

- Architektur-Highlights von DeepSeek V3.2
- VRAM-Auswirkung der DeepSeek V 3.2 DSA
- DeepSeek V3.2 VRAM- und Hardwareanforderungen
- Wie viel kostet die lokale Bereitstellung von DeepSeek V3.2?
- Kostenvergleich: Lokale GPU vs. Cloud GPU von DeepSeek V3.2
- Ein besserer und günstiger Weg zu DeepSeek V3.2 auf Cloud GPU
- So stellen Sie DeepSeek V3.2 auf Novita AI bereit
Novita AI startet seine „Build Month“-Kampagne und bietet Entwicklern einen exklusiven Rabatt von bis zu 20 % auf alle Hauptprodukte!
Da groß angelegte Reasoning- und Agentenmodelle von der Forschung in die praktische Bereitstellung übergehen, stehen Entwickler vor einer kritischen Spannung zwischen Funktionalität und Kosten. DeepSeek V3.2 verkörpert diese Herausforderung: Während es starken Long-Context-Durchsatz, mehrstufige Tool-Nutzungszuverlässigkeit und verbesserte Stabilität des verstärkenden Lernens bietet, führt es auch zu erheblichen Hardware- und VRAM-Anforderungen, insbesondere bei vollpräziser Bereitstellung.
Dieser Artikel beantwortet diese Fragen, indem er die Architektur von DeepSeek V3.2, die VRAM- und Hardwareanforderungen, die Kostenstruktur der lokalen Bereitstellung und kosteneffiziente Alternativen untersucht, die durch die flexiblen GPU-Angebote von Novita AI ermöglicht werden.
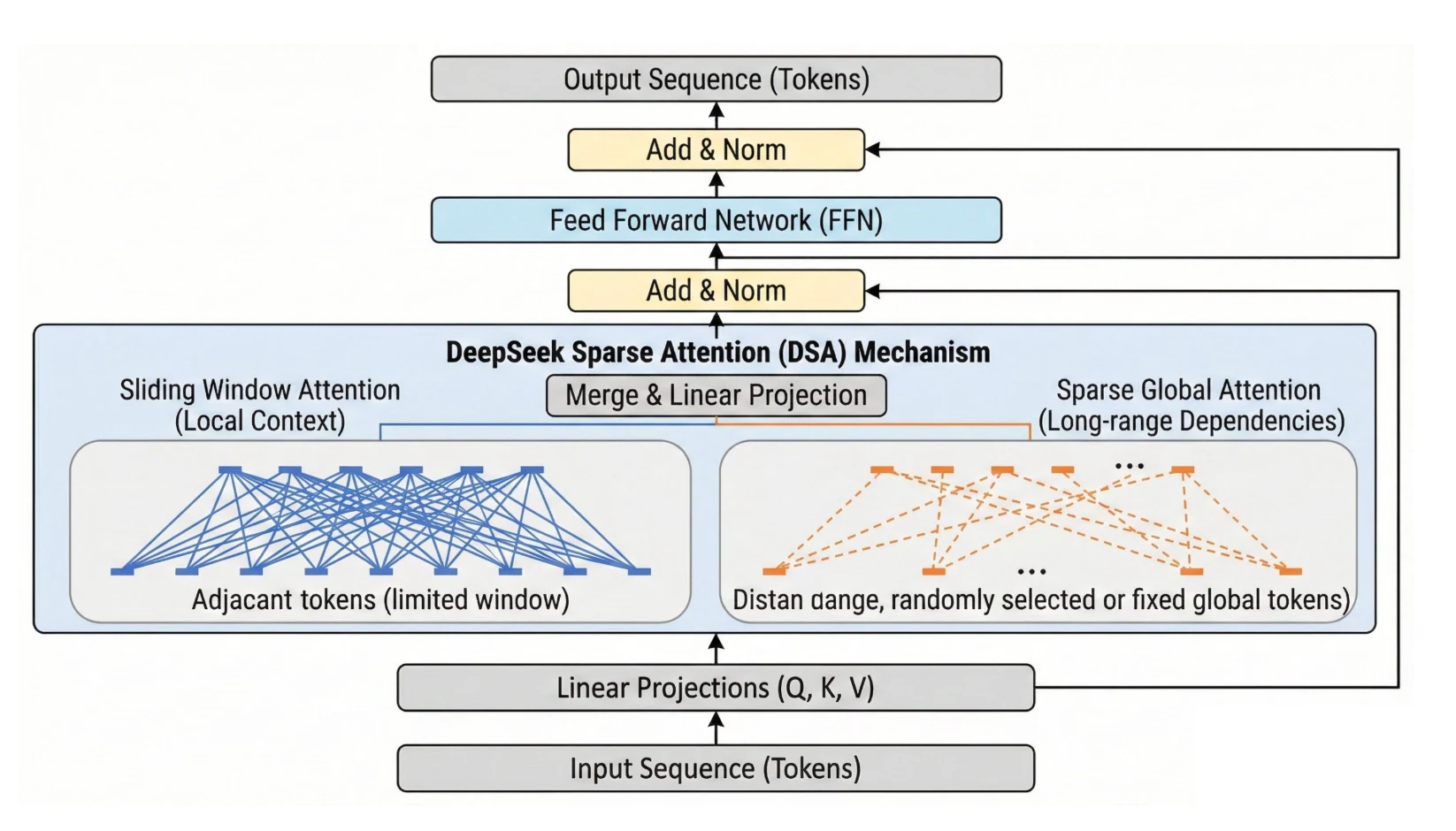
Architektur-Highlights von DeepSeek V3.2
DeepSeek V3.2 lässt sich am besten als „bereitstellungsorientiertes“ Upgrade gegenüber V3/R1 verstehen: Es zielt auf praktischen Long-Context-Durchsatz, agentische Tool-Nutzung mit persistentem Reasoning und einen flexibleren RL-Stack ab, der überprüfbare Belohnungen mit rubrikgesteuerten Belohnungen für nicht überprüfbare Aufgaben mischt. Dies ist direkt für API-Nutzer relevant, denen Latenz, Kontextdruck und mehrstufige Zuverlässigkeit wichtig sind.
| Ebene | Was V3.2 hinzufügt | Was es für API-Nutzer ändert |
|---|---|---|
