

Las GPUs H200 y B200 de NVIDIA representan dos de las opciones más avanzadas en el panorama actual de hardware para IA. Cada una cuenta con sus propias fortalezas, lo que las hace adecuadas para diferentes escenarios de inferencia y entrenamiento.
Este artículo analiza ambas GPUs en profundidad, destacando sus ventajas y casos de uso para aclarar cómo se adapta cada una a distintas cargas de trabajo de IA.
H200 vs B200: Características
| Característica | 1× H200 SMX | 1× B200 |
| Arquitectura | Hooper | Blackwell |
| Memoria de GPU | 141GB HBM3e | 192GB HBM3e |
| Ancho de banda de memoria | 4.8TB/s | 8TB/s |
| Núcleos Tensor | Hasta 4 PFLOPS FP8 | Hasta 5 PFLOPS FP8 y 9 PFLOPS FP4 |
H200 vs B200: Ventajas clave
1× H200 SXM
- Alta capacidad de memoria: Equipada con 141GB de memoria HBM3e y 4.8TB/s de ancho de banda, la H200 puede alojar conjuntos de datos considerablemente más grandes que sus predecesoras. Como resultado, este diseño de alta capacidad minimiza los cuellos de botella de memoria y mejora el movimiento de datos, lo que permite que cargas de trabajo complejas —como la inferencia de modelos de lenguaje de contexto largo y simulaciones científicas— se ejecuten con mayor estabilidad y eficiencia. Por lo tanto, el resultado es una escalabilidad más fluida y un rendimiento más consistente al manejar tareas exigentes de IA y HPC.
- Rendimiento de núcleos Tensor FP8: La H200 introduce hasta 4 PFLOPS de computación FP8, lo que supone un salto sustancial en eficiencia para las cargas de trabajo de IA. En particular, el formato FP8 ofrece un equilibrio práctico entre rendimiento computacional y precisión, lo que lo hace especialmente adecuado para la IA generativa a nivel de producción. Además, al ofrecer una inferencia más rápida sin comprometer gravemente la precisión, el FP8 posiciona a la H200 como una opción muy eficiente para desarrolladores y empresas que despliegan IA a gran escala.
- Arquitectura optimizada para inferencia: El diseño de hardware de la H200 hace hincapié en la inferencia de baja latencia y bajo consumo energético. En consecuencia, esta optimización permite sistemas de IA responsivos capaces de soportar aplicaciones en tiempo real, desde modelos de IA generativa hasta motores de recomendación. Al mismo tiempo, al reducir el consumo de energía manteniendo una alta salida computacional, la H200 garantiza un equilibrio fiable entre rendimiento y eficiencia para operaciones sostenidas con alta carga de inferencia.
1× B200
- Mayor capacidad de memoria: Con 192GB de HBM3e, la B200 supera significativamente a la H200 en tamaño de memoria bruta. Como resultado, esta capacidad adicional permite el despliegue de modelos de IA ultragrandes sin necesidad de particionamiento o gestión de memoria compleja. En la práctica, para cargas de trabajo que requieren conjuntos de datos extensos o contextos de secuencia más largos, la B200 minimiza las restricciones y simplifica el diseño de flujos de trabajo, dando a los desarrolladores una mayor flexibilidad para escalar sus sistemas.
- Soporte de precisión FP4: Como una de las innovaciones definitorias de la arquitectura Blackwell, la B200 introduce operaciones de núcleos Tensor FP4. En consecuencia, el formato FP4 mejora drásticamente el rendimiento y la eficiencia energética, permitiendo realizar entrenamiento e inferencia a gran escala de forma más rápida y a menor costo. Además, al reducir la sobrecarga computacional manteniendo la precisión funcional, el FP4 supone un avance que beneficia directamente a las organizaciones que buscan ampliar los límites del tamaño y el rendimiento de los modelos.
