

NVIDIA B200 هنا — خادم معدني فائق السرعة، متوفر الآن على Novita AI.
اختبر أكثر من 30,000 رمز في الثانية على DeepSeek-R1 باستخدام NVIDIA B200 — المدعوم بمعمارية Blackwell من الجيل التالي والمُصمَّم لنماذج اللغة الكبيرة والذكاء الاصطناعي التوليدي والاستدلال على مستوى المؤسسات. لا يوجد جهاز؟ لا مشكلة. Novita AI يُوفّر لك إمكانية الوصول عند الطلب بجزء صغير من التكلفة.
ما هو B200؟
NVIDIA B200 هو معالج رسوميات من الجيل التالي مبني على معمارية Blackwell، ويوفر أداءً ثوريًا في الذكاء الاصطناعي يصل إلى 72 بيتافلوب للتدريب و144 بيتافلوب للاستدلال، مما يجعله مثاليًا لنماذج اللغة الكبيرة وحمولات عمل الذكاء الاصطناعي التوليدي.

مقاييس الأداء الرئيسية
| المكوّن | التفاصيل |
| GPU | 8x معالجات NVIDIA Blackwell |
| ذاكرة GPU | 1,440 جيجابايت إجمالاً، عرض نطاق HBM3e 64 تيرابايت/ثانية |
| الأداء | 72 بيتافلوب تدريب FP8 و144 بيتافلوب استدلال FP4 |
| NVIDIA NVSwitch | 2x |
| عرض نطاق NVIDIA NVLink | 14.4 تيرابايت/ثانية إجمالي عرض النطاق |
| استهلاك طاقة النظام | ~14.3 كيلوواط كحد أقصى |
| CPU | 2x Intel Xeon Platinum 8570، 112 نواة إجمالاً، 2.1 جيجاهرتز (قاعدة)، 4 جيجاهرتز (تعزيز أقصى) |
| ذاكرة النظام | 2 تيرابايت، قابلة للتكوين حتى 4 تيرابايت |
| الشبكات | 4 منافذ OSFP (8 منافذ أحادية NVIDIA ConnectX-7 VPI)، حتى 400 جيجابايت/ثانية Infiniband/Ethernet؛ منفذا QSFP112 مزدوجان BlueField-3 DPU، حتى 400 جيجابايت/ثانية Infiniband/Ethernet |
| شبكة الإدارة | بطاقة NIC مدمجة 10 جيجابايت/ثانية مع RJ45؛ بطاقة Ethernet مزدوجة المنفذ 100 جيجابايت/ثانية؛ BMC مع RJ45 |
| التخزين | نظام التشغيل: 2x 1.9 تيرابايت NVMe M.2، داخلي: 8x 3.84 تيرابايت NVMe U.2 |
