

Die H200- und B200-GPUs von NVIDIA gehören zu den modernsten Optionen im aktuellen KI-Hardware-Bereich. Jede bringt ihre eigenen Stärken mit, die sie für unterschiedliche Szenarien in Inferenz und Training geeignet machen.
Dieser Artikel wirft einen genaueren Blick auf beide GPUs, hebt deren Vorteile und Anwendungsfälle hervor und klärt, wie jede in unterschiedliche KI-Workloads passt.
H200 vs B200: Features
| Feature | 1× H200 SMX | 1× B200 |
| Architektur | Hooper | Blackwell |
| GPU-Speicher | 141GB HBM3e | 192GB HBM3e |
| Speicherbandbreite | 4,8TB/s | 8TB/s |
| Tensor Core | Bis zu 4 PFLOPS FP8 | Bis zu 5 PFLOPS FP8 und 9 PFLOPS FP4 |
H200 vs B200: Wichtige Vorteile
1× H200 SXM
- Hoher Speicherplatz: Ausgestattet mit 141 GB HBM3e-Speicher und 4,8 TB/s Bandbreite kann die H200 deutlich größere Datensätze aufnehmen als ihre Vorgängermodelle. Dadurch minimiert dieses Design mit hoher Speicherkapazität Speicher-Engpässe und verbessert den Datenfluss, sodass komplexe Workloads – wie Inferenz von Sprachmodellen mit langem Kontext und wissenschaftliche Simulationen – stabiler und effizienter laufen. Das Ergebnis ist eine reibungslosere Skalierung und konsistentere Leistung bei anspruchsvollen KI- und HPC-Aufgaben.
- FP8-Tensor-Core-Leistung: Die H200 bietet eine FP8-Rechenleistung von bis zu 4 PFLOPS, was einen erheblichen Effizienzsprung für KI-Workloads darstellt. Insbesondere FP8 bietet eine praktische Balance zwischen Rechendurchsatz und Genauigkeit, was es besonders für produktionsreife generative KI geeignet macht. Darüber hinaus positioniert FP8 die H200 durch schnellere Inferenz ohne schwerwiegende Genauigkeitseinbußen als hocheffiziente Option für Entwickler und Unternehmen, die KI im großen Maßstab einsetzen.
- Inferenz-optimierte Architektur: Das Hardware-Design der H200 legt den Fokus auf latenzarme und energieeffiziente Inferenz. Diese Optimierung ermöglicht reaktionsschnelle KI-Systeme, die Echtzeitanwendungen von generativen KI-Modellen bis hin zu Empfehlungsmaschinen unterstützen können. Gleichzeitig sorgt die H200 durch geringeren Stromverbrauch bei gleichbleibend starker Rechenleistung für eine zuverlässige Balance aus Leistung und Effizienz bei dauerhaft inferenzlastigen Vorgängen.
1× B200
- Größere Speicherkapazität: Mit 192 GB HBM3e übertrifft die B200 die H200 deutlich bei der reinen Speichergröße. Diese zusätzliche Kapazität ermöglicht es, ultra große KI-Modelle einzusetzen, ohne Partitionierung oder komplexes Speichermanagement zu benötigen. In der Praxis minimiert die B200 bei Workloads mit umfangreichen Datensätzen oder längeren Sequenzkontexten Einschränkungen und vereinfacht das Workflow-Design, sodass Entwickler mehr Flexibilität bei der Skalierung ihrer Systeme haben.
- Unterstützung von FP4-Präzision: Als eine der prägenden Innovationen der Blackwell-Architektur führt die B200 FP4-Tensor-Core-Operationen ein. FP4 verbessert dadurch den Durchsatz und die Energieeffizienz drastisch, sodass groß angelegtes Training und Inferenz schneller und kostengünstiger durchgeführt werden können. Darüber hinaus markiert FP4 durch die Reduzierung von Rechenaufwand bei gleichbleibender funktionaler Genauigkeit einen Durchbruch, der Organisationen direkt zugutekommt, die die Grenzen von Modellgröße und Leistung verschieben wollen.
- Zukunftssicheres Design: Durch die Kombination aus größerem Speicherpool, höherer Bandbreite und fortschrittlichen Präzisionsformaten ist die B200 so konzipiert, dass sie auch bei weiter wachsender Komplexität von KI-Modellen relevant bleibt. Dieses zukunftsorientierte Design stellt sicher, dass Forschungsgruppen und Unternehmen, die heute in die B200 investieren, über genügend Rechenkapazität verfügen, um in den kommenden Jahren neue Workloads zu unterstützen. Letztendlich ist sie nicht nur eine Lösung für aktuelle Spitzenmodelle, sondern auch eine stabile Grundlage für die KI-Entwicklung der nächsten Generation.
