

يتطلب التعرف على الكلام في الوقت الفعلي أكثر من مجرد دقة، بل يحتاج إلى زمن استجابة منخفض ومستمر دون استهلاك مفرط لدورات GPU.
يحل نموذج NVIDIA Nemotron Speech ASR مشكلة انحراف زمن الاستجابة والحسابات المكررة بفضل بنية البث المتدفق الواعية بالذاكرة المؤقتة. هذا يلغي الحاجة إلى استدلال مخزّن مؤقتاً، ويوفر زمن استجابة مستقر أقل من 100 مللي ثانية (24 مللي ثانية كمتوسط لزمن الوصول لأول رمز) ويزيد الإنتاجية على GPU الخاص بك حتى 3 أضعاف.
يوضح لك هذا الدليل كيفية نشر NVIDIA Nemotron Speech ASR على مثيلات GPU من Novita AI باستخدام القالب المُعد مسبقاً الخاص بنا. ابنِ تطبيقات صوتية بمستوى إنتاجي دون تعقيدات البنية التحتية.
ما هو نموذج NVIDIA Nemotron Speech ASR؟
نموذج NVIDIA Nemotron Speech ASR هو نموذج تعرف تلقائي على الكلام بالبث المتدفق مصمم للتطبيقات في الوقت الفعلي مع زمن استجابة أدنى ممكن.
تعتمد أنظمة ASR التقليدية على مقاطع صوتية مخزّنة مؤقتاً، مما يخلق انحرافاً في زمن الاستجابة واستخدام غير فعال لـ GPU. يستخدم Nemotron Speech ASR البث المتدفق الواعي بالذاكرة المؤقتة لمعالجة الصوت بشكل مستمر دون تأخيرات ناتجة عن التخزين المؤقت.
مواصفات NVIDIA Nemotron Speech ASR:
- البنية: ASR بالبث المتدفق الواعي بالذاكرة المؤقتة مع Conformer-CTC
- أداء زمن الاستجابة: معالجة من الطرف إلى الطرف أقل من 100 مللي ثانية
- زمن الوصول لأول رمز: 24 مللي ثانية كمتوسط لزمن الاستجابة
- تحسين الإنتاجية: حتى 3 أضعاف مقارنة بالاستدلال المخزّن مؤقتاً
- دعم اللغات: الإنجليزية (النسخة ذات 0.6 مليار معامل)
- حجم النموذج: 600 مليون معامل مُحسّن للبث المتدفق
تؤدي بنية البث المتدفق الواعية بالذاكرة المؤقتة إلى القضاء على انحراف زمن الاستجابة والحسابات المكررة، مما يجعل NVIDIA Nemotron Speech ASR مثالياً للنسخ المباشر، والمساعدين الصوتيين، وتحليلات مراكز الاتصال، وتطبيقات الذكاء الاصطناعي التفاعلية.
ما هو إطار عمل NVIDIA NeMo؟
إطار عمل NVIDIA NeMo هو إطار ذكاء اصطناعي توليدي قابل للتطوير ومصمم للبيئة السحابية، مخصص للباحثين ومطوري PyTorch.
يدعم إطار عمل NeMo التطوير عبر مجالات ذكاء اصطناعي متعددة:
- نماذج اللغة الكبيرة (LLMs)
- النماذج متعددة الوسائط (MMs)
- التعرف التلقائي على الكلام (ASR)
- تحويل النص إلى كلام (TTS)
- الرؤية الحاسوبية (CV)
يساعدك هذا الإطار على إنشاء نماذج الذكاء الاصطناعي التوليدي وتخصيصها ونشرها بكفاءة من خلال الاستفادة من الكود الموجود ونقاط تفتيش النماذج المُدرّبة مسبقاً.
يُبنى نموذج NVIDIA Nemotron Speech ASR على إطار عمل NeMo، مما يوفر قدرات ASR جاهزة للإنتاج مع إعداد أدنى.
للحصول على الوثائق التقنية الكاملة، راجع دليل مستخدم إطار عمل NeMo.
