

即時語音辨識不僅要求準確度,還需要穩定的低延遲,同時不會過度消耗 GPU 資源。
NVIDIA Nemotron Speech ASR 模型透過快取感知串流架構,解決了延遲漂移和冗餘計算問題。此設計無需緩衝推論,即可提供穩定的低於 100ms 延遲(中位數首 Token 時間僅 24ms),並能在你的 GPU 上實現最高 3 倍的吞吐量提升。
本指南將教你如何使用我們的預配置模板在 Novita AI GPU 實例上部署 NVIDIA Nemotron Speech ASR,無需處理基礎設施複雜度,即可構建生產級語音應用程式。
什麼是 NVIDIA Nemotron Speech ASR?
NVIDIA Nemotron Speech ASR 是一款專為低延遲即時應用設計的串流自動語音辨識(ASR)模型。
傳統 ASR 系統依賴緩衝的音訊區塊,會產生延遲漂移且 GPU 使用效率低下。Nemotron Speech ASR 採用快取感知串流技術,可連續處理音訊,無需緩衝延遲。
NVIDIA Nemotron Speech ASR 規格:
- 架構: 採用 Conformer-CTC 的快取感知串流 ASR
- 延遲效能: 端對端處理低於 100ms
- 首 Token 時間: 中位數延遲僅 24ms
- 吞吐量提升: 相較於緩衝推論最高提升 3 倍
- 語言支援: 英語(0.6B 參數版本)
- 模型大小: 600M 參數,針對串流場景優化
快取感知串流架構消除了延遲漂移和冗餘計算,使 NVIDIA Nemotron Speech ASR 非常適合即時轉寫、語音助手、客服中心分析和互動式 AI 應用程式。
什麼是 NVIDIA NeMo Framework?
NVIDIA NeMo Framework 是一個可擴展、雲原生的生成式 AI 框架,專為研究人員和 PyTorch 開發人員設計。
NeMo Framework 支援多個 AI 領域的開發:
- 大型語言模型(LLMs)
- 多模態模型(MMs)
- 自動語音辨識(ASR)
- 文字轉語音(TTS)
- 電腦視覺(CV)
該框架可協助你透過利用現有程式碼和預訓練模型檢查點,高效地建立、自訂和部署生成式 AI 模型。
NVIDIA Nemotron Speech ASR 建構於 NeMo Framework 之上,只需極少設定即可提供生產級 ASR 能力。完整技術文件請參閱NeMo Framework 使用者指南。
為什麼要在 Novita AI 上部署 Nemotron Speech ASR?
Novita AI GPU 實例提供優化基礎設施,可大規模部署 NVIDIA Nemotron Speech ASR:
快速部署: 使用預配置的 NeMo 模板,數秒內即可啟動 GPU 實例,無需手動環境設定。
