقدرات أوسع من هذه النماذج الأصغر، إلا أنه ينطوي أيضًا على نفقات أعلى وتعقيد في التشغيل.
Mixtral 8x7B
فيما يلي أبرز النقاط الرئيسية لـ Mixtral:
- يعالج السياق بما يصل إلى 32 ألف رمز.
- يدعم اللغات الإنجليزية والفرنسية والإيطالية والألمانية والإسبانية.
- يظهر Mixtral كفاءة في مهام البرمجة.
- مع الضبط الدقيق، يمكن أن يتحول إلى نموذج يتبع التعليمات، محققًا درجة MT-Bench تبلغ 8.3.
يتكامل النموذج بسلاسة مع أدوات التحسين المعروفة مثل Flash Attention 2 و bitsandbytes ومكتبات PEFT. نقاط التفتيش الخاصة به متاحة تحت منظمة mistralai على Hugging Face Hub.
كيفية اختيار النموذج المناسب لعملك
ضع في اعتبارك ما يلي عند اتخاذ قرارك:
- الاستخدام المقصود: فكر في الأنشطة التي ستستخدم النموذج من أجلها بشكل أساسي. قد تتطلب الأنشطة المختلفة ميزات مختلفة مثل قوة التكبير ومجال الرؤية والأداء في الإضاءة المنخفضة.
- قابلية النقل: إذا كنت ستحمل النموذج لفترات طويلة أو تسافر بشكل متكرر، فقد تفضل خيارًا أخف وزناً وأكثر إحكاما.
- الميزانية: قارن أسعار كل نموذج وفكر في الميزات الأكثر أهمية بالنسبة لك بالنسبة للتكلفة.
- المراجعات والتوصيات: ابحث عن مراجعات أو اطلب توصيات من الأصدقاء أو العائلة أو المجتمعات عبر الإنترنت الذين لديهم خبرة مع هذه النماذج المحددة. يمكنهم تقديم رؤى قيمة حول الأداء والمتانة في العالم الحقيقي.
تم تجهيز واجهة برمجة تطبيقات LLM الخاصة بنا بنماذج Mistral 7B و Mixtral 8x7B:

من ناحية أخرى، فإن واجهة برمجة تطبيقات LLM من novita.ai، والتي يمكن أن تتكامل بسلاسة مع نماذج LLM الخاصة بك. بفضل التسعير الأرخص والنماذج القابلة للتوسع، تعمل واجهة استدلال LLM من Novita AI على تمكين نموذج LLM الخاص بك من استقرار لا يصدق وزمن وصول منخفض إلى حد ما في أقل من ثانيتين.

الخلاصة
في الختام، يبشر Mixtral-8x22B بعصر جديد في مجال النماذج اللغوية الكبيرة بميزاته الرائدة وكفاءته التشغيلية. من خلال بنيته المتطورة، بما في ذلك مفهوم الخبراء المختلطين المبتكر، يُظهر Mixtral-8x22B أداءً فائقًا مقارنة بنظرائه، كما هو موضح في التطبيقات الواقعية المختلفة والمعايير. يسهل دليل المستخدم التنفيذ السلس، مع التركيز على السرعة وكفاءة التكلفة أثناء الاستدلال. ستستفيد الشركات بشكل كبير من القدرات التحويلية لـ Mixtral-8x22B، مما يضع معايير جديدة لتكنولوجيا النماذج اللغوية. ترقبوا التحديثات المستقبلية وخريطة طريق مثيرة تعد بتعزيزات وتحسينات مستمرة في هذا الحل المتطور.
الأسئلة الشائعة
ما الذي يميز Mixtral-8x22B عن نماذج LLM الأخرى؟
يتميز Mixtral-8x22B بهندسته ونهجه الفريدين. يستخدم النموذج تقنية الخبراء المختلطين المتناثرين (SMoE)، حيث تتكون كل طبقة من مجموعات متميزة من المعلمات.
كيف يمكن للشركات الاستفادة من Mixtral-8x22B؟
يوفر النموذج كفاءة في التكلفة باستخدام جزء صغير من إجمالي مجموعة المعلمات لكل رمز أثناء الاستدلال. يسمح ذلك للشركات بتحقيق نتائج عالية الجودة مع تحسين استخدام الموارد وخفض التكاليف.
التحديثات المستقبلية وخريطة الطريق لـ Mixtral-8x22B
يلتزم فريق التطوير بتحسين أداء النموذج وقدراته باستمرار بناءً على ملاحظات المستخدمين. يمكن للمستخدمين توقع تحديثات وإضافات منتظمة لزيادة تعزيز تنوع وكفاءة Mixtral-8x22B.
novita.ai هي المنصة الشاملة للإبداع غير المحدود التي تمنحك الوصول إلى أكثر من 100 واجهة برمجة تطبيقات. من إنشاء الصور ومعالجة اللغة إلى تحسين الصوت ومعالجة الفيديو، نموذج الدفع حسب الاستخدام الرخيص، يحررك من متاعب صيانة GPU أثناء بناء منتجاتك الخاصة. جربها مجانًا.
قراءة موصى بها
محرك استدلال LLM من Novita AI: أكبر إنتاجية وأرخص استدلال متاح



