

GPU NVIDIA H200 и B200 являются двумя наиболее передовыми решениями на современном рынке оборудования для ИИ. Каждый из них имеет свои сильные стороны, что делает их подходящими для разных сценариев использования при инференсе и обучении моделей.
В этой статье мы подробно рассмотрим оба GPU, выделим их преимущества и варианты использования, чтобы понять, как каждый из них подходит для разных рабочих нагрузок ИИ.
H200 vs B200: Особенности
| Параметр | 1× H200 SMX | 1× B200 |
| Архитектура | Hooper | Blackwell |
| GPU Memory | 141GB HBM3e | 192GB HBM3e |
| Memory Bandwidth | 4.8TB/s | 8TB/s |
| Tensor Core | Up to 4 PFLOPS FP8 | Up to 5 PFLOPS FP8 and 9 PFLOPS FP4 |
H200 vs B200: Ключевые преимущества
1× H200 SXM
- Высокоемкая память: Оснащенный 141 ГБ памяти HBM3e и пропускной способностью 4,8 ТБ/с, H200 может работать с значительно более крупными наборами данных, чем его предшественники. В результате такая конструкция с высокой емкостью минимизирует узкие места в памяти и ускоряет передачу данных, что позволяет запускать сложные рабочие нагрузки — такие как инференс языковых моделей с длинным контекстом и научные симуляции — с большей стабильностью и эффективностью. В итоге это обеспечивает более плавное масштабирование и стабильную производительность при решении сложных задач ИИ и высокопроизводительных вычислений (HPC).
- Производительность Tensor Core FP8: H200 обеспечивает вычислительную мощность FP8 до 4 PFLOPS, что представляет собой значительный скачок в эффективности для рабочих нагрузок ИИ. В частности, формат FP8 обеспечивает практический баланс между пропускной способностью вычислений и точностью, что делает его особенно подходящим для генеративного ИИ промышленного уровня. Более того, обеспечивая более быстрый инференс без серьезного снижения точности, FP8 делает H200 высокоэффективным вариантом для разработчиков и предприятий, развертывающих ИИ в крупных масштабах.
- Архитектура, оптимизированная для инференса: Аппаратная конструкция H200 ориентирована на низкую задержку и энергоэффективный инференс. Как следствие, такая оптимизация позволяет создавать отзывчивые системы ИИ, способные поддерживать приложения в реальном времени — от моделей генеративного ИИ до рекомендательных систем. При этом, снижая энергопотребление при сохранении высокой вычислительной мощности, H200 обеспечивает надежный баланс производительности и эффективности для длительных операций с высокой нагрузкой на инференс.
1× B200
- Больший объем памяти: Оснащенный 192 ГБ памяти HBM3e, B200 значительно превосходит H200 по объему чистой памяти. В результате такой дополнительной емкости позволяет развертывать сверхкрупные модели ИИ без необходимости разделения на части или сложного управления памятью. На практике для рабочих нагрузок, требующих больших наборов данных или более длинных контекстов последовательностей, B200 минимизирует ограничения и упрощает проектирование рабочих процессов, давая разработчикам большую гибкость при масштабировании своих систем.
- Поддержка точности FP4: Являясь одной из ключевых инноваций архитектуры Blackwell, B200 поддерживает операции Tensor Core в формате FP4. Как следствие, FP4 значительно повышает пропускную способность и энергоэффективность, что позволяет выполнять крупномасштабное обучение и инференс быстрее и с меньшими затратами. Более того, снижая вычислительные накладные расходы при сохранении функциональной точности, FP4 представляет собой прорыв, который напрямую выгоден организациям, стремящимся выйти за пределы возможностей по размеру и производительности моделей.
- Перспективная конструкция: Объединяя больший объем памяти, более высокую пропускную способность и продвинутые форматы точности, B200 спроектирован так, чтобы оставаться актуальным по мере усложнения моделей ИИ. Как следствие, такая перспективная конструкция гарантирует, что исследовательские группы и предприятия, инвестирующие в B200 сегодня, будут иметь вычислительный запас для поддержки новых рабочих нагрузок в ближайшие годы. В конечном итоге, он позиционируется не только как решение для современных передовых моделей, но и как стабильная основа для разработки ИИ следующего поколения.
