

Puntos clave
Ventana de contexto masiva: Admite hasta 1 millón de tokens—ideal para documentos largos, bases de código o libros.
Soporte multimodal: Maneja entrada de texto e imagen simultáneamente.
Potencia multilingüe: Preentrenado en 200 idiomas, con puntuaciones sólidas en MMLU multilingüe (84.6), lo que lo convierte en un modelo preparado para uso global.
Rentable: Ofrece rendimiento de última generación a una fracción del precio de GPT-4o ($0.2 en Novita AI frente a $4.38 por millón de tokens).
Llama 4 Maverick es el último modelo de lenguaje grande de código abierto de Meta, lanzado el 5 de abril de 2025. Construido con una arquitectura de 128 Mixture-of-Experts (MoE) y entrenado con 22 billones de tokens de datos multimodales, está diseñado para rendimiento, flexibilidad y escala global. Con una longitud de contexto de hasta 10 millones de tokens, soporte para entradas de texto e imagen, y rendimiento superior en pruebas de razonamiento multilingüe y general.
¿Qué es Llama 4 Maverick?
https://www.youtube.com/watch?v=8G-GI4bvWZU
Resumen de Llama 4 Maverick
| Categoría | Detalles |
|---|---|
| Fecha de publicación | 5 de abril de 2025 |
| Tamaño del modelo | 400 mil millones de parámetros (17 mil millones activos por token) |
| Código abierto | Sí |
| Arquitectura | 128 Mixture-of-Experts (MoE) |
| Longitud de contexto | Hasta 1 millón de tokens (1,000,000 tokens) |
| Idiomas compatibles | Preentrenado en 200 idiomas, incluyendo árabe, inglés, francés, alemán, hindi, indonesio, italiano, portugués, español, tagalo, tailandés y vietnamita. |
| Capacidad multimodal | Combina entradas de texto e imagen, procesando contenido tanto textual como visual. |
| Datos de entrenamiento | ~22 billones de tokens de datos multimodales (algunos provenientes de Instagram y Facebook). |
| Preentrenamiento | MetaP (Configuración adaptativa de expertos con optimización durante el entrenamiento intermedio). |
| Pasos posteriores al entrenamiento | 1. SFT (Ajuste fino supervisado con datos fáciles). |
| 2. RL (Aprendizaje por refuerzo con datos difíciles). | |
| 3. DPO (Optimización directa de preferencias). |
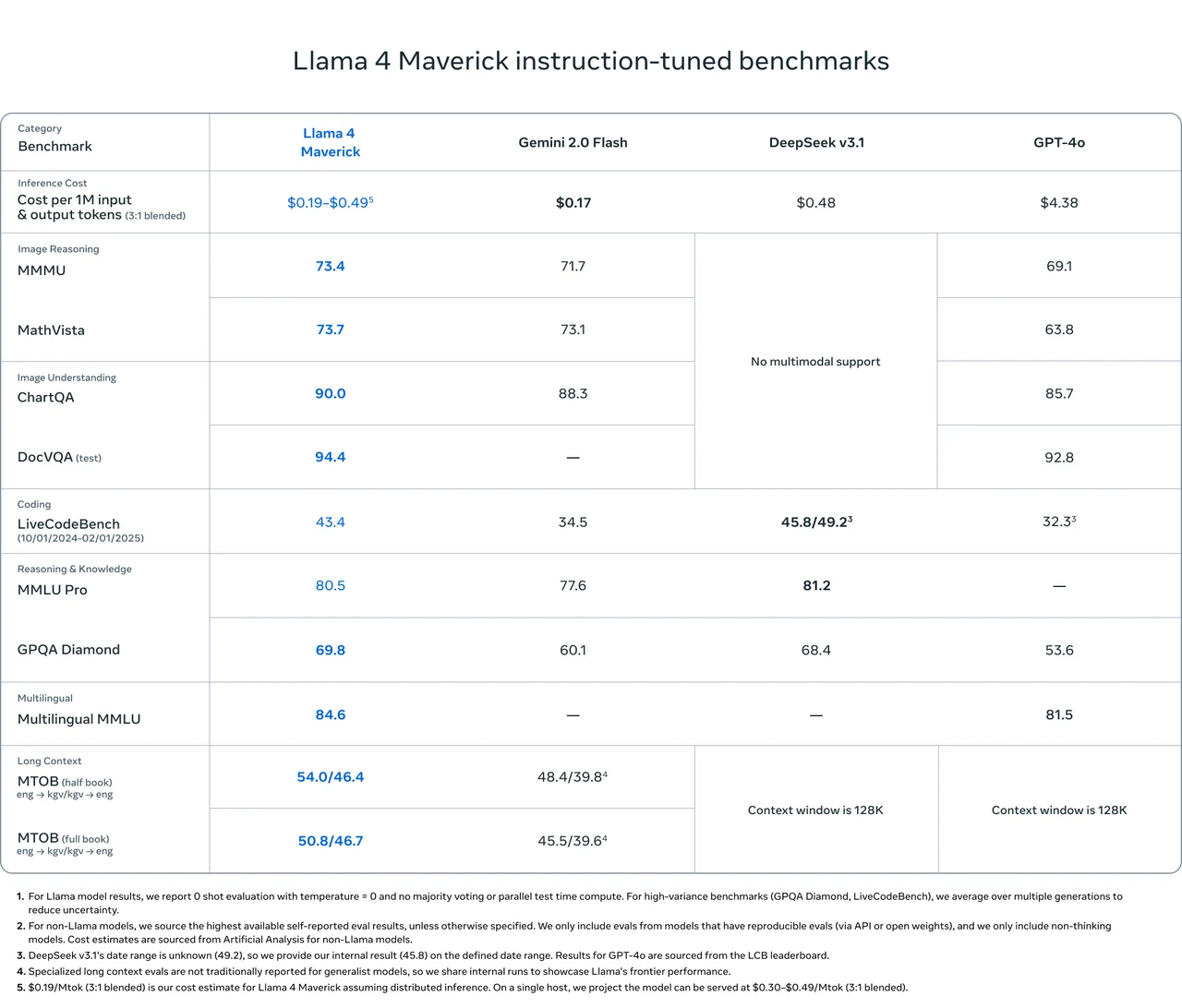
Puntuaciones de Llama 4 Maverick
Llama 4 Maverick supera a Gemini 2.0 Flash, DeepSeek v3.1 y GPT-4o en varios benchmarks importantes, especialmente en razonamiento de imágenes, comprensión de imágenes y tareas multilingües.
¿Cómo acceder a Llama 4 Maverick localmente?
Requisitos de hardware para Llama 4 Maverick
| Longitud de contexto | VRAM INT4 | GPU necesarias (INT4) | VRAM FP16 | GPU necesarias (FP16) |
|---|---|---|---|---|
| 4K tokens | ~318 GB | 4×H100/A100 | ~1.22 TB | 16×H100 |
| 128K tokens | ~552 GB | 8×H100 | ~1.45 TB | ~16×H100 |
Instalar Llama 4 Maverick localmente
Paso 1: Preparar el entorno
- Instalar Python (preferiblemente versión 3.9 o superior).
- Usar un entorno virtual para la gestión de dependencias:text
python -m venv llama_env source llama_env/bin/activate
Paso 2: Instalar las bibliotecas de Python necesarias
Ejecuta los siguientes comandos para instalar las dependencias:
bash<code>pip install -U transformers==4.51.0
pip install torch
pip install huggingface-hub
pip install hf_xet
Estas bibliotecas son esenciales para cargar y ejecutar el modelo.
Paso 3: Descargar el modelo
- Visita la página de Hugging Face Hub de Llama 4 Maverick.
- Usa el siguiente código Python para descargar el modelo:
from transformers import AutoProcessor, Llama4ForConditionalGeneration
model_id = "meta-llama/Llama-4-Maverick-17B-128E-Instruct"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16)
Esto descargará el modelo y lo preparará para inferencia.
¿Cómo acceder a Llama 4 Maverick a través de la API de Novita?
Paso 1: Iniciar sesión y acceder a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

