

- Was ist NVIDIA Nemotron Speech ASR?
- Was ist das NVIDIA NeMo Framework?
- Warum Nemotron Speech ASR auf Novita AI bereitstellen?
- Voraussetzungen für die Bereitstellung
- Bereitstellung von Nemotron Speech ASR: Schritt-für-Schritt-Anleitung
- NeMo Framework-Abhängigkeiten installieren
- NVIDIA Nemotron Speech ASR-Modell ausführen
- Anwendungsfälle von Nemotron Speech ASR
- Fazit
Echtzeit-Spracherkennung erfordert mehr als nur Genauigkeit – sie braucht konsistente niedrige Latenz, ohne dabei GPU-Ressourcen zu verschwenden.
Das NVIDIA Nemotron Speech ASR-Modell löst Latenzdrift und redundante Berechnungen durch seine cache-aware Streaming-Architektur. Dadurch entfällt die Notwendigkeit von gepufferten Inferenzen, was eine stabile Latenz unter 100 ms (24 ms median Time-to-First-Token) und bis zu 3x höheren Durchsatz auf Ihrer GPU liefert.
Diese Anleitung zeigt Ihnen, wie Sie das NVIDIA Nemotron Speech ASR auf Novita AI GPU-Instanzen mithilfe unserer vorkonfigurierten Vorlage bereitstellen. Erstellen Sie produktionsreife Sprachanwendungen ohne Infrastrukturkomplexität.
Was ist NVIDIA Nemotron Speech ASR?
NVIDIA Nemotron Speech ASR ist ein Streaming-Automatic-Speech-Recognition-Modell (ASR), das für Echtzeitanwendungen mit minimaler Latenz entwickelt wurde.
Traditionelle ASR-Systeme verlassen sich auf gepufferte Audio-Chunks, was zu Latenzdrift und ineffizienter GPU-Nutzung führt. Nemotron Speech ASR verwendet cache-aware Streaming, um Audio kontinuierlich ohne Pufferungsverzögerungen zu verarbeiten.
Spezifikationen von NVIDIA Nemotron Speech ASR:
- Architektur: Cache-aware Streaming-ASR mit Conformer-CTC
- Latenzleistung: End-to-End-Verarbeitung unter 100 ms
- Time-to-First-Token: 24 ms median Latenz
- Durchsatzsteigerung: Bis zu 3x im Vergleich zu gepufferter Inferenz
- Sprachunterstützung: Englisch (Variante mit 0,6 Mrd. Parametern)
- Modellgröße: 600 Mio. Parameter, optimiert für Streaming
Die cache-aware Streaming-Architektur eliminiert Latenzdrift und redundante Berechnungen, wodurch NVIDIA Nemotron Speech ASR ideal für Live-Transkription, Sprachassistenten, Call-Center-Analysen und interaktive KI-Anwendungen ist.
Was ist das NVIDIA NeMo Framework?
Das NVIDIA NeMo Framework ist ein skalierbares, cloud-natives generatives KI-Framework für Forscher und PyTorch-Entwickler.
Das NeMo Framework unterstützt die Entwicklung in mehreren KI-Bereichen:
- Large Language Models (LLMs)
- Multimodale Modelle (MMs)
- Automatische Spracherkennung (ASR)
- Text-zu-Sprache (TTS)
- Computervision (CV)
Das Framework hilft Ihnen, generative KI-Modelle effizient zu erstellen, anzupassen und bereitzustellen, indem es vorhandenen Code und vortrainierte Modell-Prüfpunkte nutzt.
NVIDIA Nemotron Speech ASR basiert auf dem NeMo Framework und bietet produktionsreife ASR-Funktionen mit minimalem Setup.
Die vollständige technische Dokumentation finden Sie im NeMo Framework-Benutzerhandbuch.
Warum Nemotron Speech ASR auf Novita AI bereitstellen?
Novita AI GPU-Instanzen bieten optimierte Infrastruktur für die Bereitstellung von NVIDIA Nemotron Speech ASR im großen Maßstab:
Schnelle Bereitstellung: Starten Sie GPU-Instanzen in Sekunden mit vorkonfigurierten NeMo-Vorlagen. Keine manuelle Umgebungseinrichtung erforderlich.
Kostengünstige Preisgestaltung: Abrechnung nach Sekunden ohne langfristige Verträge oder Mindestbindungen. Skalieren Sie je nach Bedarf hoch oder herunter.