高性價比定價: 按秒計費,無長期合約或最低承諾,可根據需求彈性擴展或縮減。
預配置模板: 預先安裝 NeMo Framework 及所有依賴項,可立即開始執行 Nemotron Speech ASR。
全球基礎設施: 在多個區域提供低延遲 GPU 存取,支援全球部署。
開發者工具: 提供即時監控、SSH 存取,以及從 Novita AI 模板庫一鍵部署的功能。
無論你是正在原型開發語音助手,還是擴展生產級轉寫流程,Novita AI 都會處理 GPU 基礎設施,讓你能專注於構建 ASR 應用程式。
部署前準備條件
部署 NVIDIA Nemotron Speech ASR 前,請確保你已準備好以下項目:
- 擁有足夠額度的 Novita AI 帳號(點此註冊)
- 用於模型驗證的 WAV 格式音訊測試檔案
- 具備基礎 SSH 知識,用於實例存取和設定
- 了解特定工作負載的 GPU 需求
無需具備 NeMo Framework 使用經驗——Novita AI 模板會處理初始設定。
部署 Nemotron Speech ASR:逐步指南
步驟 1:存取 Novita AI 控制台
登入你的 Novita AI 帳號,導航至GPU 介面。
選擇開始使用以存取部署管理儀表板。
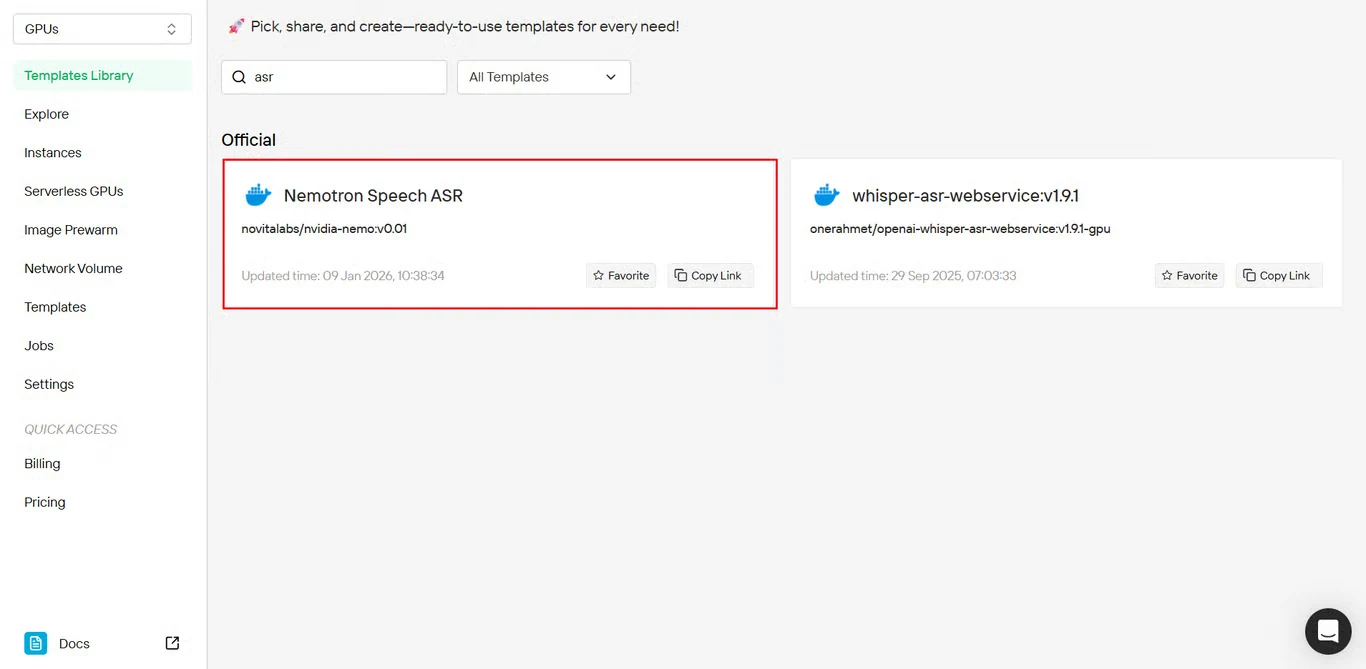
步驟 2:選擇 Nemotron Speech ASR 模板
在模板庫中找到 Nemotron Speech ASR,點擊開始安裝。
直接模板存取連結:https://novita.ai/templates-library/108969
該模板包含預配置的 NeMo Framework 設定,以及針對 Nemotron Speech ASR 部署優化的參數。
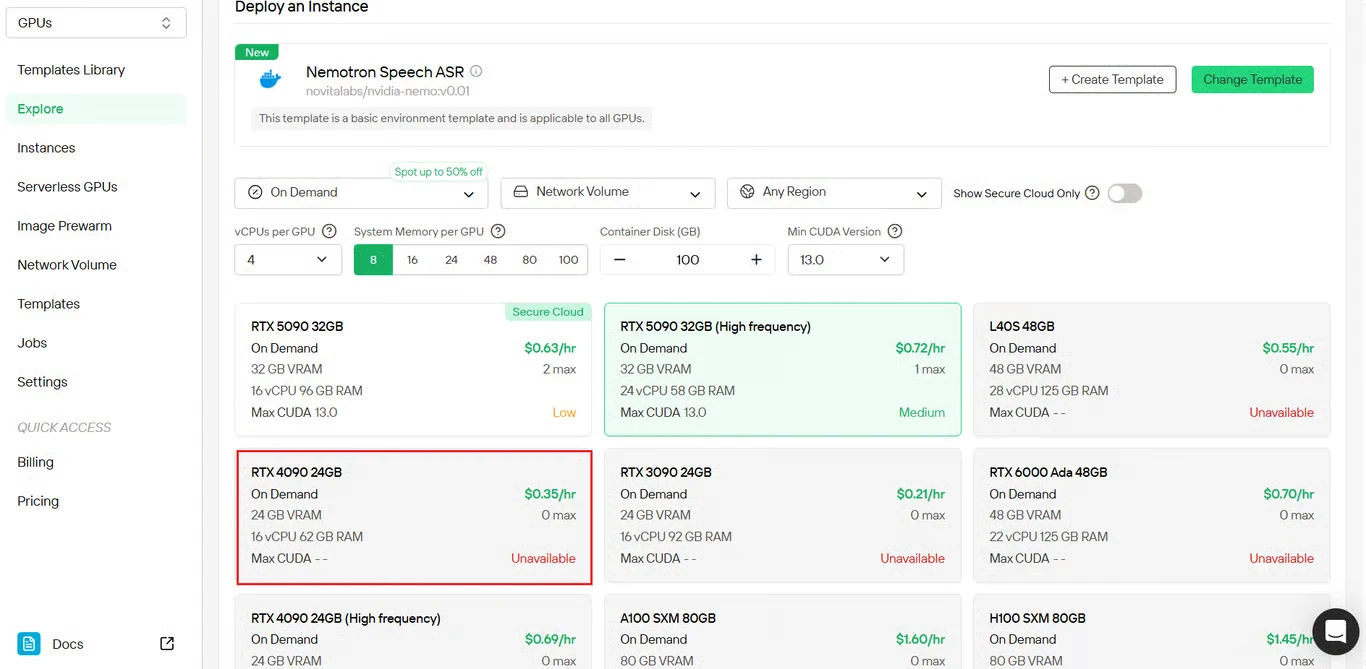
步驟 3:設定 GPU 實例參數
配置你的 GPU 實例參數:
- 記憶體分配: 根據預期的並發音訊串流數量調整
- 儲存需求: 確保有足夠空間儲存模型檔案和音訊處理資料
- 網路設定: 根據你的地理區域配置
- GPU 選擇: 根據吞吐量需求選擇合適的 GPU 型號
點擊部署繼續下一步配置。
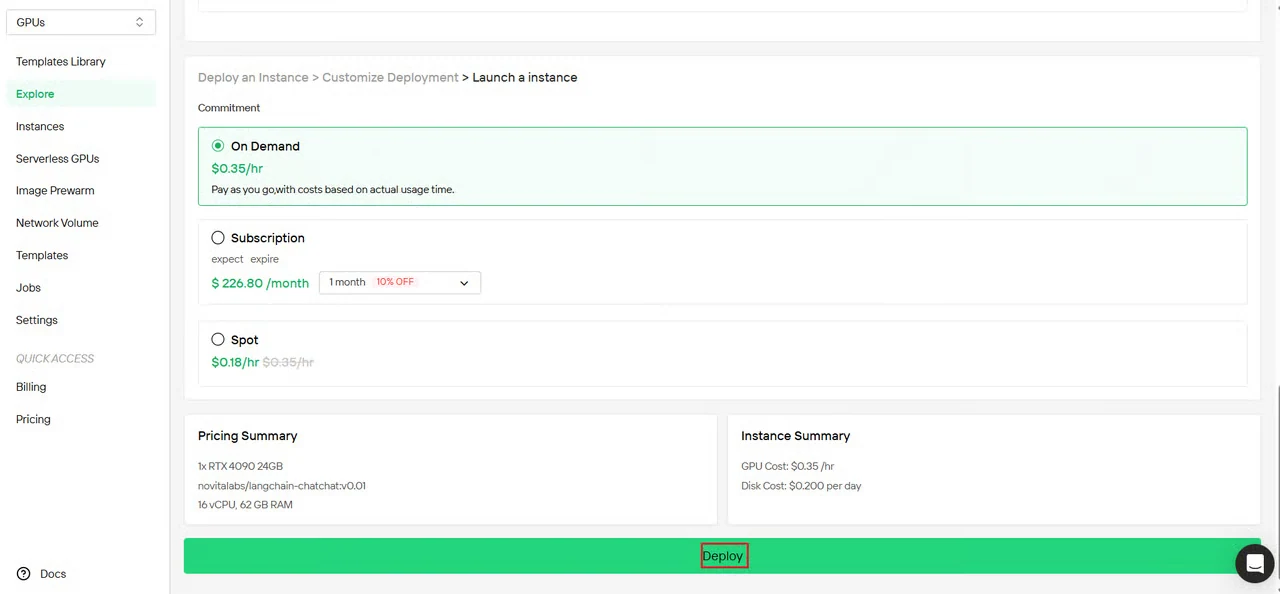
步驟 4:審核配置並部署
審核你的實例配置摘要:
- GPU 類型和數量
- 記憶體和儲存分配
- 網路區域
- 預估成本
確認所有設定無誤後,點擊部署開始建立實例。
步驟 5:監控實例建立進度
啟動部署後,Novita AI 會自動將你重新導向至實例管理頁面。
你的 Nemotron Speech ASR 實例會在背景建立,你可以隨時監控進度。
