

核心亮点
**超长上下文窗口 **:支持多达 100 万个 Token——非常适合处理长文档、代码库或书籍。
**多模态支持 :可同时处理 ** 文本和图像输入。
**多语言优势 **:在 200 种语言 上预训练,多语言 MMLU 得分高达 84.6,是一款面向全球的模型。
**成本效益高 :以远低于 GPT-4o 的价格(在 Novita AI 上为 $0.2,GPT-4o 为每百万 Token $4.38)提供 ** 顶尖性能。
Llama 4 Maverick 是 Meta 最新发布的开源大语言模型,于 2025 年 4 月 5 日推出。它采用 128 混合专家(MoE)架构,并在 22 万亿 Token 的多模态数据上训练,旨在实现 ** 高性能、灵活性和全球化规模 **。凭借 ** 高达 1000 万 Token 的上下文长度 、对 ** 文本和图像输入 ** 的支持,以及在 ** 多语言和推理基准测试 中的卓越表现,它是一款极具竞争力的模型。
什么是 Llama 4 Maverick?
https://www.youtube.com/watch?v=8G-GI4bvWZU
Llama 4 Maverick 概述
| **类别 ** | ** 详情** |
|---|---|
| 发布日期 | 2025 年 4 月 5 日 |
| 模型大小 | 400B 参数(每个 Token 活跃 17B) |
| 开源 | 是 |
| 架构 | 128 混合专家(MoE) |
| 上下文长度 | 最高 1M Token(1,000,000 Token) |
| 语言支持 | 在 200 种语言上预训练,包括阿拉伯语、英语、法语、德语、印地语、印尼语、意大利语、葡萄牙语、西班牙语、他加禄语、泰语和越南语。 |
| 多模态能力 | 结合文本和图像输入,支持处理文本与视觉内容。 |
| 训练数据 | 约 22 万亿 Token 的多模态数据(部分来自 Instagram 和 Facebook)。 |
| 预训练 | MetaP(自适应专家配置,含中期训练优化)。 |
| 后训练步骤 | 1. SFT(在简单数据上进行有监督微调) |
| 2. RL(在困难数据上进行强化学习) | |
| 3. DPO(直接偏好优化) |
Llama 4 Maverick 基准测试
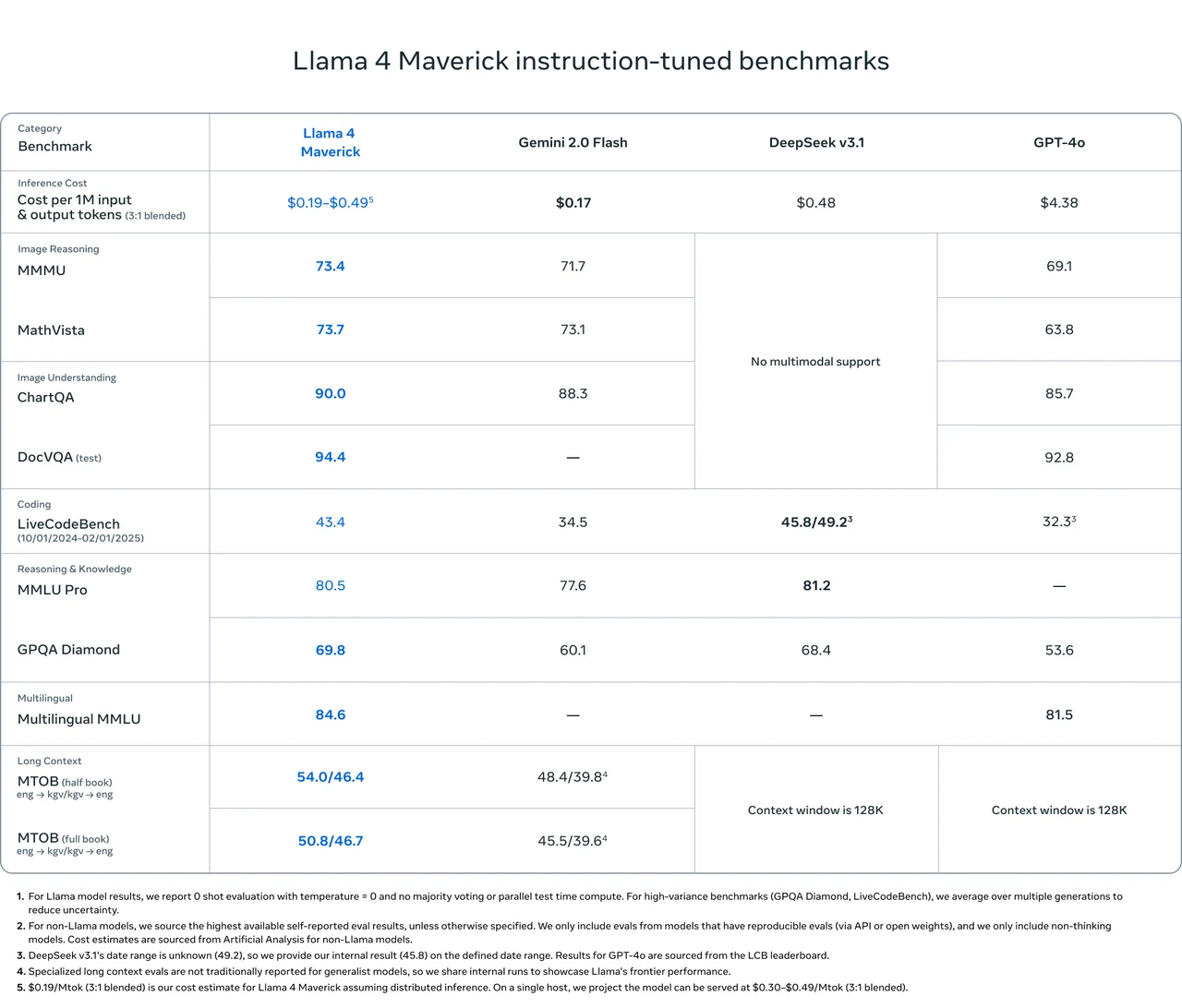
Llama 4 Maverick 在多项主要基准测试中超越 Gemini 2.0 Flash、DeepSeek v3.1 和 GPT-4o,尤其在 ** 图像推理 、 图像理解 ** 和 ** 多语言任务** 方面表现突出。
如何在本地访问 Llama 4 Maverick?
Llama 4 Maverick 硬件需求
| **上下文长度 ** | INT4 VRAM | GPU 需求(INT4) | FP16 VRAM | GPU 需求(FP16) |
|---|---|---|---|---|
| 4K Token | 约 318 GB | 4×H100/A100 | 约 1.22 TB | 16×H100 |
| 128K Token | 约 552 GB | 8×H100 | 约 1.45 TB | 约 16×H100 |
在本地安装 Llama 4 Maverick
步骤 1:准备环境
- 安装 Python(建议 3.9 或更高版本)。
- 使用虚拟环境管理依赖项:text
python -m venv llama_env source llama_env/bin/activate
步骤 2:安装所需 Python 库
运行以下命令安装依赖:
bash<code>pip install -U transformers==4.51.0
pip install torch
pip install huggingface-hub
pip install hf_xet
这些库对于加载和运行模型至关重要。
步骤 3:下载模型
- 访问 Hugging Face Hub 上 Llama 4 Maverick 的页面。
- 使用以下 Python 代码下载模型:
from transformers import AutoProcessor, Llama4ForConditionalGeneration
model_id = "meta-llama/Llama-4-Maverick-17B-128E-Instruct"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16)
这将会下载模型并准备好进行推理。
如何通过 Novita API 访问 Llama 4 Maverick?
步骤 1:登录并访问模型库
登录您的账户,点击 模型库 按钮。

