

NVIDIA’s H200 and B200 GPUs represent two of the most advanced options in today’s AI hardware landscape. Each brings its own strengths, making them suitable for different scenarios across inference and training.
This article takes a closer look at both GPUs, highlighting their advantages and use cases to clarify how each fits into different AI workloads.
H200 vs B200: Features
| Feature | 1× H200 SMX | 1× B200 |
| Architecture | Hooper | Blackwell |
| GPU Memory | 141GB HBM3e | 192GB HBM3e |
| Memory Bandwidth | 4.8TB/s | 8TB/s |
| Tensor Core | Up to 4 PFLOPS FP8 | Up to 5 PFLOPS FP8 and 9 PFLOPS FP4 |
H200 vs B200: Key Advantages
1× H200 SXM
- High-Capacity Memory: Equipped with 141GB of HBM3e memory and 4.8TB/s bandwidth, the H200 can accommodate significantly larger datasets than its predecessors. As a result, this high-capacity design minimizes memory bottlenecks and enhances data movement, allowing complex workloads—such as long-context language model inference and scientific simulations—to run with greater stability and efficiency. Therefore, the outcome is smoother scaling and more consistent performance when handling demanding AI and HPC tasks.
- FP8 Tensor Core Performance: The H200 introduces up to 4 PFLOPS of FP8 compute, representing a substantial leap in efficiency for AI workloads. In particular, FP8 offers a practical balance between computational throughput and precision, making it especially suited for production-level generative AI. Moreover, by delivering faster inference without severely compromising accuracy, FP8 positions the H200 as a highly efficient option for developers and enterprises deploying AI at scale.
- Inference-Optimized Architecture: The hardware design of the H200 emphasizes low-latency and power-efficient inference. Consequently, this optimization enables responsive AI systems capable of supporting real-time applications, from generative AI models to recommendation engines. At the same time, by reducing power draw while maintaining strong computational output, the H200 ensures a reliable balance of performance and efficiency for sustained inference-heavy operations.
1× B200
- Greater Memory Capacity: With 192GB of HBM3e, the B200 significantly surpasses the H200 in raw memory size. As a result, this additional capacity enables the deployment of ultra-large AI models without the need for partitioning or complex memory management. In practice, for workloads requiring expansive datasets or longer sequence contexts, the B200 minimizes constraints and simplifies workflow design, thereby giving developers greater flexibility in scaling their systems.
- FP4 Precision Support: As one of the defining innovations of the Blackwell architecture, the B200 introduces FP4 Tensor Core operations. Consequently, FP4 drastically improves throughput and energy efficiency, enabling large-scale training and inference to be performed faster and at lower cost. Moreover, by reducing computational overhead while retaining functional accuracy, FP4 marks a breakthrough that directly benefits organizations aiming to push the limits of model size and performance.
- Future-Proof Design: By combining its larger memory pool, higher bandwidth, and advanced precision formats, the B200 is architected to remain relevant as AI models continue to grow in complexity. Therefore, this forward-looking design ensures that research groups and enterprises investing in B200 today have the compute headroom to support new workloads in the coming years. Ultimately, it is positioned not only as a solution for current frontier models but also as a stable foundation for next-generation AI development.
While the B200 delivers clear advantages in memory, precision, and scalability, the H200 remains a strong and practical choice. Offering robust performance at a more accessible cost, the H200 serves as a balanced option for businesses seeking efficiency without the higher investment of next-generation systems.
H200 vs B200: Applications
H200 SMX
- Generative AI and LLMs: Strong fit for long-context inference, supporting advanced chatbots and content generation applications.
- High-Performance Computing (HPC): Bandwidth-driven performance accelerates data-intensive scientific simulations and modeling tasks.
- Enterprise Inference: Reliable option for large-scale deployment of search, recommendation, and conversational AI systems.
B200
- Frontier AI Development: Purpose-built for training and inference of cutting-edge LLMs and multimodal systems that push current limits.
- Enterprise-Scale Deployment: Provides the capacity and compute headroom needed for sustained high-throughput AI platforms.
- Research Infrastructure: Suitable for organizations building scalable foundations to support the next wave of AI model development.
H200 vs B200: Price
| GPU | Retail Price Range | Server/Enterprise Bundle Price | Cloud Rental Price |
|---|---|---|---|
| NVIDIA H200 | $30,000 - $40,000 | Can exceed $500,000 for full systems | $3.25 per hour(e.g. with Novita AI) |
| NVIDIA B200 | $45,000–$50,000 | Can exceed $500,000 for full systems | $3.84 per hour |
H200 and B200 set the benchmark for GPU performance, but for those aiming to balance cost and flexibility, investing in full systems may not be the optimal path. GPU Instances address this need—and Novita AI provides a flexible platform to help developers and businesses scale with ease, makes them more accessible than ever.