步驟 6:追蹤下載進度
即時監控 NeMo Framework 映像檔的下載進度。
實例狀態會從拉取中更新為執行中,代表部署完成。
點擊實例名稱旁的箭頭圖示可查看詳細進度資訊。
步驟 7:驗證部署狀態
點擊日誌按鈕查看實例啟動日誌。
確認 NeMo 服務已正確初始化,且 Nemotron Speech ASR 已準備好進行推論。
安裝 NeMo Framework 依賴項
你的 GPU 實例執行後,透過 SSH 連線安裝所需依賴項。
安裝系統依賴項和 NeMo 工具包
執行以下命令設定你的環境:
bash
apt-get update && apt-get install -y libsndfile1 ffmpeg
pip install Cython packaging
pip install git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]
依賴項說明:
- libsndfile1: 用於 WAV 處理的音訊檔案 I/O 函式庫
- ffmpeg: 用於音訊轉換的多媒體框架
- Cython: 用於 Python 程式碼效能優化
- nemo_toolkit[asr]: 內建 ASR 專用模組的 NeMo Framework
安裝時間約 5-10 分鐘,取決於網路速度。
執行 NVIDIA Nemotron Speech ASR 模型
下載 Nemotron Speech ASR 模型
從官方Hugging Face 儲存庫下載 NVIDIA Nemotron Speech ASR。
模型檔案格式為 .nemo,包含推論所需的所有參數。
使用官方 NeMo 推論腳本
NeMo Framework 提供了針對快取感知串流 ASR 優化的推論腳本。
參考腳本:speech_to_text_cache_aware_streaming_infer.py
執行 Nemotron Speech ASR 推論
執行以下命令轉寫音訊:
bash
python speech_to_text_cache_aware_streaming_infer.py \
model_path=/yourPath/nemotron-speech-streaming-en-0.6b/nemotron-speech-streaming-en-0.6b.nemo \
audio_file=/yourPath/audio.wav
推論參數
配置這些參數以符合你的部署需求:
- model_path: Nemotron Speech ASR
.nemo模型檔案的完整路徑 - audio_file: 輸入音訊檔案的路徑(建議使用 WAV 格式)
範例轉寫輸出
成功推論會產生類似以下的輸出:
