

- Qu'est-ce que le NVIDIA Nemotron Speech ASR ?
- Qu'est-ce que le NVIDIA NeMo Framework ?
- Pourquoi déployer le Nemotron Speech ASR sur Novita AI ?
- Prérequis pour le déploiement
- Déployer le Nemotron Speech ASR : guide étape par étape
- Installer les dépendances du NeMo Framework
- Exécuter le modèle NVIDIA Nemotron Speech ASR
- Cas d'utilisation du Nemotron Speech ASR
- Conclusion
La reconnaissance vocale en temps réel exige plus que de la précision : elle nécessite une latence faible et constante sans gaspiller les cycles GPU.
Le modèle NVIDIA Nemotron Speech ASR résout les dérives de latence et les calculs redondants grâce à son architecture de streaming sensible au cache. Cela élimine le besoin d’inférence tamponnée, offrant une latence stable inférieure à 100 ms (délai médian de 24 ms jusqu’au premier jeton) et un débit jusqu’à 3 fois supérieur sur votre GPU.
Ce guide vous explique comment déployer le modèle NVIDIA Nemotron Speech ASR sur des instances GPU Novita AI en utilisant notre modèle préconfiguré. Créez des applications vocales de qualité production sans complexité d’infrastructure.
Qu’est-ce que le NVIDIA Nemotron Speech ASR ?
Le NVIDIA Nemotron Speech ASR est un modèle de reconnaissance automatique de la parole en streaming conçu pour les applications en temps réel avec une latence minimale.
Les systèmes ASR traditionnels reposent sur des blocs audio tamponnés, ce qui crée des dérives de latence et une utilisation inefficace du GPU. Le Nemotron Speech ASR utilise un streaming sensible au cache pour traiter l’audio en continu sans délais de tampon.
Spécifications du NVIDIA Nemotron Speech ASR :
- Architecture : ASR en streaming sensible au cache avec Conformer-CTC
- Performance de latence : traitement de bout en bout inférieur à 100 ms
- Délai jusqu’au premier jeton : latence médiane de 24 ms
- Amélioration du débit : jusqu’à 3 fois supérieur à l’inférence tamponnée
- Prise en charge des langues : anglais (variante à 0,6 milliard de paramètres)
- Taille du modèle : 600 millions de paramètres optimisés pour le streaming
Cette architecture de streaming sensible au cache élimine les dérives de latence et les calculs redondants, ce qui fait du NVIDIA Nemotron Speech ASR un modèle idéal pour la transcription en direct, les assistants vocaux, l’analyse des centres d’appels et les applications IA interactives.
Qu’est-ce que le NVIDIA NeMo Framework ?
Le NVIDIA NeMo Framework est un framework d’IA générative évolutif et natif du cloud, destiné aux chercheurs et aux développeurs PyTorch.
Le NeMo Framework prend en charge le développement dans plusieurs domaines de l’IA :
- Modèles de langage étendus (LLM)
- Modèles multimodaux (MM)
- Reconnaissance automatique de la parole (ASR)
- Synthèse vocale (TTS)
- Vision par ordinateur (CV)
Ce framework vous permet de créer, personnaliser et déployer des modèles d’IA générative efficacement en tirant parti du code existant et des points de contrôle de modèles pré-entraînés.
Le NVIDIA Nemotron Speech ASR est construit sur le NeMo Framework, offrant des capacités ASR prêtes pour la production avec une configuration minimale.
Pour la documentation technique complète, consultez le Guide utilisateur du NeMo Framework.
Pourquoi déployer le Nemotron Speech ASR sur Novita AI ?
Les instances GPU Novita AI offrent une infrastructure optimisée pour déployer le NVIDIA Nemotron Speech ASR à grande échelle :
Déploiement rapide : Lancez des instances GPU en quelques secondes avec des modèles NeMo préconfigurés. Aucune configuration manuelle de l’environnement n’est requise.
Tarification avantageuse : Facturation à la seconde sans contrats à long terme ni engagements minimums. Augmentez ou réduisez la capacité en fonction de la demande.
Modèles préconfigurés : Le NeMo Framework et ses dépendances sont préinstallés. Commencez à exécuter le Nemotron Speech ASR immédiatement.