Five Reasons to access H200 & B200 via Novita AI GPU Instances
1. Competitive Pricing & Flexible Billing
Pricing: Novita AI vs RunPod
| Provider | H200 SMX | B200 SMX |
| Novita AI | $3.25/hr | $3.84/hr |
| RunPod | $3.59/hr | $5.98/hr |
Billing Options
| GPU | Spot | On-Demand | Subscription |
| 1× H200 SMX | $1.63/hr | $3.25/hr | $2160 /hr |
| 1× B200 SMX | $1.92/hr | $3.84/hr | - |
Spot offers discounted rates with variable availability. On-Demand follows a pay-as-you-go model for instant access. Subscription ensures cost savings for long-term, predictable usage.
2. Diverse Demanding GPU Options
| Tier | GPU |
| Consumer | RTX 3090 24GB, RTX 4090 24GB, RTX 4090 24GB (High Frequency), RTX 5090 32GB |
| Workstation | RTX 6000 Ada 48GB |
| Data Center | L40S 48GB, A100 SXM 80GB, H100 SXM 80GB, H200 SXM 141GB, B200 192GB |
3. Ready-to-Use Template Available
Pre-configured Templates remove the hassle of manual setup by not only offering optimized environments for popular models but also including validated deployment parameters, environment variables, and container configurations. As a result, you can launch instantly with models like DeepSeek, Llama, and other leading AI frameworks.
In addition, Custom Template Support gives advanced users full flexibility over their environment. This means they can build specialized setups with personalized deployment scripts, custom software stacks, and fine-tuned optimization settings so that unique requirements are fully met.
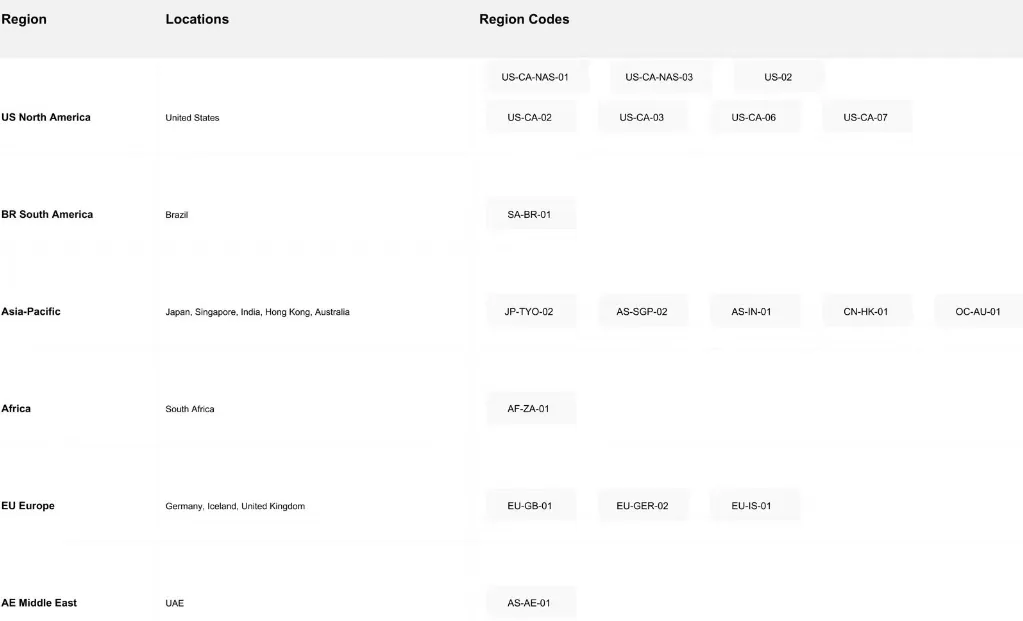
4. Global Deployment Network
Novita AI operates a global infrastructure with 18 zones across multiple continents, ensuring broad and reliable worldwide coverage:
5. Optimized User Experience
Novita AI streamlines operations with real-time monitoring, flexible resource scaling, simple image upgrades, and automatic failover, delivering stable and reliable GPU instances.
