

Points clés
Fenêtre de contexte massive : prend en charge jusqu’à 1 million de jetons — idéale pour les longs documents, les bases de code ou les livres.
Support multimodal : gère simultanément les entrées texte et image.
Force multilingue : pré-entraîné sur 200 langues, avec un score MMLU multilingue élevé (84,6), ce qui en fait un modèle prêt pour une utilisation mondiale.
Rentable : offre des performances de pointe à une fraction du prix de GPT-4o (0,2 $ sur Novita AI contre 4,38 $ par million de jetons).
Llama 4 Maverick est le dernier modèle de langage open-source de Meta, publié le 5 avril 2025. Construit avec une architecture 128-Mixture-of-Experts (MoE) et entraîné sur 22 billions de jetons de données multimodales, il est conçu pour la performance, la flexibilité et l’échelle mondiale. Avec une longueur de contexte allant jusqu’à 10 millions de jetons, la prise en charge des entrées texte et image, et des performances supérieures dans les tests de référence multilingues et de raisonnement.
Qu’est-ce que Llama 4 Maverick ?
https://www.youtube.com/watch?v=8G-GI4bvWZU
Aperçu de Llama 4 Maverick
| Catégorie | Détails |
|---|---|
| Date de sortie | 5 avril 2025 |
| Taille du modèle | 400B paramètres (17B actifs par jeton) |
| Open Source | Oui |
| Architecture | 128 Mixture-of-Experts (MoE) |
| Longueur de contexte | Jusqu’à 1M de jetons (1 000 000 de jetons) |
| Support linguistique | Pré-entraîné sur 200 langues, dont l’arabe, l’anglais, le français, l’allemand, l’hindi, l’indonésien, l’italien, le portugais, l’espagnol, le tagalog, le thaï et le vietnamien. |
| Capacité multimodale | Combine entrées texte et image, prenant en charge le traitement de contenu textuel et visuel. |
| Données d’entraînement | ~22 billions de jetons de données multimodales (certaines provenant d’Instagram et Facebook). |
| Pré-entraînement | MetaP (configuration adaptative des experts avec optimisation en milieu d’entraînement). |
| Étapes post-entraînement | 1. SFT (Supervised Fine-Tuning sur données faciles). |
| 2. RL (Reinforcement Learning sur données difficiles). | |
| 3. DPO (Direct Preference Optimization). |
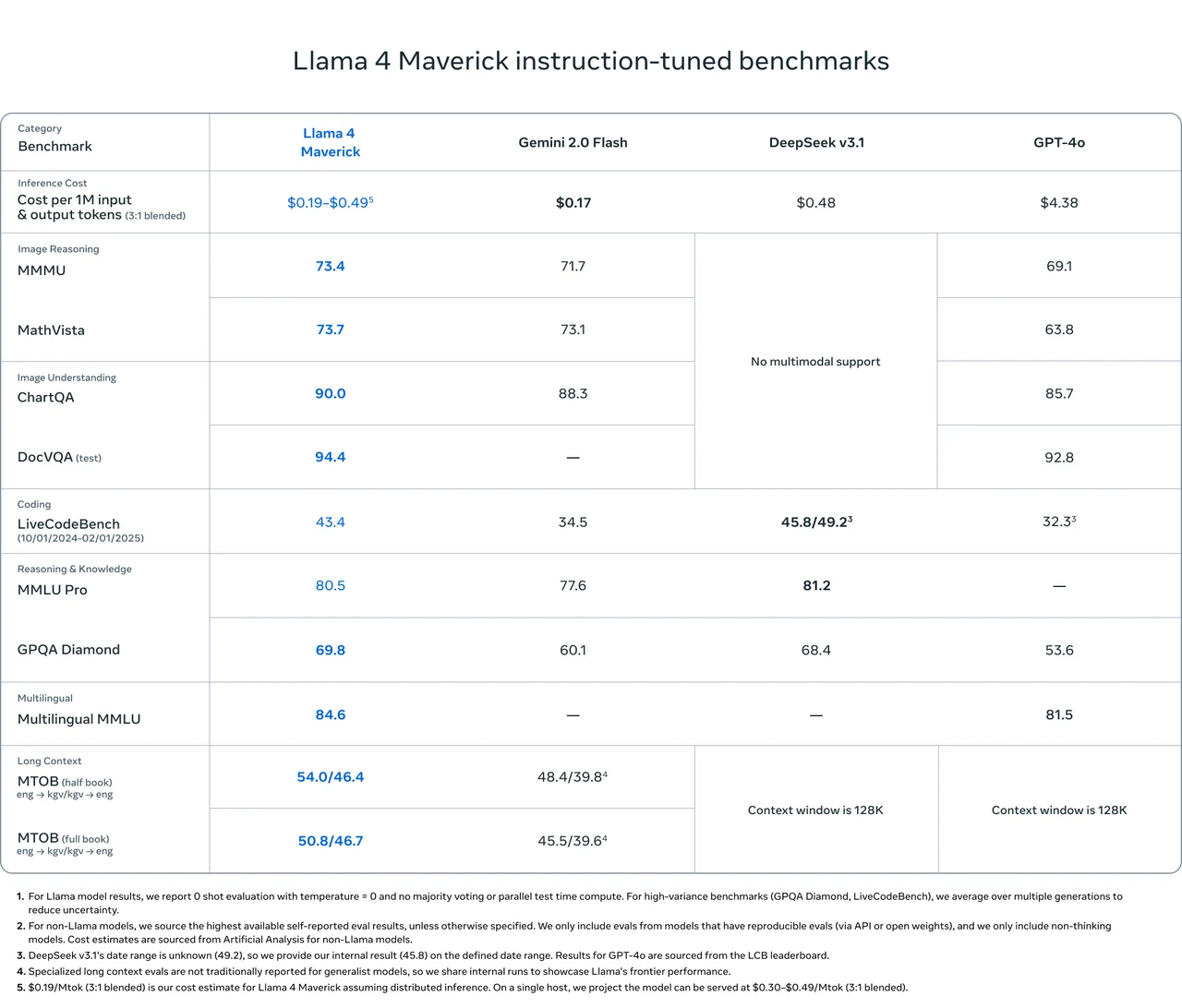
Benchmark de Llama 4 Maverick
Llama 4 Maverick surpasse Gemini 2.0 Flash, DeepSeek v3.1 et GPT-4o sur plusieurs benchmarks majeurs, notamment en raisonnement image, compréhension d’image et tâches multilingues.
Comment accéder à Llama 4 Maverick localement ?
Configuration matérielle requise pour Llama 4 Maverick
| Longueur de contexte | VRAM INT4 | Besoins GPU (INT4) | VRAM FP16 | Besoins GPU (FP16) |
|---|---|---|---|---|
| 4K jetons | ~318 Go | 4×H100/A100 | ~1,22 To | 16×H100 |
| 128K jetons | ~552 Go | 8×H100 | ~1,45 To | ~16×H100 |
Installer Llama 4 Maverick localement
Étape 1 : Préparer l’environnement
- Installez Python (de préférence version 3.9 ou supérieure).
- Utilisez un environnement virtuel pour la gestion des dépendances :text
python -m venv llama_env source llama_env/bin/activate
Étape 2 : Installer les bibliothèques Python requises
Exécutez les commandes suivantes pour installer les dépendances :
bash<code>pip install -U transformers==4.51.0
pip install torch
pip install huggingface-hub
pip install hf_xet
Ces bibliothèques sont essentielles pour charger et exécuter le modèle.
Étape 3 : Télécharger le modèle
- Visitez la page Hugging Face Hub pour Llama 4 Maverick.
- Utilisez le code Python suivant pour télécharger le modèle :
from transformers import AutoProcessor, Llama4ForConditionalGeneration
model_id = "meta-llama/Llama-4-Maverick-17B-128E-Instruct"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16)
Ceci téléchargera le modèle et le préparera pour l’inférence.
Comment accéder à Llama 4 Maverick via l’API Novita ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Essayez Llama 4 Maverick maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier avec l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page Settings, vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-maverick-17b-128e-instruct-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Utiliser Llama 4 Scout via GPU Cloud
Étape 1 : Créez un compte
Si vous êtes nouveau sur Novita AI, commencez par créer un compte sur notre site web. Une fois inscrit, dirigez-vous vers l’onglet “GPUs” pour explorer les ressources disponibles et commencer votre voyage.

