

实时语音识别不仅仅需要准确度——还需要在不大幅消耗 GPU 计算资源的前提下保持稳定的低延迟。
NVIDIA Nemotron Speech ASR 模型凭借其缓存感知流式处理架构,解决了延迟漂移和冗余计算问题。它消除了对缓冲推理的需求,提供稳定且低于 100ms 的延迟(中位首词生成时间 24ms),并能在 GPU 上实现高达 3 倍的吞吐量提升。
本指南将向您展示如何使用我们预配置的模板在 Novita AI GPU 实例上部署 NVIDIA Nemotron Speech ASR。无需处理复杂的基础设施,即可构建生产级语音应用。
什么是 NVIDIA Nemotron Speech ASR?
NVIDIA Nemotron Speech ASR 是一种流式自动语音识别模型,专为低延迟实时应用而设计。
传统 ASR 系统依赖缓冲音频块,会产生延迟漂移并导致 GPU 利用率低下。Nemotron Speech ASR 采用缓存感知流式处理,无需缓冲延迟即可连续处理音频。
NVIDIA Nemotron Speech ASR 规格:
- **架构:**基于 Conformer-CTC 的缓存感知流式 ASR
- **延迟表现:**端到端处理低于 100ms
- **首词生成时间:**中位延迟 24ms
- **吞吐量提升:**相比缓冲推理高达 3 倍
- **语言支持:**英语(0.6B 参数变体)
- **模型大小:**600M 参数,针对流式处理优化
缓存感知流式架构消除了延迟漂移和冗余计算,使 NVIDIA Nemotron Speech ASR 成为实时转录、语音助手、呼叫中心分析和交互式 AI 应用的理想选择。
什么是 NVIDIA NeMo 框架?
NVIDIA NeMo 框架是一个可扩展的云原生生成式 AI 框架,适用于研究人员和 PyTorch 开发者。
NeMo 框架支持多个 AI 领域的开发:
- 大型语言模型(LLM)
- 多模态模型(MM)
- 自动语音识别(ASR)
- 文本转语音(TTS)
- 计算机视觉(CV)
该框架帮助您利用现有代码和预训练模型检查点,高效地创建、定制和部署生成式 AI 模型。
NVIDIA Nemotron Speech ASR 基于 NeMo 框架构建,以最少的设置提供生产级 ASR 能力。
完整技术文档请参阅 NeMo 框架用户指南。
为什么在 Novita AI 上部署 Nemotron Speech ASR?
Novita AI GPU 实例为大规模部署 NVIDIA Nemotron Speech ASR 提供了优化基础设施:
**快速部署:**使用预配置的 NeMo 模板在数秒内启动 GPU 实例。无需手动设置环境。
**经济实惠的定价:**按秒计费,无长期合同或最低承诺。可根据需求扩展或缩减。
**预配置模板:**NeMo 框架和依赖项已预安装。可立即运行 Nemotron Speech ASR。
**全球基础设施:**跨多个区域提供低延迟 GPU 访问,支持全球部署。
**开发者工具:**实时监控、SSH 访问以及从 Novita AI 模板库直接部署。
无论是原型开发语音助手还是扩展生产转录管道,Novita AI 都能处理 GPU 基础设施,让您专注于构建 ASR 应用。
部署前提条件
在部署 NVIDIA Nemotron Speech ASR 之前,请确保您已具备:
- Novita AI 帐户且拥有足够的积分(在此注册)
- WAV 格式的音频测试文件用于模型验证
- 基本 SSH 知识用于实例访问和配置
- 了解工作负载对 GPU 的要求
无需预先掌握 NeMo 框架经验——Novita AI 模板会处理初始设置。
部署 Nemotron Speech ASR:分步指南
第 1 步:访问 Novita AI 控制台
登录您的 Novita AI 帐户,导航至 GPU 界面。
选择 Get Started 进入部署管理仪表板。
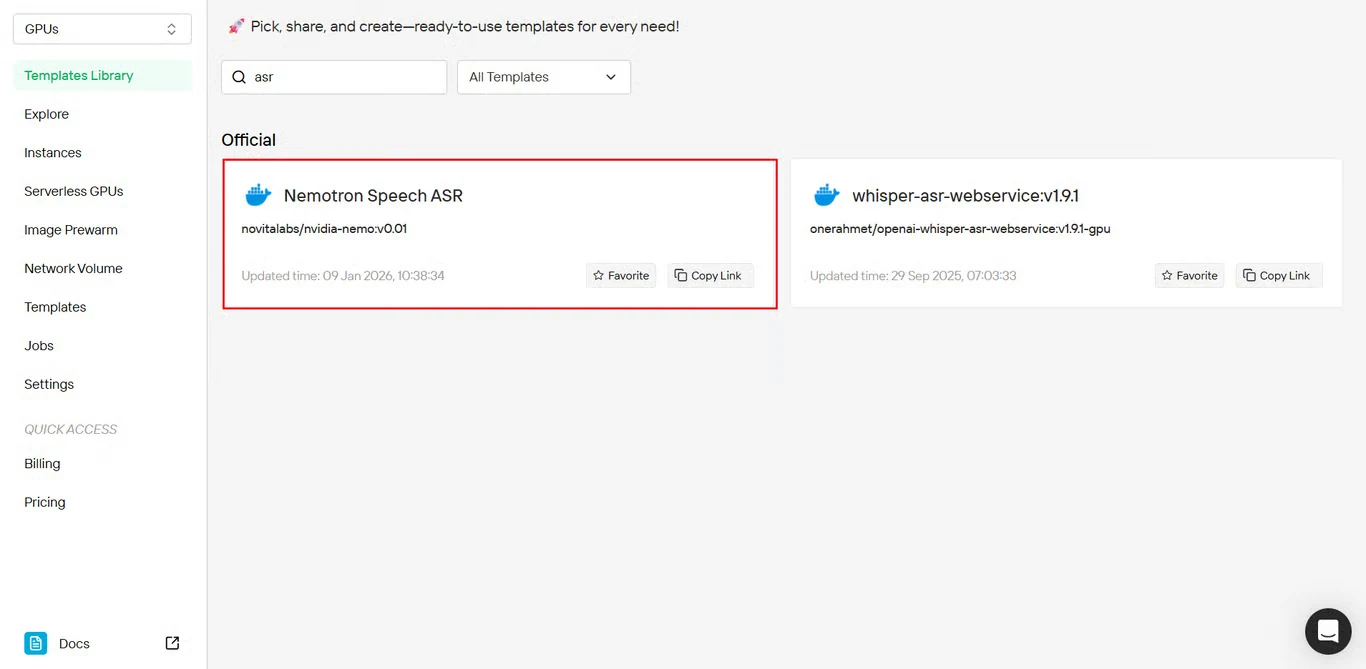
第 2 步:选择 Nemotron Speech ASR 模板
在模板仓库中找到 Nemotron Speech ASR,点击开始安装。
模板直接链接:https://novita.ai/templates-library/108969
该模板包含预配置的 NeMo 框架设置和针对 Nemotron Speech ASR 部署优化的参数。
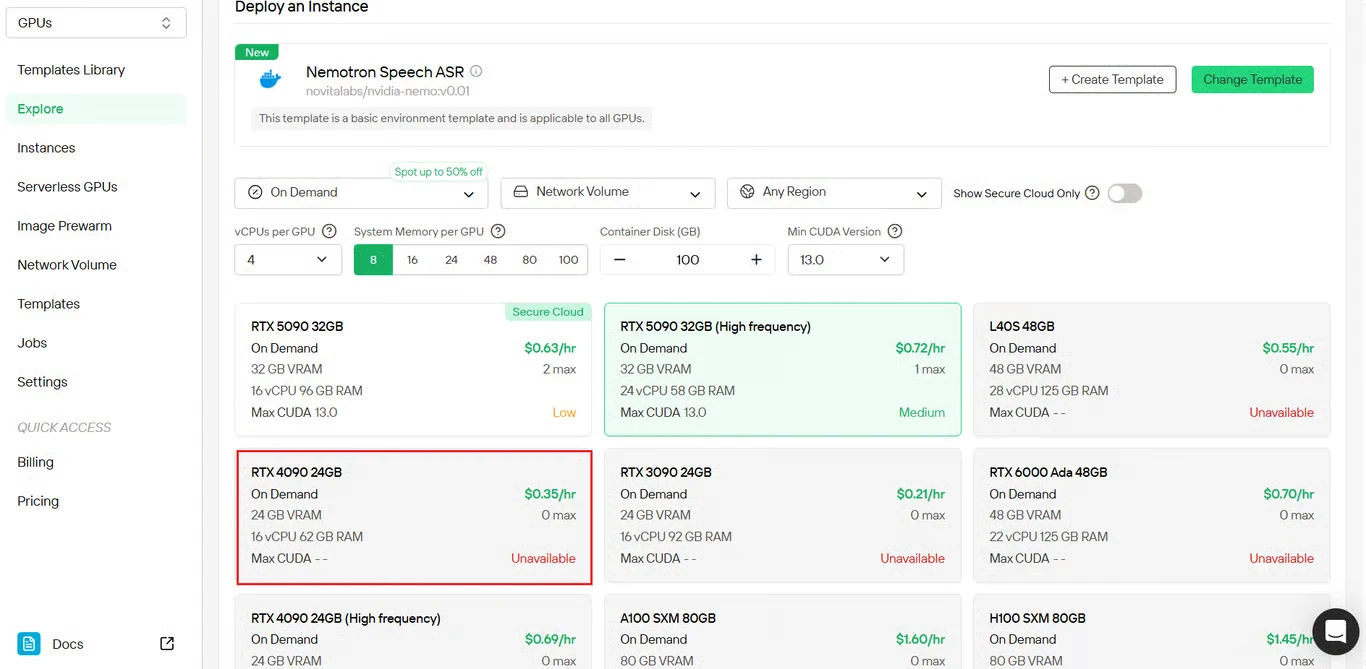
第 3 步:配置 GPU 实例设置
配置您的 GPU 实例参数:
- **内存分配:**根据预期的并发音频流数量决定
- **存储需求:**足够的空间存放模型文件和音频处理数据
- **网络设置:**根据您的地理区域进行配置
- **GPU 选择:**根据吞吐量需求选择
点击 Deploy 继续配置。
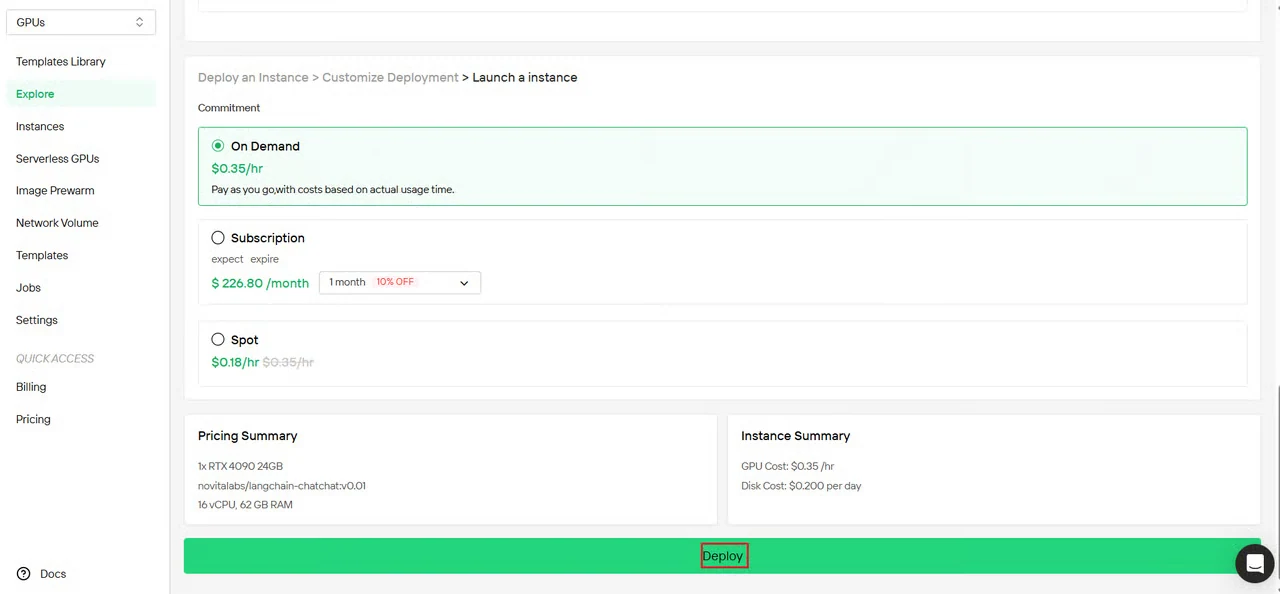
第 4 步:审查配置并部署
审查您的实例配置摘要:
- GPU 类型和数量
- 内存和存储分配
- 网络区域
- 预估费用
确认所有设置后,点击 Deploy 开始创建实例。
第 5 步:监控实例创建
启动部署后,Novita AI 会自动将您重定向到实例管理页面。
您的 Nemotron Speech ASR 实例将在后台创建,同时您可以监控进度。