| Langer Kontext (DSA) | DeepSeek Sparse Attention (DSA) mit einem Blitz-Indizierer + Token-Selektor (Top-k). Sparse Attention reduziert die Attention. | Lange Prompts werden wirtschaftlich sinnvoll: niedrigere Grenzkosten pro zusätzlicher Token-Position in langen Kontexten, verbesserte End-to-End-Geschwindigkeit in Long-Context-Szenarien, weniger Bereitstellungen, die „aufgeteilt werden müssen“. |
| Agentenfähigkeit | „Denken in der Tool-Nutzung“ plus Kontextverwaltung, die Reasoning-Spuren über Tool-Ausgaben hinweg beibehält, und groß angelegte agentische Datensynthese (offizielle Release Notes: 1.800+ Umgebungen, 85k+ komplexe Anweisungen). | Höhere Erfolgsraten bei Multi-Tool-Workflows. Reduzierte Fehler durch das erneute Ableiten von Zuständen bei jedem Tool-Aufruf, aber auch höheres Risiko für Kontext-Überlauf, wenn er nicht verwaltet wird. |
| RLVR + Multi-Belohnung | Gemischtes RL verwendet regelbasierte Ergebnisbelohnung + Längenstrafe + Sprachkonsistenz für Reasoning-/Agentenaufgaben; generatives Belohnungsmodell mit per-Prompt-Rubriken für allgemeine Aufgaben. GRPO stabilisiert durch unvoreingenommene KL-Schätzung, Off-Policy-Sequenzmaskierung, Keep-Routing (MoE), Keep-Sampling-Maske (Top-p/Top-k). | Robustere Ausrichtung für offene Aufgaben ohne symbolische Verifizierer; bessere RL-Stabilität im großen Maßstab; besser kontrollierbare Ausführlichkeit über Längenstrafen. |
VRAM-Auswirkung der DeepSeek V 3.2 DSA
DeepSeek Sparse Attention (DSA) senkt die Rechen- und Speicherkosten von Attention-Schichten für lange Kontexte, indem es die Attention auf nur die relevantesten Token beschneidet, was den Gesamt-FLOPs und VRAM-Druck im Vergleich zu dichter Attention bei großen Token-Anzahlen reduziert. API-Preissenkungen von über 50 % spiegeln diese Effizienzgewinne in der Praxis wider.
- DSA reduziert die Rechen- und Speicherkosten für lange Kontexte um etwa 50 %+ im Vergleich zu dichter Attention in Szenarien mit langen Sequenzen, mit vernachlässigbarer Qualitätseinbuße.