Infrastructure mondiale : Accès GPU à faible latence dans plusieurs régions pour un déploiement mondial.
Outils pour développeurs : Surveillance en temps réel, accès SSH et déploiement simple de modèles depuis la bibliothèque Novita AI.
Que vous prototypiez un assistant vocal ou que vous dimensionniez un pipeline de transcription de production, Novita AI gère l’infrastructure GPU pour que vous puissiez vous concentrer sur la création d’applications ASR.
Prérequis pour le déploiement
Avant de déployer le NVIDIA Nemotron Speech ASR, assurez-vous de disposer de :
- Compte Novita AI avec suffisamment de crédits (inscrivez-vous ici)
- Fichiers audio de test au format WAV pour la validation du modèle
- Connaissances SSH de base pour l’accès et la configuration des instances
- Compréhension des exigences GPU pour votre charge de travail spécifique
Aucune expérience préalable du NeMo Framework n’est requise : le modèle Novita AI gère la configuration initiale.
Déployer le Nemotron Speech ASR : guide étape par étape
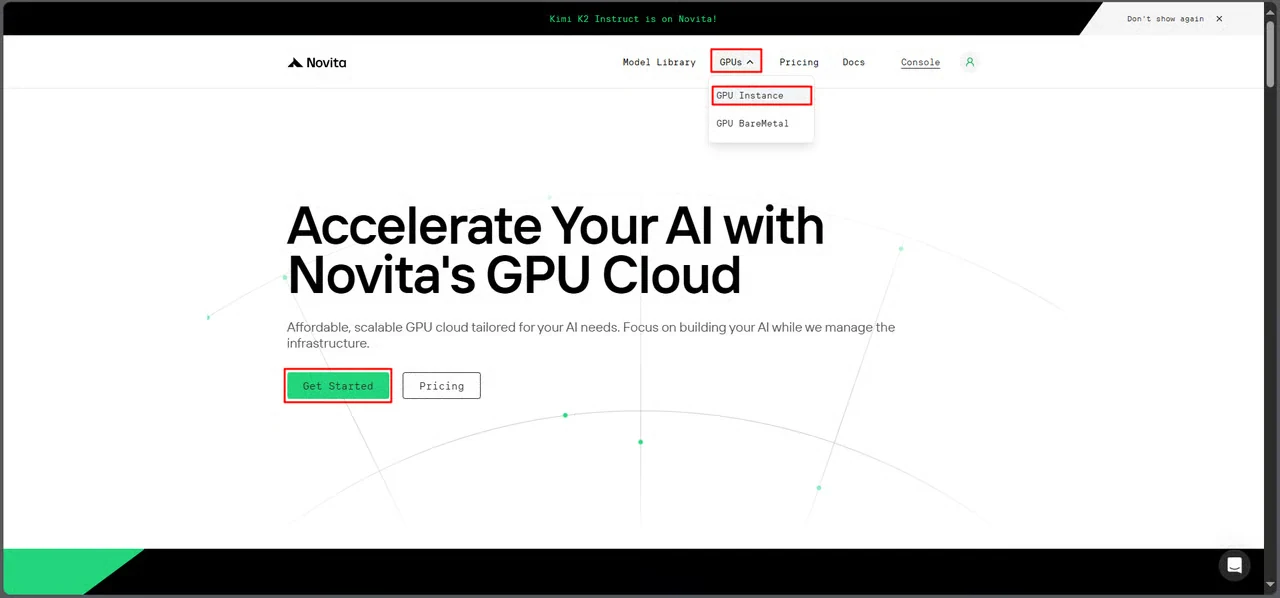
Étape 1 : Accéder à la console Novita AI
Connectez-vous à votre compte Novita AI et accédez à l’interface GPU.
Sélectionnez Commencer pour accéder au tableau de bord de gestion des déploiements.