Vorkonfigurierte Vorlagen: NeMo Framework und Abhängigkeiten sind vorinstalliert. Starten Sie Nemotron Speech ASR sofort.
Globale Infrastruktur: GPU-Zugang mit niedriger Latenz in mehreren Regionen für weltweite Bereitstellung.
Entwicklertools: Echtzeit-Überwachung, SSH-Zugang und unkomplizierte Bereitstellung von Vorlagen aus der Novita AI-Bibliothek.
Egal, ob Sie einen Sprachassistenten prototypisieren oder eine produktive Transkriptionspipeline skalieren – Novita AI übernimmt die GPU-Infrastruktur, sodass Sie sich auf die Entwicklung von ASR-Anwendungen konzentrieren können.
Voraussetzungen für die Bereitstellung
Stellen Sie vor der Bereitstellung von NVIDIA Nemotron Speech ASR sicher, dass Sie über Folgendes verfügen:
- Novita AI-Konto mit ausreichendem Guthaben (Registrieren Sie sich hier)
- Audio-Testdateien im WAV-Format zur Modellvalidierung
- Grundlegende SSH-Kenntnisse für Instanzzugriff und -konfiguration
- Verständnis der GPU-Anforderungen für Ihre spezifische Arbeitslast
Keine vorherige Erfahrung mit dem NeMo Framework erforderlich – die Novita AI-Vorlage übernimmt die Ersteinrichtung.
Bereitstellung von Nemotron Speech ASR: Schritt-für-Schritt-Anleitung
Schritt 1: Zugriff auf die Novita AI-Konsole
Melden Sie sich bei Ihrem Novita AI-Konto an und navigieren Sie zur GPU-Oberfläche.
Wählen Sie Loslegen, um auf das Bereitstellungsverwaltungs-Dashboard zuzugreifen.
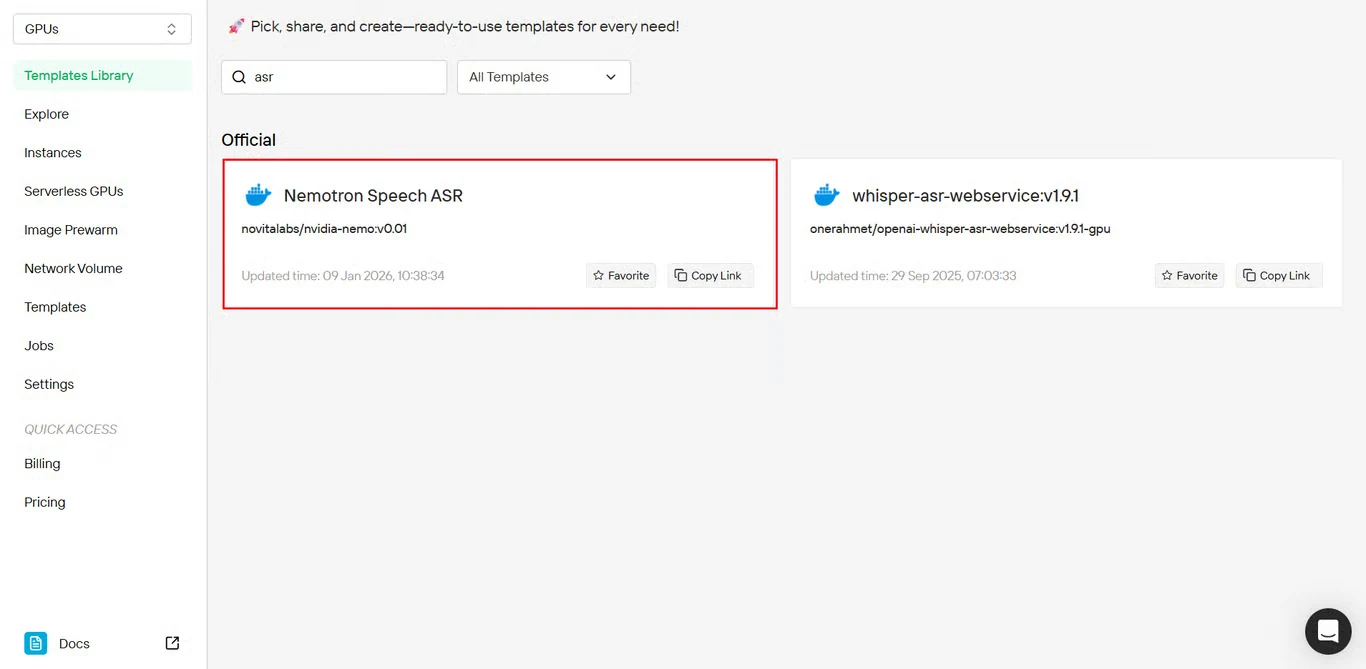
Schritt 2: Nemotron Speech ASR-Vorlage auswählen
Suchen Sie Nemotron Speech ASR in der Vorlagenbibliothek und klicken Sie darauf, um die Installation zu starten.
