

النقاط الرئيسية
نافذة سياق ضخمة: تدعم حتى مليون رمز (token) — مثالية للمستندات الطويلة، أو قواعد الأكواد، أو الكتب.
دعم متعدد الوسائط: تعالج النصوص والصور في وقت واحد.
قوة متعددة اللغات: تم تدريبها على 200 لغة، مع درجات MMLU متعددة اللغات قوية (84.6)، مما يجعلها نموذجًا عالميًا جاهزًا.
فعالية من حيث التكلفة: تقدم أداءً حديثًا بجزء صغير من سعر GPT-4o (0.2 دولار على Novita AI مقابل 4.38 دولار لكل مليون رمز).
Llama 4 Maverick هو أحدث نموذج لغة كبير مفتوح المصدر من Meta، تم إطلاقه في 5 أبريل 2025. تم بناؤه باستخدام بنية 128-mixture-of-experts (MoE) وتدريبه على 22 تريليون رمز من البيانات متعددة الوسائط، وهو مصمم لتحقيق الأداء والمرونة والنطاق العالمي. مع طول سياق يصل إلى 10 ملايين رمز، ودعم إدخال النصوص والصور، وأداء متفوق في معايير التعدد اللغوي والتفكير.
ما هو Llama 4 Maverick؟
https://www.youtube.com/watch?v=8G-GI4bvWZU
نظرة عامة على Llama 4 Maverick
| الفئة | التفاصيل |
|---|---|
| تاريخ الإصدار | 5 أبريل 2025 |
| حجم النموذج | 400B معلمة (17B نشطة لكل رمز) |
| مفتوح المصدر | نعم |
| البنية | 128 mixture-of-experts (MoE) |
| طول السياق | حتى 1M رمز (1,000,000 رمز) |
| دعم اللغات | تم تدريبه مسبقًا على 200 لغة، بما في ذلك العربية والإنجليزية والفرنسية والألمانية والهندية والإندونيسية والإيطالية والبرتغالية والإسبانية والتاغالوغية والتايلاندية والفيتنامية. |
| القدرة متعددة الوسائط | يجمع بين إدخال النصوص والصور، ويدعم معالجة المحتوى النصي والمرئي معًا. |
| بيانات التدريب | حوالي 22 تريليون رمز من البيانات متعددة الوسائط (بعضها من Instagram وFacebook). |
| التدريب المسبق | MetaP (تكوين خبير تكيفي مع تحسين متوسط التدريب). |
