

リアルタイム音声認識には、精度だけでなく、一貫した低レイテンシとGPUサイクルの効率的な利用が求められます。
NVIDIA Nemotron Speech ASRモデルは、キャッシュ対応ストリーミングアーキテクチャにより、レイテンシのドリフトと冗長な計算を解決します。これによりバッファリング推論が不要になり、安定したサブ100msレイテンシ(最初のトークンまでの中央値24ms)と、GPU上での最大3倍のスループットを実現します。
このガイドでは、事前設定済みテンプレートを使用してNVIDIA Nemotron Speech ASRをNovita AI GPUインスタンスにデプロイする方法を説明します。インフラの複雑さを気にせずに、本番環境対応の音声アプリケーションを構築できます。
NVIDIA Nemotron Speech ASRとは?
NVIDIA Nemotron Speech ASRは、リアルタイムアプリケーション向けに設計された、最小レイテンシのストリーミング自動音声認識モデルです。
従来のASRシステムはバッファリングされた音声チャンクに依存しており、レイテンシのドリフトや非効率的なGPU使用が発生します。Nemotron Speech ASRはキャッシュ対応ストリーミングを使用して、バッファリングによる遅延なしに音声を連続的に処理します。
NVIDIA Nemotron Speech ASRの仕様:
- アーキテクチャ: Conformer-CTCによるキャッシュ対応ストリーミングASR
- レイテンシ性能: エンドツーエンドでサブ100ms
- 最初のトークンまでの時間: 中央値24ms
- スループット向上: バッファリング推論と比較して最大3倍
- 対応言語: 英語(0.6Bパラメータバリアント)
- モデルサイズ: ストリーミングに最適化された600Mパラメータ
キャッシュ対応ストリーミングアーキテクチャがレイテンシのドリフトと冗長な計算を排除するため、NVIDIA Nemotron Speech ASRはライブ文字起こし、音声アシスタント、コンタクトセンター分析、インタラクティブAIアプリケーションに最適です。