| البرمجيات | NVIDIA AI Enterprise، NVIDIA Mission Control، NVIDIA Runai Technology، NVIDIA DGX OS / Ubuntu |
| وحدات الرف (RU) | 10 RU |
| أبعاد النظام | الارتفاع: 17.5 بوصة (444 مم)، العرض: 19.0 بوصة (482.2 مم)، الطول: 35.3 بوصة (897.1 مم) |
| درجة حرارة التشغيل | 5–30 درجة مئوية (41–86 درجة فهرنهايت) |
| دعم المؤسسات | دعم قياسي لمدة 3 سنوات للعتاد/البرمجيات؛ بوابة دعم على مدار الساعة؛ وكيل مباشر خلال ساعات العمل |
هذا أساسًا حاسوب فائق للذكاء الاصطناعي يمكنه:
- تدريب نماذج ذكاء اصطناعي متقدمة (مثل ChatGPT، Claude)
- خدمة آلاف طلبات استدلال الذكاء الاصطناعي بشكل متزامن
- معالجة مجموعات بيانات ضخمة للبحث أو ذكاء الأعمال
- تشغيل تطبيقات ذكاء اصطناعي لمؤسسات بأكملها
كفاءة تكلفة B200
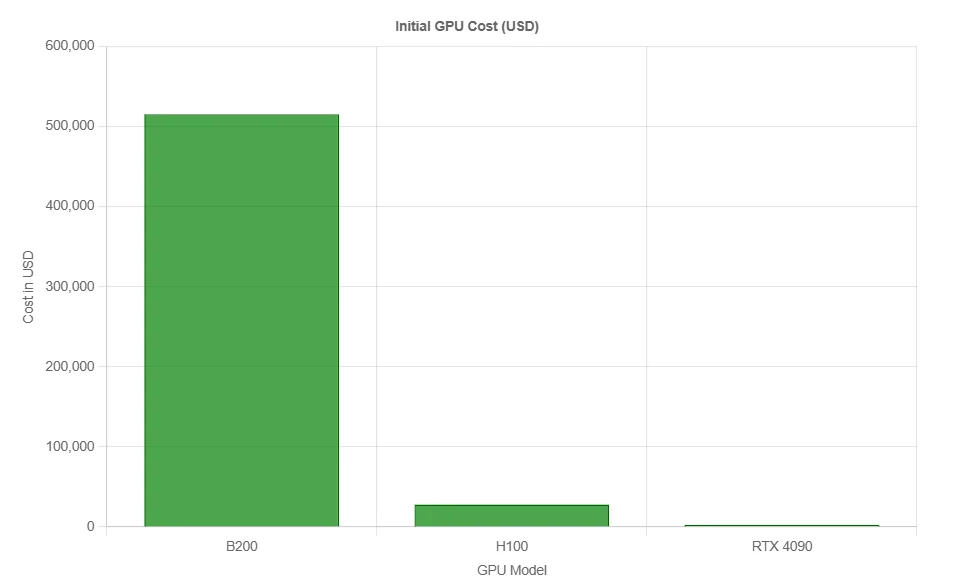
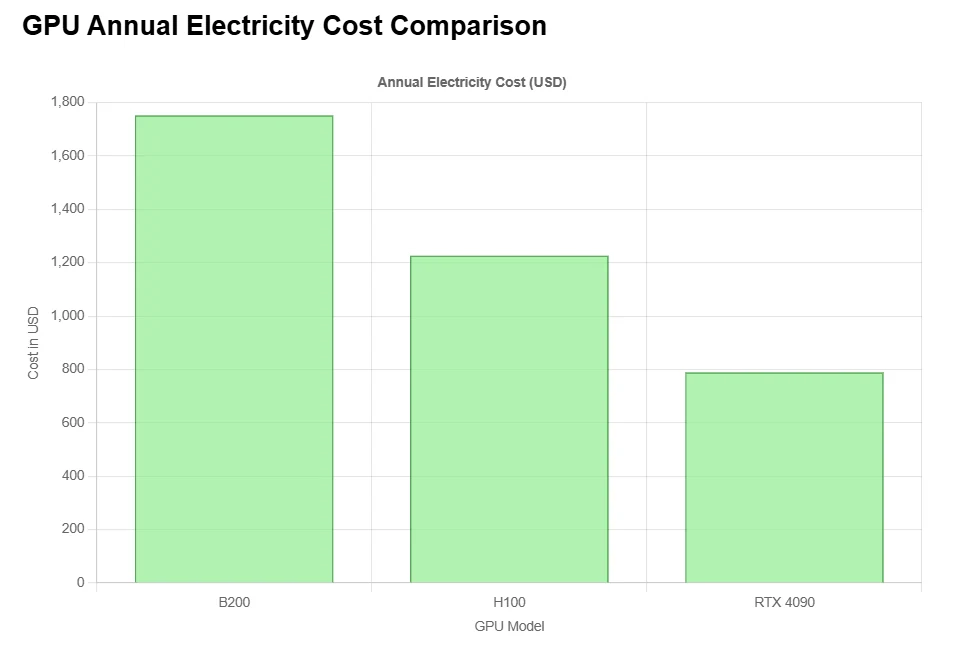
هذا السعر ليس لمعالج GPU واحد. إنه يغطي عادةً نظام DGX كامل مع:
- 8x معالجات Blackwell B200 GPU
- معالجي Xeon مزدوجين
- وصلات NVLink و NVSwitch عالية السرعة
- 1.44 تيرابايت من ذاكرة GPU HBM3e
- 2 تيرابايت+ من ذاكرة الوصول العشوائي للنظام
- شبكات وأقراص SSD ومكدس برمجيات من فئة المؤسسات (NVIDIA AI Enterprise، Run:ai، إلخ.)
تطبيقات B200
1. تدريب واستدلال الذكاء الاصطناعي
يتفوق B200 في كل من تدريب واستدلال نماذج الذكاء الاصطناعي واسعة النطاق، خاصة نماذج اللغة الكبيرة (LLMs) وتطبيقات الذكاء الاصطناعي التوليدي.
- التدريب: بفضل محرك المحولات من الجيل الثاني ودعم دقة FP4، يُسرّع B200 عملية تدريب النماذج الضخمة، مما يُقلّل الوقت والموارد الحاسوبية المطلوبة.
- الاستدلال: يُقدّم B200 أداءً استثنائيًا في الاستدلال، محققًا أكثر من 1,000 رمز في الثانية لكل مستخدم في المعايير مع نماذج مثل Llama 4 Maverick من Meta.