Während die B200 klare Vorteile bei Speicher, Präzision und Skalierbarkeit bietet, bleibt die H200 eine starke und praktische Wahl. Mit robuster Leistung zu einem zugänglicheren Preis ist die H200 eine ausgewogene Option für Unternehmen, die Effizienz ohne die höheren Investitionen in Systeme der nächsten Generation suchen.
H200 vs B200: Anwendungsfälle
H200 SMX
- Generative KI und LLMs: Sehr gut geeignet für Inferenz mit langem Kontext, unterstützt fortschrittliche Chatbots und Anwendungen zur Inhaltsgenerierung.
- High-Performance Computing (HPC): Die bandbreitengesteuerte Leistung beschleunigt datenintensive wissenschaftliche Simulationen und Modellierungsaufgaben.
- Unternehmens-Inferenz: Zuverlässige Option für die großflächige Bereitstellung von Such-, Empfehlungs- und Konversations-KI-Systemen.
B200
- Spitzen-KI-Entwicklung: Speziell entwickelt für das Training und die Inferenz von modernsten LLMs und multimodalen Systemen, die aktuelle Grenzen verschieben.
- Unternehmensweite Bereitstellung: Bietet die Kapazität und den Rechenspielraum, die für dauerhaft leistungsstarke KI-Plattformen mit hohem Durchsatz benötigt werden.
- Forschungsinfrastruktur: Geeignet für Organisationen, die skalierbare Grundlagen aufbauen, um die nächste Welle der KI-Modellentwicklung zu unterstützen.
H200 vs B200: Preis
| GPU | Einzelhandelspreisspanne | Server-/Unternehmens-Bundle-Preis | Cloud-Mietpreis |
|---|---|---|---|
| NVIDIA H200 | 30.000 – 40.000 $ | Kann bei vollständigen Systemen 500.000 $ überschreiten | 3,25 $ pro Stunde (z. B. bei Novita AI) |
| NVIDIA B200 | 45.000 – 50.000 $ | Kann bei vollständigen Systemen 500.000 $ überschreiten | 3,84 $ pro Stunde |
H200 und B200 setzen den Maßstab für GPU-Leistung, aber für diejenigen, die Kosten und Flexibilität in Einklang bringen wollen, ist die Investition in vollständige Systeme möglicherweise nicht der optimale Weg. GPU-Instanzen decken diesen Bedarf ab – und Novita AI bietet eine flexible Plattform, die Entwicklern und Unternehmen die einfache Skalierung ermöglicht und sie zugänglicher macht als je zuvor.
Fünf Gründe, um H200 und B200 über Novita AI GPU-Instanzen zu nutzen
1. Wettbewerbsfähige Preise und flexible Abrechnung
Preise: Novita AI vs RunPod
| Anbieter | H200 SMX | B200 SMX |
| Novita AI | 3,25 $/Stunde | 3,84 $/Stunde |
| RunPod | 3,59 $/Stunde | 5,98 $/Stunde |
Abrechnungsoptionen
| GPU | Spot | On-Demand | Abonnement |
| 1× H200 SMX | 1,63 $/Stunde | 3,25 $/Stunde | 2160 $/Stunde |
| 1× B200 SMX | 1,92 $/Stunde | 3,84 $/Stunde | - |
Spot bietet ermäßigte Tarife bei variabler Verfügbarkeit. On-Demand folgt einem Pay-as-you-go-Modell für sofortigen Zugriff. Abonnement sorgt für Kosteneinsparungen bei langfristiger, planbarer Nutzung.
2. Vielfältige leistungsstarke GPU-Optionen
| Klasse | GPU |
| Consumer | RTX 3090 24GB, RTX 4090 24GB, RTX 4090 24GB (High Frequency), RTX 5090 32GB |
| Workstation | RTX 6000 Ada 48GB |
| Rechenzentrum | L40S 48GB, A100 SXM 80GB, H100 SXM 80GB, H200 SXM 141GB, B200 192GB |
Probieren Sie Novita AI GPUs jetzt aus!