- Diese Reduktion ändert nicht die Gesamtparameteranzahl des Modells (≈685B), sondern senkt den Laufzeitspeicherbedarf für lange Fenster, insbesondere die pro-Token-KV- und Attention-Arbeitsbereichsnutzung.
| Kontextlänge | Dichte Attention (Basistrend) | DSA (DeepSeek Sparse Attention) Effekt (ca.) |
|---|---|---|
| 8K Token | Baseline-Speicher & -Rechenleistung | ähnlicher oder moderat niedrigerer Speicher – minimaler Overhead durch Sparsity bei kurzen Längen |
| 32K Token | Quadratische Zunahme wird groß | 30-40 % niedrigere Speichernutzung vs. dichte Attention bei ähnlichen Kontextlängen (Inferenz) |
| 128K Token | Kosten und Speicher werden sehr hoch | 60-70 % niedrigere Speichernutzung & Kosten, mit Inferenzkosten, die um >60 % reduziert sind, und Speichernutzung, die um ~70 % mit DSA reduziert ist |
Von Amitray
DeepSeek V3.2 VRAM- und Hardwareanforderungen
Vollpräzision (FP16/BF16)
Bei standardmäßiger Vollpräzisionsbereitstellung (FP16/BF16) erfordert die Inferenz mit DeepSeek-V3.2 extrem hohe Hardwareanforderungen, da der kombinierte GPU-Speicherbedarf für Modellgewichte und Laufzeitausführung approximately 1 TB überschreitet. Für BF16/FP16-Szenarien werden üblicherweise Konfigurationen mit 8–16 H100- oder A100-GPUs mit je 80 GB VRAM verwendet, was eine gesamte GPU-Speicherkapazität von fast 1,3 TB ergibt.
Quantisierung & Auslagerungskompromisse
| Quantisierungsstufe | Ungefährer Speicherbedarf |
|---|---|
| FP16 / BF16 | 1,3 TB gesamt |
| 8-Bit (w8a8) | 670 GB gesamt |
| 4-Bit | 335 GB gesamt |
Wie viel kostet die lokale Bereitstellung von DeepSeek V3.2?
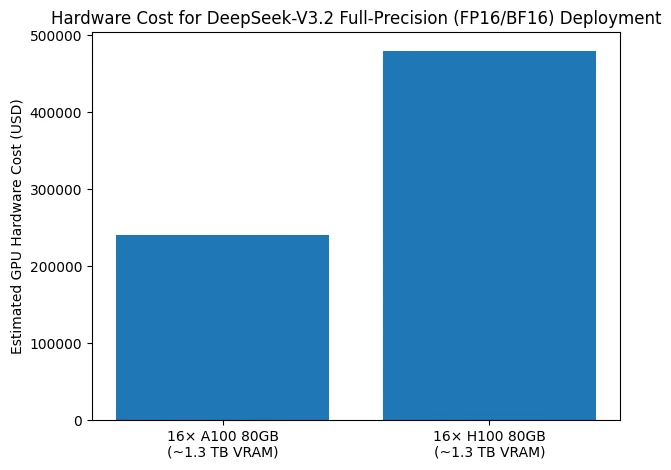
Das Balkendiagramm zeigt die Hardwarekosten, die für die Bereitstellung von DeepSeek-V3.2 unter Vollpräzisionseinstellungen (FP16/BF16) erforderlich sind. Um den ungefähren GPU-Speicherbedarf von 1,3 TB zu decken, basiert eine typische Konfiguration auf 16 GPUs mit je 80 GB VRAM. Bei Verwendung von A100 80 GB GPUs liegen die geschätzten GPU-only-Kosten bei rund 240.000 US-Dollar, während eine gleichwertige Konfiguration auf Basis von H100 80 GB GPUs die Kosten auf rund 480.000 US-Dollar erhöht.
Dieser Vergleich zeigt, dass die vollpräzise Inferenz von DeepSeek-V3.2 bereits vor der Berücksichtigung von Servern, Hochgeschwindigkeitsverbindungen, Strom und Kühlinfrastruktur allein für GPUs mehrere hunderttausend US-Dollar kostet. Die Zahl unterstreicht daher die außergewöhnlich hohe Hardwarekostenbarriere für die Bereitstellung von DeepSeek-V3.2 in FP16/BF16, was erklärt, warum solche Bereitstellungen weitgehend auf große Rechenzentren beschränkt sind und warum Quantisierungs- und Auslagerungsstrategien in der Praxis oft als unerlässlich angesehen werden.