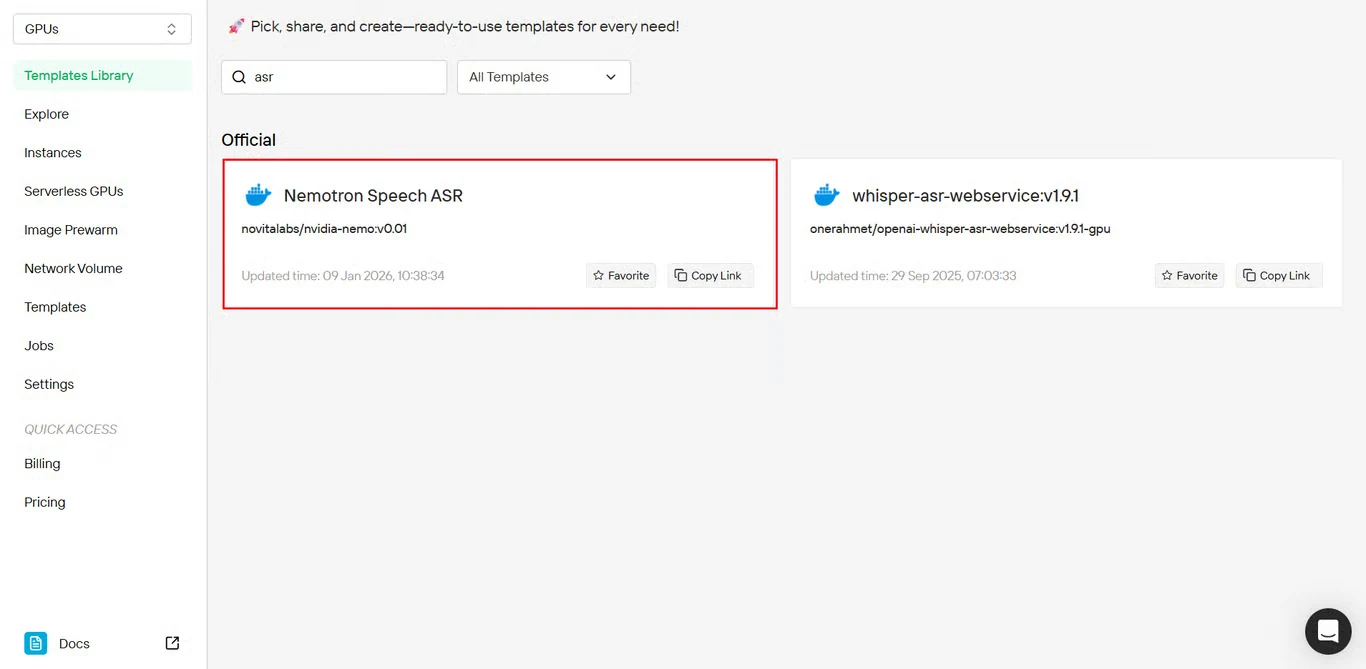
Étape 2 : Sélectionner le modèle Nemotron Speech ASR
Repérez Nemotron Speech ASR dans le référentiel de modèles et cliquez pour commencer l’installation.
Accès direct au modèle : https://novita.ai/templates-library/108969
Ce modèle inclut des paramètres NeMo Framework préconfigurés et des paramètres optimisés pour le déploiement du Nemotron Speech ASR.
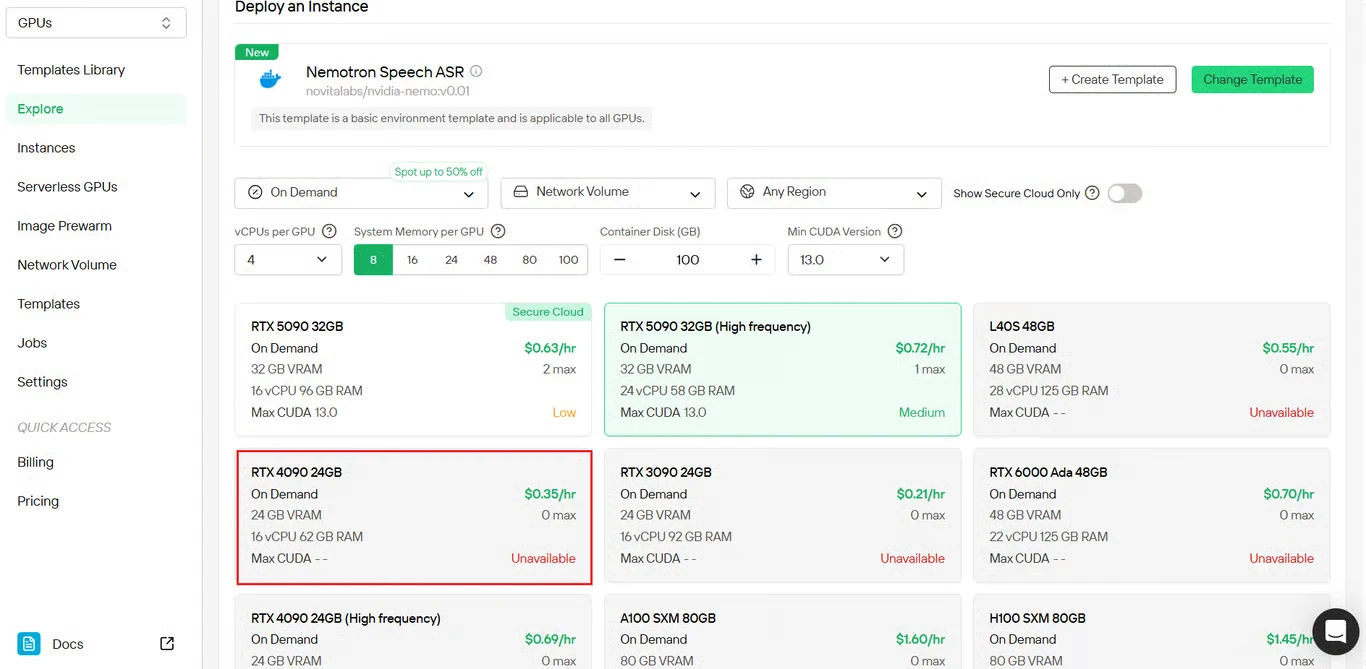
Étape 3 : Configurer les paramètres de l’instance GPU
Configurez les paramètres de votre instance GPU :
- Allocation de mémoire : basée sur le nombre de flux audio simultanés attendus