Хотя B200 имеет явные преимущества в объеме памяти, точности и масштабируемости, H200 остается сильным и практичным выбором. Обеспечивая высокую производительность по более доступной цене, H200 является сбалансированным вариантом для бизнеса, который стремится к эффективности без больших инвестиций в системы следующего поколения.
H200 vs B200: Области применения
H200 SMX
- Генеративный ИИ и LLM: Отлично подходит для инференса с длинным контекстом, поддерживает продвинутые чат-боты и приложения для генерации контента.
- Высокопроизводительные вычисления (HPC): Производительность, основанная на высокой пропускной способности, ускоряет ресурсоемкие научные симуляции и задачи моделирования.
- Корпоративный инференс: Надежный вариант для крупномасштабного развертывания поисковых, рекомендательных и разговорных систем ИИ.
B200
- Разработка передового ИИ: Специально создан для обучения и инференса современных LLM и мультимодальных систем, выходящих за пределы текущих возможностей.
- Корпоративное развертывание в крупных масштабах: Обеспечивает необходимую мощность и вычислительный запас для стабильной работы высокопроизводительных платформ ИИ.
- Исследовательская инфраструктура: Подходит для организаций, создающих масштабируемые основы для поддержки следующей волны разработки моделей ИИ.
H200 vs B200: Цены
| GPU | Розничный диапазон цен | Цена за сервер/корпоративный пакет | Цена аренды в облаке |
|---|---|---|---|
| NVIDIA H200 | $30 000 - $40 000 | Может превышать $500 000 за полные системы | $3,25 в час (например, в Novita AI) |
| NVIDIA B200 | $45 000–$50 000 | Может превышать $500 000 за полные системы | $3,84 в час |
H200 и B200 задают планку производительности GPU, но для тех, кто стремится сбалансировать стоимость и гибкость, инвестиции в полные системы могут быть не оптимальным решением. Экземпляры GPU решают эту проблему — а платформа Novita AI предоставляет гибкие возможности, которые помогают разработчикам и бизнесу легко масштабироваться, делая эти GPU более доступными, чем когда-либо.
Пять причин получить доступ к H200 и B200 через экземпляры GPU Novita AI
1. Конкурентные цены и гибкая тарификация
Цены: Novita AI против RunPod
| Провайдер | H200 SMX | B200 SMX |
| Novita AI | $3,25/час | $3,84/час |
| RunPod | $3,59/час | $5,98/час |
Варианты тарификации
| GPU | Spot | On-Demand | Subscription |
| 1× H200 SMX | $1,63/час | $3,25/час | $2160 /час |
| 1× B200 SMX | $1,92/час | $3,84/час | - |
Spot предлагает сниженные тарифы с переменной доступностью. On-Demand работает по модели оплаты по мере использования для мгновенного доступа. Subscription обеспечивает экономию затрат при долгосрочном, предсказуемом использовании.
2. Разнообразные производительные GPU для любых задач
| Категория | GPU |
| Потребительские | RTX 3090 24GB, RTX 4090 24GB, RTX 4090 24GB (High Frequency), RTX 5090 32GB |
| Рабочие станции | RTX 6000 Ada 48GB |
| Центры обработки данных | L40S 48GB, A100 SXM 80GB, H100 SXM 80GB, H200 SXM 141GB, B200 192GB |
Попробуйте GPU Novita AI сейчас!
3. Доступные готовые шаблоны
Предварительно настроенные шаблоны избавляют от хлопот ручной настройки: они не только предлагают оптимизированные среды для популярных моделей, но и включают проверенные параметры развертывания, переменные окружения и конфигурации контейнеров. В результате вы можете мгновенно запускать такие модели, как DeepSeek, Llama и другие ведущие ИИ-фреймворки.
