

- Введение
- Представляем Mixtral-8x22B: новую эру больших языковых моделей
- Погружение в архитектуру Mixtral-8x22B
- Производительность и возможности Mixtral
- Операционная эффективность Mixtral-8x22B
- Руководство пользователя: внедрение Mixtral-8x22B
- Лучшие практики интеграции Mixtral-8x22B
- Ветви семейства моделей Mixtral
- Заключение
- Часто задаваемые вопросы
Изучите Mixtral-8x22B и другие ветви семейства моделей Mixtral в нашем блоге.
Введение
В мире NLP большие языковые модели стали основой для различных задач обработки естественного языка. Эти модели предназначены для понимания и генерации человекоподобного текста, что делает их ценным инструментом для таких приложений, как чат-боты, системы перевода и генерация кода. Mistral AI, ведущая исследовательская лаборатория в области ИИ, недавно представила Mixtral-8x22B — самую новую и крупную смесь экспертных больших языковых моделей (LLM), которая расширяет границы открытых моделей.
Mixtral-8x22B — это разреженная смесь экспертов (SMoE), которая обеспечивает превосходную производительность и экономическую эффективность по сравнению с другими LLM. Она превосходит Llama 2 70B с шестикратным ускорением вывода и сравнивается или даже превосходит GPT-3.5 по различным бенчмаркам. Эта модель распространяется под лицензией Apache 2.0, что делает её доступной для разработчиков и исследователей.
Имея 47 миллиардов параметров, Mixtral-8x22B — мощная языковая модель, способная справляться со сложными задачами, такими как математические рассуждения, генерация кода и многоязычное понимание. Она поддерживает такие языки, как английский, французский, итальянский, немецкий и испанский, что делает её универсальным инструментом для глобальных приложений. Кроме того, Mixtral-8x22B может обрабатывать контекстное окно из 32 000 токенов, что позволяет ей обрабатывать и генерировать текст с длинными и сложными промптами, используя передовые технологии GPU.
Представляем Mixtral-8x22B: новую эру больших языковых моделей
Mixtral-8x22B представляет собой новый стандарт в области больших языковых моделей. Благодаря своей передовой архитектуре и впечатляющей производительности она устанавливает новый ориентир для возможностей и эффективности языковых моделей.
Разработанная компанией Mistral AI, Mixtral-8x22B предлагает новый подход к языковому моделированию, используя технику разреженной смеси экспертов (SMoE). Эта инновационная архитектура позволяет лучше контролировать стоимость и задержку, сохраняя при этом исключительные результаты. Выпущенная в декабре 2023 года, Mixtral-8x22B является последним и крупнейшим дополнением к семейству моделей Mixtral, представляя концепцию «микстраль экспертов» и принося с собой множество улучшений, которые ещё больше повышают её производительность и возможности.
История создания Mixtral-8x22B
Разработка Mixtral-8x22B стала результатом обширных исследований и сотрудничества в сообществе ИИ. Mistral AI вместе с командой талантливых исследователей и инженеров, включая Уильяма Эль Сайеда, отправились в путешествие по созданию языковой модели, которая раздвинула бы границы возможного в области обработки естественного языка.
Создание Mixtral-8x22B включало исследование новых архитектур и техник, а также анализ больших наборов данных для обучения модели. Сообщество ИИ сыграло решающую роль в этом процессе: исследователи и разработчики делились своим опытом и знаниями для совершенствования модели. Результатом стала передовая языковая модель, представляющая собой кульминацию многолетних исследований и разработок. Mixtral-8x22B — это свидетельство силы сотрудничества и инноваций в области ИИ.
Ключевые компоненты Mixtral-8x22B
Модель Mixtral-8x22B состоит из нескольких ключевых компонентов, которые работают вместе, обеспечивая её исключительную производительность. К ним относятся:
- Модель Mixtral: Mixtral-8x22B — это разреженная смесь экспертов (SMoE), то есть она использует комбинацию различных экспертных сетей для обработки и генерации текста.
- Маршрутизирующая сеть: На каждом уровне модели Mixtral маршрутизирующая сеть выбирает двух экспертов из набора различных групп параметров для обработки каждого токена.
- Активные параметры: Хотя Mixtral-8x22B имеет в общей сложности 47 миллиардов параметров, во время логического вывода используется только 13 миллиардов параметров на токен, что обеспечивает лучший контроль стоимости и задержки.
