

실시간 음성 인식은 정확성 이상의 것을 요구합니다. 즉, GPU 사이클을 낭비하지 않으면서 일관된 낮은 지연 시간이 필요합니다.
NVIDIA Nemotron Speech ASR 모델은 캐시 인식 스트리밍 아키텍처를 통해 지연 시간 드리프트와 중복 연산 문제를 해결합니다. 이는 버퍼링된 추론의 필요성을 없애주며, 안정적인 100ms 미만의 지연 시간(첫 토큰까지 중간 24ms)과 GPU에서 최대 3배의 처리량 향상을 제공합니다.
이 가이드에서는 사전 구성된 템플릿을 사용하여 Novita AI GPU 인스턴스에 NVIDIA Nemotron Speech ASR을 배포하는 방법을 보여줍니다. 인프라 복잡성 없이 프로덕션 등급의 음성 애플리케이션을 구축할 수 있습니다.
NVIDIA Nemotron Speech ASR이란?
NVIDIA Nemotron Speech ASR은 최소 지연 시간으로 실시간 애플리케이션을 위해 설계된 스트리밍 자동 음성 인식 모델입니다.
기존 ASR 시스템은 버퍼링된 오디오 청크에 의존하여 지연 시간 드리프트와 비효율적인 GPU 사용을 초래합니다. Nemotron Speech ASR은 캐시 인식 스트리밍을 사용하여 버퍼링 지연 없이 오디오를 지속적으로 처리합니다.
NVIDIA Nemotron Speech ASR 사양:
- 아키텍처: Conformer-CTC 기반 캐시 인식 스트리밍 ASR
- 지연 시간 성능: 종단 간 100ms 미만 처리
- 첫 토큰까지의 시간: 중간 24ms 지연 시간
- 처리량 개선: 버퍼링된 추론 대비 최대 3배
- 지원 언어: 영어 (0.6B 파라미터 변형)
- 모델 크기: 스트리밍에 최적화된 6억 파라미터
캐시 인식 스트리밍 아키텍처는 지연 시간 드리프트와 중복 연산을 제거하여, NVIDIA Nemotron Speech ASR이 실시간 자막, 음성 비서, 콜센터 분석 및 대화형 AI 애플리케이션에 이상적입니다.
NVIDIA NeMo 프레임워크란?
NVIDIA NeMo 프레임워크는 연구자와 PyTorch 개발자를 위한 확장 가능한 클라우드 네이티브 생성형 AI 프레임워크입니다.
NeMo 프레임워크는 여러 AI 도메인에 걸친 개발을 지원합니다:
- 대규모 언어 모델(LLM)
- 멀티모달 모델(MM)
- 자동 음성 인식(ASR)
- 텍스트 음성 변환(TTS)
- 컴퓨터 비전(CV)
이 프레임워크는 기존 코드와 사전 훈련된 모델 체크포인트를 활용하여 생성형 AI 모델을 효율적으로 생성, 커스터마이징 및 배포하는 데 도움을 줍니다.
NVIDIA Nemotron Speech ASR은 NeMo 프레임워크 위에 구축되어 최소한의 설정으로 프로덕션 준비가 완료된 ASR 기능을 제공합니다.
전체 기술 문서는 NeMo 프레임워크 사용자 가이드를 참조하세요.
Novita AI에서 Nemotron Speech ASR을 배포해야 하는 이유
Novita AI GPU 인스턴스는 대규모로 NVIDIA Nemotron Speech ASR을 배포하기 위한 최적화된 인프라를 제공합니다:
빠른 배포: 사전 구성된 NeMo 템플릿으로 몇 초 만에 GPU 인스턴스를 시작합니다. 수동 환경 설정이 필요하지 않습니다.
경제적인 가격: 초 단위 과금, 장기 계약이나 최소 약정이 없습니다. 수요에 따라 확장 또는 축소할 수 있습니다.
사전 구성된 템플릿: NeMo 프레임워크와 종속성이 사전 설치되어 제공됩니다. 즉시 Nemotron Speech ASR을 실행할 수 있습니다.