لماذا تنشر Nemotron Speech ASR على Novita AI؟
توفر مثيلات GPU من Novita AI بنية تحتية مُحسّنة لنشر NVIDIA Nemotron Speech ASR على نطاق واسع:
نشر سريع: ابدأ مثيلات GPU في ثوانٍ باستخدام قوالب NeMo المُعدة مسبقاً. لا حاجة لإعداد بيئة يدوي.
تسعير فعال من حيث التكلفة: فواتير بالثانية بدون عقود طويلة الأجل أو التزامات دنيا. قم بالتوسع أو التقلص بناءً على الطلب.
قوالب مُعدة مسبقاً: يأتي إطار عمل NeMo والتبعيات مُثبتة مسبقاً. ابدأ تشغيل Nemotron Speech ASR فوراً.
بنية تحتية عالمية: وصول منخفض الزمن لـ GPU عبر مناطق متعددة للنشر على مستوى العالم.
أدوات للمطورين: مراقبة في الوقت الفعلي، وصول عبر SSH، ونشر سهل للقوالب من مكتبة Novita AI.
سواء كنت تُطوّر نموذجاً أولياً لمساعد صوتي أو تقوم بتوسيع خط أنابيب نسخ إنتاجي، فإن Novita AI تتولى إدارة بنية GPU التحتية حتى تتمكن من التركيز على بناء تطبيقات ASR.
المتطلبات الأساسية للنشر
قبل نشر NVIDIA Nemotron Speech ASR، تأكد من أن لديك:
- حساب Novita AI مع رصيد كافٍ (سجل هنا)
- ملفات صوتية اختبارية بتنسيق WAV للتحقق من صحة النموذج
- معرفة أساسية بـ SSH للوصول إلى المثيل وتكوينه
- فهم لمتطلبات GPU الخاصة بحمل العمل المحدد الخاص بك
لا حاجة إلى خبرة سابقة بإطار عمل NeMo—يتولى قالب Novita AI الإعداد الأولي.
نشر Nemotron Speech ASR: دليل خطوة بخطوة
الخطوة 1: الوصول إلى وحدة تحكم Novita AI
سجل الدخول إلى حسابك في Novita AI وانتقل إلى واجهة GPU.
اختر ابدأ الآن للوصول إلى لوحة إدارة النشر.
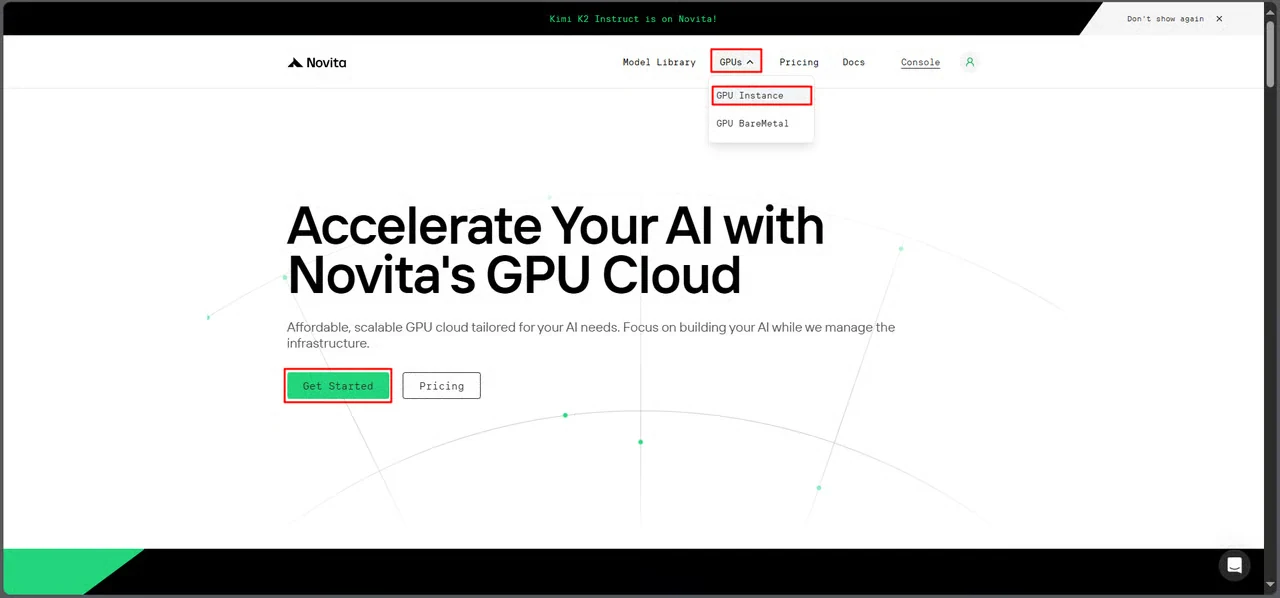
الخطوة 2: اختيار قالب Nemotron Speech ASR
ابحث عن Nemotron Speech ASR في مستودع القوالب وانقر لبدء التثبيت.