- Аддитивная комбинация: Выходные данные, полученные от экспертных сетей, комбинируются аддитивно, в результате чего получается взвешенная сумма, представляющая выходные данные всего модуля смеси экспертов.
Эти ключевые компоненты позволяют Mixtral-8x22B эффективно обрабатывать и генерировать текст, предоставляя пользователям точные и высококачественные результаты. Архитектура Mixtral-8x22B спроектирована так, чтобы оптимизировать как производительность, так и эффективность, что делает её мощным инструментом для широкого круга задач обработки языка.
Погружение в архитектуру Mixtral-8x22B
Архитектура Mixtral-8x22B основана на концепции смеси экспертов, а именно на разреженной модели смеси экспертов (SMoE). Эта модель типа decoder-only использует маршрутизирующую сеть для выбора двух экспертов из каждого из 8 различных групп параметров для обработки каждого токена. Выходные данные выбранных экспертов затем комбинируются аддитивно для получения конечного результата. Такая архитектура позволяет Mixtral-8x22B расширять границы открытых моделей и достигать передовой производительности и точности.
Понимание смеси экспертов (MoE)
Смесь экспертов (MoE) — это техника моделирования, которая объединяет выходные данные нескольких экспертных сетей для генерации текста. В контексте Mixtral-8x22B архитектура MoE используется для использования сильных сторон и опыта различных сетей для обработки и генерации точного и качественного текста. Маршрутизирующая сеть играет решающую роль в этой архитектуре, выбирая двух экспертов из каждого набора параметров для обработки каждого токена.
Этот выбор основан на оптимизации предпочтений маршрутизатора, который определяет наиболее подходящих экспертов для каждого токена. Аддитивно комбинируя выходные данные выбранных экспертов, Mixtral-8x22B способна генерировать текст, отражающий коллективные знания и опыт экспертных сетей, что приводит к превосходной производительности и точности.
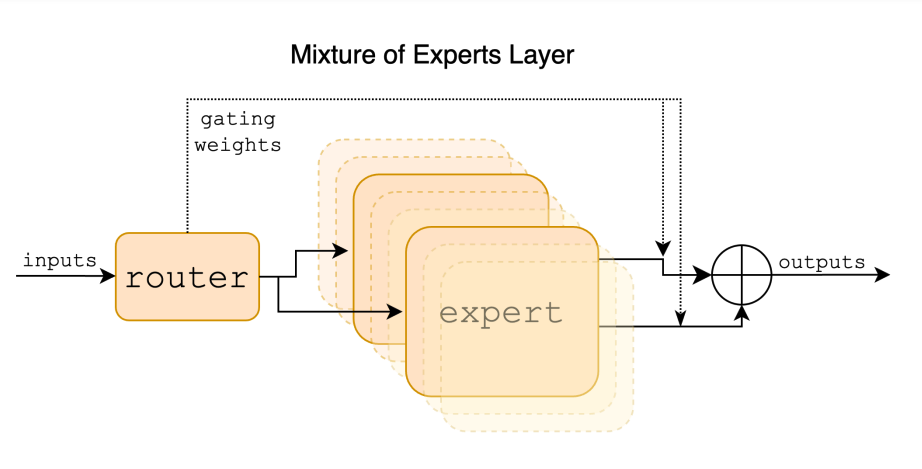
Роль моделей 22B в Mixtral-8x22B
Модели 22B играют решающую роль в производительности Mixtral-8x22B. Эти модели отвечают за предоставление опыта и знаний, необходимых для генерации точного и качественного текста. Используя сильные стороны и возможности моделей 22B, Mixtral-8x22B способна обеспечивать превосходную производительность в широком спектре задач обработки языка.
Модели 22B вносят вклад в общую производительность Mixtral-8x22B, предоставляя специализированные знания и опыт в конкретных областях, таких как генерация кода, математические рассуждения и многоязычное понимание. Такое сочетание опыта позволяет Mixtral-8x22B генерировать точный и контекстуально релевантный текст, что делает её мощным инструментом для разработчиков и исследователей в области обработки естественного языка.