NVIDIA NeMo Frameworkとは?
NVIDIA NeMo Frameworkは、研究者やPyTorch開発者向けの、スケーラブルでクラウドネイティブな生成AIフレームワークです。
NeMo Frameworkは、以下の複数のAIドメインにわたる開発をサポートします。
- 大規模言語モデル(LLM)
- マルチモーダルモデル(MM)
- 自動音声認識(ASR)
- テキスト読み上げ(TTS)
- コンピュータビジョン(CV)
このフレームワークは、既存のコードと事前学習済みモデルチェックポイントを活用することで、生成AIモデルを効率的に作成、カスタマイズ、デプロイするのに役立ちます。
NVIDIA Nemotron Speech ASRはNeMo Framework上に構築されており、最小限のセットアップで本番環境対応のASR機能を提供します。
詳細なテクニカルドキュメントについては、NeMo Frameworkユーザーガイドを参照してください。
Nemotron Speech ASRをNovita AIでデプロイする理由
Novita AI GPUインスタンスは、NVIDIA Nemotron Speech ASRを大規模にデプロイするための最適化されたインフラを提供します。
高速デプロイ: 事前設定済みのNeMoテンプレートを使用して、数秒でGPUインスタンスを起動。手動での環境構築は不要です。
コスト効率の高い料金: 秒単位の課金で、長期契約や最低利用額は不要。需要に応じてスケールアップ/ダウンが可能です。
事前設定済みテンプレート: NeMo Frameworkと依存関係がプリインストールされています。すぐにNemotron Speech ASRを実行できます。
グローバルインフラ: 複数のリージョンで低レイテンシのGPUアクセスを実現し、世界中にデプロイ可能。