الوصول المباشر إلى القالب: https://novita.ai/templates-library/108969
يتضمن القالب إعدادات إطار عمل NeMo المُعدة مسبقاً والمعلمات المُحسّنة لنشر Nemotron Speech ASR.
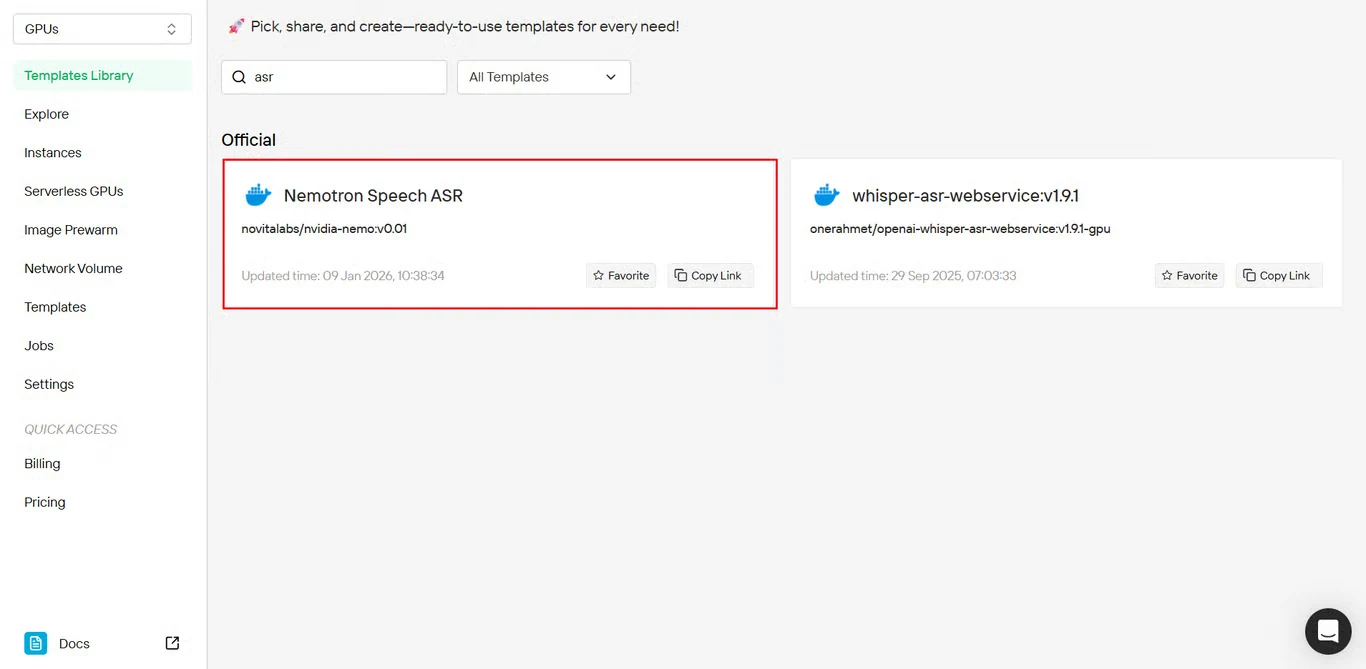
الخطوة 3: تكوين إعدادات مثيل GPU
قم بتكوين معلمات مثيل GPU الخاص بك:
- تخصيص الذاكرة: بناءً على تدفقات الصوت المتزامنة المتوقعة
- متطلبات التخزين: مساحة كافية لملفات النموذج ومعالجة الصوت
- إعدادات الشبكة: قم بتكوينها بناءً على منطقتك الجغرافية
- اختيار GPU: اختر بناءً على متطلبات الإنتاجية
انقر نشر للمتابعة مع التكوين الخاص بك.
