

Wichtige Highlights
Riesiges Kontextfenster: Unterstützt bis zu 1 Million Token – ideal für lange Dokumente, Codebasen oder Bücher.
Multimodale Unterstützung: Verarbeitet Text- und Bildeingaben gleichzeitig.
Mehrsprachige Stärke: Vortrainiert in 200 Sprachen, mit starken mehrsprachigen MMLU-Werten (84,6), was es zu einem weltweit einsetzbaren Modell macht.
Kosteneffizient: Bietet hochmoderne Leistung zu einem Bruchteil des Preises von GPT-4o (0,2 $ auf Novita AI gegenüber 4,38 $ pro Million Token).
Llama 4 Maverick ist das neueste Open-Source-Sprachmodell von Meta, veröffentlicht am 5. April 2025. Es basiert auf einer 128-Mixture-of-Experts (MoE)-Architektur und wurde mit 22 Billionen Token multimodaler Daten trainiert. Es ist für Leistung, Flexibilität und globale Skalierung ausgelegt. Mit einer Kontextlänge von bis zu 10 Millionen Token, Unterstützung für Text- und Bildeingaben sowie überlegener Leistung in mehrsprachigen und logischen Benchmarks.
Was ist Llama 4 Maverick?
https://www.youtube.com/watch?v=8G-GI4bvWZU
Llama 4 Maverick Übersicht
| Kategorie | Details |
|---|---|
| Veröffentlichungsdatum | 5. April 2025 |
| Modellgröße | 400B Parameter (17B aktiv pro Token) |
| Open Source | Ja |
| Architektur | 128 Mixture-of-Experts (MoE) |
| Kontextlänge | Bis zu 1M Token (1.000.000 Token) |
| Sprachunterstützung | Vortrainiert in 200 Sprachen, darunter Arabisch, Englisch, Französisch, Deutsch, Hindi, Indonesisch, Italienisch, Portugiesisch, Spanisch, Tagalog, Thailändisch und Vietnamesisch. |
| Multimodale Fähigkeit | Kombiniert Text- und Bildeingaben und unterstützt sowohl textuelle als auch visuelle Inhaltsverarbeitung. |
| Trainingsdaten | ~22 Billionen Token multimodaler Daten (teilweise von Instagram und Facebook). |
| Vor-Training | MetaP (Adaptive Expert Configuration mit Mid-Training-Optimierung). |
| Nach-Training-Schritte | 1. SFT (Supervised Fine-Tuning auf einfachen Daten). |