開発者ツール: リアルタイム監視、SSHアクセス、Novita AIライブラリからのテンプレートデプロイが簡単に行えます。
音声アシスタントのプロトタイプ作成から、本番用文字起こしパイプラインのスケーリングまで、Novita AIがGPUインフラを管理するため、ASRアプリケーションの構築に集中できます。
デプロイの前提条件
NVIDIA Nemotron Speech ASRをデプロイする前に、以下を準備してください。
- Novita AIアカウント(十分なクレジットがあること)— こちらからサインアップ
- テスト用音声ファイル(WAV形式、モデル検証用)
- SSHの基本的な知識(インスタンスへのアクセスと設定用)
- ワークロードに応じたGPU要件の理解
NeMo Frameworkの経験は不要です。Novita AIテンプレートが初期セットアップを処理します。
Nemotron Speech ASRのデプロイ:ステップバイステップガイド
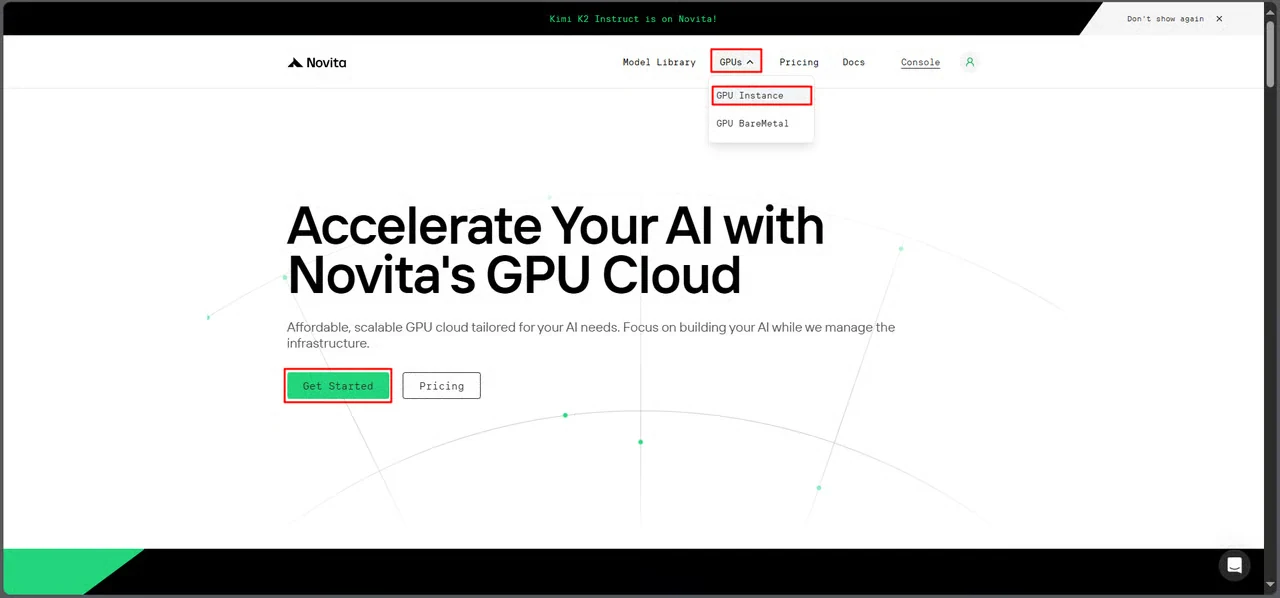
ステップ1:Novita AIコンソールにアクセス
Novita AIアカウントにログインし、GPUインターフェースに移動します。
はじめる を選択して、デプロイ管理ダッシュボードにアクセスします。
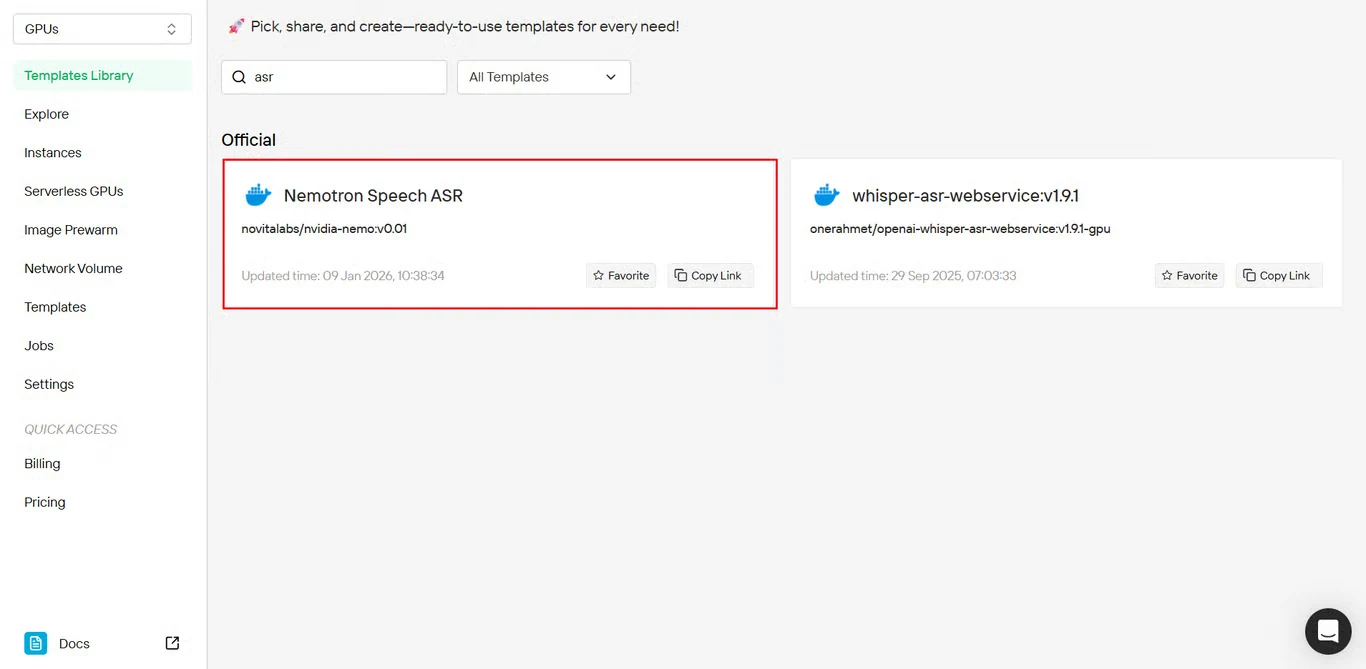
ステップ2:Nemotron Speech ASRテンプレートを選択
テンプレートリポジトリで Nemotron Speech ASR を見つけ、クリックしてインストールを開始します。
テンプレートへの直接リンク:https://novita.ai/templates-library/108969
このテンプレートには、事前設定されたNeMo Framework設定とNemotron Speech ASRデプロイ用の最適化パラメータが含まれています。
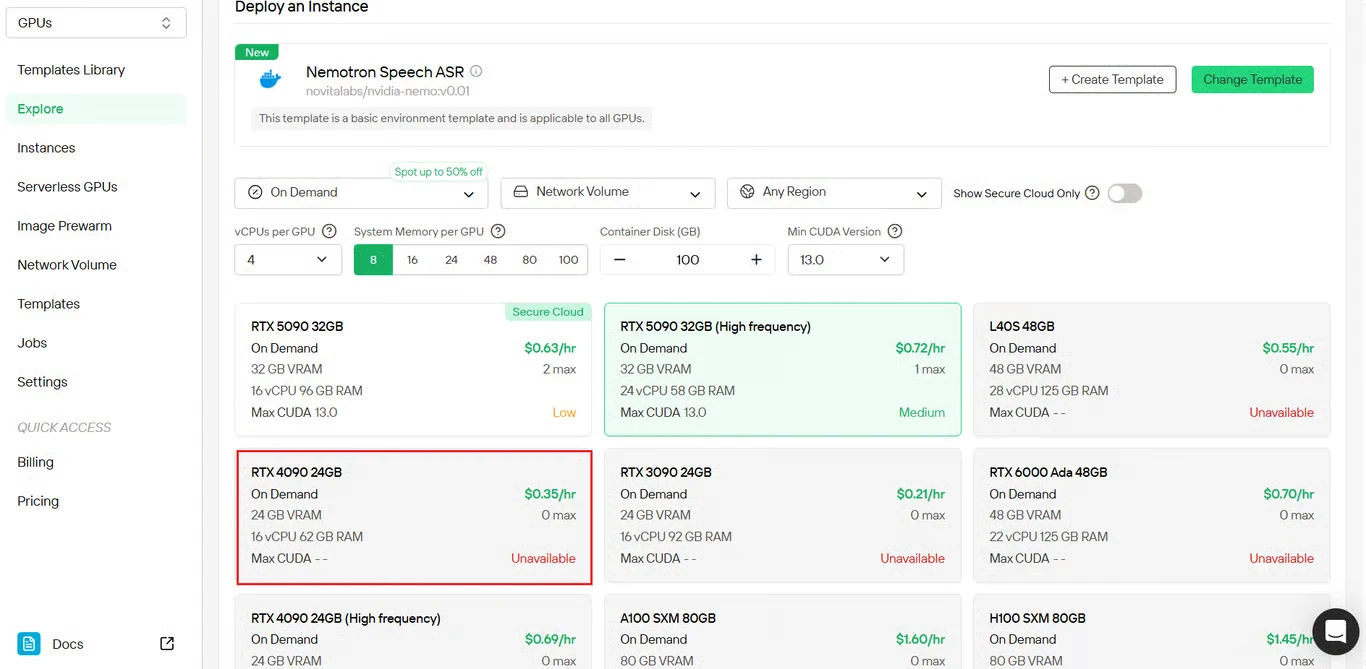
ステップ3:GPUインスタンス設定を構成