- Exigences de stockage : espace suffisant pour les fichiers de modèle et le traitement audio
- Paramètres réseau : configurez pour votre région géographique
- Sélection du GPU : choisissez en fonction des exigences de débit
Cliquez sur Déployer pour poursuivre avec votre configuration.
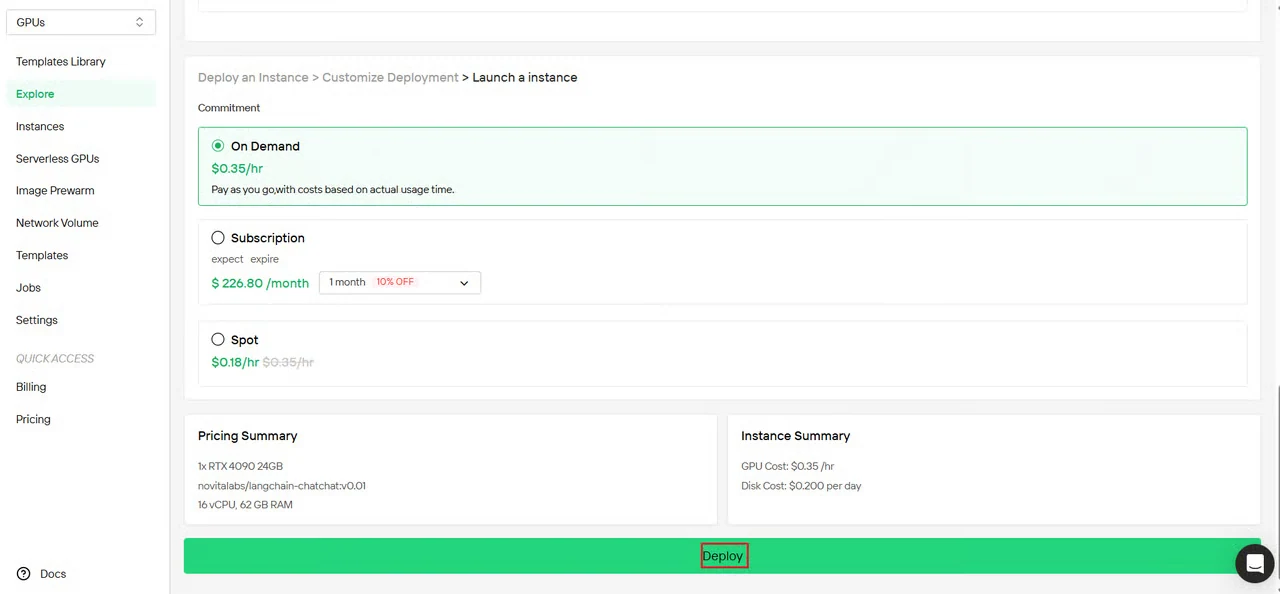
Étape 4 : Vérifier la configuration et déployer
Vérifiez le récapitulatif de la configuration de votre instance :
- Type et quantité de GPU
- Allocation de mémoire et de stockage
- Région réseau
- Coûts estimés
Vérifiez tous les paramètres et cliquez sur Déployer pour lancer la création de l’instance.