| خطوات ما بعد التدريب | 1. SFT (التدريب الدقيق الخاضع للإشراف على بيانات سهلة). |
| 2. RL (التعلم المعزز على بيانات صعبة). | |
| 3. DPO (تحسين التفضيل المباشر). |
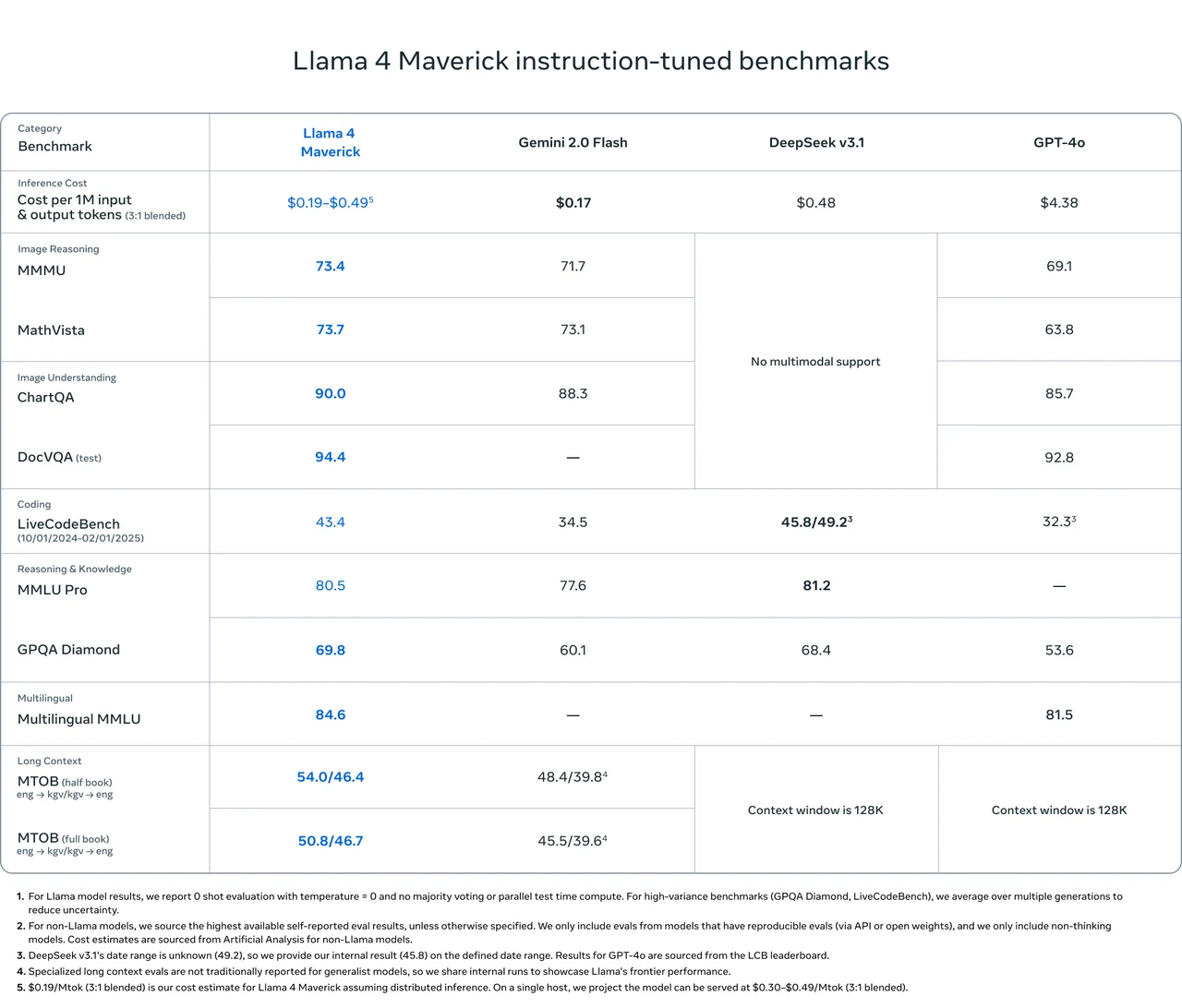
معايير Llama 4 Maverick
Llama 4 Maverick يتفوق على Gemini 2.0 Flash و DeepSeek v3.1 و GPT-4o في العديد من المعايير الرئيسية، خاصة في التفكير بالصور، و فهم الصور، و المهام متعددة اللغات.
كيفية الوصول إلى Llama 4 Maverick محليًا؟
متطلبات الأجهزة لـ Llama 4 Maverick
| طول السياق | ذاكرة INT4 VRAM | احتياجات GPU (INT4) | ذاكرة FP16 VRAM | احتياجات GPU (FP16) |
|---|---|---|---|---|
| 4K رمز | ~318 جيجابايت | 4×H100/A100 | ~1.22 تيرابايت | 16×H100 |
| 128K رمز | ~552 جيجابايت | 8×H100 | ~1.45 تيرابايت | ~16×H100 |
تثبيت Llama 4 Maverick محليًا
الخطوة 1: تهيئة البيئة
- تثبيت Python (يفضل الإصدار 3.9 أو أعلى).
- استخدام بيئة افتراضية لإدارة التبعيات:
python -m venv llama_env
source llama_env/bin/activate
الخطوة 2: تثبيت مكتبات Python المطلوبة
قم بتشغيل الأوامر التالية لتثبيت التبعيات:
pip install -U transformers==4.51.0
pip install torch
pip install huggingface-hub
pip install hf_xet
هذه المكتبات ضرورية لتحميل النموذج وتشغيله.
الخطوة 3: تنزيل النموذج
- قم بزيارة صفحة Hugging Face Hub الخاصة بـ Llama 4 Maverick.
- استخدم كود Python التالي لتنزيل النموذج:
from transformers import AutoProcessor, Llama4ForConditionalGeneration
model_id = "meta-llama/Llama-4-Maverick-17B-128E-Instruct"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16)
سيؤدي هذا إلى تنزيل النموذج وإعداده للاستدلال.
كيفية الوصول إلى Llama 4 Maverick عبر Novita API؟
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر Model Library.

الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ النسخة التجريبية المجانية
ابدأ النسخة التجريبية المجانية لاستكشاف إمكانيات النموذج المحدد.
الخطوة 4: احصل على مفتاح API
للمصادقة مع API، سنزودك بمفتاح API جديد. انتقل إلى صفحة “Settings”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.

بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام واجهة برمجة تطبيقات إكمال المحادثة (chat completions) لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-maverick-17b-128e-instruct-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
استخدام Llama 4 Scout عبر وحدات GPU سحابية
الخطوة 1: إنشاء حساب
إذا كنت جديدًا في Novita AI، ابدأ بإنشاء حساب على موقعنا. بمجرد التسجيل، توجه إلى علامة التبويب “GPUs” لاستكشاف الموارد المتاحة وبدء رحلتك.

الخطوة 2: استكشاف القوالب وخوادم GPU
ابدأ باختيار قالب يناسب احتياجات مشروعك، مثل PyTorch أو TensorFlow أو CUDA. اختر الإصدار الذي يناسب متطلباتك، مثل PyTorch 2.2.1 أو CUDA 11.8.0. ثم حدد تكوين خادم GPU A100، الذي يوفر أداءً قويًا للتعامل مع أعباء العمل الصعبة مع سعة VRAM وRAM وقرص كافية.

جرب وحدات GPU عالية الأداء من Novita AI
الخطوة 3: تخصيص النشر
بعد اختيار قالب وGPU، قم بتخصيص إعدادات النشر عن طريق ضبط المعلمات مثل إصدار نظام التشغيل (مثل CUDA 11.8). يمكنك أيضًا تعديل التكوينات الأخرى لتكييف البيئة مع متطلبات مشروعك المحددة.

الخطوة 4: إطلاق مثيل
بمجرد الانتهاء من القالب وإعدادات النشر، انقر على “Launch Instance” لإعداد مثيل GPU الخاص بك. سيبدأ هذا في إعداد البيئة، مما يتيح لك البدء في استخدام موارد GPU لمهام الذكاء الاصطناعي الخاصة بك.

إذا كنت تبحث عن نموذج LLM قوي وبأسعار معقولة وصديق للمطورين، فإن Llama 4 Maverick هو الخيار الأمثل لك. إنه يتفوق على النماذج الرائدة مثل GPT-4o و Gemini 2.0 Flash في المجالات الرئيسية — التفكير بالصور، الدعم متعدد اللغات، فهم السياق الطويل، و تكلفة الاستدلال. سواء كنت تعمل محليًا أو من خلال واجهة برمجة تطبيقات عالية الأداء من Novita AI، فإن البدء سهل وسريع. جربه اليوم ولاحظ الفرق.
الأسئلة الشائعة
ما هو Llama 4 Maverick؟
Llama 4 Maverick هو نموذج لغة كبير مفتوح المصدر تم تطويره بواسطة Meta، قادر على معالجة إدخال النصوص والصور، ودعم سياق يصل إلى 10M رمز، وتدريبه عبر 200 لغة.
هل يمكنني استخدام Llama 4 Maverick دون وجود GPU محلي قوي؟
نعم! يمكنك الوصول بسهولة إلى Llama 4 Maverick من خلال Novita AI API أو منصة GPU السحابية، مع توفر نسخ تجريبية مجانية.
هل Llama 4 Maverick مناسب للمستندات أو الكتب واسعة النطاق؟
بالتأكيد. بفضل دعم حتى مليون رمز، فهو مثالي لمعالجة النصوص الطويلة والمستندات المعقدة ومهام الذاكرة السياقية.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API بسيط، مع توفير GPU سحابي ميسور وموثوق للبناء والتوسع.