Кроме того, поддержка пользовательских шаблонов дает продвинутым пользователям полную гибкость в настройке окружения. Это означает, что они могут создавать специализированные конфигурации с персонализированными скриптами развертывания, кастомными программными стеками и тонко настроенными параметрами оптимизации, чтобы полностью удовлетворить уникальные требования.
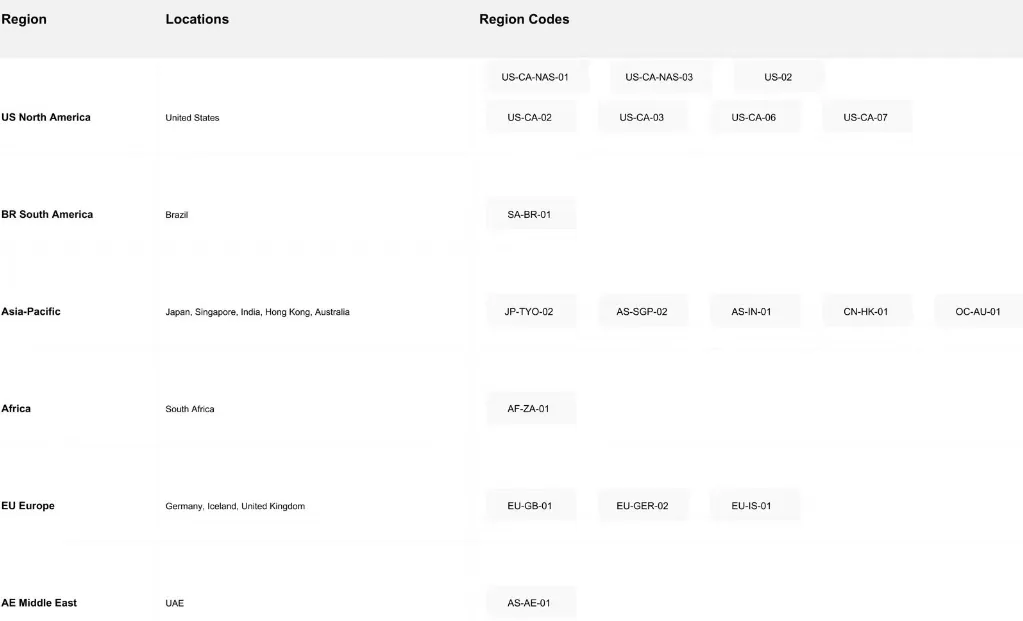
4. Глобальная сеть для развертывания
Novita AI управляет глобальной инфраструктурой с 18 зонами на нескольких континентах, обеспечивая широкий и надежный охват по всему миру:
5. Оптимизированный пользовательский опыт
Novita AI оптимизирует работу с помощью мониторинга в реальном времени, гибкого масштабирования ресурсов, простого обновления образов и автоматического переключения при сбоях, предоставляя стабильные и надежные экземпляры GPU.
Начало работы с экземплярами GPU Novita AI
Шаг 1: Войдите в свой аккаунт или создайте новый и перейдите в раздел «GPUs → GPU Instance»
Шаг 2: Выберите нужный GPU
Независимо от того, используете ли вы библиотеку готовых шаблонов или создаете полностью кастомную конфигурацию, платформа предоставляет все необходимые компоненты. Оснащенная передовым оборудованием, таким как GPU NVIDIA B200 SXM или H200 SXM с большим объемом памяти, она обеспечивает исключительную производительность даже для самых сложных рабочих нагрузок ИИ.