GPUインスタンスのパラメータを設定します。
- メモリ割り当て: 予想される同時音声ストリーム数に基づく
- ストレージ要件: モデルファイルと音声処理に十分な容量
- ネットワーク設定: 地理的リージョンに合わせて設定
- GPU選択: スループット要件に基づいて選択
デプロイ をクリックして、設定を確定します。
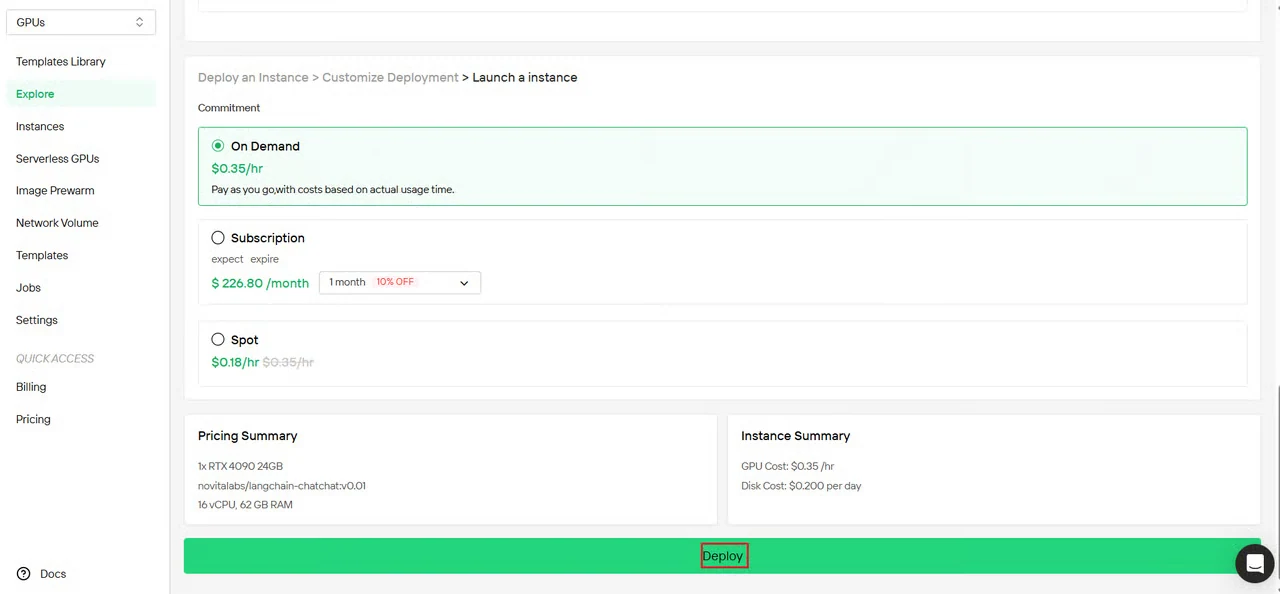
ステップ4:設定を確認してデプロイ
インスタンス設定の概要を確認します。
- GPUタイプと数
- メモリとストレージの割り当て
- ネットワークリージョン
- 推定コスト
すべての設定を確認し、デプロイ をクリックしてインスタンス作成を開始します。
ステップ5:インスタンス作成の監視
デプロイを開始すると、Novita AIは自動的にインスタンス管理ページにリダイレクトします。
Nemotron Speech ASRインスタンスはバックグラウンドで作成され、進行状況を監視できます。
ステップ6:ダウンロード進捗の追跡
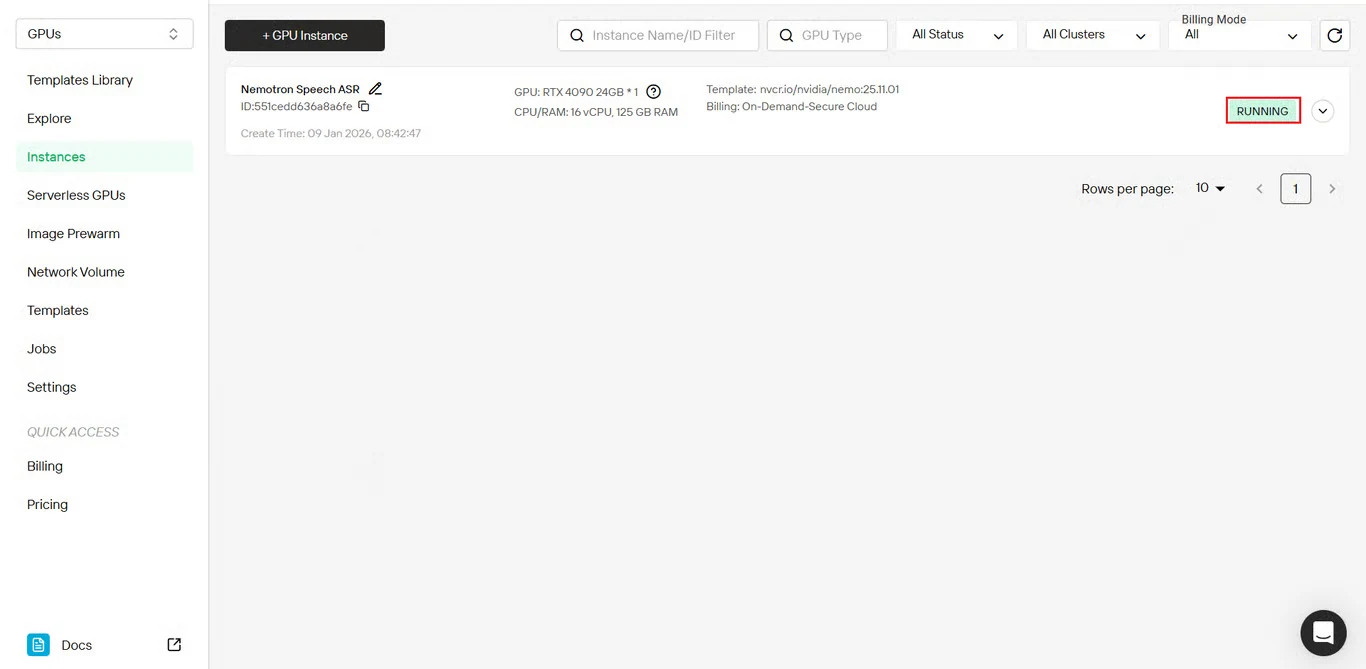
NeMo Frameworkイメージのダウンロードをリアルタイムで監視します。
インスタンスステータスが Pulling から Running に変わると、デプロイ完了です。
インスタンス名の横にある矢印アイコンをクリックすると、詳細な進捗情報が表示されます。
ステップ7:デプロイ状態の確認
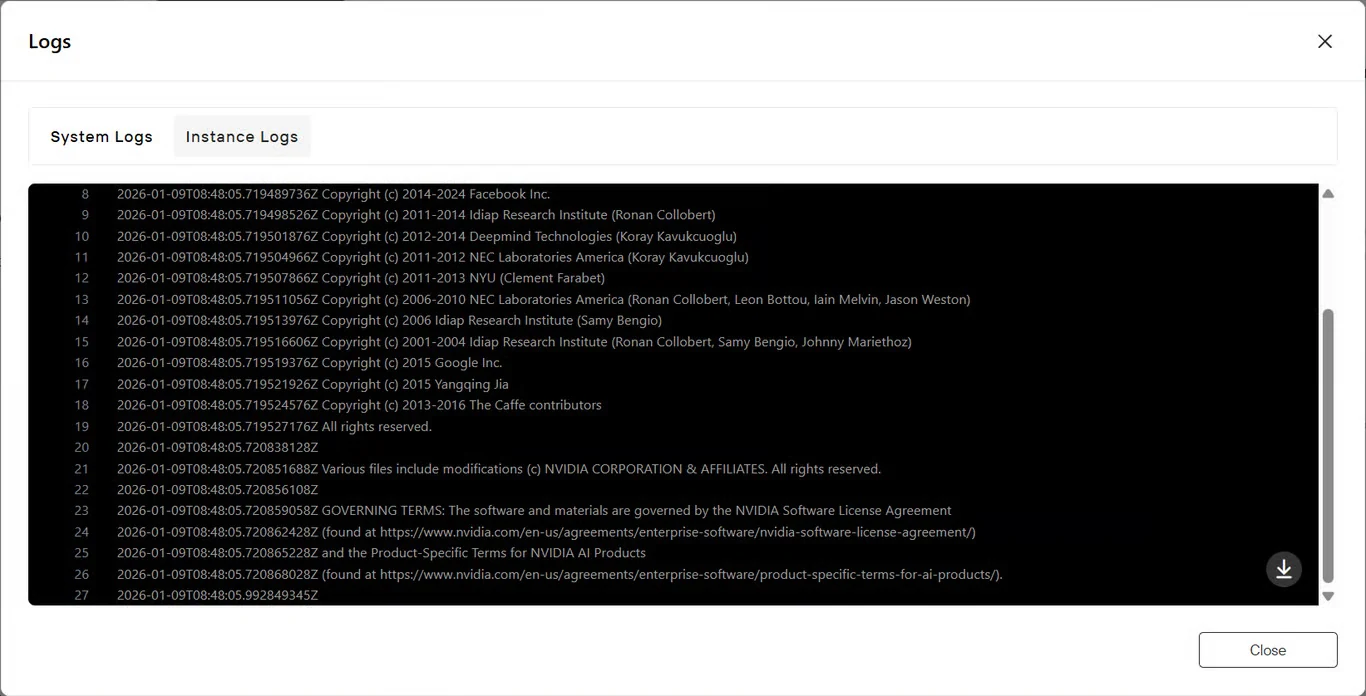
ログ ボタンをクリックして、インスタンス起動ログを表示します。
NeMoサービスが正しく初期化され、Nemotron Speech ASRが推論可能な状態であることを確認します。
NeMo Framework依存関係のインストール
GPUインスタンスが起動したら、SSH経由で接続し、必要な依存関係をインストールします。
システム依存関係とNeMoツールキットのインストール