- Diseño preparado para el futuro: Al combinar su mayor pool de memoria, mayor ancho de banda y formatos de precisión avanzados, la B200 está arquitecturada para seguir siendo relevante a medida que los modelos de IA continúen aumentando su complejidad. Por lo tanto, este diseño orientado al futuro garantiza que los grupos de investigación y empresas que inviertan en una B200 hoy dispongan de margen de computación para soportar nuevas cargas de trabajo en los próximos años. En última instancia, no se posiciona solo como una solución para los modelos fronterizos actuales, sino también como una base estable para el desarrollo de la IA de próxima generación.
Aunque la B200 ofrece ventajas claras en memoria, precisión y escalabilidad, la H200 sigue siendo una opción sólida y práctica. Ofreciendo un rendimiento robusto a un costo más accesible, la H200 sirve como una opción equilibrada para empresas que buscan eficiencia sin la inversión más elevada de los sistemas de próxima generación.
H200 vs B200: Aplicaciones
H200 SMX
- IA generativa y LLM: Es muy adecuada para la inferencia de contexto largo, soportando aplicaciones avanzadas de chatbots y generación de contenido.
- Computación de alto rendimiento (HPC): Su rendimiento impulsado por el ancho de banda acelera las simulaciones científicas y tareas de modelado intensivas en datos.
- Inferencia empresarial: Opción fiable para el despliegue a gran escala de sistemas de búsqueda, recomendación y conversacionales de IA.
B200
- Desarrollo de IA fronteriza: Diseñada específicamente para el entrenamiento e inferencia de LLMs y sistemas multimodales de vanguardia que amplían los límites actuales.
- Despliegue a escala empresarial: Proporciona la capacidad y el margen de computación necesarios para plataformas de IA de alto rendimiento sostenido.
- Infraestructura de investigación: Adecuada para organizaciones que construyen bases escalables para soportar la próxima ola de desarrollo de modelos de IA.
H200 vs B200: Precio
| GPU | Rango de precio minorista | Precio de paquete para servidores/empresas | Precio de alquiler en la nube |
|---|---|---|---|
| NVIDIA H200 | $30,000 - $40,000 | Puede superar los $500,000 para sistemas completos | $3.25 por hora (ej: con Novita AI) |
| NVIDIA B200 | $45,000–$50,000 | Puede superar los $500,000 para sistemas completos | $3.84 por hora |
La H200 y la B200 marcan el estándar de rendimiento de GPUs, pero para quienes buscan equilibrar costo y flexibilidad, invertir en sistemas completos puede no ser el camino óptimo. Las Instancias de GPU responden a esta necesidad, y Novita AI proporciona una plataforma flexible para ayudar a desarrolladores y empresas a escalar con facilidad, haciéndolas más accesibles que nunca.
Cinco razones para acceder a la H200 y la B200 a través de las Instancias de GPU de Novita AI
1. Precios competitivos y facturación flexible
Precios: Novita AI frente a RunPod
| Proveedor | H200 SMX | B200 SMX |
| Novita AI | $3.25/h | $3.84/h |
| RunPod | $3.59/h | $5.98/h |
Opciones de facturación
| GPU | Spot | Bajo demanda | Suscripción |
| 1× H200 SMX | $1.63/h | $3.25/h | $2160 /h |
| 1× B200 SMX | $1.92/h | $3.84/h | - |
Spot ofrece tarifas con descuento y disponibilidad variable. Bajo demanda sigue un modelo de pago por uso para acceso instantáneo. Suscripción garantiza ahorros de costos para usos prolongados y predecibles.
2. Amplia gama de GPUs para demandas variadas
| Nivel | GPU |
| Consumo | RTX 3090 24GB, RTX 4090 24GB, RTX 4090 24GB (Alta frecuencia), RTX 5090 32GB |
| Estación de trabajo | RTX 6000 Ada 48GB |
| Centro de datos | L40S 48GB, A100 SXM 80GB, H100 SXM 80GB, H200 SXM 141GB, B200 192GB |
¡Prueba las GPUs de Novita AI ahora!
3. Plantillas listas para usar disponibles
Las plantillas preconfiguradas eliminan la molestia de la configuración manual, ya que no solo ofrecen entornos optimizados para modelos populares, sino que también incluyen parámetros de despliegue validados, variables de entorno y configuraciones de contenedores. Como resultado, puedes lanzar instancias al instante con modelos como DeepSeek, Llama y otros marcos de IA líderes.