| 2. RL (Reinforcement Learning auf schwierigen Daten). | |
| 3. DPO (Direct Preference Optimization). |
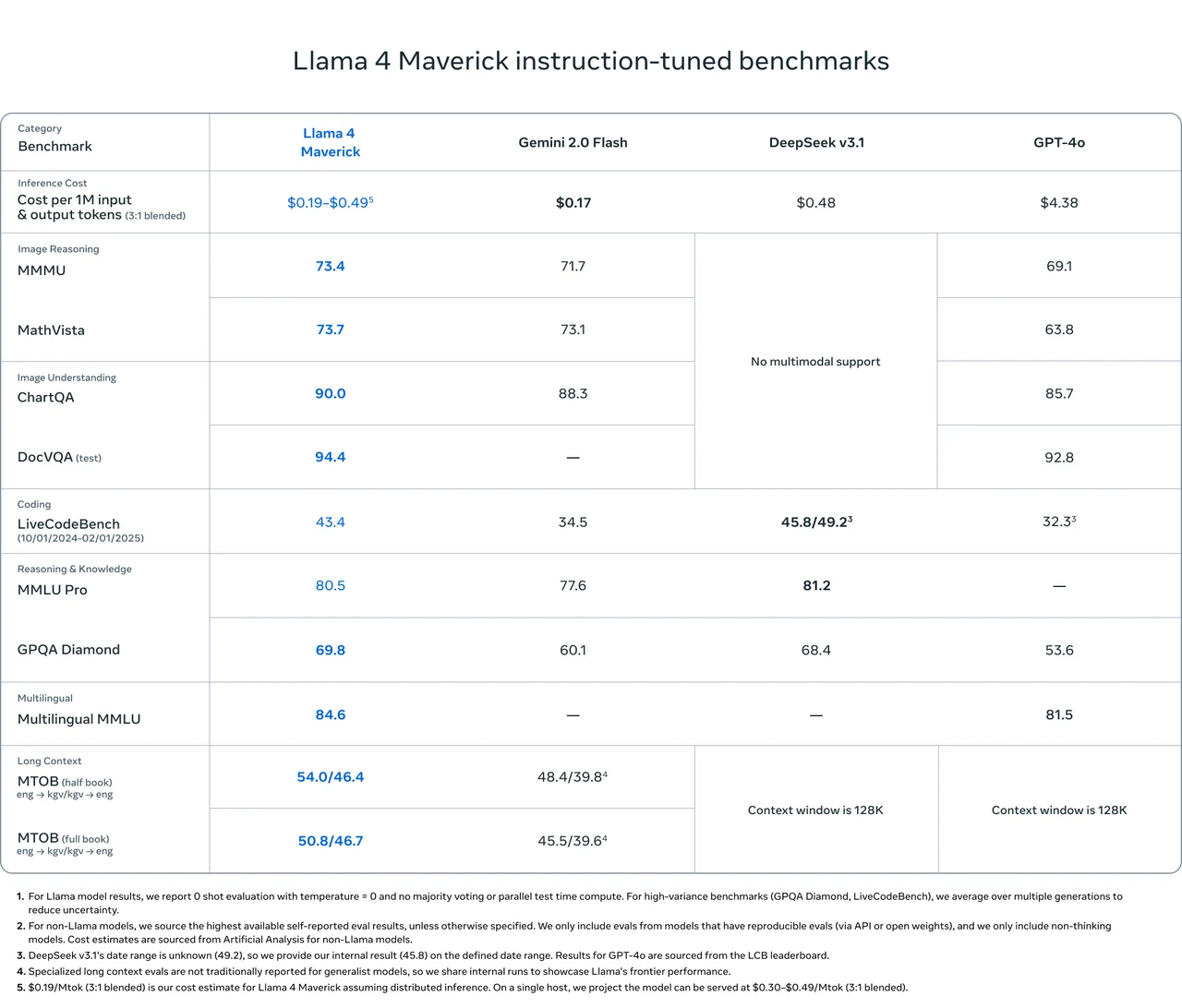
Llama 4 Maverick Benchmark
Llama 4 Maverick übertrifft Gemini 2.0 Flash, DeepSeek v3.1 und GPT-4o in mehreren wichtigen Benchmarks, insbesondere in Bildlogik, Bildverständnis und mehrsprachigen Aufgaben.
Wie greift man lokal auf Llama 4 Maverick zu?
Llama 4 Maverick Hardware-Anforderungen
| Kontextlänge | INT4 VRAM | GPU-Bedarf (INT4) | FP16 VRAM | GPU-Bedarf (FP16) |
|---|---|---|---|---|
| 4K Token | ~318 GB | 4×H100/A100 | ~1,22 TB | 16×H100 |
| 128K Token | ~552 GB | 8×H100 | ~1,45 TB | ~16×H100 |
Llama 4 Maverick lokal installieren
Schritt 1: Umgebung vorbereiten
- Python installieren (vorzugsweise Version 3.9 oder höher).
- Eine virtuelle Umgebung für das Abhängigkeitsmanagement verwenden:
python -m venv llama_env
source llama_env/bin/activate
Schritt 2: Erforderliche Python-Bibliotheken installieren
Führen Sie die folgenden Befehle aus, um die Abhängigkeiten zu installieren:
bash
pip install -U transformers==4.51.0
pip install torch
pip install huggingface-hub
pip install hf_xet
Diese Bibliotheken sind notwendig, um das Modell zu laden und auszuführen.
Schritt 3: Modell herunterladen
- Besuchen Sie die Hugging Face Hub-Seite für Llama 4 Maverick.
- Verwenden Sie den folgenden Python-Code, um das Modell herunterzuladen:
from transformers import AutoProcessor, Llama4ForConditionalGeneration
model_id = "meta-llama/Llama-4-Maverick-17B-128E-Instruct"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16)
Dies lädt das Modell herunter und bereitet es für die Inferenz vor.
Wie greift man über die Novita API auf Llama 4 Maverick zu?
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Loggen Sie sich in Ihr Konto ein und klicken Sie auf die Schaltfläche Modellbibliothek.

