

Principais Destaques
Janela de Contexto Massiva: Suporta até 1 milhão de tokens — ideal para documentos longos, bases de código ou livros.
Suporte Multimodal: Lida com entrada de texto e imagem simultaneamente.
Força Multilíngue: Pré-treinado em 200 idiomas, com fortes pontuações MMLU multilíngues (84,6), tornando-o um modelo pronto para uso global.
Custo-Efetivo: Oferece desempenho de ponta a uma fração do preço do GPT-4o ($0,2 no Novita AI vs $4,38 por milhão de tokens).
Llama 4 Maverick é o mais recente modelo de linguagem aberto da Meta, lançado em 5 de abril de 2025. Construído com uma arquitetura de 128 Mixture-of-Experts (MoE) e treinado em 22 trilhões de tokens de dados multimodais, ele foi projetado para desempenho, flexibilidade e escala global. Com comprimento de contexto de até 10 milhões de tokens, suporte para entradas de texto e imagem e desempenho superior em benchmarks multilíngues e de raciocínio.
O que é o Llama 4 Maverick?
https://www.youtube.com/watch?v=8G-GI4bvWZU
Visão Geral do Llama 4 Maverick
| Categoria | Detalhes |
|---|---|
| Data de Lançamento | 5 de abril de 2025 |
| Tamanho do Modelo | 400B parâmetros (17B ativos por token) |
| Código Aberto | Sim |
| Arquitetura | 128 Mixture-of-Experts (MoE) |
| Comprimento do Contexto | Até 1M de tokens (1.000.000 tokens) |
| Suporte a Idiomas | Pré-treinado em 200 idiomas, incluindo Árabe, Inglês, Francês, Alemão, Hindi, Indonésio, Italiano, Português, Espanhol, Tagalo, Tailandês e Vietnamita. |
| Capacidade Multimodal | Combina entradas de texto e imagem, suportando processamento de conteúdo textual e visual. |
| Dados de Treinamento | ~22 trilhões de tokens de dados multimodais (alguns provenientes do Instagram e Facebook). |
| Pré-Treinamento | MetaP (Configuração Adaptativa de Especialistas com otimização intermediária). |
| Etapas de Pós-Treinamento | 1. SFT (Ajuste Fino Supervisionado em dados fáceis). |
| 2. RL (Aprendizado por Reforço em dados difíceis). | |
| 3. DPO (Otimização Direta de Preferências). |
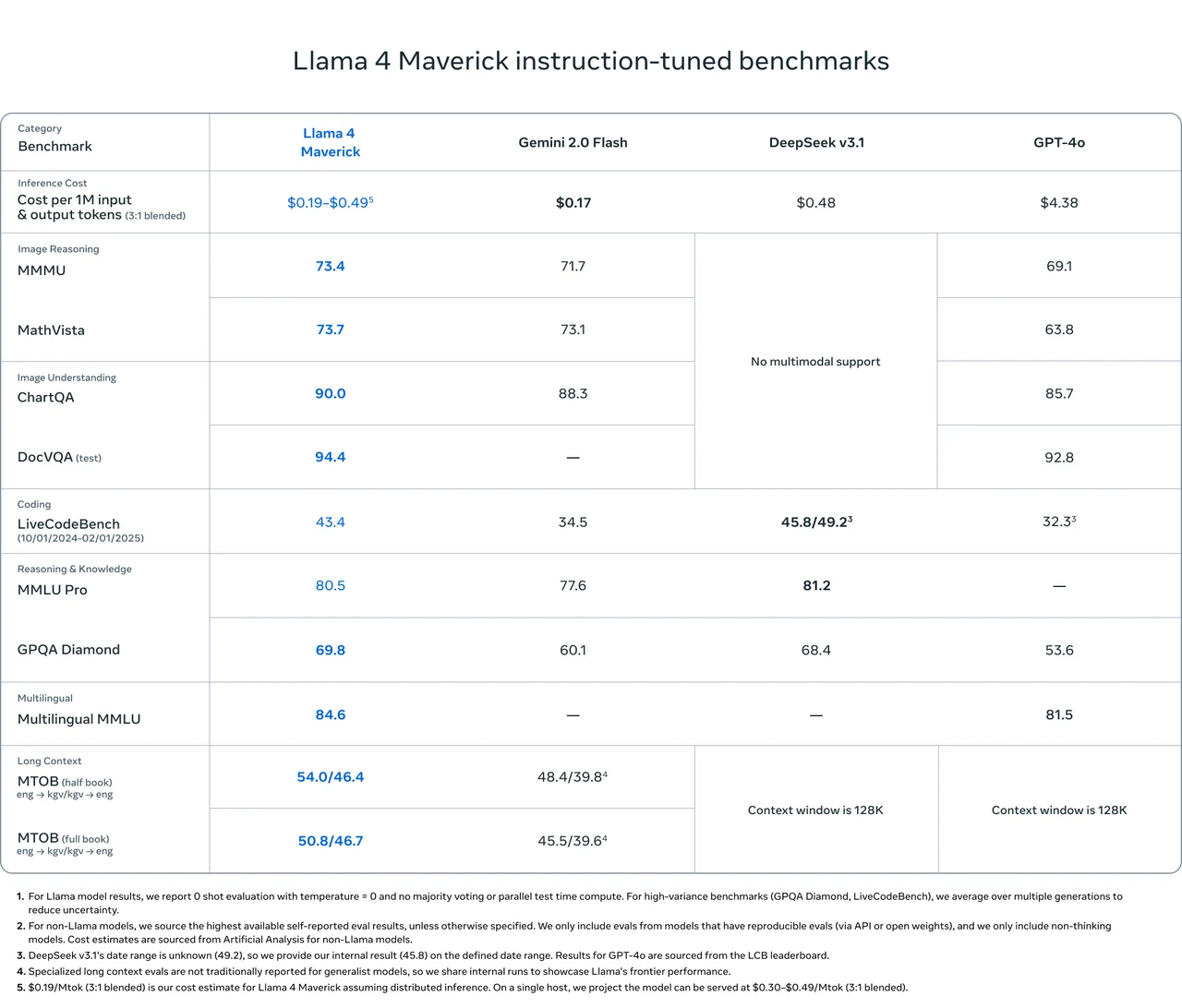
Benchmark do Llama 4 Maverick
Llama 4 Maverick supera Gemini 2.0 Flash, DeepSeek v3.1 e GPT-4o em vários benchmarks importantes, especialmente em raciocínio de imagem, compreensão de imagem e tarefas multilíngues.
Como Acessar o Llama 4 Maverick Localmente?
Requisitos de Hardware do Llama 4 Maverick
| Comprimento do Contexto | VRAM INT4 | Necessidade de GPU (INT4) | VRAM FP16 | Necessidade de GPU (FP16) |
|---|---|---|---|---|
| 4K Tokens | ~318 GB | 4×H100/A100 | ~1,22 TB | 16×H100 |
| 128K Tokens | ~552 GB | 8×H100 | ~1,45 TB | ~16×H100 |
Instalar o Llama 4 Maverick Localmente
Passo 1: Preparar o Ambiente
- Instale o Python (preferencialmente versão 3.9 ou superior).
- Use um ambiente virtual para gerenciamento de dependências:text
python -m venv llama_env source llama_env/bin/activate
Passo 2: Instalar as Bibliotecas Python Necessárias
Execute os seguintes comandos para instalar as dependências:
bash<code>pip install -U transformers==4.51.0
pip install torch
pip install huggingface-hub
pip install hf_xet
Essas bibliotecas são essenciais para carregar e executar o modelo.
Passo 3: Baixar o Modelo
- Acesse a página do Hugging Face Hub para o Llama 4 Maverick.
- Use o seguinte código Python para baixar o modelo:
from transformers import AutoProcessor, Llama4ForConditionalGeneration
model_id = "meta-llama/Llama-4-Maverick-17B-128E-Instruct"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16)
Isso baixará o modelo e o preparará para inferência.
Como Acessar o Llama 4 Maverick via API Novita?
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Experimente o Llama 4 Maverick Agora!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Entre na página “Settings” e copie a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de completions de chat para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-maverick-17b-128e-instruct-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Usando o Llama 4 Scout via GPU em Nuvem
Passo 1: Crie uma conta
Se você é novo no Novita AI, comece criando uma conta em nosso site. Depois de registrado, vá para a aba “GPUs” para explorar os recursos disponíveis e iniciar sua jornada.