Direkter Vorlagenzugang: https://novita.ai/templates-library/108969
Die Vorlage enthält vorkonfigurierte NeMo Framework-Einstellungen und optimierte Parameter für die Bereitstellung von Nemotron Speech ASR.
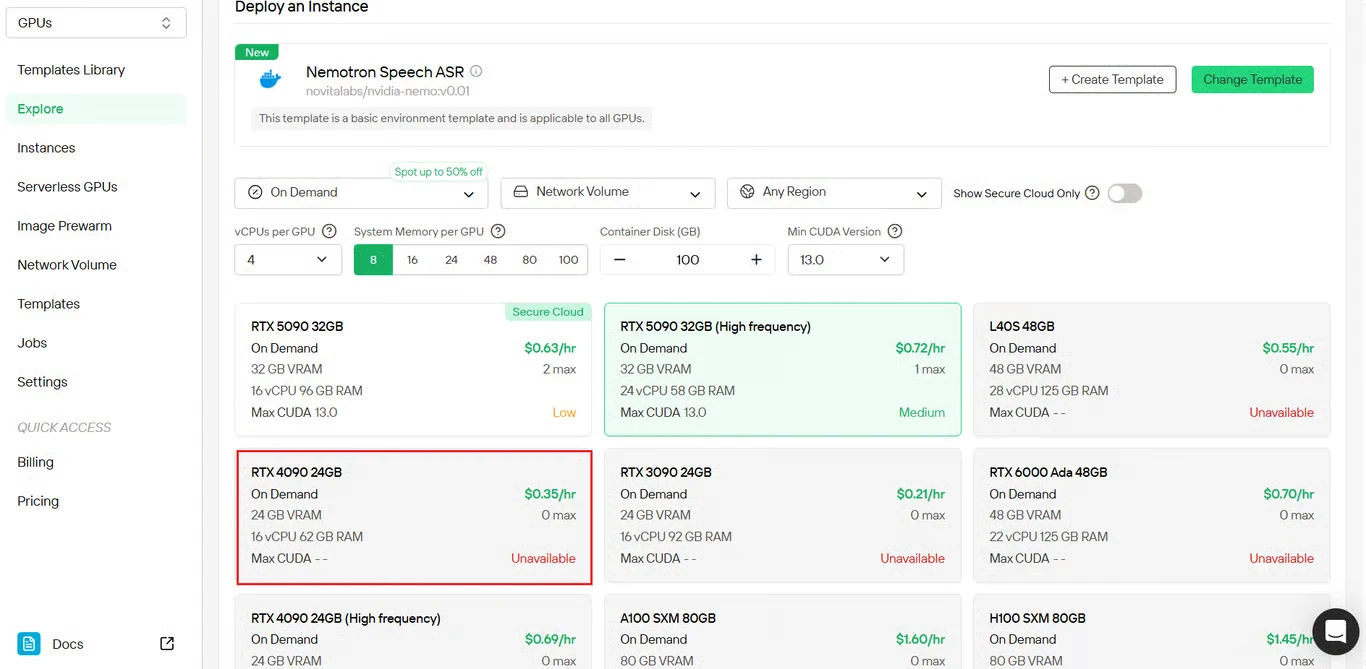
Schritt 3: GPU-Instanzeinstellungen konfigurieren
Konfigurieren Sie die Parameter Ihrer GPU-Instanz:
- Speicherzuweisung: Basierend auf den erwarteten gleichzeitigen Audio-Streams
- Speicheranforderungen: Ausreichend Platz für Modelldateien und Audioverarbeitung
- Netzwerkeinstellungen: Konfigurieren Sie diese für Ihre geografische Region
- GPU-Auswahl: Wählen Sie basierend auf den Durchsatzanforderungen
Klicken Sie auf Bereitstellen, um mit Ihrer Konfiguration fortzufahren.