以下のコマンドを実行して環境をセットアップします。
bash
apt-get update && apt-get install -y libsndfile1 ffmpeg
pip install Cython packaging
pip install git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]
依存関係の説明:
- libsndfile1: WAV処理用のオーディオファイルI/Oライブラリ
- ffmpeg: オーディオ変換用マルチメディアフレームワーク
- Cython: Pythonコードのパフォーマンス最適化
- nemo_toolkit[asr]: ASR固有モジュールを含むNeMo Framework
インストールはネットワーク速度にもよりますが、5〜10分で完了します。
NVIDIA Nemotron Speech ASRモデルの実行
Nemotron Speech ASRモデルのダウンロード
公式のHugging FaceリポジトリからNVIDIA Nemotron Speech ASRをダウンロードします。
モデルファイル形式は.nemoで、推論に必要なすべてのパラメータが含まれています。
公式NeMo推論スクリプトの使用
NeMo Frameworkは、キャッシュ対応ストリーミングASR用に最適化された推論スクリプトを提供しています。
リファレンススクリプト: speech_to_text_cache_aware_streaming_infer.py
Nemotron Speech ASR推論の実行
以下のコマンドを実行して音声を文字起こしします。
bash
python speech_to_text_cache_aware_streaming_infer.py \
model_path=/yourPath/nemotron-speech-streaming-en-0.6b/nemotron-speech-streaming-en-0.6b.nemo \