Étape 5 : Surveiller la création de l’instance
Après avoir lancé le déploiement, Novita AI vous redirige automatiquement vers la page de gestion des instances.
Votre instance Nemotron Speech ASR est créée en arrière-plan pendant que vous surveillez la progression.
Étape 6 : Suivre la progression du téléchargement
Surveillez le téléchargement de l’image NeMo Framework en temps réel.
Le statut de l’instance passe de Extraction à En cours d’exécution une fois le déploiement terminé.
Cliquez sur l’icône de flèche à côté du nom de votre instance pour obtenir des informations détaillées sur la progression.
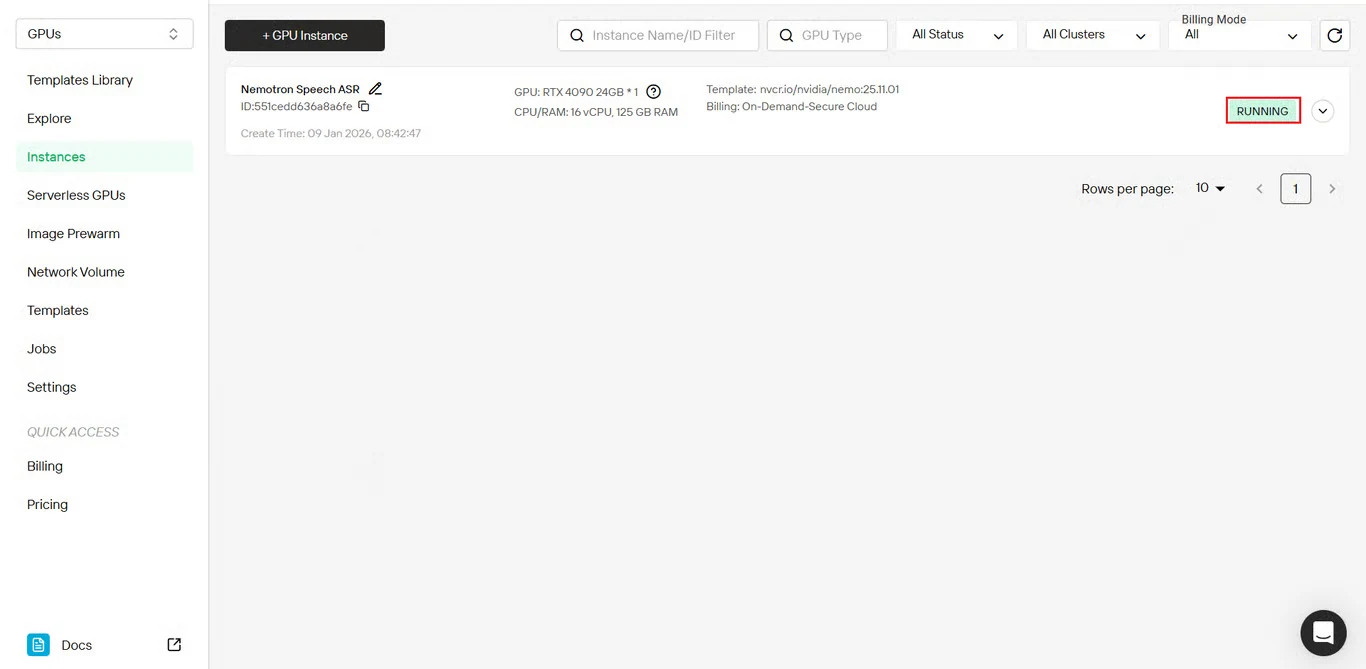
Étape 7 : Vérifier le statut du déploiement
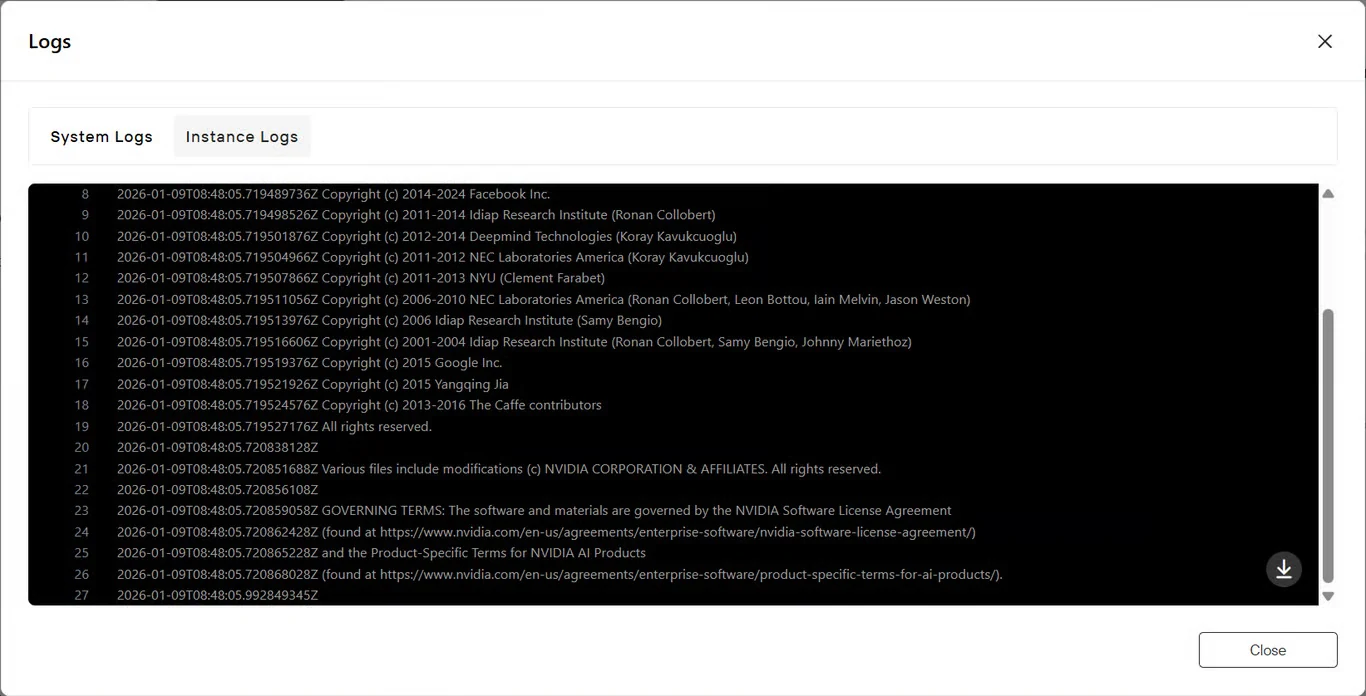
Cliquez sur le bouton Journaux pour consulter les journaux de démarrage de l’instance.
Vérifiez que les services NeMo se sont initialisés correctement et que le Nemotron Speech ASR est prêt pour l’inférence.
Installer les dépendances du NeMo Framework
Une fois votre instance GPU en cours d’exécution, connectez-vous via SSH pour installer les dépendances requises.
Installer les dépendances système et le toolkit NeMo
Exécutez les commandes suivantes pour configurer votre environnement :
apt-get update && apt-get install -y libsndfile1 ffmpeg
pip install Cython packaging
pip install git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]
Décomposition des dépendances :
- libsndfile1 : bibliothèque d’E/S de fichiers audio pour le traitement WAV
- ffmpeg : framework multimédia pour la conversion audio
- Cython : optimisation des performances pour le code Python
- nemo_toolkit[asr] : NeMo Framework avec des modules spécifiques à l’ASR
L’installation prend entre 5 et 10 minutes selon la vitesse du réseau.