Производительность и возможности Mixtral
Mixtral-8x22B демонстрирует высокую производительность в широком спектре бенчмарков и задач обработки языка. Она превосходит Llama 2 70B по нескольким бенчмаркам, включая BBQ (Bias Benchmark for QA), и сравнивается или даже превосходит GPT-3.5 — широко признанную большую языковую модель. Производительность модели особенно заметна в таких областях, как математические рассуждения, генерация кода и многоязычное понимание. Она была обучена на огромном объёме открытых веб-данных и показала исключительные результаты при решении сложных задач. Благодаря впечатляющей производительности и универсальным возможностям, Mixtral-8x22B, работающая на библиотеке PyTorch, готова стать предпочтительным выбором для разработчиков и исследователей в области обработки естественного языка.
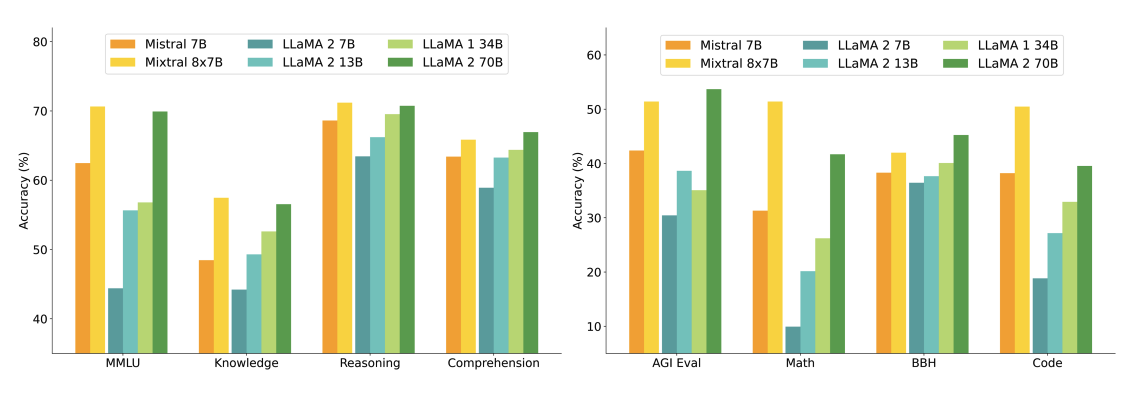
На диаграмме ниже показано сравнение производительности с моделями Llama 2 различного размера по более широкому спектру возможностей и бенчмарков. Mixtral сравнивается или превосходит Llama 2 70B, демонстрируя превосходные результаты в математике и генерации кода.
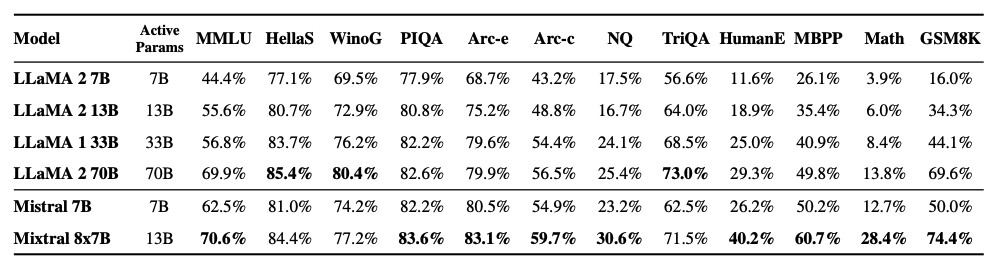
Как показано на рисунке ниже, Mixtral 8x7B также превосходит или сравнивается с моделями Llama 2 по различным популярным бенчмаркам, таким как MMLU и GSM8K. Эти результаты достигаются при использовании в 5 раз меньшего количества активных параметров во время логического вывода.
На рисунке ниже показан компромисс между качеством и бюджетом логического вывода. Mixtral превосходит Llama 2 70B по нескольким бенчмаркам, используя в 5 раз меньше активных параметров.