audio_file=/yourPath/audio.wav
推論パラメータ
デプロイに応じて以下のパラメータを設定します。
- model_path: Nemotron Speech ASRの
.nemoモデルファイルへのフルパス - audio_file: 入力音声ファイルのパス(WAV形式推奨)
推論出力例
成功した推論では、以下のような出力が得られます。
bash
[NeMo I 2026-01-09 08:13:32 speech_to_text_cache_aware_streaming_infer:282] Final streaming transcriptions: ['The English forwarded to the French baskets of flowers of which they had made a plentiful provision to greet the arrival of the young princess. The French, in return, invited the English to a supper, which was to be given the next day.']
これにより、Nemotron Speech ASRがキャッシュ対応ストリーミングアーキテクチャを使用して、音声ストリームをテキストに正常に変換したことが確認できます。
Nemotron Speech ASRのユースケース
リアルタイムライブ文字起こし
NVIDIA Nemotron Speech ASRを会議、ウェビナー、放送向けのライブキャプションシステムにデプロイ。
サブ100msのレイテンシにより、キャプションが目立った遅延なくリアルタイムに表示されます。
音声アシスタントアプリケーション
インスタントな音声認識を備えた対話型AIエージェントを構築し、自然なユーザーインタラクションを実現。
キャッシュ対応ストリーミングがバッファリングによる遅延を排除し、応答性の高い音声コマンドを提供します。