글로벌 인프라: 전 세계 배포를 위해 여러 리전에서 낮은 지연 시간의 GPU에 액세스할 수 있습니다.
개발자 도구: 실시간 모니터링, SSH 액세스, Novita AI 라이브러리에서 간편한 템플릿 배포 기능을 제공합니다.
음성 비서를 프로토타이핑하든 프로덕션 전사 파이프라인을 확장하든, Novita AI가 GPU 인프라를 처리하므로 사용자는 ASR 애플리케이션 구축에 집중할 수 있습니다.
배포를 위한 사전 요구 사항
NVIDIA Nemotron Speech ASR을 배포하기 전에 다음이 준비되어 있는지 확인하세요:
- 충분한 크레딧이 있는 Novita AI 계정 (회원가입)
- 모델 검증을 위한 WAV 형식의 오디오 테스트 파일
- 인스턴스 액세스 및 구성을 위한 기본 SSH 지식
- 워크로드에 맞는 GPU 요구 사항 이해
NeMo 프레임워크 경험이 필요하지 않습니다. Novita AI 템플릿이 초기 설정을 처리합니다.
Nemotron Speech ASR 배포: 단계별 가이드
1단계: Novita AI 콘솔에 액세스
Novita AI 계정에 로그인하고 GPU 인터페이스로 이동합니다.
시작하기를 선택하여 배포 관리 대시보드에 액세스합니다.
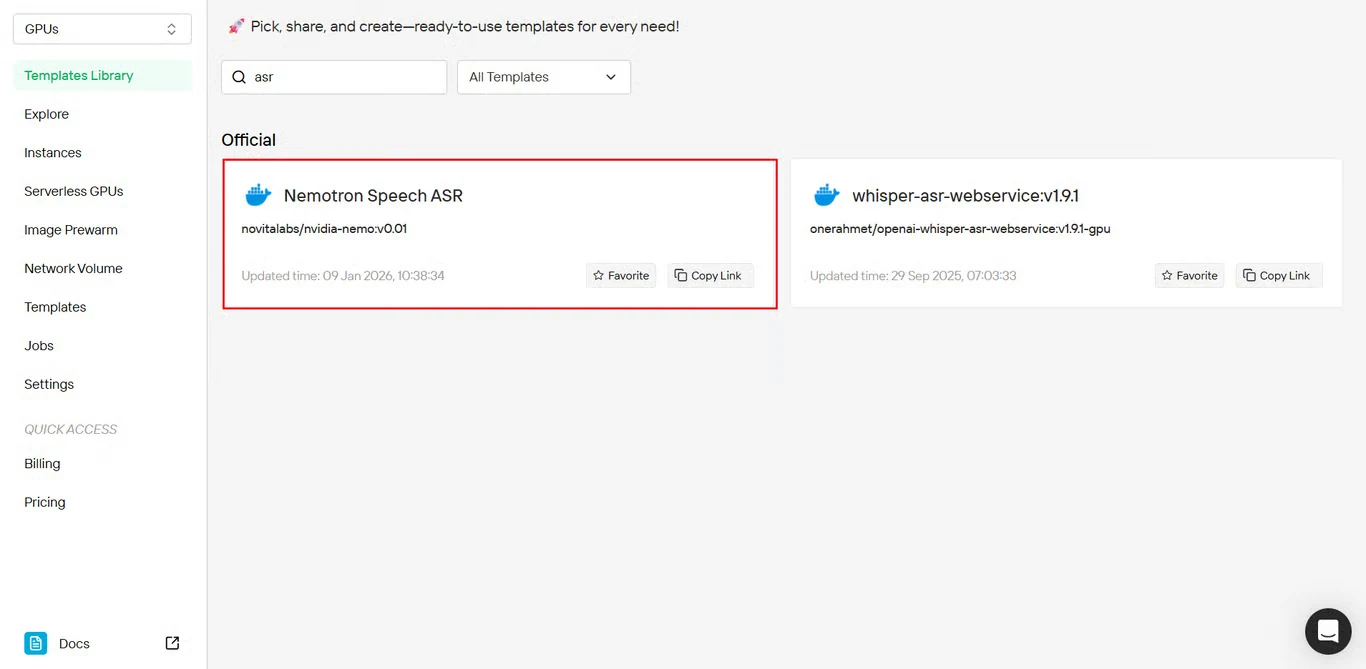
2단계: Nemotron Speech ASR 템플릿 선택
템플릿 저장소에서 Nemotron Speech ASR을 찾아 클릭하여 설치를 시작합니다.
