

تمثل بطاقات معالجة الرسوميات NVIDIA H200 و B200 اثنين من أكثر الخيارات تقدمًا في مشهد أجهزة الذكاء الاصطناعي اليوم. لكل منهما نقاط قوة خاصة به، مما يجعله مناسبًا لسيناريوهات مختلفة عبر الاستدلال والتدريب.
يتناول هذا المقال كلا البطاقتين عن كثب، مسلطًا الضوء على مزاياها وحالات استخدامها لتوضيح كيف يتناسب كل منهما مع عبء عمل الذكاء الاصطناعي المختلف.
H200 مقابل B200: الميزات
| الميزة | 1× H200 SMX | 1× B200 |
| البنية | Hooper | Blackwell |
| ذاكرة بطاقة المعالجة الرسومية | 141GB HBM3e | 192GB HBM3e |
| عرض نطاق الذاكرة | 4.8TB/s | 8TB/s |
| نوى Tensor | حتى 4 PFLOPS FP8 | حتى 5 PFLOPS FP8 و 9 PFLOPS FP4 |
H200 مقابل B200: المزايا الرئيسية
1× H200 SXM
- ذاكرة عالية السعة: مجهزة بذاكرة HBM3e سعة 141GB وعرض نطاق 4.8TB/s، يمكن لبطاقة H200 استيعاب مجموعات بيانات أكبر بكثير من سابقاتها. وكنتيجة لذلك، يقلل هذا التصميم عالي السعة من اختناقات الذاكرة ويعزز حركة البيانات، مما يسمح للعبء العمل المعقد - مثل استدلال نماذج اللغة ذات السياق الطويل والمحاكيات العلمية - بالعمل بثبات وكفاءة أكبر. وبالتالي، النتيجة هي توسيع أكثر سلاسة وأداء أكثر اتساقًا عند التعامل مع مهام الذكاء الاصطناعي والحوسبة عالية الأداء (HPC) الصعبة.
- أداء نوى Tensor FP8: تقدم H200 ما يصل إلى 4 PFLOPS من قوة الحساب FP8، مما يمثل قفزة كبيرة في الكفاءة لعبء عمل الذكاء الاصطناعي. على وجه الخصوص، يقدم FP8 توازنًا عمليًا بين الإنتاجية الحسابية والدقة، مما يجعله مناسبًا بشكل خاص للذكاء الاصطناعي التوليدي على مستوى الإنتاج. علاوة على ذلك، من خلال تقديم استدلال أسرع دون المساس بالدقة بشكل كبير، يضع FP8 بطاقة H200 كخيار فعال للغاية للمطورين والشركات التي تنشر الذكاء الاصطناعي على نطاق واسع.
- بنية محسنة للاستدلال: يركز تصميم الأجهزة لبطاقة H200 على الاستدلال منخفض التأخير وموفر للطاقة. وكنتيجة لذلك، يمكن لهذا التحسين أن يمكّن أنظمة ذكاء اصطناعي سريعة الاستجابة القادرة على دعم التطبيقات في الوقت الفعلي، من نماذج الذكاء الاصطناعي التوليدي إلى محركات التوصيات. في نفس الوقت، من خلال تقليل استهلاك الطاقة مع الحفاظ على إنتاج حسابي قوي، تضمن بطاقة H200 توازنًا موثوقًا بين الأداء والكفاءة للعمليات المستمرة كثيفة الاستدلال.
1× B200
- سعة ذاكرة أكبر: بذاكرة HBM3e سعة 192GB، تتجاوز بطاقة B200 بشكل كبير بطاقة H200 من حيث حجم الذاكرة الخام. وكنتيجة لذلك، تتيح هذه السعة الإضافية نشر نماذج ذكاء اصطناعي فائقة الكبر دون الحاجة إلى تقسيم أو إدارة ذاكرة معقدة. في الممارسة العملية، بالنسبة لعبء العمل الذي يتطلب مجموعات بيانات واسعة أو سياقات تسلسل أطول، تقلل بطاقة B200 من القيود وتبسط تصميم سير العمل، مما يمنح المطورين مرونة أكبر في توسيع نطاق أنظمتهم.
- دعم دقة FP4: كواحدة من الابتكارات المميزة لبنية Blackwell، تقدم بطاقة B200 عمليات نوى Tensor FP4. وكنتيجة لذلك، يحسن FP4 بشكل كبير الإنتاجية والكفاءة الطاقية، مما يتيح إجراء التدريب والاستدلال على نطاق واسع بشكل أسرع وبتكلفة أقل. علاوة على ذلك، من خلال تقليل التكاليف الحسابية مع الحفاظ على الدقة الوظيفية، يمثل FP4 اختراقًا يفيد بشكل مباشر المؤسسات التي تهدف إلى دفع حدود حجم النموذج والأداء.
