

The NVIDIA B200 is here—bare metal, blazing fast, and now available at Novita AI.
Experience over 30,000 tokens per second on DeepSeek-R1 with the NVIDIA B200—powered by next-gen Blackwell architecture and built for LLMs, generative AI, and enterprise-scale inference. No hardware? No problem. Novita AI gives you on-demand access at a fraction of the cost.
What is B200?
The NVIDIA B200 is a next-generation GPU built on the Blackwell architecture, delivering breakthrough AI performance with up to 72 petaFLOPS for training and 144 petaFLOPS for inference, making it ideal for large language models and generative AI workloads.

Key Performance Metrics
| Component | Details |
| GPU | 8x NVIDIA Blackwell GPUs |
| GPU Memory | 1,440GB total, 64TB/s HBM3e bandwidth |
| Performance | 72 petaFLOPS FP8 training and 144 petaFLOPS FP4 inference |
| NVIDIA NVSwitch | 2x |
| NVIDIA NVLink Bandwidth | 14.4 TB/s aggregate bandwidth |
| System Power Usage | ~14.3kW max |
| CPU | 2x Intel Xeon Platinum 8570 Processors, 112 Cores total, 2.1 GHz (Base), 4 GHz (Max Boost) |
| System Memory | 2TB, configurable to 4TB |
| Networking | 4x OSFP ports (8x single-port NVIDIA ConnectX-7 VPI), Up to 400Gb/s Infiniband/Ethernet; 2x dual-port QSFP112 BlueField-3 DPU, Up to 400Gb/s Infiniband/Ethernet |
| Management Network | 10Gb/s onboard NIC with RJ45; 100Gb/s dual-port Ethernet NIC; BMC with RJ45 |
| Storage | OS: 2x 1.9TB NVMe M.2, Internal: 8x 3.84TB NVMe U.2 |
| Software | NVIDIA AI Enterprise, NVIDIA Mission Control, NVIDIA Runai Technology, NVIDIA DGX OS / Ubuntu |
| Rack Units (RU) | 10 RU |
| System Dimensions | Height: 17.5in (444mm), Width: 19.0in (482.2mm), Length: 35.3in (897.1mm) |
| Operating Temperature | 5–30°C (41–86°F) |
| Enterprise Support | 3-year standard support for hardware/software; 24/7 support portal access; live agent during business hours |
This is essentially an AI supercomputer that can:
- Train advanced AI models (like ChatGPT, Claude)
- Serve thousands of AI inference requests simultaneously
- Process massive datasets for research or business intelligence
- Power AI applications for entire organizations
Cost Efficiency of the B200
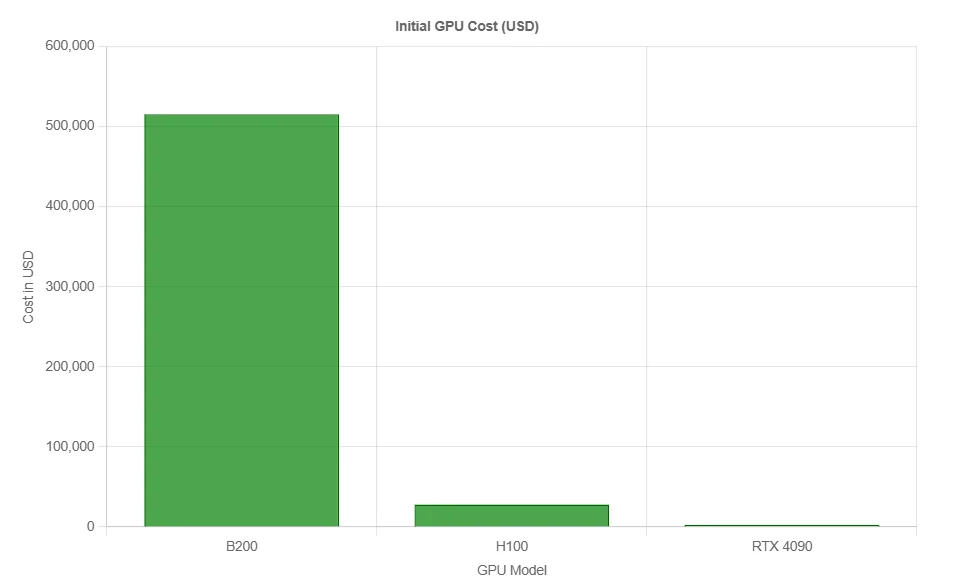
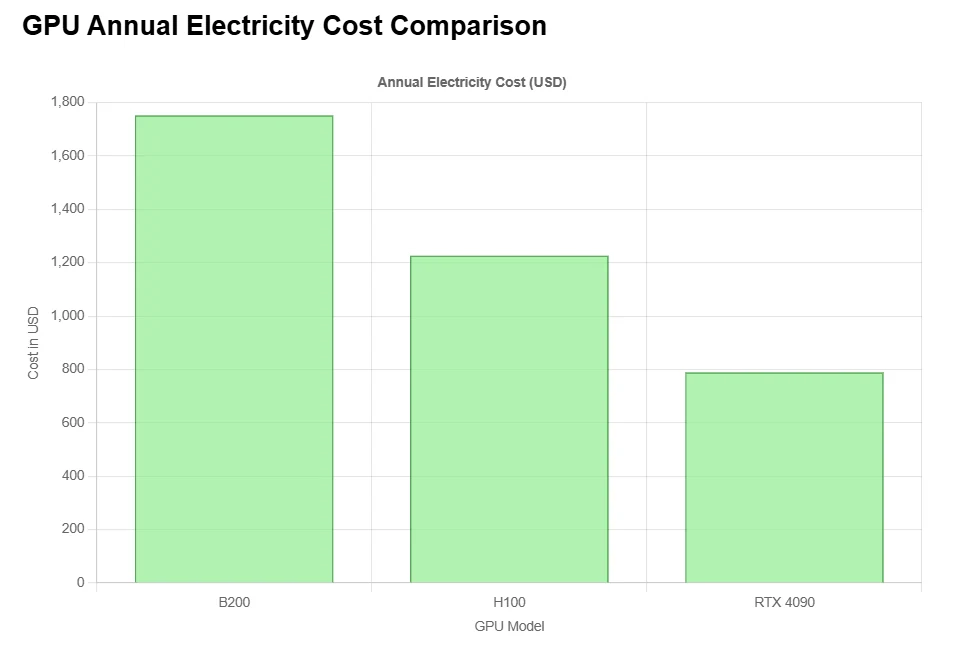
This price isn’t for a single GPU. It typically covers a full DGX system with:
- 8x Blackwell B200 GPUs
- Dual Xeon CPUs
- High-speed NVLink & NVSwitch interconnects
- 1.44TB HBM3e GPU memory
- 2TB+ system RAM
- Enterprise-grade networking, SSDs, and software stack (NVIDIA AI Enterprise, Run:ai, etc.)