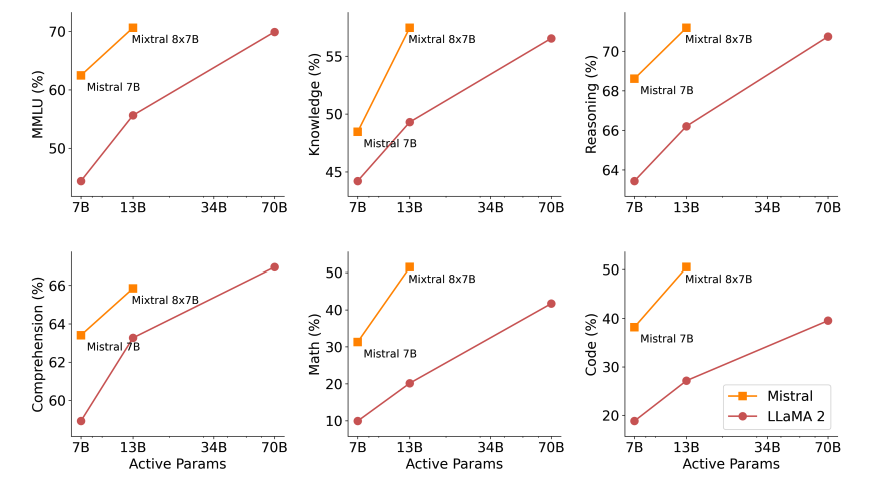
Сравнение Mixtral-8x22B с другими LLM по бенчмаркам
Mixtral-8x22B была протестирована в сравнении с несколькими другими большими языковыми моделями (LLM) для оценки её производительности и возможностей. Результаты этих тестов демонстрируют превосходную производительность Mixtral-8x22B в различных задачах обработки языка. Ниже приведено сравнение Mixtral-8x22B с другими LLM по различным стандартным бенчмаркам:

Эти результаты бенчмарков чётко показывают высокую производительность Mixtral-8x22B по сравнению с другими LLM. Её способность справляться со сложными задачами и давать точные результаты выделяет её как ведущий выбор для разработчиков и исследователей в области обработки естественного языка.
Реальные приложения и примеры использования
Mixtral-8x22B имеет множество реальных приложений в различных отраслях и сферах. Её универсальность и мощные возможности делают её ценным инструментом для широкого круга задач. Вот несколько примеров реальных приложений Mixtral-8x22B:
- Чат-боты: Mixtral-8x22B можно использовать для разработки чат-ботов, которые могут эффективно понимать и отвечать на человеческие диалоги, обеспечивая бесшовную поддержку клиентов и помощь.
- Системы перевода: Благодаря своим возможностям многоязычного понимания, Mixtral-8x22B может использоваться для создания систем перевода, которые точно переводят текст между разными языками.
- Генерация кода: Мощные возможности генерации кода делают Mixtral-8x22B идеальным выбором для разработки систем, которые могут автоматически генерировать фрагменты кода на основе требований пользователя.
Это лишь несколько примеров того, как Mixtral-8x22B может применяться в реальных сценариях. Её операционная эффективность и высокая производительность делают её ценным активом для бизнеса и исследователей, нуждающихся в передовых решениях для обработки языка.
Операционная эффективность Mixtral-8x22B
Операционная эффективность — ключевой фактор производительности больших языковых моделей. Mixtral-8x22B была спроектирована с акцентом на операционную эффективность, предлагая значительные преимущества с точки зрения контроля стоимости и задержки. Модель использует архитектуру разреженной смеси экспертов (SMoE), которая позволяет лучше контролировать стоимость и задержку, используя только часть общего набора параметров на токен во время логического вывода. Такой подход гарантирует, что Mixtral-8x22B выдаёт высококачественные результаты, оптимизируя использование ресурсов с помощью прямой оптимизации предпочтений. Операционная эффективность Mixtral-8x22B в сочетании с продвинутым шаблоном чата делает её идеальным выбором для приложений, требующих быстрой и экономичной обработки языка.
Скорость и экономическая эффективность при логическом выводе
Одним из ключевых преимуществ Mixtral-8x22B является её скорость и экономическая эффективность при логическом выводе. Используя архитектуру разреженной смеси экспертов (SMoE), Mixtral-8x22B способна обрабатывать и генерировать текст быстрее по сравнению с другими большими языковыми моделями. Это преимущество в скорости приводит к экономической эффективности, поскольку для достижения того же уровня производительности требуется меньше ресурсов. Использование активных параметров, когда только часть общего набора параметров используется на токен, также способствует экономической эффективности базовой модели Mixtral-8x22B. Эти факторы делают Mixtral-8x22B привлекательным выбором для приложений, требующих быстрой и экономичной обработки языка.