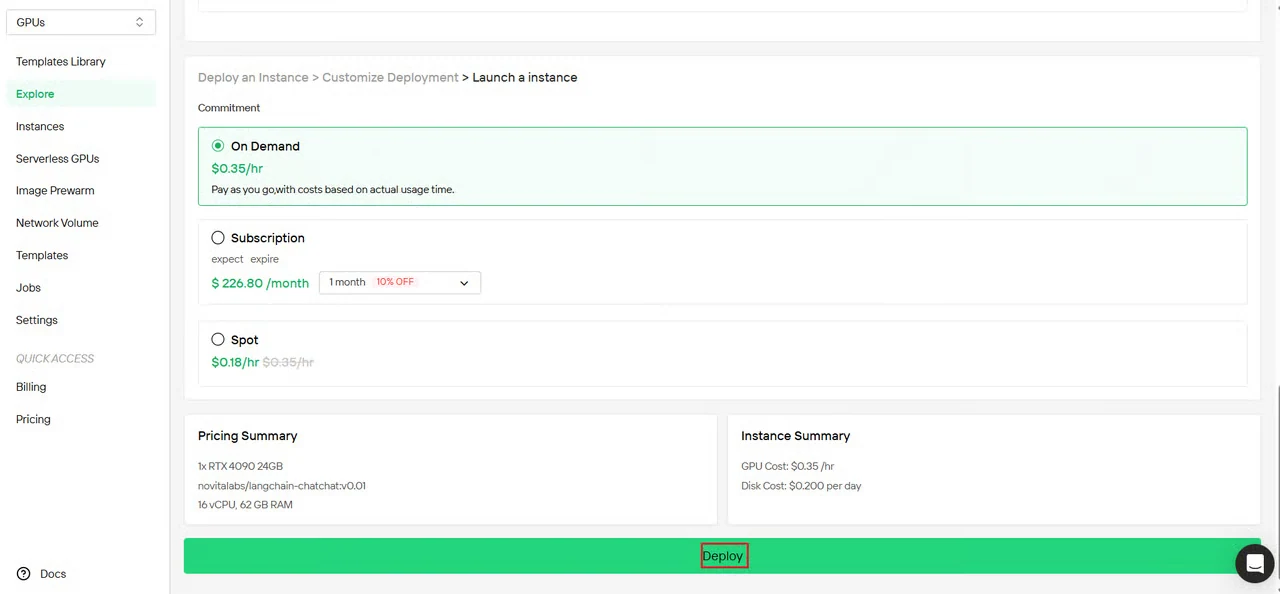
Schritt 4: Konfiguration überprüfen und bereitstellen
Überprüfen Sie die Zusammenfassung Ihrer Instanzkonfiguration:
- GPU-Typ und -Anzahl
- Speicher- und Speicherplatzzuweisung
- Netzwerkregion
- Geschätzte Kosten
Überprüfen Sie alle Einstellungen und klicken Sie auf Bereitstellen, um die Instanzerstellung zu starten.
Schritt 5: Instanzerstellung überwachen
Nach Einleitung der Bereitstellung werden Sie von Novita AI automatisch zur Instanzverwaltungsseite weitergeleitet.
Ihre Nemotron Speech ASR-Instanz wird im Hintergrund erstellt, während Sie den Fortschritt überwachen.
Schritt 6: Download-Fortschritt verfolgen
Überwachen Sie den Download des NeMo Framework-Images in Echtzeit.
Der Instanzstatus aktualisiert sich von Pulling zu Running, sobald die Bereitstellung abgeschlossen ist.
Klicken Sie auf das Pfeilsymbol neben Ihrem Instanznamen, um detaillierte Fortschrittsinformationen zu erhalten.