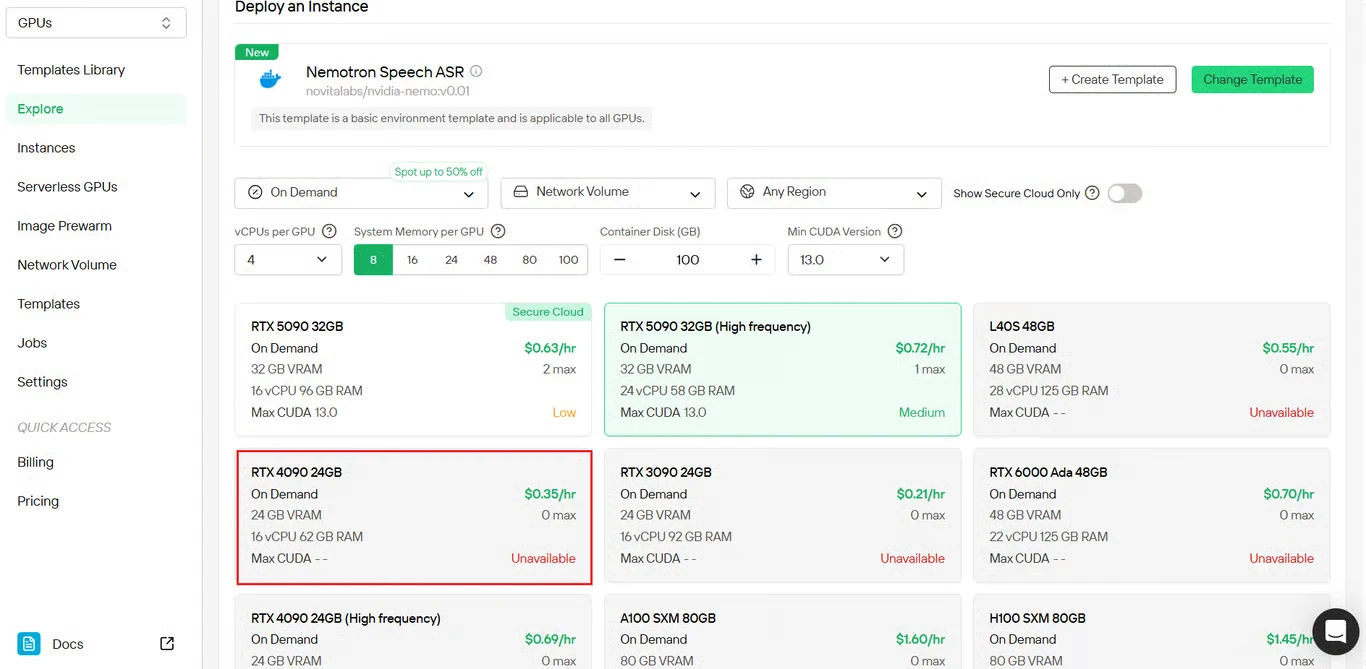
الخطوة 4: مراجعة التكوين والنشر
راجع ملخص تكوين المثيل الخاص بك:
- نوع وكمية GPU
- تخصيص الذاكرة والتخزين
- منطقة الشبكة
- التكاليف المقدرة
تحقق من جميع الإعدادات وانقر نشر لبدء إنشاء المثيل.