步骤 2:选择您的模型
浏览可用的选项,选择适合您需求的模型。

步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。
步骤 4:获取您的 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入“设置”页面,您可以按照图片所示复制 API 密钥。

步骤 5:安装 API
使用您编程语言对应的包管理器安装 API。

安装完成后,将必要的库导入您的开发环境。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-maverick-17b-128e-instruct-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
通过云端 GPU 使用 Llama 4 Scout
步骤 1:注册账户
如果您是 Novita AI 的新用户,请先在网站上注册账户。注册完成后,前往“GPUs”标签页,探索可用资源并开始您的旅程。

步骤 2:探索模板和 GPU 服务器
首先选择一个与您项目需求匹配的模板,例如 PyTorch、TensorFlow 或 CUDA。选择适合的版本,比如 PyTorch 2.2.1 或 CUDA 11.8.0。然后选择 A100 GPU 服务器配置,它提供强大的性能来处理繁重的工作负载,并拥有充足的 VRAM、RAM 和磁盘容量。

步骤 3:定制您的部署
选择模板和 GPU 后,通过调整参数(如操作系统版本,例如 CUDA 11.8)来自定义部署设置。您还可以调整其他配置,使环境更符合项目的特定要求。

步骤 4:启动实例
完成模板和部署设置后,点击“启动实例”来设置您的 GPU 实例。这将开始环境配置,使您能够开始使用 GPU 资源处理 AI 任务。

如果您正在寻找一款强大、实惠且对开发者友好的 LLM,Llama 4 Maverick 是您的最佳选择。它在 ** 图像推理、多语言支持、长上下文理解 ** 和 ** 推理成本 ** 等关键领域超越 GPT-4o 和 Gemini 2.0 Flash 等领先模型。无论是本地运行还是通过 Novita AI 的高性能 API 使用,开始使用都非常快速简便。今天就试试吧,看看它的不同之处。
常见问题
什么是 Llama 4 Maverick?
Llama 4 Maverick 是 Meta 开发的开源大语言模型,能够处理 **文本和图像输入 **,支持 ** 最高 10M Token 上下文 **,并在 200 种语言 上训练。
我可以在没有强大本地 GPU 的情况下使用 Llama 4 Maverick 吗?
可以!您可以通过 Novita AI 的 API 或 ** 云端 GPU 平台** 轻松访问 Llama 4 Maverick,并提供免费试用。
Llama 4 Maverick 适合处理大型文档或书籍吗?
当然。凭借对 最多 100 万 Token 的支持,它非常适合处理长文本、复杂文档和上下文记忆任务。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。



