

NVIDIA B200 来了——裸金属、极速,现已于 Novita AI 提供。
在 DeepSeek-R1 上体验超过 30,000 令牌/秒 ** 的性能——搭载 NVIDIA B200,基于下一代 Blackwell 架构,专为 LLM、生成式 AI 和企业级推理设计。没有硬件?没问题。Novita AI 以 ** 按需访问 模式提供,成本仅为传统方案的一小部分。
B200 是什么?
NVIDIA B200 是基于 Blackwell 架构的下一代 GPU,提供突破性的 AI 性能:训练高达 72 petaFLOPS,推理高达 144 petaFLOPS,非常适合大型语言模型和生成式 AI 工作负载。

关键性能指标
| **组件 ** | ** 详情** |
| GPU | 8× NVIDIA Blackwell GPU |
| GPU 内存 | 总容量 1,440GB,HBM3e 带宽 64TB/s |
| 性能 | 训练 72 petaFLOPS FP8,推理 144 petaFLOPS FP4 |
| NVIDIA NVSwitch | 2× |
| NVIDIA NVLink 带宽 | 总带宽 14.4 TB/s |
| 系统功耗 | 约 14.3kW 最大 |
| CPU | 2× Intel Xeon Platinum 8570 处理器,共 112 核,2.1 GHz(基础频率),4 GHz(最大睿频) |
| 系统内存 | 2TB,可配置至 4TB |
| 网络 | 4× OSFP 端口(8× 单端口 NVIDIA ConnectX-7 VPI),最高 400Gb/s InfiniBand/以太网;2× 双端口 QSFP112 BlueField-3 DPU,最高 400Gb/s InfiniBand/以太网 |
| 管理网络 | 10Gb/s 板载 NIC(RJ45);100Gb/s 双端口以太网 NIC;BMC(RJ45) |
| 存储 | 操作系统:2× 1.9TB NVMe M.2,内部:8× 3.84TB NVMe U.2 |
| 软件 | NVIDIA AI Enterprise、NVIDIA Mission Control、NVIDIA Runai Technology、NVIDIA DGX OS / Ubuntu |
| 机架单元(RU) | 10 RU |
| 系统尺寸 | 高 17.5in (444mm),宽 19.0in (482.2mm),深 35.3in (897.1mm) |
| 工作温度 | 5–30°C (41–86°F) |
| 企业支持 | 3 年标准硬件/软件支持;24/7 支持门户访问;工作时间在线客服 |
这本质上是一台 AI 超级计算机,能够:
- 训练高级 AI 模型(如 ChatGPT、Claude)
- 同时处理数千个 AI 推理请求
- 处理用于研究或商业智能的海量数据集
- 为整个组织提供 AI 应用支持
B200 的成本效益