Además, la compatibilidad con plantillas personalizadas brinda a los usuarios avanzados total flexibilidad sobre su entorno. Esto significa que pueden crear configuraciones especializadas con scripts de despliegue personalizados, pilas de software a medida y configuraciones de optimización ajustadas para cumplir completamente con los requisitos únicos de cada proyecto.
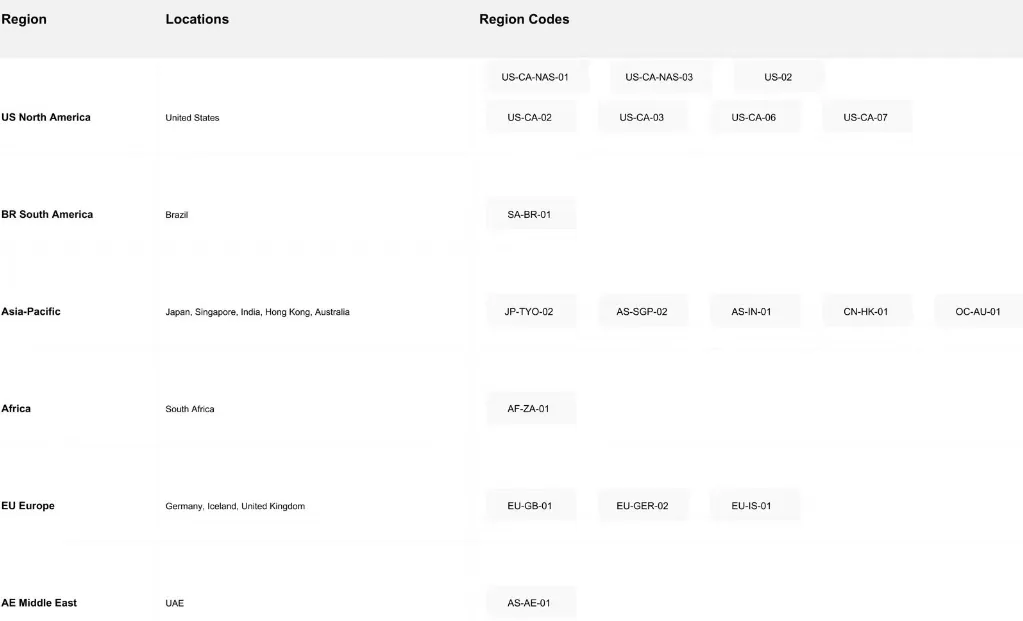
4. Red de despliegue global
Novita AI opera una infraestructura global con 18 zonas en varios continentes, garantizando una cobertura mundial amplia y fiable:
5. Experiencia de usuario optimizada
Novita AI agiliza las operaciones con monitorización en tiempo real, escalado flexible de recursos, actualizaciones de imágenes sencillas y conmutación por error automática, ofreciendo instancias de GPU estables y fiables.