Llama 4 Maverick jetzt ausprobieren!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

Schritt 3: Kostenlose Testversion starten
Starten Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: API-Schlüssel abrufen
Um sich bei der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Einstellungen“ und kopieren Sie den API-Schlüssel, wie im Bild gezeigt.

Schritt 5: Die API installieren
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<IHR Novita AI API-Schlüssel>",
)
model = "meta-llama/llama-4-maverick-17b-128e-instruct-fp8"
stream = True # oder False
max_tokens = 2048
system_content = """Seien Sie ein hilfreicher Assistent"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Verwenden von Llama 4 Scout über Cloud-GPU
Schritt 1: Ein Konto erstellen
Wenn Sie neu bei Novita AI sind, erstellen Sie zunächst ein Konto auf unserer Website. Sobald Sie registriert sind, gehen Sie zum Tab „GPUs“, um verfügbare Ressourcen zu erkunden und Ihre Reise zu beginnen.

Schritt 2: Vorlagen und GPU-Server erkunden
Wählen Sie zunächst eine Vorlage aus, die zu Ihren Projektanforderungen passt, z. B. PyTorch, TensorFlow oder CUDA. Wählen Sie die Version, die Ihren Anforderungen entspricht, z. B. PyTorch 2.2.1 oder CUDA 11.8.0. Wählen Sie dann die A100-GPU-Serverkonfiguration, die leistungsstarke Performance für anspruchsvolle Workloads mit ausreichend VRAM, RAM und Speicherkapazität bietet.

Probieren Sie die Hochleistungs-GPUs von Novita AI
Schritt 3: Bereitstellung anpassen
Passen Sie nach der Auswahl einer Vorlage und GPU Ihre Bereitstellungseinstellungen an, indem Sie Parameter wie die Betriebssystemversion (z. B. CUDA 11.8) ändern. Sie können auch andere Konfigurationen anpassen, um die Umgebung auf die spezifischen Anforderungen Ihres Projekts abzustimmen.

Schritt 4: Instanz starten
Klicken Sie nach Abschluss der Vorlagen- und Bereitstellungseinstellungen auf „Instanz starten“, um Ihre GPU-Instanz einzurichten. Dadurch wird die Umgebungseinrichtung gestartet und Sie können die GPU-Ressourcen für Ihre KI-Aufgaben nutzen.

Wenn Sie nach einem leistungsstarken, erschwinglichen und entwicklerfreundlichen LLM suchen, ist Llama 4 Maverick die beste Wahl. Es übertrifft führende Modelle wie GPT-4o und Gemini 2.0 Flash in Schlüsselbereichen – Bildlogik, mehrsprachige Unterstützung, Langzeitkontextverständnis und Inferenzkosten. Ob lokal oder über die hochleistungsfähige API von Novita AI – der Einstieg ist schnell und einfach. Probieren Sie es noch heute aus und überzeugen Sie sich selbst.
Häufig gestellte Fragen
Was ist Llama 4 Maverick?
Llama 4 Maverick ist ein Open-Source-Sprachmodell von Meta, das Text- und Bildeingaben verarbeiten kann, einen Kontext von bis zu 10 Millionen Token unterstützt und in 200 Sprachen vortrainiert ist.
Kann ich Llama 4 Maverick ohne leistungsstarke lokale GPU verwenden?
Ja! Sie können einfach über die Novita AI-API oder die Cloud-GPU-Plattform auf Llama 4 Maverick zugreifen. Kostenlose Testversionen sind verfügbar.
Ist Llama 4 Maverick für groß angelegte Dokumente oder Bücher geeignet?
Absolut. Mit Unterstützung für bis zu 1 Million Token ist es ideal für die Verarbeitung langer Texte, komplexer Dokumente und kontextbezogener Gedächtnisaufgaben.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.