Kostenvergleich: Lokale GPU vs. Cloud GPU von DeepSeek V3.2
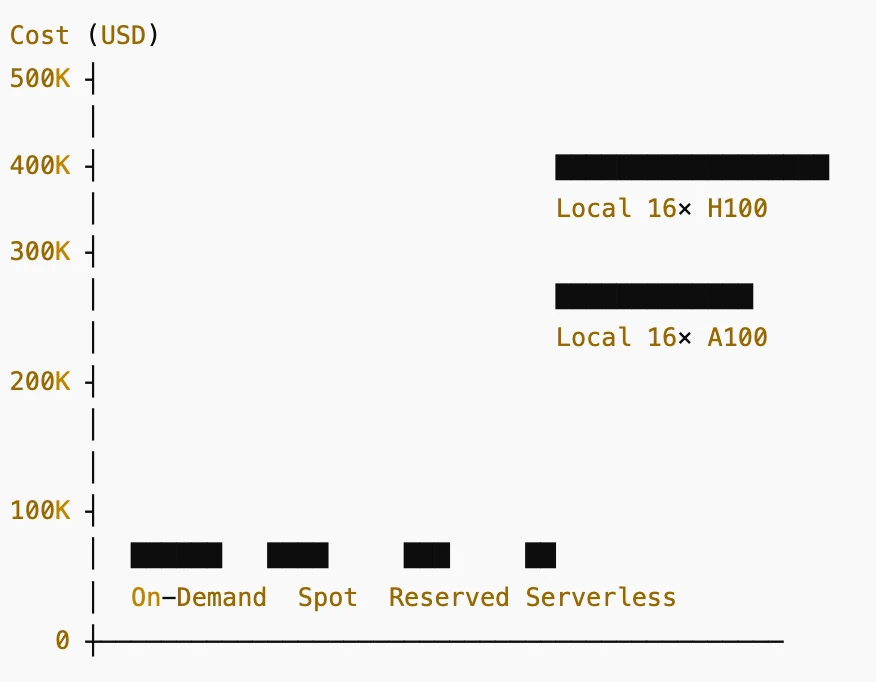
Balken (von links nach rechts):
- On-Demand: ~26.000 $/Jahr
- Spot-Instanzen: ~13.000 $/Jahr
- Reservierte / Abonnement-Pläne: ~8.000 $/Jahr
- Serverlose GPU-Abrechnung: ~5.000 $/Jahr
- Lokal 16× A100 80 GB: ~240.000 $ Hardwarekosten
- Lokal 16× H100 80 GB: ~480.000 $ Hardwarekosten
Ein besserer und günstiger Weg zu DeepSeek V3.2 auf Cloud GPU
Novita AI bietet vier GPU-Abrechnungsmodelle an, um unterschiedliche Workload-Muster und Kostenanforderungen zu erfüllen.
Abrechnungsmodell Abrechnungsmethode Ressourcenverfügbarkeit Kostenniveau Unterbrechungsrisiko Typische Anwendungsfälle On-Demand (Pay-as-you-go) Abrechnung nach tatsächlicher Laufzeit (pro Sekunde oder pro Stunde) Hoch, Instanzen können jederzeit gestartet oder gestoppt werden Mittel Keines Entwicklung und Test, Modell-Debugging, variable oder unvorhersehbare Workloads Spot-Instanzen Abrechnung nach Laufzeit zu ermäßigten Preisen Mittel, abhängig von verfügbarer Leerlaufkapazität Niedrig (oft bis zu ~50 % günstiger als On-Demand) Ja, Instanzen können vorzeitig beendet werden Batch-Jobs, Offline-Inferenz, fehlertolerantes Training, kostensensitive Workloads Abonnement / Reservierte Pläne Feste monatliche oder jährliche Abrechnung Hoch, dedizierte und vorhersehbare Ressourcen Mittel–Niedrig (ermäßigt im Vergleich zu On-Demand) Keines Langfristig stabile Workloads, Produktionssysteme, kontinuierliches Training oder Inferenz Serverlose GPU-Abrechnung Abrechnung nach tatsächlich verbrauchter Rechenleistung pro Ausführung Skaliert automatisch mit der Nachfrage Niedrig–Mittel (zahle nur für das, was genutzt wird) Keines (vollständig von der Plattform verwaltet) Ereignisgesteuerte Inferenz, sprunghafter Verkehr, API-basiertes Modell-Serving, minimaler Betriebsaufwand
- On-Demand (Pay-as-you-go)
On-Demand ist das Standardverbrauchsmodell, bei dem GPU-Rechenleistung strikt nach Laufzeit abgerechnet wird, typischerweise pro Sekunde oder pro Stunde, ohne langfristige Verpflichtungen oder Reservierungen. Es bietet maximale Flexibilität und eignet sich gut für variable Workloads, intermittierende Nutzung und frühe Experimente, da Kosten nur anfallen, während die Instanz aktiv ist. Speicher und Hilfsressourcen, einschließlich Festplatten und Netzwerk, werden nutzungsbasiert abgerechnet.
Probieren Sie jetzt schnelle und günstige GPUs aus!