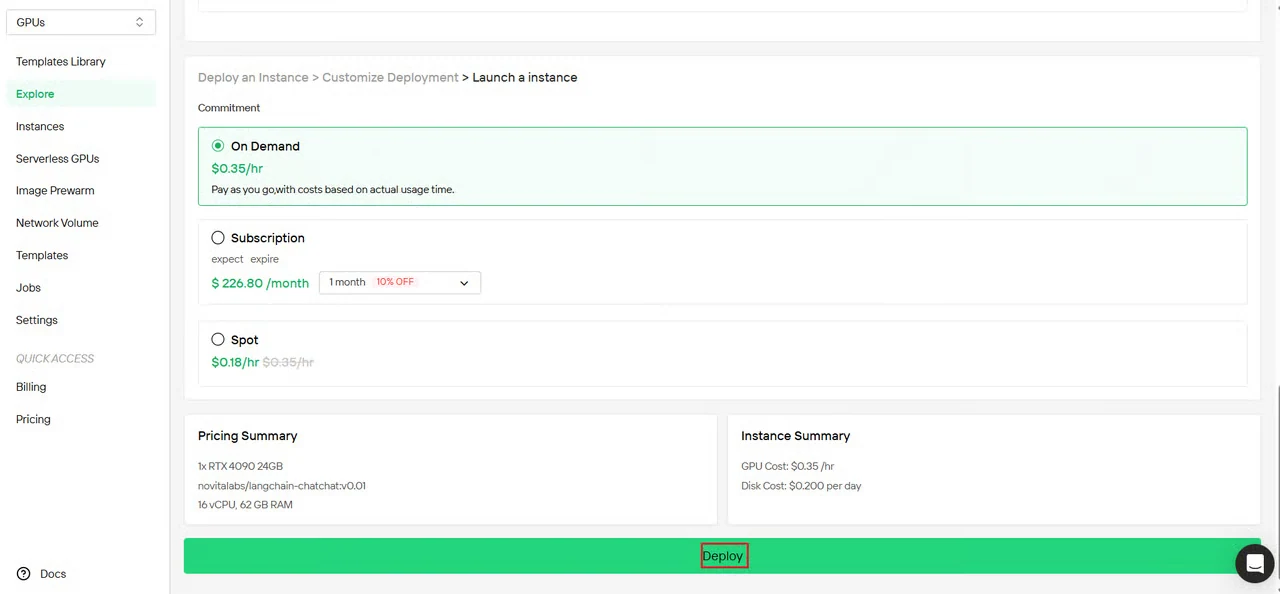
الخطوة 5: مراقبة إنشاء المثيل
بعد بدء النشر، تعيدك Novita AI تلقائياً إلى صفحة إدارة المثيلات.
يتم إنشاء مثيل Nemotron Speech ASR الخاص بك في الخلفية بينما تراقب التقدم.
الخطوة 6: تتبع تقدم التنزيل
راقب تنزيل صورة إطار عمل NeMo في الوقت الفعلي.
يتم تحديث حالة المثيل من سحب إلى قيد التشغيل عند اكتمال النشر.
انقر على أيقونة السهم بجانب اسم المثيل للحصول على معلومات تفصيلية عن التقدم.