템플릿 직접 액세스: https://novita.ai/templates-library/108969
이 템플릿에는 사전 구성된 NeMo 프레임워크 설정과 Nemotron Speech ASR 배포에 최적화된 매개변수가 포함되어 있습니다.
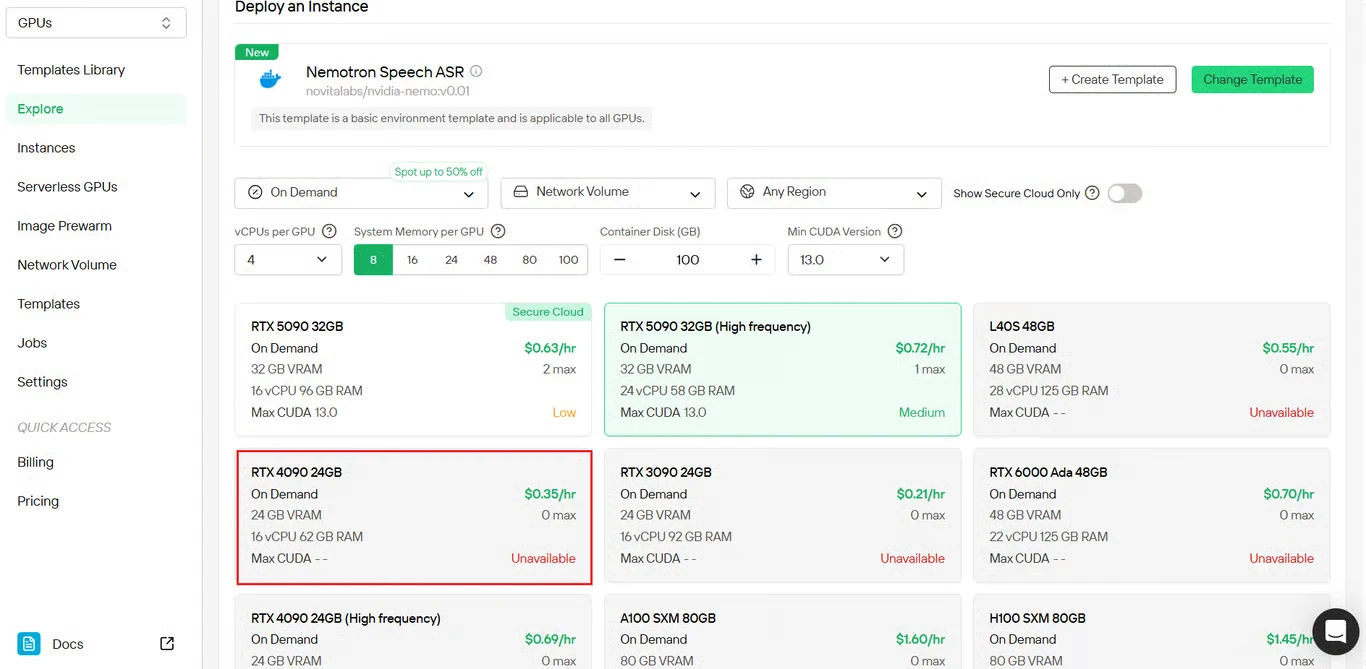
3단계: GPU 인스턴스 설정 구성
GPU 인스턴스 매개변수를 구성합니다:
- 메모리 할당: 예상되는 동시 오디오 스트림 수에 따라 설정
- 스토리지 요구 사항: 모델 파일 및 오디오 처리를 위한 충분한 공간
- 네트워크 설정: 지리적 리전에 맞게 구성
- GPU 선택: 처리량 요구 사항에 따라 선택
배포를 클릭하여 구성을 진행합니다.