Навигация по выбору экспертов во время логического вывода
Во время логического вывода Mixtral-8x22B осуществляет навигацию по выбору экспертов для обработки каждого токена. Маршрутизирующая сеть — ключевой компонент архитектуры — отвечает за выбор двух экспертов из каждого набора параметров для обработки каждого токена. Выбор экспертов основан на предпочтениях маршрутизирующей сети, которая определяет наиболее подходящих экспертов для каждого токена. Эта навигация по выбору экспертов позволяет Mixtral-8x22B использовать сильные стороны и опыт различных сетей, что приводит к точной и качественной генерации текста. Маршрутизирующая сеть играет решающую роль в обеспечении того, чтобы выбранные эксперты могли эффективно обрабатывать каждый токен и вносить вклад в общую производительность Mixtral-8x22B во время логического вывода.
Руководство пользователя: внедрение Mixtral-8x22B
Внедрение Mixtral-8x22B в ваши проекты — это простой процесс, состоящий из нескольких ключевых шагов. Вот руководство, которое поможет вам начать работу с Mixtral-8x22B:
- Начало работы с Mixtral-8x22B: Ознакомьтесь с документацией и ресурсами, предоставленными Mistral AI. Эти ресурсы помогут вам в процессе внедрения и предоставят ценную информацию о возможностях Mixtral-8x22B.
- Лучшие практики интеграции Mixtral-8x22B: Следуйте лучшим практикам интеграции Mixtral-8x22B в вашу кодовую базу. Это включает оптимизацию использования ресурсов, обработку форматов ввода и вывода, а также использование возможностей Mixtral-8x22B для достижения желаемых результатов.
Следуя этим шагам, вы сможете успешно внедрить Mixtral-8x22B в свои проекты и использовать её мощные возможности обработки языка.
Начало работы с Mixtral-8x22B
Начало работы с Mixtral-8x22B — это простой процесс, который включает ознакомление с документацией и ресурсами, предоставленными Mistral AI. Документация проведёт вас через установку и использование Mixtral-8x22B, включая использование PEFT (Preference-based Fine-tuning) для оптимизации производительности модели.
Кроме того, Mistral AI предоставляет предварительно обученные модели, которые вы можете использовать сразу, что позволяет быстро интегрировать Mixtral-8x22B в ваши проекты. Обращаясь к конфигурации и документации и используя предварительно обученные модели, вы легко сможете начать работу с Mixtral-8x22B и начать использовать её мощные возможности обработки языка. Также обязательно ознакомьтесь с классами конфигурации PEFT и классами базовых моделей для лучшего понимания того, как PEFT работает в моделях NeMo.
Кроме того, понимание классификационных возможностей Mixtral-8x22B имеет решающее значение для полного использования её потенциала в различных задачах обработки языка.
Лучшие практики интеграции Mixtral-8x22B
Интеграция Mixtral-8x22B в ваши проекты требует соблюдения лучших практик для обеспечения оптимальной производительности и удобства использования. Вот несколько ключевых рекомендаций по интеграции Mixtral-8x22B:
- Оптимизируйте использование ресурсов: Убедитесь, что вы оптимизируете использование ресурсов, эффективно управляя памятью и вычислительными ресурсами. Это поможет повысить производительность и эффективность Mixtral-8x22B в ваших приложениях.
- Обрабатывайте форматы ввода и вывода: Понимайте форматы ввода и вывода, ожидаемые Mixtral-8x22B, и убедитесь, что ваше приложение может их правильно обрабатывать. Это включает предварительную обработку входных данных и постобработку сгенерированного текста.
- Используйте возможности Mixtral-8x22B: Изучите и используйте различные возможности Mixtral-8x22B, такие как математические рассуждения, генерация кода и многоязычное понимание. Это позволит вам полностью использовать мощь Mixtral-8x22B в ваших приложениях.
Следуя этим лучшим практикам, вы сможете легко интегрировать Mixtral-8x22B в свои проекты и раскрыть её полный потенциал.
Ветви семейства моделей Mixtral
Как мы уже представили модель Mixtral-8x22B, существуют ещё две ветви семейства моделей Mixtral — Mistral 7B и Mixtral 8x7B.