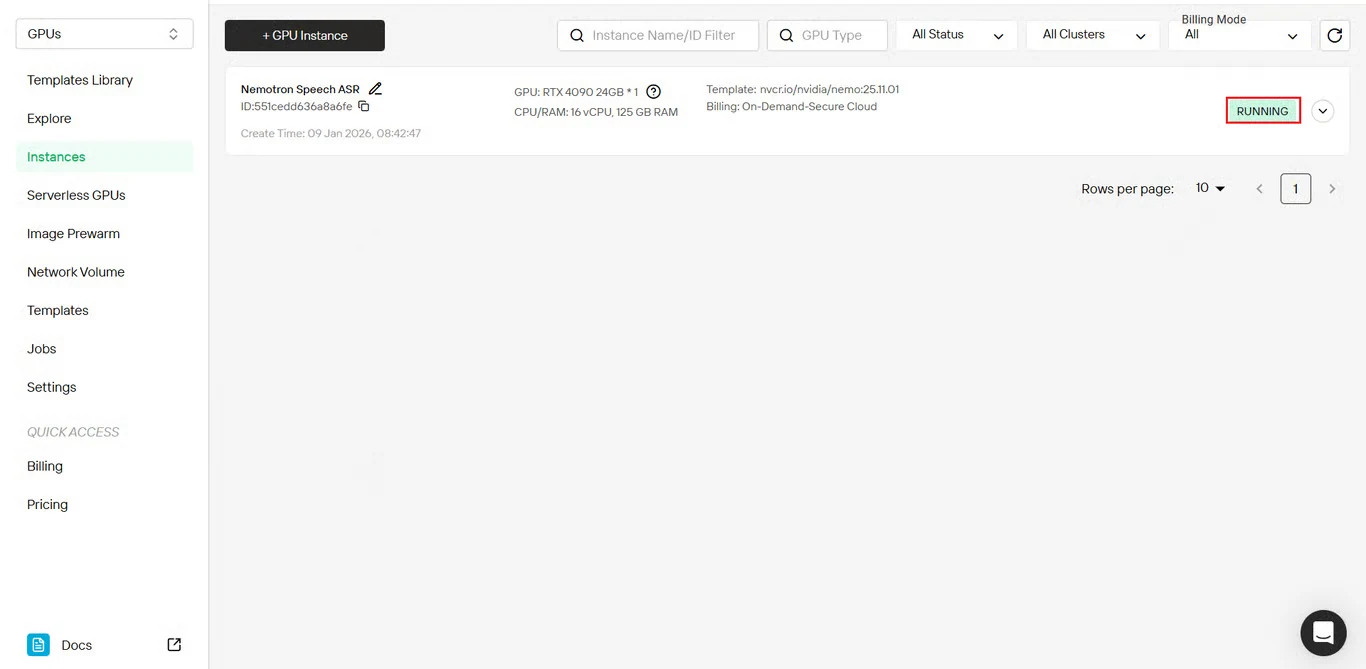
الخطوة 7: التحقق من حالة النشر
انقر على زر السجلات لعرض سجلات بدء تشغيل المثيل.
تحقق من أن خدمات NeMo تم تهيئتها بشكل صحيح وأن Nemotron Speech ASR جاهز للاستدلال.
تثبيت تبعيات إطار عمل NeMo
بمجرد تشغيل مثيل GPU الخاص بك، اتصل عبر SSH لتثبيت التبعيات المطلوبة.
تثبيت التبعيات النظامية ومجموعة أدوات NeMo
قم بتشغيل الأوامر التالية لإعداد بيئتك:
bash
apt-get update && apt-get install -y libsndfile1 ffmpeg
pip install Cython packaging
pip install git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]
تفصيل التبعيات:
- libsndfile1: مكتبة إدخال/إخراج لملفات الصوت لمعالجة ملفات WAV
- ffmpeg: إطار عمل متعدد الوسائط لتحويل الصوت
- Cython: تحسين الأداء لكود Python
- nemo_toolkit[asr]: إطار عمل NeMo مع وحدات ASR المحددة
يكتمل التثبيت في 5 إلى 10 دقائق بناءً على سرعة الشبكة.
تشغيل نموذج NVIDIA Nemotron Speech ASR
تنزيل نموذج Nemotron Speech ASR
قم بتنزيل NVIDIA Nemotron Speech ASR من مستودع Hugging Face الرسمي.
تنسيق ملف النموذج هو .nemo ويحتوي على جميع المعلمات المطلوبة للاستدلال.
استخدام سكريبت الاستدلال الرسمي لـ NeMo
يوفر إطار عمل NeMo سكريبت استدلال مُحسّن لـ ASR بالبث المتدفق الواعي بالذاكرة المؤقتة.