Exécuter le modèle NVIDIA Nemotron Speech ASR
Télécharger le modèle Nemotron Speech ASR
Téléchargez le NVIDIA Nemotron Speech ASR depuis le dépôt Hugging Face officiel.
Le format du fichier du modèle est .nemo et contient tous les paramètres nécessaires à l’inférence.
Utiliser le script d’inférence NeMo officiel
Le NeMo Framework fournit un script d’inférence optimisé pour l’ASR en streaming sensible au cache.
Script de référence : speech_to_text_cache_aware_streaming_infer.py
Exécuter l’inférence du Nemotron Speech ASR
Exécutez la commande suivante pour transcrire l’audio :
python speech_to_text_cache_aware_streaming_infer.py \
model_path=/yourPath/nemotron-speech-streaming-en-0.6b/nemotron-speech-streaming-en-0.6b.nemo \
audio_file=/yourPath/audio.wav
Paramètres d’inférence
Configurez ces paramètres pour votre déploiement :
- model_path : chemin complet vers le fichier de modèle
.nemodu Nemotron Speech ASR - audio_file : chemin vers le fichier audio d’entrée (format WAV recommandé)
Exemple de sortie de transcription
Une inférence réussie produit une sortie similaire à :
[NeMo I 2026-01-09 08:13:32 speech_to_text_cache_aware_streaming_infer:282] Final streaming transcriptions: ['The English forwarded to the French baskets of flowers of which they had made a plentiful provision to greet the arrival of the young princess. The French, in return, invited the English to a supper, which was to be given the next day.']
Cela confirme que le Nemotron Speech ASR a converti avec succès le flux audio en texte grâce à son architecture de streaming sensible au cache.
Cas d’utilisation du Nemotron Speech ASR
Transcription en direct en temps réel
Déployez le NVIDIA Nemotron Speech ASR pour des systèmes de sous-titrage en direct lors de réunions, de webinaires et de diffusions.
La latence inférieure à 100 ms garantit que les sous-titres apparaissent en temps réel sans délais perceptibles.
Applications d’assistants vocaux
Créez des agents IA conversationnels avec une reconnaissance vocale instantanée pour des interactions utilisateur naturelles.
Le streaming sensible au cache élimine les délais de tampon pour des commandes vocales réactives.
Analyse et surveillance des centres d’appels
Transcrivez les appels clients en temps réel pour l’analyse des sentiments, la surveillance de la conformité et l’assistance aux agents.
Le débit élevé (amélioration de 3x) permet le traitement d’appels simultanés sans ressources GPU supplémentaires.
Solutions d’accessibilité
Créez des technologies d’assistance pour les utilisateurs malentendants nécessitant des sous-titres en direct à faible latence.
Les performances de latence stables garantissent une accessibilité cohérente quelles que soient les conditions audio.
Production médiatique et création de contenu
Automatisez la génération de sous-titres pour les podcasts, les vidéos et les flux en direct avec une transcription anglaise de haute précision.
L’architecture de streaming traite efficacement le contenu de longue durée sans contraintes de mémoire.
Conclusion
Le déploiement du NVIDIA Nemotron Speech ASR sur des instances GPU Novita AI fournit une infrastructure de reconnaissance vocale prête pour la production en quelques minutes, et non en plusieurs heures.
L’architecture de streaming sensible au cache du modèle offre la latence stable inférieure à 100 ms et l’amélioration de l’efficacité GPU de 3x que demandent vos applications en temps réel. Le modèle préconfiguré de Novita AI élimine la configuration complexe du NeMo Framework, vous permettant de vous concentrer sur la création d’applications vocales au lieu de gérer l’infrastructure.
Que vous développiez des assistants vocaux, des services de transcription, des outils d’analyse de centres d’appels ou des solutions d’accessibilité, cette combinaison de déploiement élimine les compromis traditionnels entre latence, débit et complexité opérationnelle.
Commencez à déployer le Nemotron Speech ASR sur Novita AI dès aujourd’hui avec une tarification GPU flexible à la seconde et sans engagement initial.
Novita AI est une plateforme cloud IA leader qui fournit aux développeurs des API faciles à utiliser et une infrastructure GPU abordable et fiable pour créer et dimensionner des applications IA.