¡Prueba Llama 4 Maverick ahora!
Paso 2: Elegir tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comenzar tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtener tu clave de API
Para autenticarte en la API, te proporcionaremos una nueva clave de API. Ingresa a la página de “Settings” y copia la clave de API como se indica en la imagen.

Paso 5: Instalar la API
Instala la API usando el administrador de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completado de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<TU CLAVE DE API DE NOVITA AI>",
)
model = "meta-llama/llama-4-maverick-17b-128e-instruct-fp8"
stream = True # o False
max_tokens = 2048
system_content = """Sé un asistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Usar Llama 4 Scout mediante GPU en la nube
Paso 1: Crear una cuenta
Si eres nuevo en Novita AI, comienza creando una cuenta en nuestro sitio web. Una vez registrado, dirígete a la pestaña “GPUs” para explorar los recursos disponibles y comenzar tu viaje.

Paso 2: Explorar plantillas y servidores GPU
Comienza seleccionando una plantilla que se ajuste a las necesidades de tu proyecto, como PyTorch, TensorFlow o CUDA. Elige la versión que se adapte a tus requisitos, por ejemplo PyTorch 2.2.1 o CUDA 11.8.0. Luego, selecciona la configuración del servidor GPU A100, que ofrece un rendimiento potente para manejar cargas de trabajo exigentes con amplia VRAM, RAM y capacidad de disco.

Prueba las GPU de alto rendimiento de Novita AI
Paso 3: Personalizar tu implementación
Después de seleccionar una plantilla y una GPU, personaliza la configuración de tu implementación ajustando parámetros como la versión del sistema operativo (por ejemplo, CUDA 11.8). También puedes modificar otras configuraciones para adaptar el entorno a los requisitos específicos de tu proyecto.

Paso 4: Lanzar una instancia
Una vez que hayas finalizado la plantilla y la configuración de implementación, haz clic en “Launch Instance” para configurar tu instancia GPU. Esto iniciará la preparación del entorno, permitiéndote comenzar a usar los recursos GPU para tus tareas de IA.

Si buscas un LLM potente, asequible y amigable para desarrolladores, Llama 4 Maverick es tu mejor opción. Supera a modelos líderes como GPT-4o y Gemini 2.0 Flash en áreas clave: razonamiento de imágenes, soporte multilingüe, comprensión de contexto largo y costo de inferencia. Ya sea ejecutándolo localmente o a través de la API de alto rendimiento de Novita AI, comenzar es rápido y fácil. Pruébalo hoy y nota la diferencia.
Preguntas frecuentes
¿Qué es Llama 4 Maverick?
Llama 4 Maverick es un modelo de lenguaje grande de código abierto desarrollado por Meta, capaz de manejar entradas de texto e imagen, admitir hasta 10 millones de tokens de contexto y entrenado en 200 idiomas.
¿Puedo usar Llama 4 Maverick sin una GPU local potente?
¡Sí! Puedes acceder a Llama 4 Maverick fácilmente a través de la API de Novita AI o la plataforma GPU en la nube, con pruebas gratuitas disponibles.
¿Es Llama 4 Maverick adecuado para documentos o libros a gran escala?
Absolutamente. Con soporte para hasta 1 millón de tokens, es ideal para procesar textos largos, documentos complejos y tareas de memoria contextual.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona una GPU en la nube asequible y confiable para construir y escalar.