3. Vorkonfigurierte Vorlagen verfügbar
Vorkonfigurierte Vorlagen eliminieren den Aufwand manueller Einrichtung, indem sie nicht nur optimierte Umgebungen für beliebte Modelle bieten, sondern auch validierte Bereitstellungsparameter, Umgebungsvariablen und Container-Konfigurationen enthalten. Dadurch können Sie sofort mit Modellen wie DeepSeek, Llama und anderen führenden KI-Frameworks starten.
Zusätzlich bietet die Unterstützung für benutzerdefinierte Vorlagen fortgeschrittenen Benutzern volle Flexibilität über ihre Umgebung. Das bedeutet, dass sie spezialisierte Setups mit personalisierten Bereitstellungsskripten, benutzerdefinierten Software-Stacks und fein abgestimmten Optimierungseinstellungen erstellen können, sodass einzigartige Anforderungen vollständig erfüllt werden.
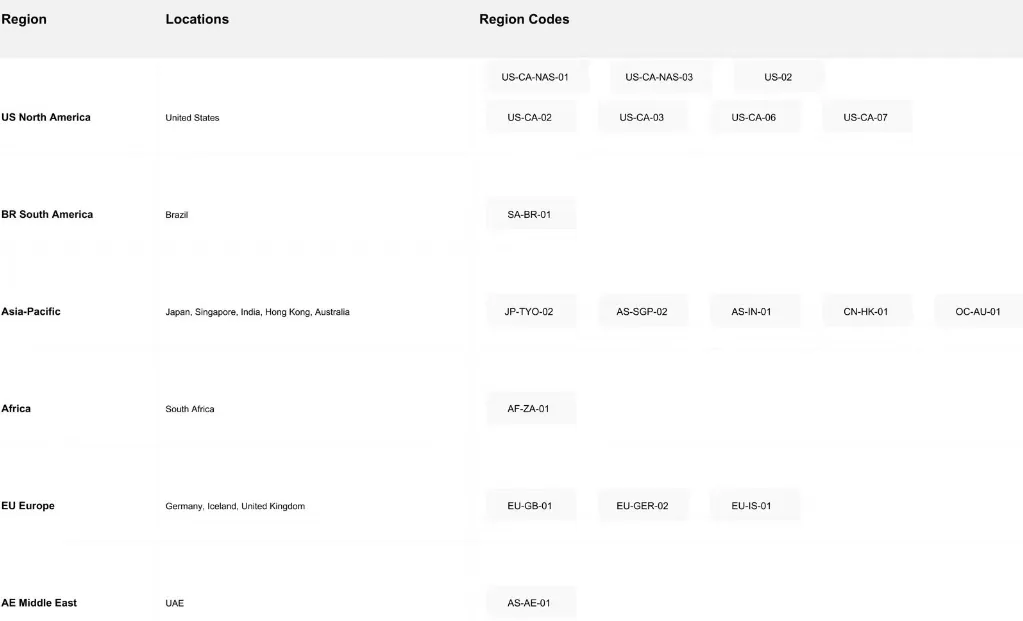
4. Globales Bereitstellungsnetzwerk
Novita AI betreibt eine globale Infrastruktur mit 18 Zonen auf mehreren Kontinenten, die eine breite und zuverlässige weltweite Abdeckung gewährleistet:
5. Optimierte Benutzererfahrung
Novita AI optimiert Abläufe durch Echtzeit-Überwachung, flexible Ressourcenskalierung, einfache Image-Upgrades und automatisches Failover und liefert stabile, zuverlässige GPU-Instanzen.