bash
[NeMo I 2026-01-09 08:13:32 speech_to_text_cache_aware_streaming_infer:282] Final streaming transcriptions: ['The English forwarded to the French baskets of flowers of which they had made a plentiful provision to greet the arrival of the young princess. The French, in return, invited the English to a supper, which was to be given the next day.']
這確認 Nemotron Speech ASR 已透過快取感知串流架構成功將音訊串流轉換為文字。
Nemotron Speech ASR 應用場景
即時現場轉寫
部署 NVIDIA Nemotron Speech ASR 用於會議、網路研討會和廣播的即時字幕系統。
低於 100ms 的延遲確保字幕即時呈現,無明顯延遲。
語音助手應用程式
構建具備即時語音辨識能力的對話式 AI 代理,實現自然的使用者互動。
快取感知串流消除了緩衝延遲,讓語音指令回覆更靈敏。
客服中心分析與監控
即時轉寫客戶通話,用於情感分析、合規監控和客服輔助。
高吞吐量(3 倍提升)支援並發通話處理,無需額外 GPU 資源。
無障礙解決方案
為聽障使用者建立輔助科技,需要低延遲的即時字幕。
穩定的延遲效能確保在不同音訊條件下都能提供一致的無障礙體驗。
媒體製作與內容創作
為播客、影片和直播自動生成高準確度的英語字幕,串流架構可高效處理長篇內容,無記憶體限制。
結論
在 Novita AI GPU 實例上部署 NVIDIA Nemotron Speech ASR,可在數分鐘內(而非數小時)提供生產級語音辨識基礎設施。該模型的快取感知串流架構能提供穩定的低於 100ms 延遲和 3 倍的 GPU 效率提升,滿足即時應用的需求。Novita AI 的預配置模板消除了複雜的 NeMo Framework 設定,讓你能專注於構建語音應用程式,而非管理基礎設施。
無論你是開發語音助手、轉寫服務、客服中心分析還是無障礙工具,這套部署組合都消除了延遲、吞吐量和運營複雜度之間的傳統取捨。今天就在 Novita AI 上開始部署 Nemotron Speech ASR,享受彈性的按秒計費 GPU 定價,無需前期承諾。
Novita AI 是領先的 AI 雲端平台,為開發者提供易於使用的 API 和實惠、可靠的 GPU 基礎設施,用於構建和擴展 AI 應用程式。