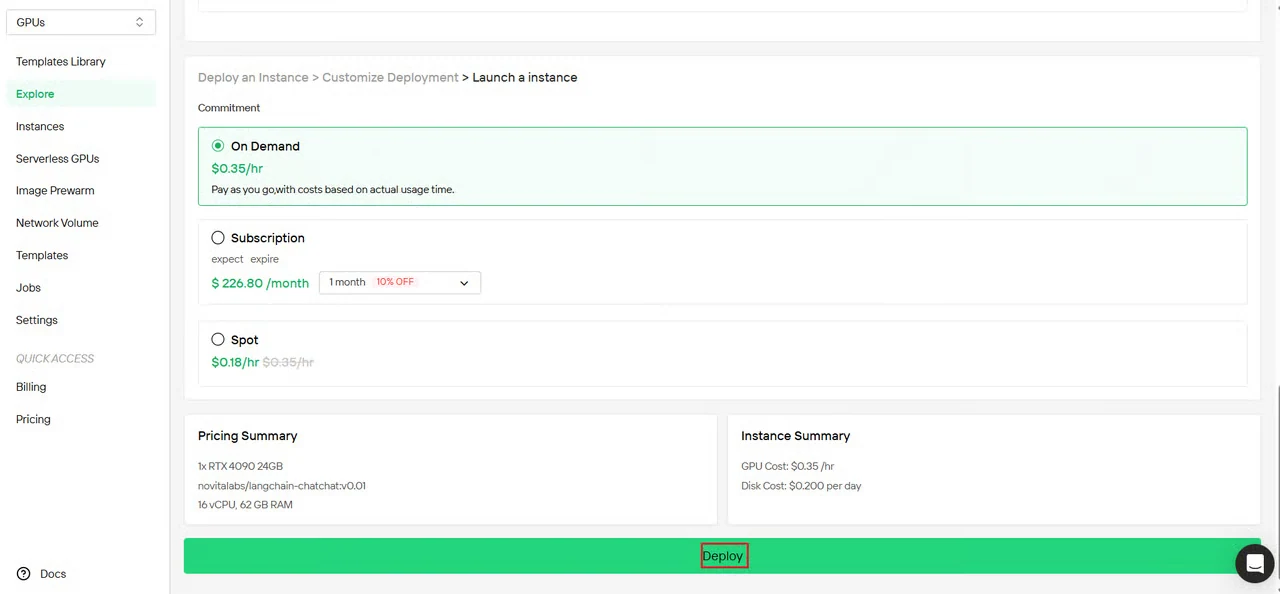
4단계: 구성 검토 및 배포
인스턴스 구성 요약을 검토합니다:
- GPU 유형 및 수량
- 메모리 및 스토리지 할당
- 네트워크 리전
- 예상 비용
모든 설정을 확인하고 배포를 클릭하여 인스턴스 생성을 시작합니다.
5단계: 인스턴스 생성 모니터링
배포를 시작하면 Novita AI가 자동으로 인스턴스 관리 페이지로 리디렉션합니다.
Nemotron Speech ASR 인스턴스가 백그라운드에서 생성되는 동안 진행 상황을 모니터링할 수 있습니다.
6단계: 다운로드 진행 상황 추적
NeMo 프레임워크 이미지 다운로드를 실시간으로 모니터링합니다.
인스턴스 상태가 Pulling에서 Running으로 변경되면 배포가 완료됩니다.
인스턴스 이름 옆의 화살표 아이콘을 클릭하면 자세한 진행 정보를 볼 수 있습니다.