コンタクトセンター分析とモニタリング
顧客との通話をリアルタイムで文字起こしし、感情分析、コンプライアンス監視、エージェント支援に活用。
高いスループット(3倍改善)により、追加GPUリソースなしで同時通話処理が可能。
アクセシビリティソリューション
低レイテンシのライブキャプションを必要とする聴覚障害者向けの支援技術を構築。
安定したレイテンシ性能により、さまざまな音声条件下でも一貫したアクセシビリティを実現。
メディア制作とコンテンツ作成
高精度な英語文字起こしで、ポッドキャスト、動画、ライブストリームの字幕生成を自動化。
ストリーミングアーキテクチャにより、メモリ制約なく長尺コンテンツを効率的に処理。
まとめ
NVIDIA Nemotron Speech ASRをNovita AI GPUインスタンスにデプロイすることで、数時間ではなく数分で本番環境対応の音声認識インフラを構築できます。
このモデルのキャッシュ対応ストリーミングアーキテクチャは、リアルタイムアプリケーションに求められる安定したサブ100msレイテンシと3倍のGPU効率向上を実現します。Novita AIの事前設定済みテンプレートは複雑なNeMo Frameworkセットアップを排除し、インフラ管理ではなく音声アプリケーションの構築に集中できます。
音声アシスタント、文字起こしサービス、コンタクトセンター分析、アクセシビリティツールのいずれを開発している場合でも、このデプロイの組み合わせにより、レイテンシ、スループット、運用の複雑さの間の従来のトレードオフが解消されます。
今すぐNovita AIでNemotron Speech ASRのデプロイを開始しましょう。柔軟な秒単位のGPU課金で、初期コミットメントは不要です。
Novita AIは、開発者がAIアプリケーションを構築・スケーリングするための、使いやすいAPIと手頃な価格で信頼性の高いGPUインフラを提供する主要なAIクラウドプラットフォームです。