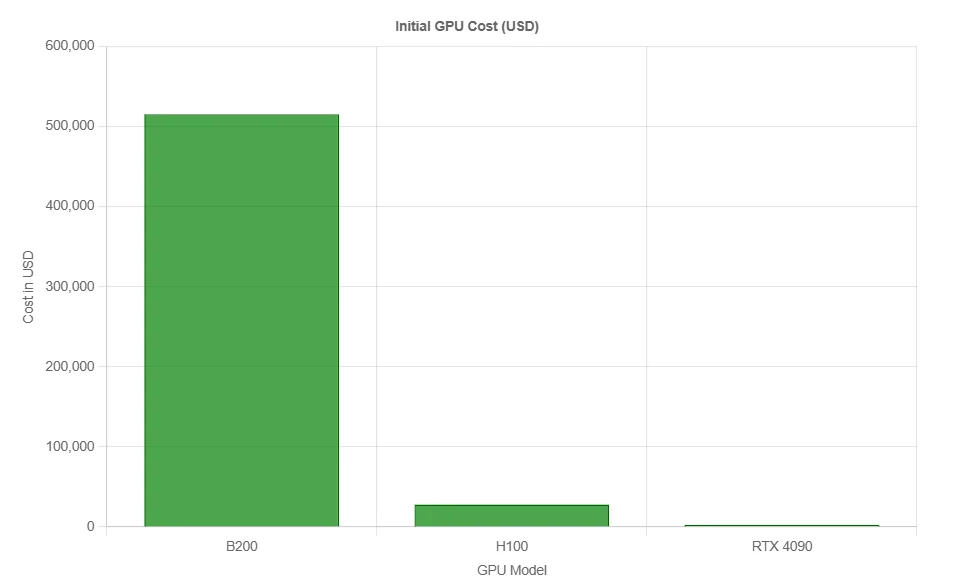
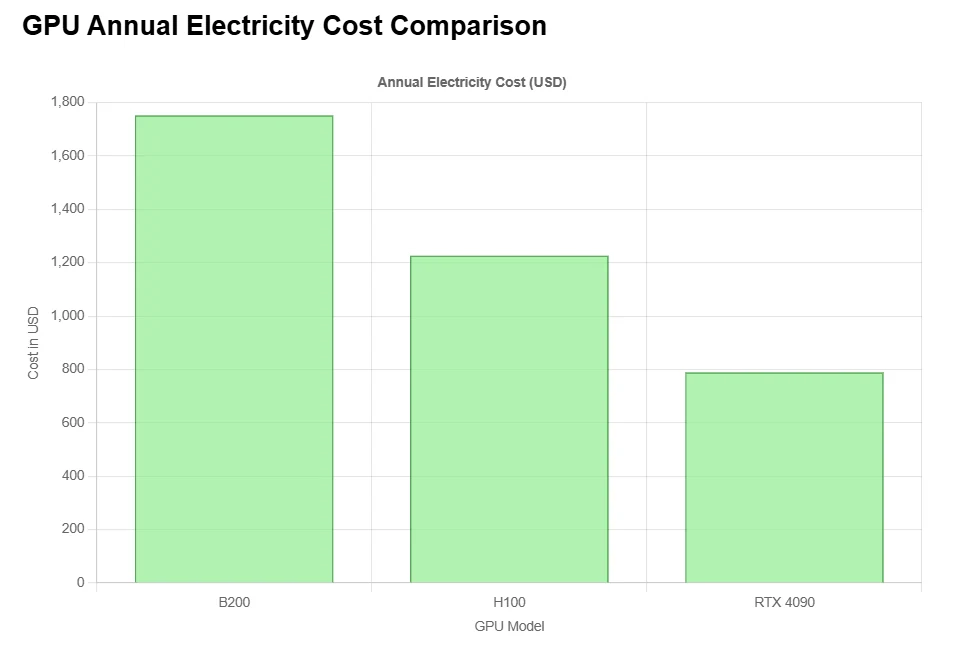
此价格并非针对单个 GPU。它通常涵盖一个完整的 DGX 系统,包括:
- 8× Blackwell B200 GPU
- 双路 Xeon CPU
- 高速 NVLink 和 NVSwitch 互连
- 1.44TB HBM3e GPU 内存
- 2TB+ 系统内存
- 企业级网络、SSD 及软件栈(NVIDIA AI Enterprise、Run:ai 等)
B200 的应用
1. AI 训练与推理
B200 在大型 AI 模型的训练和推理方面表现出色,尤其适用于大型语言模型(LLM)和生成式 AI 应用。
- 训练:凭借第二代 Transformer Engine 和对 FP4 精度的支持,B200 加速了大规模模型的训练过程,减少了所需的时间和计算资源。
- 推理:B200 提供卓越的推理性能,在 Meta 的 Llama 4 Maverick 等模型基准测试中,每个用户每秒超过 1,000 令牌。
2. 图形与可视化
虽然主要为 AI 工作负载设计,B200 也支持高级图形和可视化任务:
- 光线追踪:配备第 4 代 RT Core,B200 可执行实时光线追踪,为复杂场景实现高保真渲染。
- 着色器技术:GPU 架构包含 Shader Execution Reordering (SER) 2.0 等增强功能,优化复杂着色程序和计算内核的执行。
3. 精度密集型工作负载
B200 擅长处理各种科学和工业领域中对精度要求高的任务:
- NVIDIA B200 GPU 基于 Blackwell 架构,通过其第五代 Tensor Core 支持浮点(FP)运算。这些 Tensor Core 旨在处理多种 FP 精度,包括 FP4、FP6、FP8、FP16 和 TF32,从而高效加速 AI 工作负载。
B200 + DeepSeek R1 = 世界纪录
| **GPU 配置 ** | ** 总吞吐量 ** | ** 备注** |
|---|---|---|
| 8× NVIDIA B200(DGX B200) | 超过 30,000 令牌/秒 | 使用 TensorRT-LLM 和 FP4 精度实现 |
| 8× NVIDIA H200(HGX H200) | 高达 3,872 令牌/秒 | 使用 NVIDIA NIM 微服务 |
| 8× NVIDIA H100(4 位量化) | 约 2,500 令牌/秒 | 使用 vLLM 0.7.3 部署 |
| 4× NVIDIA H100 | 25 令牌/秒 | Lambda Cloud 实际测试 |
| 单 NVIDIA RTX 4090(24GB) | 3–33 令牌/秒 | 性能因量化和配置而异 |
总之,NVIDIA B200 GPU 在 DeepSeek-R1 推理方面表现最佳,提供无与伦比的吞吐量,使企业环境中的大型语言模型能够高效部署。
如何以极低成本运行 B200?