Passo 2: Explore Modelos e Servidores GPU
Comece selecionando um modelo que corresponda às necessidades do seu projeto, como PyTorch, TensorFlow ou CUDA. Escolha a versão que atenda aos seus requisitos, como PyTorch 2.2.1 ou CUDA 11.8.0. Em seguida, selecione a configuração do servidor GPU A100, que oferece desempenho poderoso para lidar com cargas de trabalho exigentes, com ampla VRAM, RAM e capacidade de disco.

Experimente as GPUs de Alto Desempenho do Novita AI
Passo 3: Personalize Sua Implantação
Após selecionar um modelo e GPU, personalize as configurações de implantação ajustando parâmetros como a versão do sistema operacional (por exemplo, CUDA 11.8). Você também pode ajustar outras configurações para adequar o ambiente aos requisitos específicos do seu projeto.

Passo 4: Inicie uma instância
Depois de finalizar o modelo e as configurações de implantação, clique em “Launch Instance” para configurar sua instância GPU. Isso iniciará a configuração do ambiente, permitindo que você comece a usar os recursos de GPU para suas tarefas de IA.

Se você está procurando um LLM poderoso, acessível e amigável para desenvolvedores, o Llama 4 Maverick é a sua melhor aposta. Ele supera modelos líderes como GPT-4o e Gemini 2.0 Flash em áreas-chave — raciocínio de imagem, suporte multilíngue, compreensão de contexto longo e custo de inferência. Seja executando localmente ou através da API de alto desempenho do Novita AI, começar é rápido e fácil. Experimente hoje e veja a diferença.
Perguntas Frequentes
O que é o Llama 4 Maverick?
O Llama 4 Maverick é um modelo de linguagem de código aberto desenvolvido pela Meta, capaz de lidar com entradas de texto e imagem, suportando até 10M de tokens de contexto e treinado em 200 idiomas.
Posso usar o Llama 4 Maverick sem uma GPU local potente?
Sim! Você pode acessar o Llama 4 Maverick facilmente através da API do Novita AI ou plataforma de GPU em nuvem, com testes gratuitos disponíveis.
O Llama 4 Maverick é adequado para documentos ou livros em larga escala?
Com certeza. Com suporte para até 1 milhão de tokens, é ideal para processar textos longos, documentos complexos e tarefas de memória contextual.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem GPU acessível e confiável para construir e escalar.