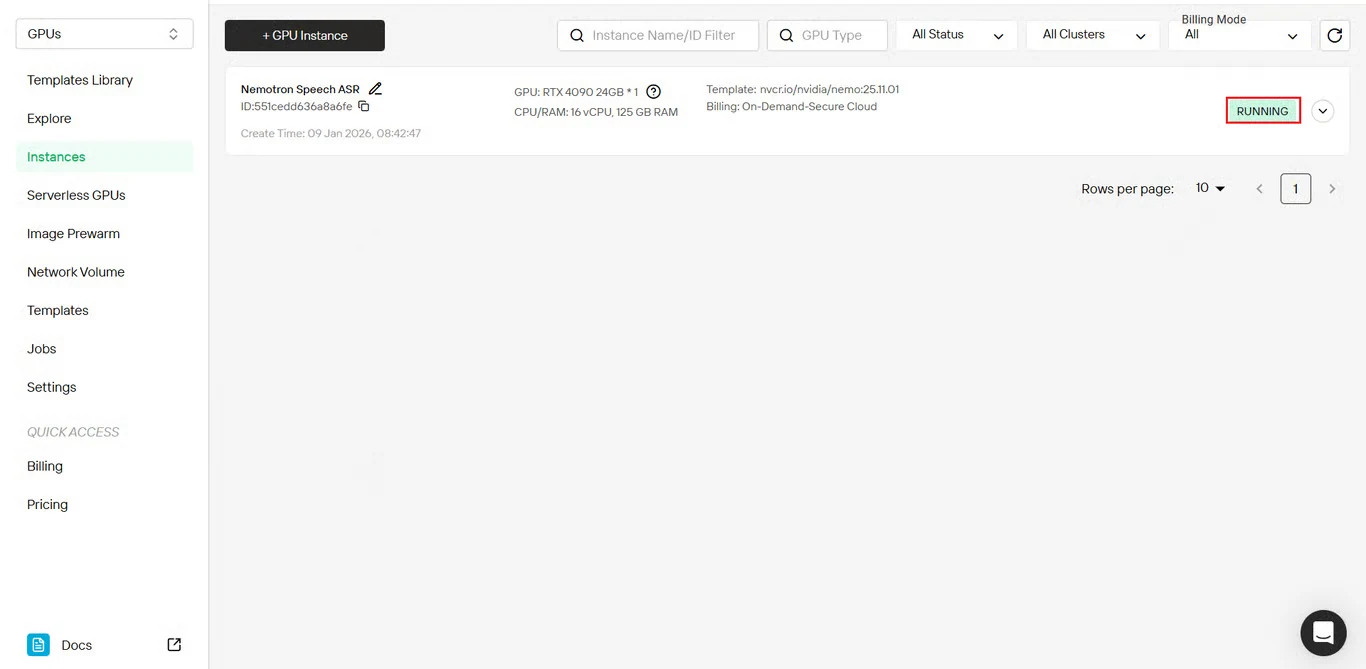
Schritt 7: Bereitstellungsstatus überprüfen
Klicken Sie auf die Schaltfläche Logs, um die Startprotokolle der Instanz einzusehen.
Überprüfen Sie, ob die NeMo-Dienste korrekt initialisiert wurden und Nemotron Speech ASR für die Inferenz bereit ist.
NeMo Framework-Abhängigkeiten installieren
Sobald Ihre GPU-Instanz läuft, stellen Sie eine SSH-Verbindung her, um die erforderlichen Abhängigkeiten zu installieren.
Systemabhängigkeiten und NeMo Toolkit installieren
Führen Sie die folgenden Befehle aus, um Ihre Umgebung einzurichten:
bash
apt-get update && apt-get install -y libsndfile1 ffmpeg
pip install Cython packaging
pip install git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]
Aufschlüsselung der Abhängigkeiten:
- libsndfile1: Audio-Ein-/Ausgabe-Bibliothek für die WAV-Verarbeitung
- ffmpeg: Multimedia-Framework für die Audioumwandlung
- Cython: Leistungsoptimierung für Python-Code
- nemo_toolkit[asr]: NeMo Framework mit ASR-spezifischen Modulen
Die Installation dauert je nach Netzwerkgeschwindigkeit 5–10 Minuten.
NVIDIA Nemotron Speech ASR-Modell ausführen
Nemotron Speech ASR-Modell herunterladen
Laden Sie NVIDIA Nemotron Speech ASR aus dem offiziellen Hugging Face-Repository herunter.
Das Modulldateiformat ist .nemo und enthält alle erforderlichen Parameter für die Inferenz.
Offizielles NeMo-Inferenzskript verwenden
Das NeMo Framework bietet ein optimiertes Inferenzskript für cache-aware Streaming-ASR.