- تصميم مستقبلي: من خلال الجمع بين مجموعة الذاكرة الأكبر، وعرض النطاق الأعلى، وتنسيقات الدقة المتقدمة، تم تصميم بطاقة B200 لتبقى ذات صلة بينما تستمر نماذج الذكاء الاصطناعي في النمو في التعقيد. لذلك، يضمن هذا التصميم الموجه نحو المستقبل أن مجموعات البحث والشركات التي تستثمر في B200 اليوم لديها مساحة حسابية كافية لدعم عبء عمل جديد في السنوات القادمة. في النهاية، يتم وضعها ليس فقط كحل للنماذج الحدية الحالية، ولكن أيضًا كأساس مستقر لتطوير الجيل التالي من الذكاء الاصطناعي.
بينما تقدم بطاقة B200 مزايا واضحة في الذاكرة والدقة والقابلية للتوسع، تظل بطاقة H200 خيارًا قويًا وعمليًا. مع تقديم أداء قوي بتكلفة أكثر سهولة، تعد بطاقة H200 خيارًا متوازنًا للشركات التي تسعى إلى الكفاءة دون الحاجة إلى استثمار أعلى في أنظمة الجيل التالي.
H200 مقابل B200: التطبيقات
H200 SMX
- الذكاء الاصطناعي التوليدي ونماذج اللغة الكبيرة (LLMs): تناسب بشكل قوي لاستدلال السياق الطويل، ويدعم تطبيقات روبوتات الدردشة المتقدمة وتوليد المحتوى.
- الحوسبة عالية الأداء (HPC): يعزز الأداء المعتمد على عرض النطاق المحاكيات العلمية كثيفة البيانات ومهام النمذجة.
- استدلال المؤسسات: خيار موثوق لنشر أنظمة البحث والتوصيات والذكاء الاصطناعي الحواري على نطاق واسع.
B200
- تطوير الذكاء الاصطناعي الحدودي: مصمم خصيصًا لتدريب واستدلال نماذج اللغة الكبيرة (LLMs) متطورة والأنظمة متعددة الوسائط التي تدفع الحدود الحالية.
- النشر على نطاق المؤسسات: يوفر السعة والمساحة الحسابية المطلوبة لمنصات الذكاء الاصطناعي عالية الإنتاجية المستمرة.
- البنية التحتية للبحث: مناسب للمؤسسات التي تبني أسسًا قابلة للتوسع لدعم الموجة التالية من تطوير نماذج الذكاء الاصطناعي.
H200 مقابل B200: السعر
| بطاقة معالجة الرسوميات | نطاق سعر التجزئة | سعر حزمة الخادم/المؤسسات | سعر تأجير السحابة |
|---|---|---|---|
| NVIDIA H200 | $30,000 - $40,000 | يمكن أن يتجاوز $500,000 للأنظمة الكاملة | $3.25 في الساعة (مثال مع Novita AI) |
| NVIDIA B200 | $45,000–$50,000 | يمكن أن يتجاوز $500,000 للأنظمة الكاملة | $3.84 في الساعة |
تحدد بطاقتا H200 و B200 المعيار لأداء بطاقات معالجة الرسوميات، ولكن لأولئك الذين يهدفون إلى الموازنة بين التكلفة والمرونة، قد لا يكون الاستثمار في أنظمة كاملة هو المسار الأمثل. تعالج مثيلات GPU هذه الحاجة - وتوفر منصة Novita AI المرونة لمساعدة المطورين والشركات على التوسع بسهولة، مما يجعل هذه البطاقات أكثر سهولة في الوصول من أي وقت مضى.
خمسة أسباب للوصول إلى H200 و B200 عبر مثيلات GPU من Novita AI
1. تسعير تنافسي وفوترة مرنة
التسعير: Novita AI مقابل RunPod
| المزود | H200 SMX | B200 SMX |
| Novita AI | $3.25/ساعة | $3.84/ساعة |
| RunPod | $3.59/ساعة | $5.98/ساعة |
خيارات الفوترة
| بطاقة معالجة الرسوميات | البيع الفوري | عند الطلب | الاشتراك |
| 1× H200 SMX | $1.63/ساعة | $3.25/ساعة | $2160 /ساعة |
| 1× B200 SMX | $1.92/ساعة | $3.84/ساعة | - |
يقدم البيع الفوري أسعارًا مخفضة مع توفر متغير. يتبع عند الطلب نموذج الدفع حسب الاستخدام للوصول الفوري. يضمن الاشتراك توفير التكاليف للاستخدام طويل الأمد والقابل للتنبؤ.