Application of B200
1. AI Training and Inference
The B200 excels in both training and inference of large-scale AI models, particularly large language models (LLMs) and generative AI applications.
- Training: With its second-generation Transformer Engine and support for FP4 precision, the B200 accelerates the training process of massive models, reducing time and computational resources required.
- Inference: The B200 delivers exceptional inference performance, achieving over 1,000 tokens per second per user in benchmarks with models like Meta’s Llama 4 Maverick.
2. Graphics and Visualization
While primarily designed for AI workloads, the B200 also supports advanced graphics and visualization tasks:
- Ray Tracing: Equipped with 4th-generation RT Cores, the B200 can perform real-time ray tracing, enabling high-fidelity rendering for complex scenes.
- Shader Technology: The GPU’s architecture includes enhancements like Shader Execution Reordering (SER) 2.0, optimizing the execution of complex shader programs and compute kernels.
3. Precision Workloads
The B200 is adept at handling precision-intensive tasks across various scientific and industrial domains:
- The NVIDIA B200 GPU, based on the Blackwell architecture, does support floating-point (FP) operations through its fifth-generation Tensor Cores. These Tensor Cores are designed to handle a variety of FP precisions, including FP4, FP6, FP8, FP16, and TF32, enabling efficient acceleration of AI workloads.
B200+Deepseek R1=World Record
| GPU Setup | Total Throughput | Notes |
|---|---|---|
| 8x NVIDIA B200 (DGX B200) | Over 30,000 tokens/s | Achieved using TensorRT-LLM with FP4 precision |
| 8x NVIDIA H200 (HGX H200) | Up to 3,872 tokens/s | Utilized NVIDIA NIM microservice |
| 8x NVIDIA H100 (Quantized 4-bit) | Approximately 2,500 tokens/s | Deployed with vLLM 0.7.3 |
| 4x NVIDIA H100 | 25 tokens/s | Real-world test on Lambda Cloud |
| Single NVIDIA RTX 4090 (24GB) | 3–33 tokens/s | Performance varies based on quantization and configuration |
In summary, the NVIDIA B200 GPU stands out as the top performer for DeepSeek-R1 inference, offering unparalleled throughput that enables efficient deployment of large language models in enterprise environments.
How to Run B200 at a very Cost-effectively Price?
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing a affordable and reliable GPU cloud for building and scaling.
Step 1: Log In and Access the GPU Bare Metal
Log in to your account and click on the GPU Bare Metal button.