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 轻松部署 AI 模型的途径,同时还提供经济实惠且可靠的 GPU 云用于构建和扩展。
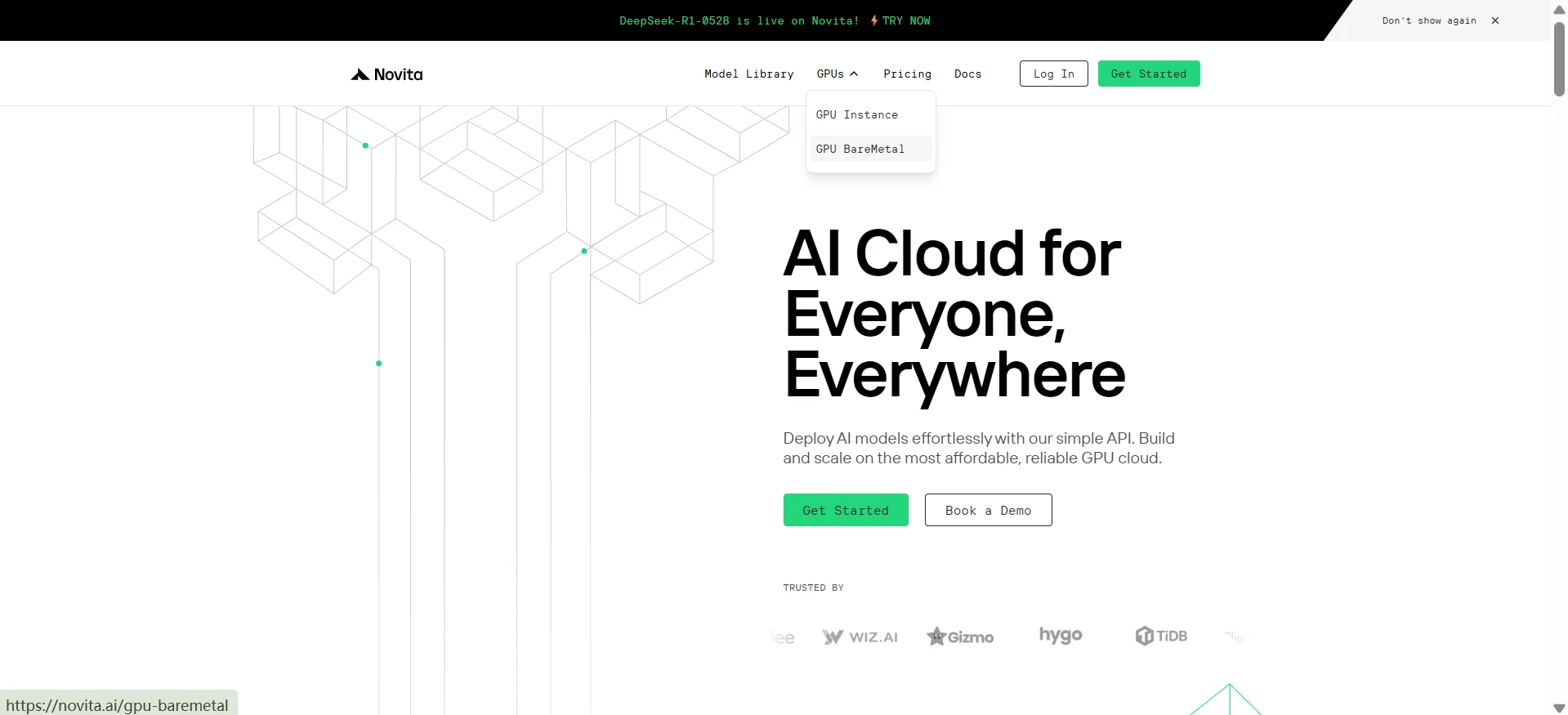
步骤 1:登录并访问 GPU 裸金属
登录您的账户,点击 GPU Bare Metal 按钮。
步骤 2:选择你的 GPU
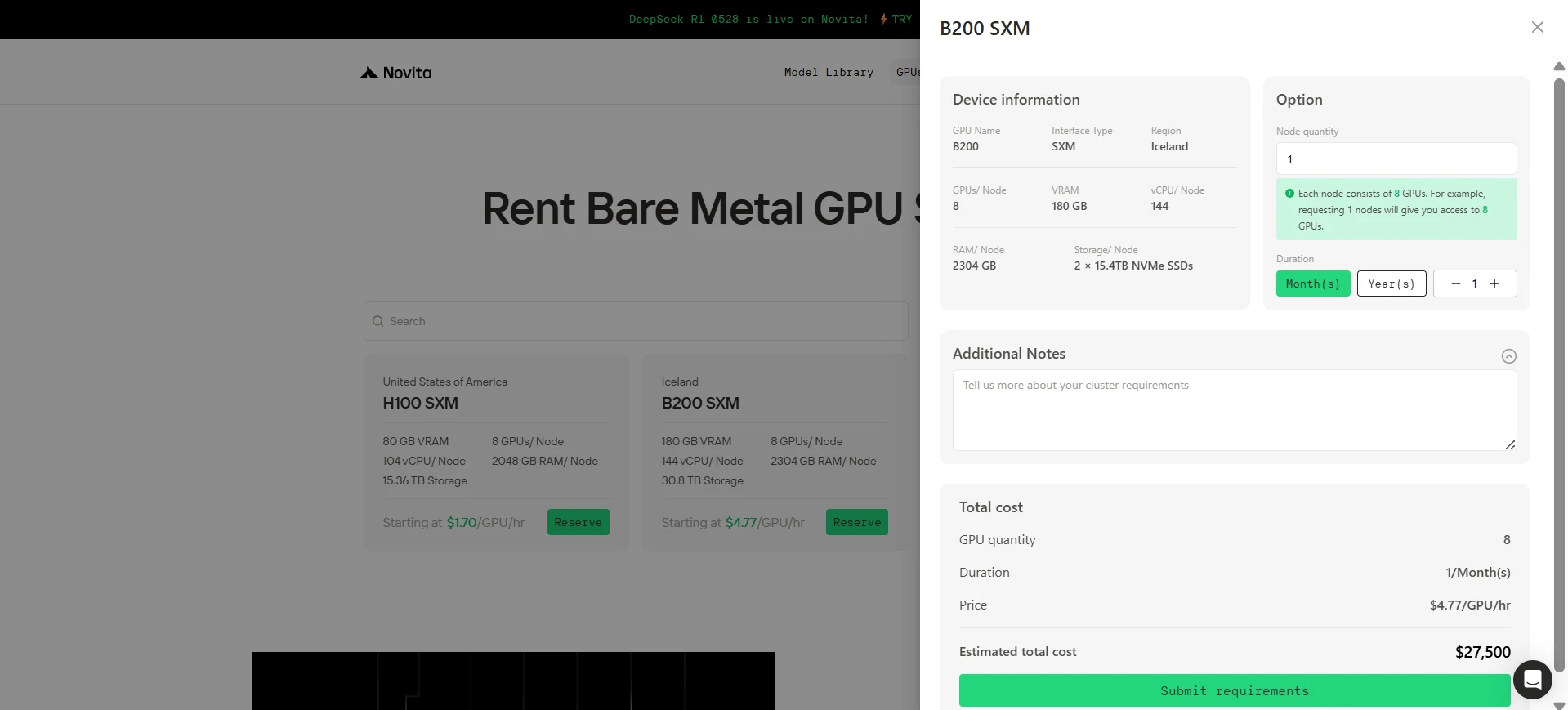
选择设备
- **设备名称 **:选择 H100 SXM 或 B200 SXM。
- 区域:美国。
- 配置(适用于 H100 SXM):
- 8 GPU
- 2048 GB 内存
- 104vCPU/节点
- 15.36 TB 存储
- 价格为 $1.7/小时。
- 配置(适用于 B200 SXM):
- 8 GPU
- 2304 GB 内存
- 144vCPU/节点
- 30.8 TB 存储
- 价格为 $4.77/小时。
设置数量 和租赁时长
- 根据需求调整 **GPU 数量 ** 字段。例如,选择 8 GPU。
- 选择租赁时长。例如,设置为 1 个月。
基于 Blackwell 架构的 NVIDIA B200 GPU 是一款尖端 AI 超级计算机,专为训练、推理、图形和精度密集型工作负载提供极致性能而设计。