2. الرسوميات والتصور
على الرغم من تصميمه الأساسي لأعباء عمل الذكاء الاصطناعي، إلا أن B200 يدعم أيضًا مهام الرسوميات والتصور المتقدمة:
- تتبع الأشعة: مزود بنوى RT من الجيل الرابع، يمكن لـ B200 تنفيذ تتبع الأشعة في الوقت الفعلي، مما يتيح عرضًا عالي الدقة للمشاهد المعقدة.
- تقنية التظليل: تتضمن بنية المعالج تحسينات مثل إعادة ترتيب تنفيذ التظليل (SER) 2.0، مما يُحسّن تنفيذ برامج التظليل والعمليات الحسابية المعقدة.
3. أعباء العمل الدقيقة
يتقن B200 التعامل مع المهام كثيفة الدقة عبر مجالات علمية وصناعية متنوعة:
- يدعم معالج NVIDIA B200، المبني على معمارية Blackwell، عمليات الفاصلة العائمة (FP) عبر نوى Tensor من الجيل الخامس. صُمّمت نوى Tensor هذه للتعامل مع مجموعة متنوعة من دقة FP، بما في ذلك FP4 و FP6 و FP8 و FP16 و TF32، مما يتيح تسريعًا فعالاً لأعباء عمل الذكاء الاصطناعي.
B200 + DeepSeek R1 = رقم قياسي عالمي
| إعداد GPU | الإنتاجية الإجمالية | ملاحظات |
|---|---|---|
| 8x NVIDIA B200 (DGX B200) | أكثر من 30,000 رمز/ثانية | تحقق باستخدام TensorRT-LLM بدقة FP4 |
| 8x NVIDIA H200 (HGX H200) | حتى 3,872 رمزًا/ثانية | استخدام خدمة NVIDIA NIM المصغرة |
| 8x NVIDIA H100 (مكمّم بدقة 4 بت) | حوالي 2,500 رمز/ثانية | نشر باستخدام vLLM 0.7.3 |
| 4x NVIDIA H100 | 25 رمزًا/ثانية | اختبار فعلي على سحابة Lambda |
| واحد NVIDIA RTX 4090 (24 جيجابايت) | 3–33 رمزًا/ثانية | يختلف الأداء بناءً على التكميم والتكوين |
باختصار، يبرز معالج NVIDIA B200 GPU كأفضل أداء لاستدلال DeepSeek-R1، مما يُوفّر إنتاجية لا مثيل لها تُمكّن من نشر فعال لنماذج اللغة الكبيرة في بيئات المؤسسات.
كيفية تشغيل B200 بسعر فعال جدًا؟
Novita AI هي منصة سحابية للذكاء الاصطناعي تُوفّر للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة تطبيقات بسيطة، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.
الخطوة 1: تسجيل الدخول والوصول إلى الخادم المعدني GPU
سجّل الدخول إلى حسابك وانقر على زر GPU Bare Metal.
الخطوة 2: اختر معالج GPU الخاص بك
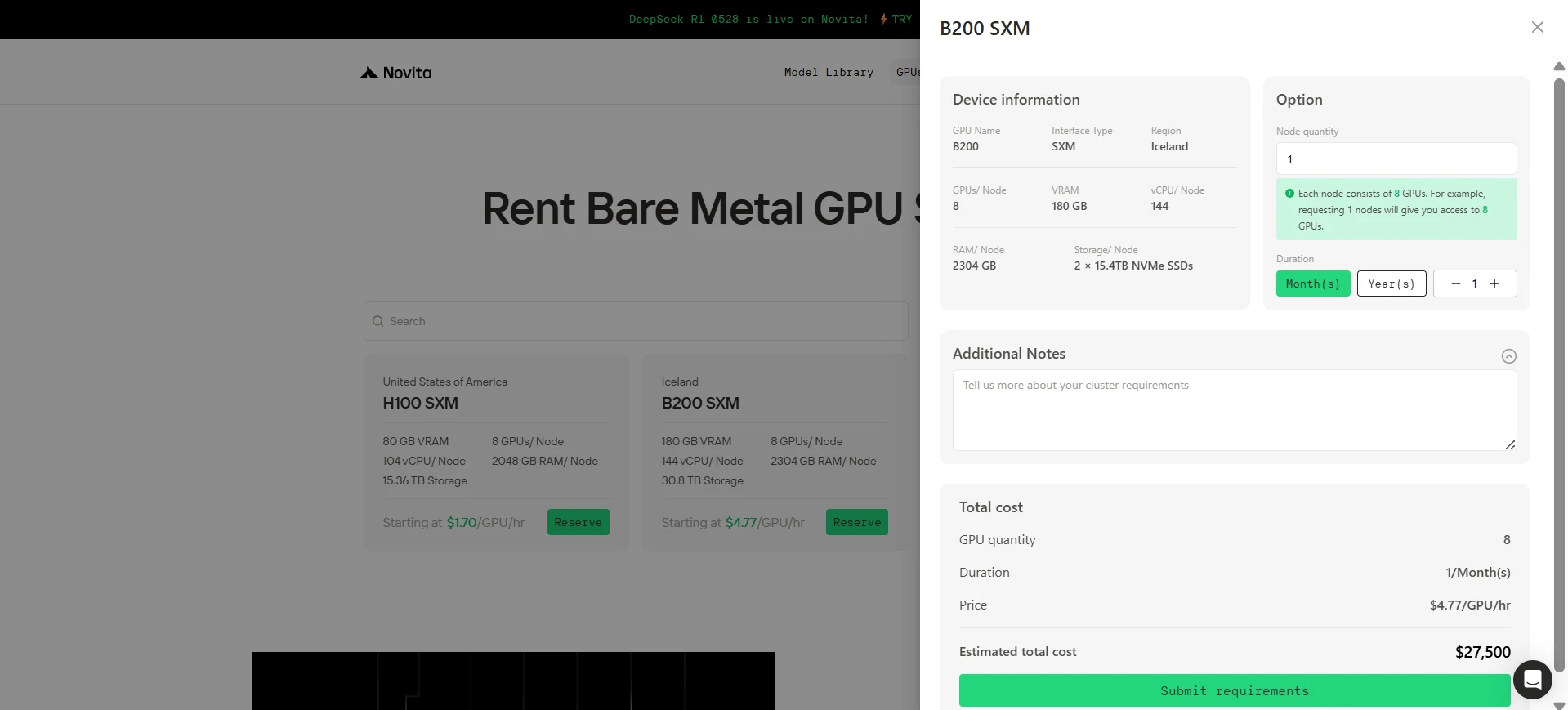
اختر الجهاز