Referenzskript: speech_to_text_cache_aware_streaming_infer.py
Nemotron Speech ASR-Inferenz ausführen
Führen Sie den folgenden Befehl aus, um Audio zu transkribieren:
bash
python speech_to_text_cache_aware_streaming_infer.py \
model_path=/yourPath/nemotron-speech-streaming-en-0.6b/nemotron-speech-streaming-en-0.6b.nemo \
audio_file=/yourPath/audio.wav
Inferenzparameter
Konfigurieren Sie diese Parameter für Ihre Bereitstellung:
- model_path: Vollständiger Pfad zur Nemotron Speech ASR-
.nemo-Modelldatei - audio_file: Pfad zur Eingabe-Audiodatei (WAV-Format empfohlen)
Beispiel für eine Transkriptionsausgabe
Eine erfolgreiche Inferenz erzeugt eine Ausgabe wie folgt:
bash
[NeMo I 2026-01-09 08:13:32 speech_to_text_cache_aware_streaming_infer:282] Final streaming transcriptions: ['The English forwarded to the French baskets of flowers of which they had made a plentiful provision to greet the arrival of the young princess. The French, in return, invited the English to a supper, which was to be given the next day.']
Dies bestätigt, dass Nemotron Speech ASR den Audio-Stream mithilfe der cache-aware Streaming-Architektur erfolgreich in Text umgewandelt hat.
Anwendungsfälle von Nemotron Speech ASR
Echtzeit-Live-Transkription
Setzen Sie NVIDIA Nemotron Speech ASR für Live-Untertitelungssysteme in Meetings, Webinaren und Übertragungen ein.
Die Latenz unter 100 ms sorgt dafür, dass Untertitel in Echtzeit ohne spürbare Verzögerungen angezeigt werden.
Sprachassistenten-Anwendungen
Erstellen Sie konversationelle KI-Agenten mit sofortiger Spracherkennung für natürliche Benutzerinteraktionen.
Cache-aware Streaming eliminiert Pufferungsverzögerungen für reaktionsschnelle Sprachbefehle.
Call-Center-Analysen und -Überwachung
Transkribieren Sie Kundenanrufe in Echtzeit für Sentiment-Analysen, Compliance-Überwachung und Agentenunterstützung.
Der hohe Durchsatz (3x Verbesserung) ermöglicht die gleichzeitige Verarbeitung von Anrufen ohne zusätzliche GPU-Ressourcen.
Barrierefreiheitslösungen
Entwickeln Sie Assistenztechnologien für hörgeschädigte Nutzer, die Live-Untertitel mit niedriger Latenz benötigen.
Die stabile Latenzleistung gewährleistet eine konsistente Barrierefreiheit unter unterschiedlichen Audio-Bedingungen.
Medienproduktion und Content-Erstellung
Automatisieren Sie die Untertitelgenerierung für Podcasts, Videos und Live-Streams mit hochgenauer englischer Transkription.
Die Streaming-Architektur verarbeitet Langform-Inhalte effizient ohne Speicherbeschränkungen.
Fazit
Die Bereitstellung von NVIDIA Nemotron Speech ASR auf Novita AI GPU-Instanzen liefert produktionsreife Spracherkennungsinfrastruktur in Minuten, nicht in Stunden.
Die cache-aware Streaming-Architektur des Modells bietet die stabile Latenz unter 100 ms und die 3x höhere GPU-Effizienz, die Ihre Echtzeitanwendungen benötigen. Die vorkonfigurierte Vorlage von Novita AI eliminiert die komplexe Einrichtung des NeMo Frameworks, sodass Sie sich auf die Entwicklung von Sprachanwendungen konzentrieren können, anstatt Infrastruktur zu verwalten.
Egal, ob Sie Sprachassistenten, Transkriptionsdienste, Call-Center-Analysen oder Barrierefreiheitstools entwickeln – diese Bereitstellungskombination beseitigt die traditionellen Kompromisse zwischen Latenz, Durchsatz und operativer Komplexität.
Starten Sie noch heute die Bereitstellung von Nemotron Speech ASR auf Novita AI mit flexibler GPU-Abrechnung nach Sekunden und ohne Vorabkosten.
Novita AI ist eine führende KI-Cloud-Plattform, die Entwicklern benutzerfreundliche APIs und erschwingliche, zuverlässige GPU-Infrastruktur für die Entwicklung und Skalierung von KI-Anwendungen bietet.