السكريبت المرجعي: speech_to_text_cache_aware_streaming_infer.py
تشغيل استدلال Nemotron Speech ASR
قم بتشغيل الأمر التالي لنسخ الصوت إلى نص:
bash
python speech_to_text_cache_aware_streaming_infer.py \
model_path=/yourPath/nemotron-speech-streaming-en-0.6b/nemotron-speech-streaming-en-0.6b.nemo \
audio_file=/yourPath/audio.wav
معلمات الاستدلال
قم بتكوين هذه المعلمات للنشر الخاص بك:
- model_path: المسار الكامل لملف نموذج Nemotron Speech ASR بتنسيق
.nemo - audio_file: المسار لملف الصوت المدخل (يُفضل تنسيق WAV)
مثال على مخرج النسخ
ينتج الاستدلال الناجح مخرجاً مشابهاً لما يلي:
bash
[NeMo I 2026-01-09 08:13:32 speech_to_text_cache_aware_streaming_infer:282] Final streaming transcriptions: ['The English forwarded to the French baskets of flowers of which they had made a plentiful provision to greet the arrival of the young princess. The French, in return, invited the English to a supper, which was to be given the next day.']
هذا يؤكد أن Nemotron Speech ASR حول تدفق الصوت إلى نص بنجاح باستخدام بنية البث المتدفق الواعية بالذاكرة المؤقتة.
حالات استخدام Nemotron Speech ASR
النسخ المباشر في الوقت الفعلي
انشر NVIDIA Nemotron Speech ASR لأنظمة الترجمة المباشرة في الاجتماعات والندوات عبر الإنترنت والبثوث.
يضمن زمن الاستجابة الأقل من 100 مللي ثانية ظهور الترجمة في الوقت الفعلي دون تأخيرات ملحوظة.
تطبيقات المساعد الصوتي
ابنِ وكلاء ذكاء اصطناعي محادثيين مع تعرف فوري على الكلام لتفاعلات مستخدم طبيعية.
يلغي البث المتدفق الواعي بالذاكرة المؤقتة تأخيرات التخزين المؤقت لأوامر صوتية سريعة الاستجابة.
تحليقات ومراقبة مراكز الاتصال
قم بنسخ مكالمات العملاء في الوقت الفعلي لتحليل المشاعر، ومراقبة الامتثال، ومساعدة الوكلاء.
تتيح الإنتاجية العالية (تحسين 3 أضعاف) معالجة مكالمات متزامنة دون موارد GPU إضافية.
حلول إمكانية الوصول
أنشئ تقنيات مساعدة للمستخدمين ذوي الإعاقة السمعية الذين يحتاجون إلى ترجمات مباشرة منخفضة الزمن.
يضمن أداء زمن الاستجابة المستقر إمكانية وصول متسقة عبر ظروف صوتية مختلفة.
إنتاج الوسائط وإنشاء المحتوى
أتمتة إنشاء الترجمات للبودكاست والفيديوهات والبثوث المباشرة مع نسخ إنجليزي عالي الدقة.
تعالج بنية البث المتدفق المحتوى الطويل بكفاءة دون قيود على الذاكرة.
الخلاصة
يوفر نشر NVIDIA Nemotron Speech ASR على مثيلات GPU من Novita AI بنية تحتية للتعرف على الكلام جاهزة للإنتاج في دقائق وليس ساعات.
توفر بنية البث المتدفق الواعية بالذاكرة المؤقتة للنموذج زمن استجابة مستقر أقل من 100 مللي ثانية وتحسين كفاءة GPU بنسبة 3 أضعاف الذي تتطلبه تطبيقاتك في الوقت الفعلي. يلغي القالب المُعد مسبقاً من Novita AI إعداد إطار عمل NeMo المعقد، مما يسمح لك بالتركيز على بناء تطبيقات صوتية بدلاً من إدارة البنية التحتية.
سواء كنت تُطوّر مساعدين صوتيين، أو خدمات نسخ، أو تحليلات لمراكز الاتصال، أو أدوات إمكانية وصول، فإن هذا المزيج من النشر يزيل المفاضلات التقليدية بين زمن الاستجابة والإنتاجية والتعقيدات التشغيلية.
ابدأ نشر Nemotron Speech ASR على Novita AI اليوم مع تسعير GPU مرن بالثانية وبدون التزامات مسبقة.
Novita AI هي منصة سحابية رائدة للذكاء الاصطناعي توفر للمطورين واجهات برمجة تطبيقات سهلة الاستخدام وبنية تحتية لـ GPU موثوقة وبأسعار معقولة لبناء وتوسيع نطاق تطبيقات الذكاء الاصطناعي.