Étape 2 : Explorez les modèles et les serveurs GPU****
Commencez par sélectionner un modèle qui correspond aux besoins de votre projet, comme PyTorch, TensorFlow ou CUDA. Choisissez la version qui correspond à vos besoins, par exemple PyTorch 2.2.1 ou CUDA 11.8.0. Ensuite, sélectionnez la configuration de serveur GPU A100, qui offre des performances puissantes pour gérer des charges de travail exigeantes avec suffisamment de VRAM, RAM et capacité disque.

Essayez les GPU haute performance de Novita AI
Étape 3 : Personnalisez votre déploiement
Après avoir sélectionné un modèle et un GPU, personnalisez les paramètres de déploiement en ajustant des paramètres comme la version du système d’exploitation (par exemple, CUDA 11.8). Vous pouvez également modifier d’autres configurations pour adapter l’environnement aux exigences spécifiques de votre projet.

Étape 4 : Lancez une instance****
Une fois que vous avez finalisé le modèle et les paramètres de déploiement, cliquez sur “Launch Instance” pour configurer votre instance GPU. Cela démarrera la configuration de l’environnement, vous permettant de commencer à utiliser les ressources GPU pour vos tâches d’IA.

Si vous recherchez un LLM puissant, abordable et convivial pour les développeurs, Llama 4 Maverick est votre meilleur choix. Il surpasse les modèles leaders comme GPT-4o et Gemini 2.0 Flash dans des domaines clés — raisonnement image, support multilingue, compréhension de longs contextes et coût d’inférence. Que vous l’exécutiez localement ou via l’API haute performance de Novita AI, la mise en route est rapide et facile. Essayez-le dès aujourd’hui et voyez la différence.
Questions fréquemment posées
Qu’est-ce que Llama 4 Maverick ?
Llama 4 Maverick est un modèle de langage open-source développé par Meta, capable de gérer des entrées texte et image, prenant en charge jusqu’à 10M de jetons de contexte, et entraîné dans 200 langues.
Puis-je utiliser Llama 4 Maverick sans un GPU local puissant ?
Oui ! Vous pouvez accéder facilement à Llama 4 Maverick via l’API de Novita AI ou la plateforme GPU cloud, avec des essais gratuits disponibles.
Llama 4 Maverick est-il adapté aux documents ou livres à grande échelle ?
Absolument. Avec la prise en charge de jusqu’à 1 million de jetons, il est idéal pour traiter de longs textes, documents complexes et tâches de mémoire contextuelle.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant également un GPU cloud abordable et fiable pour construire et passer à l’échelle.