凭借 DeepSeek-R1 的世界纪录吞吐量和优化的 FP4/FP8 Transformer Engine,它为大规模生成式 AI 提供了无与伦比的效率。虽然初始系统成本较高,但像 Novita AI 这样的平台提供灵活、经济高效的 B200 硬件云访问——无需基础设施开销即可获得顶级 AI 能力。
[立即预约演示
直接链接到 Novita AI 裸金属!](https://meet.brevo.com/novita-ai/contact-sales)
常见问题
什么是 NVIDIA B200?
B200 是 NVIDIA 基于 Blackwell 架构的最新 GPU,提供 72 petaFLOPS(FP8)训练和 144 petaFLOPS(FP4)推理性能,非常适合 LLM、生成式 AI 和科学计算。
哪些模型在 B200 上运行效果最好?
B200 在大型模型(如 DeepSeek-R1、Llama 4 Maverick 及其他数十亿参数的 LLM)上表现卓越,得益于其高吞吐量和内存。
DeepSeek-R1 在 B200 上的推理性能如何?
使用 8× B200 GPU,DeepSeek-R1 每秒可处理超过 30,000 令牌,远超 H100 和 H200 配置。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 轻松部署 AI 模型的途径,同时还提供经济实惠且可靠的 GPU 云用于构建和扩展。