2. خيارات متنوعة من بطاقات معالجة الرسوميات عالية الطلب
| الفئة | بطاقة معالجة الرسوميات |
| المستهلك | RTX 3090 24GB, RTX 4090 24GB, RTX 4090 24GB (High Frequency), RTX 5090 32GB |
| محطة العمل | RTX 6000 Ada 48GB |
| مركز البيانات | L40S 48GB, A100 SXM 80GB, H100 SXM 80GB, H200 SXM 141GB, B200 192GB |
جرب بطاقات معالجة الرسوميات من Novita AI الآن !
3. قوالب جاهزة للاستخدام متاحة
تزيل القوالب المُعدة مسبقًا عناء الإعداد اليدوي من خلال تقديم بيئات محسنة للنماذج الشائعة، بالإضافة إلى تضمين معلمات نشر معتمدة، ومتغيرات بيئة، وتكوينات حاويات. وكنتيجة لذلك، يمكنك الإطلاق فورًا مع نماذج مثل DeepSeek و Llama وأطر الذكاء الاصطناعي الرائدة الأخرى.
علاوة على ذلك، يمنح دعم القوالب المخصصة للمستخدمين المتقدمين مرونة كاملة على بيئتهم. هذا يعني أنه يمكنهم بناء إعدادات متخصصة مع نصوص نشر مخصصة، ومكدسات برامج مخصصة، وإعدادات تحسين دقيقة بحيث يتم تلبية المتطلبات الفريدة بالكامل.
4. شبكة نشر عالمية
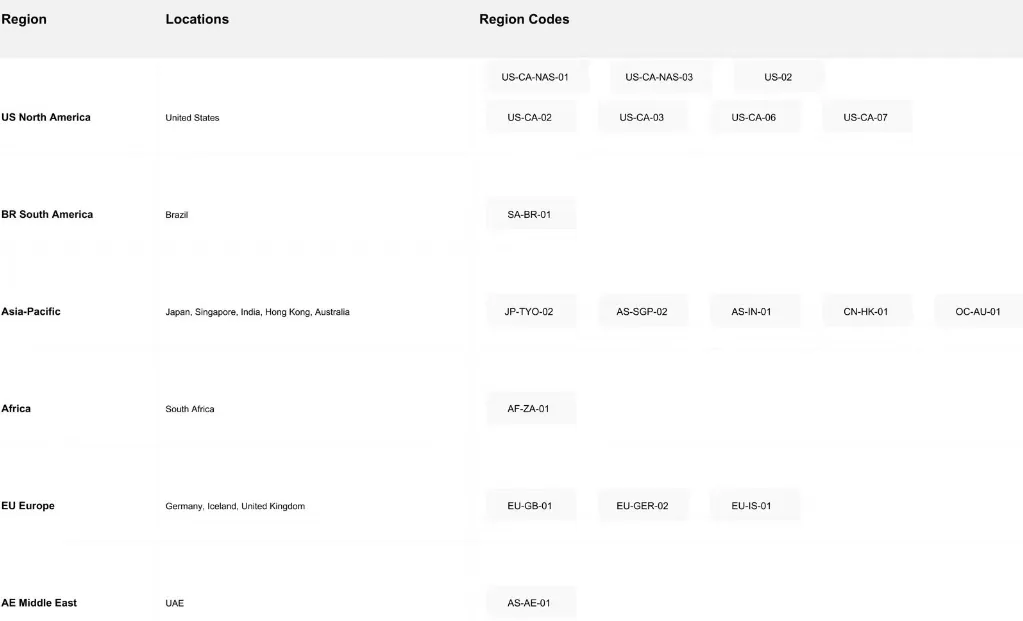
تدير Novita AI بنية تحتية عالمية مع 18 منطقة عبر قارات متعددة، مما يضمن تغطية عالمية واسعة وموثوقة:
5. تجربة مستخدم محسنة
تبسط Novita AI العمليات من خلال المراقبة في الوقت الفعلي، وتوسيع الموارد المرن، وترقيات الصور البسيطة، والتجاوز التلقائي عن الأعطال، مما يوفر مثيلات GPU مستقرة وموثوقة.