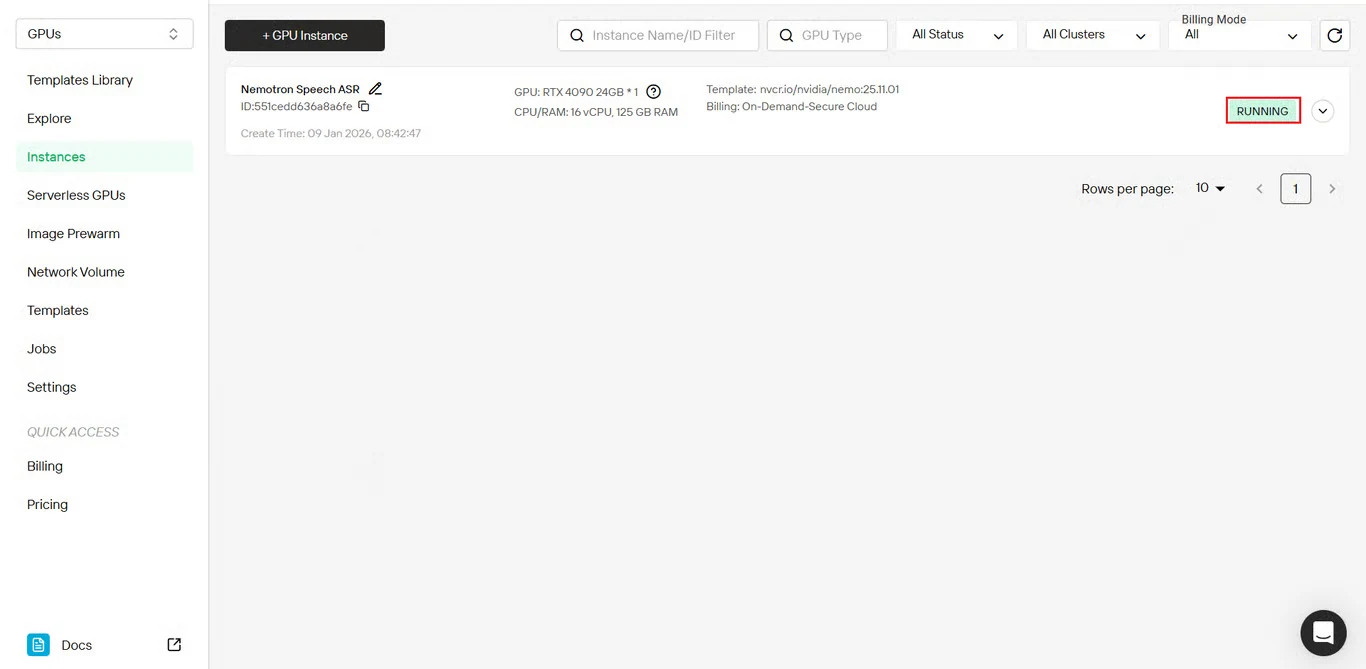
7단계: 배포 상태 확인
로그 버튼을 클릭하여 인스턴스 시작 로그를 확인합니다.
NeMo 서비스가 올바르게 초기화되었는지, Nemotron Speech ASR이 추론할 준비가 되었는지 확인합니다.
NeMo 프레임워크 종속성 설치
GPU 인스턴스가 실행되면 SSH로 연결하여 필요한 종속성을 설치합니다.
시스템 종속성 및 NeMo 툴킷 설치
다음 명령을 실행하여 환경을 설정합니다:
bash
apt-get update && apt-get install -y libsndfile1 ffmpeg
pip install Cython packaging
pip install git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]
종속성 설명:
- libsndfile1: WAV 처리를 위한 오디오 파일 I/O 라이브러리
- ffmpeg: 오디오 변환을 위한 멀티미디어 프레임워크
- Cython: Python 코드 성능 최적화
- nemo_toolkit[asr]: ASR 관련 모듈이 포함된 NeMo 프레임워크
설치는 네트워크 속도에 따라 5~10분 정도 소요됩니다.
NVIDIA Nemotron Speech ASR 모델 실행
Nemotron Speech ASR 모델 다운로드
공식 Hugging Face 저장소에서 NVIDIA Nemotron Speech ASR을 다운로드합니다.
모델 파일 형식은 .nemo이며 추론에 필요한 모든 매개변수를 포함합니다.
공식 NeMo 추론 스크립트 사용
NeMo 프레임워크는 캐시 인식 스트리밍 ASR을 위한 최적화된 추론 스크립트를 제공합니다.