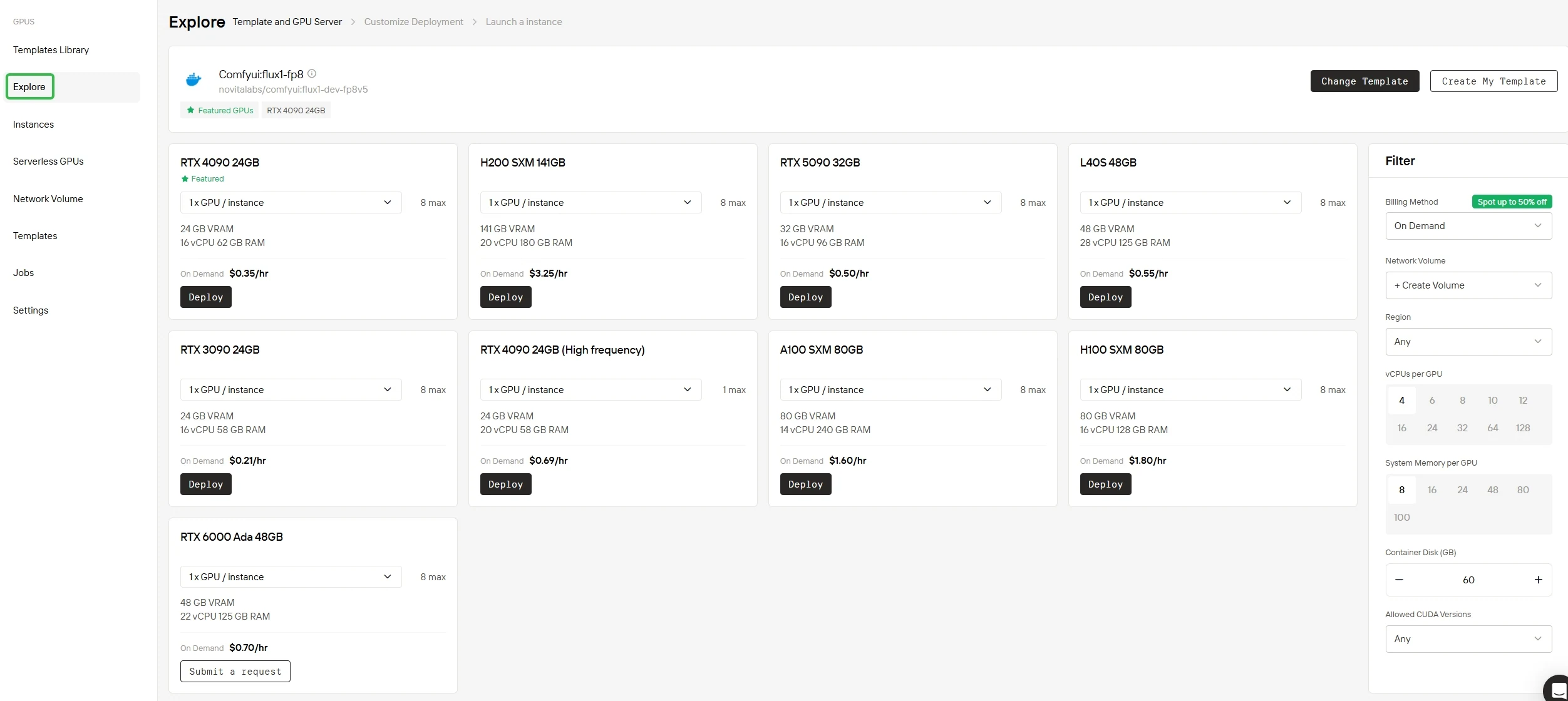
Доступные GPU B200 SXM bare metal на Novita AI
Для пользователей, которым нужен еще больший контроль и выделенная производительность, Novita AI также предлагает вариант аренды B200 SMX Bare Metal.
Каждый узел bare metal B200 SXM включает 8 GPU (по 180 ГБ VRAM каждый), 144 виртуальных ЦП и 30,8 ТБ хранилища. В отличие от управляемых и гибких экземпляров GPU, bare metal предоставляет весь физический сервер с исключительными ресурсами. Он предлагает полный контроль, но требует самостоятельной эксплуатации и обслуживания.
Часто задаваемые вопросы
Novita AI — это облачная платформа для ИИ, которая предоставляет разработчикам простой способ развертывать модели ИИ с помощью нашего простого API, а также доступное и надежное облако GPU для построения и масштабирования решений.
Рекомендуемые материалы
H100 против H200: полное сравнение за 2025 год
B200 на Novita AI: всего $4,77 в час для запуска DeepSeek R1!
Аренда NVIDIA H200 по требованию за $3,25 в час на Novita AI