Step2: Chooose Your GPU
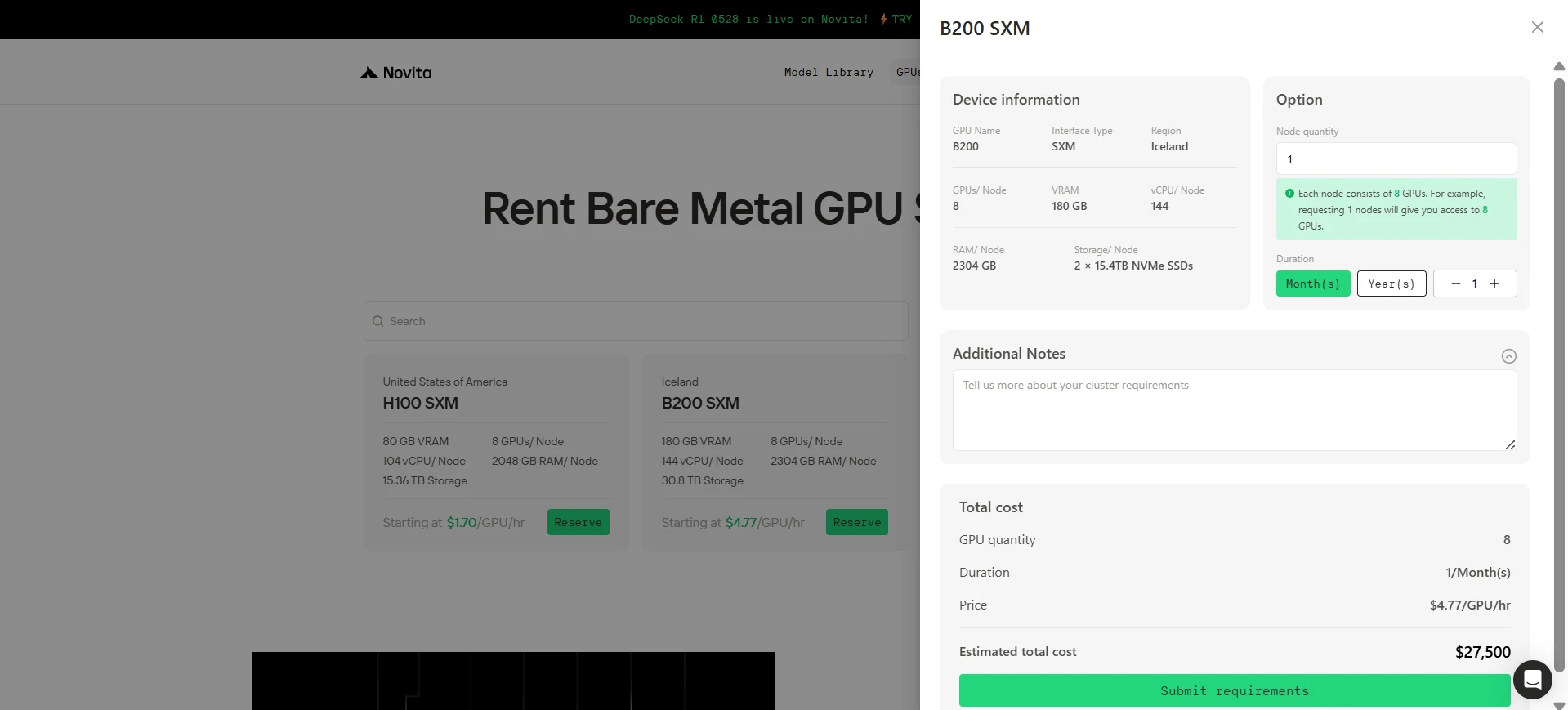
Select the Device
- Device Name: Choose H100 SXM or B200 SXM.
- Region: United States of America.
- Configuration (for H100 SXM):
- 8 GPUs
- 2048 GB Memory
- 104vCPU/Node
- 15.36 TB Storage
- at $1.7./hour.
- Configuration (for B200 SXM):
- 8 GPUs
- 2304 GB Memory
- 144vCPU/Node
- 30.8 TB Storage
- at $4.77./hour.
Set the Quantity and Rental Duration
-
Adjust the GPU Quantity field to match your needs. For example, select 8 GPUs.
-
Choose the rental duration. For instance, set it to 1 month.
The NVIDIA B200 GPU, built on the Blackwell architecture, is a cutting-edge AI supercomputer designed for extreme performance across training, inference, graphics, and precision workloads. With world-record throughput for DeepSeek-R1 and an optimized FP4/FP8 Transformer Engine, it delivers unmatched efficiency for large-scale generative AI. While the initial system cost is high, platforms like Novita AI offer flexible, cost-effective cloud access to B200 hardware—making top-tier AI accessible without infrastructure overhead.
[Book a Demo Now
A Direct Link to Bare Metal Novita AI Now!](https://meet.brevo.com/novita-ai/contact-sales)
Frequently Asked Questions
What is the NVIDIA B200?
The B200 is NVIDIA’s latest GPU based on the Blackwell architecture, offering 72 petaFLOPS (FP8) for training and 144 petaFLOPS (FP4) for inference—ideal for LLMs, generative AI, and scientific computing.
What models run best on B200?
The B200 excels with large models like DeepSeek-R1, Llama 4 Maverick, and other multi-billion parameter LLMs, thanks to its high throughput and memory.
What’s the DeepSeek-R1 inference performance on B200?
With 8x B200 GPUs, DeepSeek-R1 achieves over 30,000 tokens per second, far exceeding H100 and H200 setups.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