- اسم الجهاز: اختر H100 SXM أو B200 SXM.
- المنطقة: الولايات المتحدة الأمريكية.
- التكوين (لـ H100 SXM):
- 8 معالجات GPU
- 2048 جيجابايت ذاكرة
- 104 vCPU/عقدة
- 15.36 تيرابايت تخزين
- بسعر 1.7 دولار/ساعة.
- التكوين (لـ B200 SXM):
- 8 معالجات GPU
- 2304 جيجابايت ذاكرة
- 144 vCPU/عقدة
- 30.8 تيرابايت تخزين
- بسعر 4.77 دولار/ساعة.
اضبط الكمية ومدة الإيجار
- اضبط حقل كمية GPU وفقًا لاحتياجاتك. على سبيل المثال، اختر 8 معالجات GPU.
- اختر مدة الإيجار. على سبيل المثال، اضبطها على شهر واحد.
معالج NVIDIA B200 GPU، المبني على معمارية Blackwell، هو حاسوب فائق للذكاء الاصطناعي متطور مصمم للأداء المتطرف عبر التدريب والاستدلال والرسوميات وأعباء العمل الدقيقة. مع إنتاجية قياسية عالمية لـ DeepSeek-R1 ومحرك محولات FP4/FP8 محسّن، يُقدّم كفاءة لا تُضاهى للذكاء الاصطناعي التوليدي واسع النطاق. على الرغم من أن التكلفة الأولية للنظام مرتفعة، إلا أن منصات مثل Novita AI تُوفّر وصولاً سحابيًا مرنًا وفعّالاً من حيث التكلفة إلى أجهزة B200 — مما يجعل الذكاء الاصطناعي من الطراز الأول في متناول اليد دون أعباء البنية التحتية.
[احجز عرضًا توضيحيًا الآن
رابط مباشر إلى الخادم المعدني Novita AI الآن!](https://meet.brevo.com/novita-ai/contact-sales)
الأسئلة الشائعة
ما هو NVIDIA B200؟
B200 هو أحدث معالج GPU من NVIDIA يعتمد على معمارية Blackwell، ويُوفّر 72 بيتافلوب (FP8) للتدريب و144 بيتافلوب (FP4) للاستدلال — مثالي لنماذج اللغة الكبيرة والذكاء الاصطناعي التوليدي والحوسبة العلمية.
ما النماذج التي تعمل بشكل أفضل على B200؟
يتفوق B200 مع النماذج الكبيرة مثل DeepSeek-R1 و Llama 4 Maverick وغيرها من نماذج اللغة ذات المليارات من المعاملات، بفضل إنتاجيته العالية وذاكرته.
ما أداء استدلال DeepSeek-R1 على B200؟
مع 8 معالجات B200 GPU، يُحقق DeepSeek-R1 أكثر من 30,000 رمز في الثانية، متجاوزًا بكثير إعدادات H100 و H200.
Novita AI هي منصة سحابية للذكاء الاصطناعي تُوفّر للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة تطبيقات بسيطة، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.