第 6 步:跟踪下载进度
实时监控 NeMo 框架镜像的下载。
部署完成后,实例状态从 Pulling 更新为 Running。
点击实例名称旁的箭头图标查看详细进度信息。
第 7 步:验证部署状态
点击 Logs 按钮查看实例启动日志。
确认 NeMo 服务正确初始化,Nemotron Speech ASR 已准备好进行推理。
安装 NeMo 框架依赖项
GPU 实例运行后,通过 SSH 连接以安装所需依赖项。
安装系统依赖项和 NeMo 工具包
运行以下命令设置环境:
apt-get update && apt-get install -y libsndfile1 ffmpeg
pip install Cython packaging
pip install git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]
依赖项说明:
- **libsndfile1:**用于 WAV 处理的音频文件 I/O 库
- **ffmpeg:**用于音频转换的多媒体框架
- **Cython:**Python 代码的性能优化
- **nemo_toolkit[asr]:**包含 ASR 特定模块的 NeMo 框架
安装过程根据网络速度需要 5-10 分钟。
运行 NVIDIA Nemotron Speech ASR 模型
下载 Nemotron Speech ASR 模型
从官方 Hugging Face 仓库 下载 NVIDIA Nemotron Speech ASR 模型。
模型文件格式为 .nemo,包含推理所需的所有参数。
使用官方 NeMo 推理脚本
NeMo 框架提供了针对缓存感知流式 ASR 优化的推理脚本。
参考脚本:speech_to_text_cache_aware_streaming_infer.py
运行 Nemotron Speech ASR 推理
执行以下命令对音频进行转写:
python speech_to_text_cache_aware_streaming_infer.py \
model_path=/yourPath/nemotron-speech-streaming-en-0.6b/nemotron-speech-streaming-en-0.6b.nemo \
audio_file=/yourPath/audio.wav
推理参数
根据部署需求配置以下参数:
- **model_path:**Nemotron Speech ASR
.nemo模型文件的完整路径 - **audio_file:**输入音频文件路径(推荐 WAV 格式)
示例转写输出
成功推理会产生类似以下输出:
[NeMo I 2026-01-09 08:13:32 speech_to_text_cache_aware_streaming_infer:282] Final streaming transcriptions: ['The English forwarded to the French baskets of flowers of which they had made a plentiful provision to greet the arrival of the young princess. The French, in return, invited the English to a supper, which was to be given the next day.']
这确认 Nemotron Speech ASR 已通过缓存感知流式架构成功将音频流转换为文本。
Nemotron Speech ASR 应用场景
实时现场转录
为会议、网络研讨会和广播部署 NVIDIA Nemotron Speech ASR,用于实时字幕系统。
低于 100ms 的延迟确保字幕实时显示,无明显延迟。
语音助手应用
构建具有即时语音识别能力的对话式 AI 代理,实现自然的用户交互。
缓存感知流式处理消除了缓冲延迟,带来响应迅速的语音命令体验。
呼叫中心分析与监控
实时转写客户通话,用于情感分析、合规监控和坐席辅助。
高吞吐量(3 倍提升)使无需额外 GPU 资源即可并发处理多个通话。
无障碍解决方案
为听力障碍用户创建需要低延迟实时字幕的辅助技术。
稳定的延迟性能确保在不同音频条件下提供一致的无障碍体验。
媒体制作与内容创作
自动生成播客、视频和直播的字幕,实现高精度的英语转写。
流式架构高效处理长篇幅内容,无内存限制。
结论
在 Novita AI GPU 实例上部署 NVIDIA Nemotron Speech ASR,可在数分钟(而非数小时)内获得生产级语音识别基础设施。
该模型的缓存感知流式架构为您的实时应用提供了稳定的低于 100ms 的延迟和 3 倍的 GPU 效率提升。Novita AI 的预配置模板消除了复杂的 NeMo 框架设置,让您专注于构建语音应用,而非管理基础设施。
无论您是开发语音助手、转录服务、呼叫中心分析还是无障碍工具,这一部署组合消除了延迟、吞吐量和运维复杂性之间的传统权衡。
立即在 Novita AI 上开始部署 Nemotron Speech ASR,享受灵活的按秒 GPU 计费,无需前期承诺。
Novita AI 是一家领先的 AI 云平台,为开发者提供易用的 API 以及经济实惠、可靠的 GPU 基础设施,用于构建和扩展 AI 应用。