Getting Started with Novita AI’s GPU Instance
Step 1: Log in or create your account & Access the “GPUs -> GPU Instance” section
Step 2: Select your GPU
Whether you rely on our ready-to-use template library or design a fully customized setup, the platform provides every essential component you need. Powered by cutting-edge hardware like NVIDIA B200 SXM or H200 SXM GPUs with expansive memory capacity, it delivers exceptional performance even for your most demanding AI workloads.
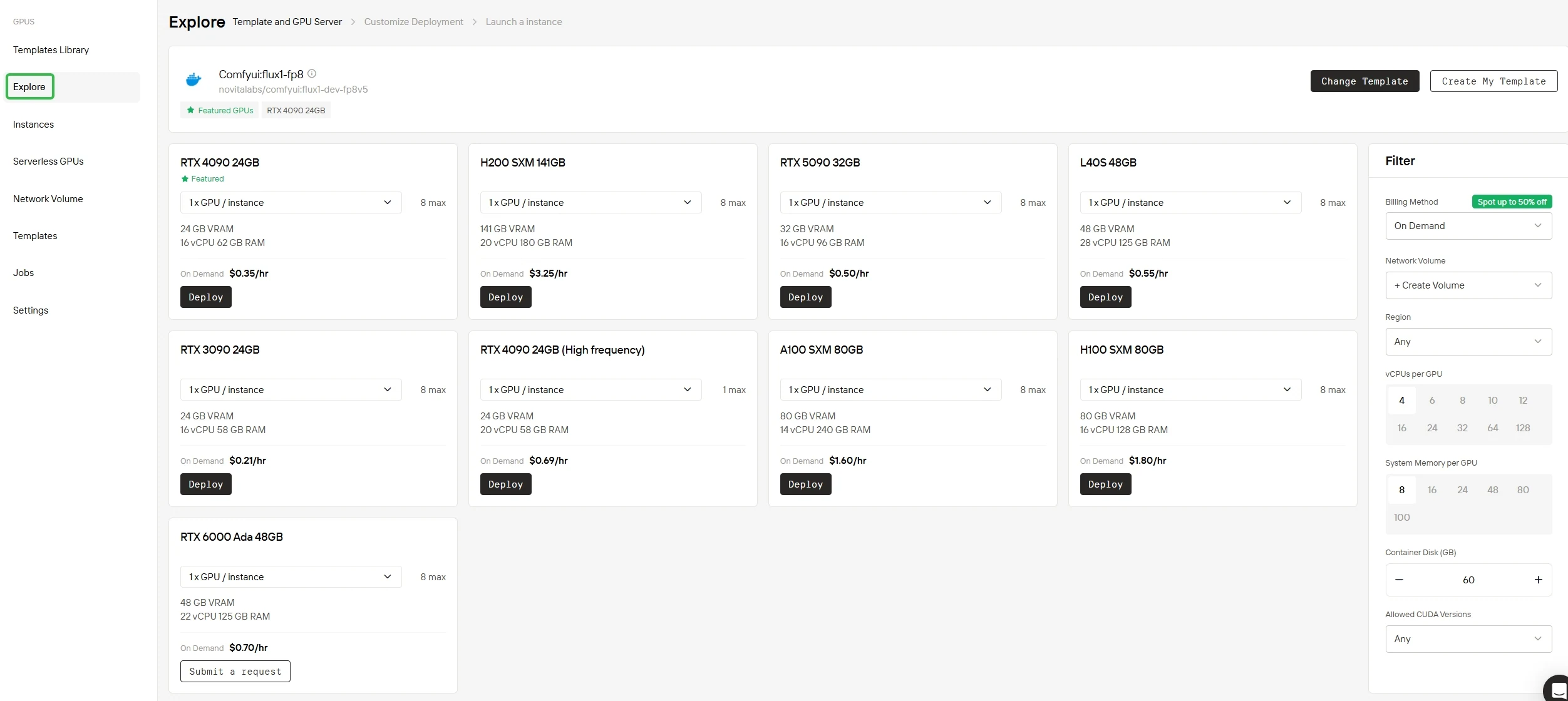
B200 SXM Bare Metal GPU Available on Novita AI
For users seeking even greater control and dedicated performance, Novita AI also provides B200 SMX Bare Metal rental option.
Each B200 SXM bare metal node includes 8 GPUs (180GB VRAM each), 144 vCPUs, and 30.8TB storage. Bare Metal delivers the entire physical server with exclusive resources, unlike GPU Instances that are managed and flexible. It offers full control but requires in-house operation and maintenance.
Frequently Asked Questions
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Recommended Reading
H100 vs H200: A Comprehensive Comparison for 2025