참조 스크립트: speech_to_text_cache_aware_streaming_infer.py
Nemotron Speech ASR 추론 실행
다음 명령을 실행하여 오디오를 텍스트로 변환합니다:
bash
python speech_to_text_cache_aware_streaming_infer.py \
model_path=/yourPath/nemotron-speech-streaming-en-0.6b/nemotron-speech-streaming-en-0.6b.nemo \
audio_file=/yourPath/audio.wav
추론 매개변수
배포에 맞게 다음 매개변수를 구성합니다:
- model_path: Nemotron Speech ASR
.nemo모델 파일의 전체 경로 - audio_file: 입력 오디오 파일 경로 (WAV 형식 권장)
예제 전사 출력
성공적인 추론은 다음과 유사한 출력을 생성합니다:
bash
[NeMo I 2026-01-09 08:13:32 speech_to_text_cache_aware_streaming_infer:282] Final streaming transcriptions: ['The English forwarded to the French baskets of flowers of which they had made a plentiful provision to greet the arrival of the young princess. The French, in return, invited the English to a supper, which was to be given the next day.']
이는 Nemotron Speech ASR이 캐시 인식 스트리밍 아키텍처를 통해 오디오 스트림을 텍스트로 성공적으로 변환했음을 확인합니다.
Nemotron Speech ASR 사용 사례
실시간 라이브 전사
회의, 웨비나, 방송에서 라이브 자막 시스템을 위해 NVIDIA Nemotron Speech ASR을 배포합니다.
100ms 미만의 지연 시간으로 자막이 눈에 띄는 지연 없이 실시간으로 표시됩니다.
음성 비서 애플리케이션
자연스러운 사용자 상호작용을 위한 즉각적인 음성 인식 기능을 갖춘 대화형 AI 에이전트를 구축합니다.
캐시 인식 스트리밍은 반응형 음성 명령을 위해 버퍼링 지연을 제거합니다.
콜센터 분석 및 모니터링
감정 분석, 규정 준수 모니터링, 상담원 지원을 위해 고객 통화를 실시간으로 전사합니다.
높은 처리량(3배 향상)으로 추가 GPU 리소스 없이 동시 통화 처리가 가능합니다.
접근성 솔루션
저지연 라이브 자막이 필요한 청각 장애 사용자를 위한 보조 기술을 만듭니다.
안정적인 지연 시간 성능은 다양한 오디오 조건에서 일관된 접근성을 보장합니다.
미디어 제작 및 콘텐츠 생성
정확한 영어 전사 기능으로 팟캐스트, 비디오, 라이브 스트림의 자막 생성을 자동화합니다.
스트리밍 아키텍처는 메모리 제약 없이 긴 형식의 콘텐츠를 효율적으로 처리합니다.
결론
Novita AI GPU 인스턴스에 NVIDIA Nemotron Speech ASR을 배포하면 몇 시간이 아닌 몇 분 만에 프로덕션 준비가 완료된 음성 인식 인프라를 구축할 수 있습니다.
이 모델의 캐시 인식 스트리밍 아키텍처는 실시간 애플리케이션에 필요한 안정적인 100ms 미만 지연 시간과 3배의 GPU 효율성 향상을 제공합니다. Novita AI의 사전 구성된 템플릿은 복잡한 NeMo 프레임워크 설정을 없애주므로, 인프라 관리 대신 음성 애플리케이션 구축에 집중할 수 있습니다.
음성 비서, 전사 서비스, 콜센터 분석 또는 접근성 도구를 개발하든, 이 배포 조합은 지연 시간, 처리량, 운영 복잡성 사이의 기존 트레이드오프를 제거합니다.
지금 Novita AI에서 Nemotron Speech ASR 배포를 시작하세요. 유연한 초 단위 GPU 과금과 선불 약정이 없습니다.
Novita AI는 개발자가 AI 애플리케이션을 구축하고 확장할 수 있도록 사용하기 쉬운 API와 저렴하고 안정적인 GPU 인프라를 제공하는 선도적인 AI 클라우드 플랫폼입니다.