البدء في استخدام مثيل GPU من Novita AI
الخطوة 1: تسجيل الدخول أو إنشاء حسابك والوصول إلى قسم “GPUs -> GPU Instance”
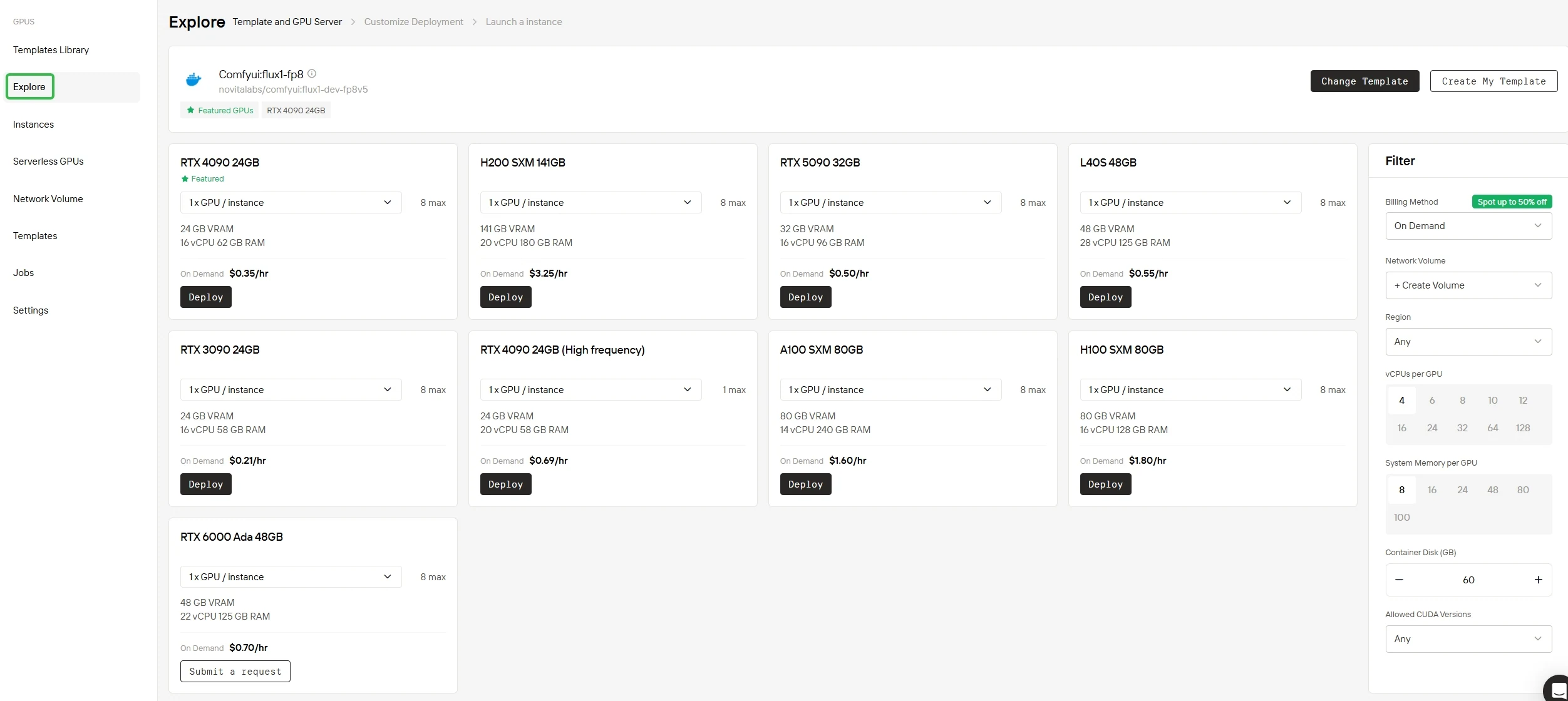
الخطوة 2: اختر بطاقة معالجة الرسوميات الخاصة بك
سواء كنت تعتمد على مكتبة القوالب الجاهزة للاستخدام لدينا أو تصميم إعداد مخصص بالكامل، فإن المنصة توفر كل المكونات الأساسية التي تحتاجها. مدعوم بأجهزة متطورة مثل بطاقات معالجة الرسوميات NVIDIA B200 SXM أو H200 SXM ذات السعة الذاكرية الواسعة، فإنها تقدم أداء استثنائي حتى لأعباء عمل الذكاء الاصطناعي الأكثر تطلبًا.
اختر بطاقة معالجة الرسوميات الخاصة بك الآن !
بطاقة معالجة الرسوميات B200 SXM Bare Metal متاحة على Novita AI
للمستخدمين الذين يسعون إلى تحكم أكبر وأداء مخصص، توفر Novita AI أيضًا خيار تأجير B200 SMX Bare Metal.
تتضمن كل عقدة B200 SXM من نوع Bare Metal 8 بطاقات معالجة رسوميات (180GB VRAM لكل منها)، و 144 vCPUs، و 30.8TB تخزين. يوفر Bare Metal الخادم الفعلي بالكامل مع موارد حصرية، على عكس مثيلات GPU التي تكون مُدارة ومرنة. إنه يقدم تحكمًا كاملًا ولكنه يتطلب تشغيلًا وصيانة داخلية.
الأسئلة الشائعة
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، بالإضافة إلى توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.
قراءة موصى بها
H100 مقابل H200: مقارنة شاملة لعام 2025