Cómo empezar con la Instancia de GPU de Novita AI
Paso 1: Inicia sesión o crea tu cuenta y accede a la sección “GPUs -> Instancia de GPU”
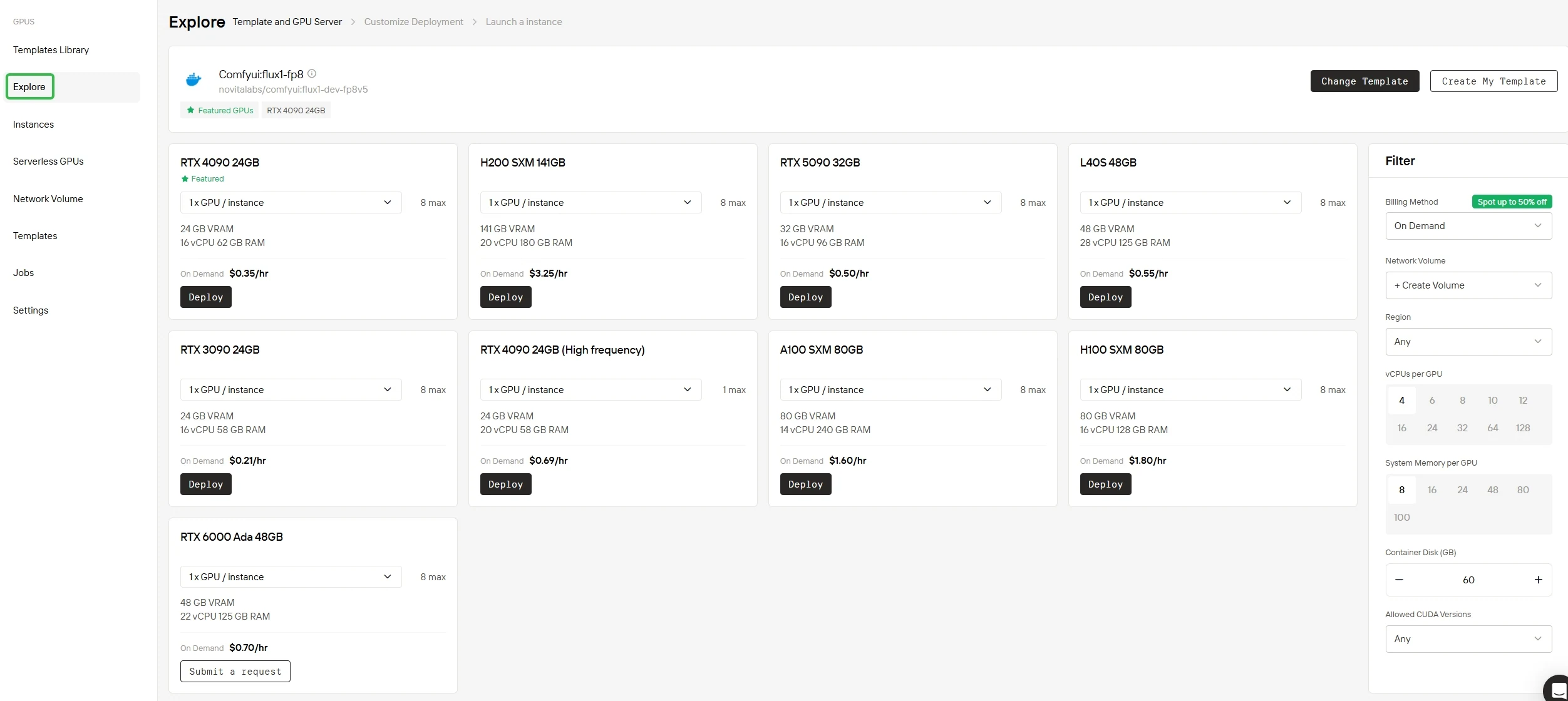
Paso 2: Selecciona tu GPU
Ya sea que uses nuestra biblioteca de plantillas listas para usar o diseñes una configuración totalmente personalizada, la plataforma proporciona todos los componentes esenciales que necesites. Impulsada por hardware de vanguardia como las GPUs NVIDIA B200 SXM o H200 SXM con una amplia capacidad de memoria, ofrece un rendimiento excepcional incluso para tus cargas de trabajo de IA más exigentes.
GPU B200 SXM Bare Metal disponible en Novita AI
Para usuarios que buscan un mayor control y rendimiento dedicado, Novita AI también ofrece la opción de alquiler de B200 SMX Bare Metal.
Cada nodo bare metal de B200 SXM incluye 8 GPUs (180GB de VRAM cada una), 144 vCPUs y 30.8TB de almacenamiento. Bare Metal entrega el servidor físico completo con recursos exclusivos, a diferencia de las Instancias de GPU que son gestionadas y flexibles. Ofrece control total, pero requiere operación y mantenimiento interno.
Preguntas frecuentes
Novita AI es una plataforma de cloud de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA mediante nuestra API simple, además de proporcionar un cloud de GPUs asequible y fiable para construir y escalar proyectos.
Lecturas recomendadas
H100 vs H200: Una comparación exhaustiva para 2025
B200 en Novita AI: ¡Solo $4.77/h para ejecutar DeepSeek R1!
Alquila la NVIDIA H200 bajo demanda por $3.25/Hora en Novita AI