Mistral 7B
Mistral AI применила иной подход к своей первоначальной модели Mistral 7B, решив не конкурировать напрямую с более крупными аналогами, такими как GPT-4. Вместо этого она была обучена на меньшем наборе данных, состоящем из 7 миллиардов параметров, что представляет собой уникальное предложение в области моделей ИИ. В стремлении подчеркнуть доступность Mistral AI сделала эту модель доступной для бесплатного скачивания, что позволяет разработчикам интегрировать её в свои собственные системы. Mistral 7B — это компактная языковая модель, которая стоит значительно дешевле по сравнению с такими моделями, как GPT-4. В то время как GPT-4 обладает более широкими возможностями, чем подобные небольшие модели, она также требует более высоких затрат и сложности в эксплуатации.
Mixtral 8x7B
Вот ключевые особенности Mixtral:
- Обрабатывает контекст до 32 000 токенов.
- Поддерживает английский, французский, итальянский, немецкий и испанский языки.
- Mixtral демонстрирует навыки в задачах программирования.
- После точной настройки может превратиться в модель, следующую инструкциям, с оценкой MT-Bench 8.3.
Модель легко интегрируется с известными инструментами оптимизации, такими как Flash Attention 2, bitsandbytes и библиотеки PEFT. Её контрольные точки доступны в организации mistralai на Hugging Face Hub.
Как выбрать подходящую модель для вашего бизнеса
При принятии решения учитывайте следующее:
- Предполагаемое использование: Подумайте, для каких задач вы будете в первую очередь использовать модель. Разные задачи могут требовать разных функций, таких как мощность, объём контекста и производительность при работе с несколькими языками.
- Портативность: Если вы будете использовать модель в течение длительного времени или часто перемещаться, возможно, вы отдадите предпочтение более лёгкому и компактному варианту.
- Бюджет: Сравните цены каждой модели и определите, какие функции наиболее важны для вас относительно стоимости.
- Отзывы и рекомендации: Поищите отзывы или обратитесь за рекомендациями к друзьям, коллегам или онлайн-сообществам, имеющим опыт работы с этими конкретными моделями. Они могут предоставить ценную информацию о реальной производительности и надёжности.
Наш LLM API оснащён как моделями Mistral 7B, так и Mixtral 8x7B:

С другой стороны, novita.ai LLM API легко интегрируется с вашими LLM. Благодаря самым низким ценам и масштабируемым моделям, Novita AI LLM Inference API обеспечивает невероятную стабильность и довольно низкую задержку — менее 2 секунд.

Заключение
В заключение, Mixtral-8x22B знаменует собой новую эру в области больших языковых моделей благодаря своим революционным функциям и операционной эффективности. Благодаря своей сложной архитектуре, включающей инновационную концепцию смеси экспертов, Mixtral-8x22B демонстрирует превосходную производительность по сравнению с аналогами, что подтверждается различными реальными приложениями и бенчмарками. Руководство пользователя облегчает беспрепятственное внедрение, подчёркивая скорость и экономическую эффективность при логическом выводе. Бизнес может получить огромную выгоду от трансформационных возможностей Mixtral-8x22B, устанавливая новые стандарты для технологии языковых моделей. Следите за будущими обновлениями и захватывающей дорожной картой, которая обещает непрерывные улучшения и усовершенствования этого передового решения.
Часто задаваемые вопросы
Что отличает Mixtral-8x22B от других LLM?
Mixtral-8x22B выделяется благодаря своей уникальной архитектуре и подходу. Модель использует технику разреженной смеси экспертов (SMoE), где каждый уровень состоит из различных групп параметров.
Как бизнес может извлечь выгоду из Mixtral-8x22B?
Модель обеспечивает экономическую эффективность, используя только часть общего набора параметров на токен во время логического вывода. Это позволяет бизнесу достигать высококачественных результатов, оптимизируя использование ресурсов и снижая затраты.
Будущие обновления и дорожная карта для Mixtral-8x22B
Команда разработчиков стремится постоянно улучшать производительность и возможности модели на основе отзывов пользователей. Пользователи могут ожидать регулярных обновлений и дополнений, которые ещё больше повысят универсальность и эффективность Mixtral-8x22B.
novita.ai — универсальная платформа для безграничного творчества, предоставляющая доступ к 100+ API. От генерации изображений и обработки языка до улучшения аудио и манипуляций с видео — недорогая модель оплаты по мере использования освобождает вас от хлопот с обслуживанием GPU при создании собственных продуктов. Попробуйте бесплатно.
Рекомендуемое чтение
Novita AI LLM Inference Engine: максимальная пропускная способность и самый дешёвый вывод