Erste Schritte mit der GPU-Instanz von Novita AI
Schritt 1: Melden Sie sich an oder erstellen Sie ein Konto & Rufen Sie den Bereich „GPUs -> GPU-Instanz“ auf
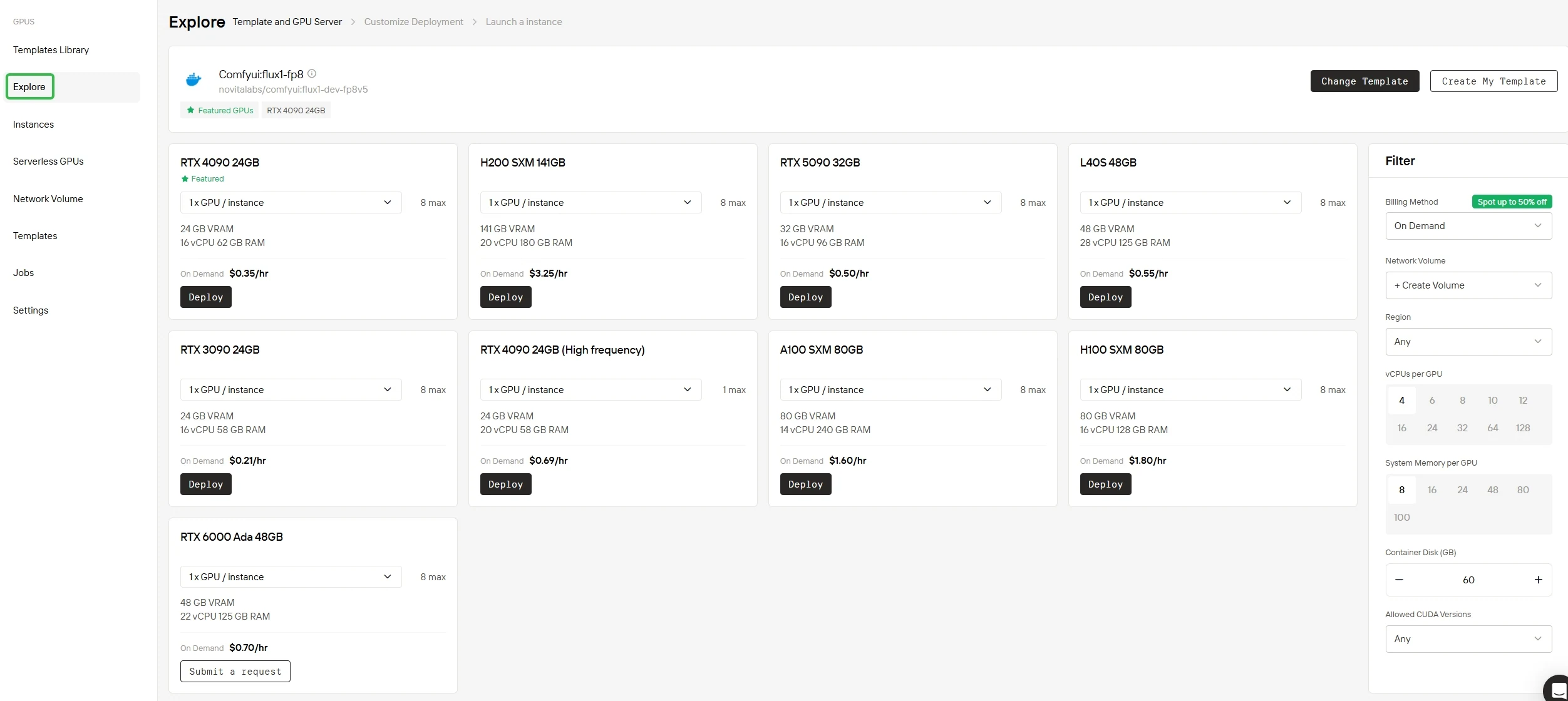
Schritt 2: Wählen Sie Ihre GPU aus
Egal, ob Sie auf unsere Bibliothek mit vorkonfigurierten Vorlagen zurückgreifen oder ein vollständig angepasstes Setup entwerfen: Die Plattform stellt alle wesentlichen Komponenten zur Verfügung, die Sie benötigen. Ausgestattet mit modernster Hardware wie NVIDIA B200 SXM oder H200 SXM GPUs mit großer Speicherkapazität liefert sie selbst für Ihre anspruchsvollsten KI-Workloads eine außergewöhnliche Leistung.
Wählen Sie jetzt Ihre GPU aus!
B200 SXM Bare Metal GPU verfügbar auf Novita AI
Für Benutzer, die noch mehr Kontrolle und dedizierte Leistung suchen, bietet Novita AI auch die B200 SMX Bare Metal-Mietoption an.
Jeder B200 SXM Bare-Metal-Knoten umfasst 8 GPUs (je 180 GB VRAM), 144 vCPUs und 30,8 TB Speicher. Im Gegensatz zu verwalteten, flexiblen GPU-Instanzen stellt Bare Metal den gesamten physischen Server mit exklusiven Ressourcen bereit. Es bietet volle Kontrolle, erfordert aber den Betrieb und die Wartung im eigenen Haus.
Häufig gestellte Fragen
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche, zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.
Empfohlene Lektüre
H100 vs H200: Ein umfassender Vergleich für 2025
B200 auf Novita AI: Nur 4,77 $/Stunde für die Ausführung von DeepSeek R1!
Mieten Sie NVIDIA H200 auf Abruf für 3,25 $/Stunde auf Novita AI