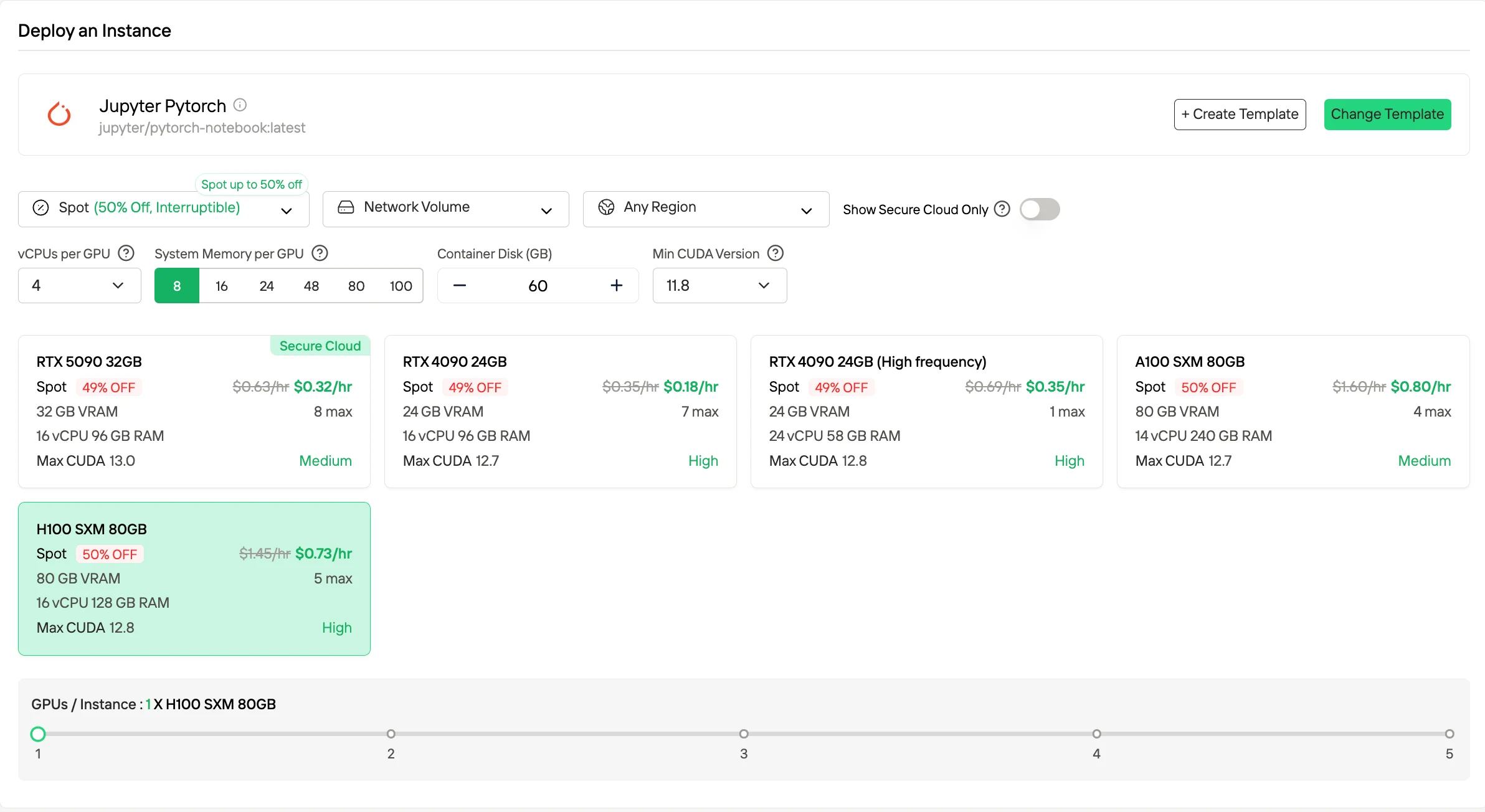
- Spot-Instanzen
Spot-Instanzen bieten deutlich reduzierte Stundenpreise, oft bis zu etwa 50 % niedriger als On-Demand-Preise, indem sie ungenutzte GPU-Kapazität nutzen. Diese Instanzen können von der Plattform vorzeitig beendet werden. Novita mildert dieses Risiko durch ein einstündiges Schutzfenster und vorab Benachrichtigungen über die Beendigung. Dieser Abrechnungsmodus eignet sich für fehlertolerante oder Batch-Workloads, bei denen gelegentliche Unterbrechungen akzeptabel sind.
Probieren Sie jetzt schnelle und günstige GPUs aus!
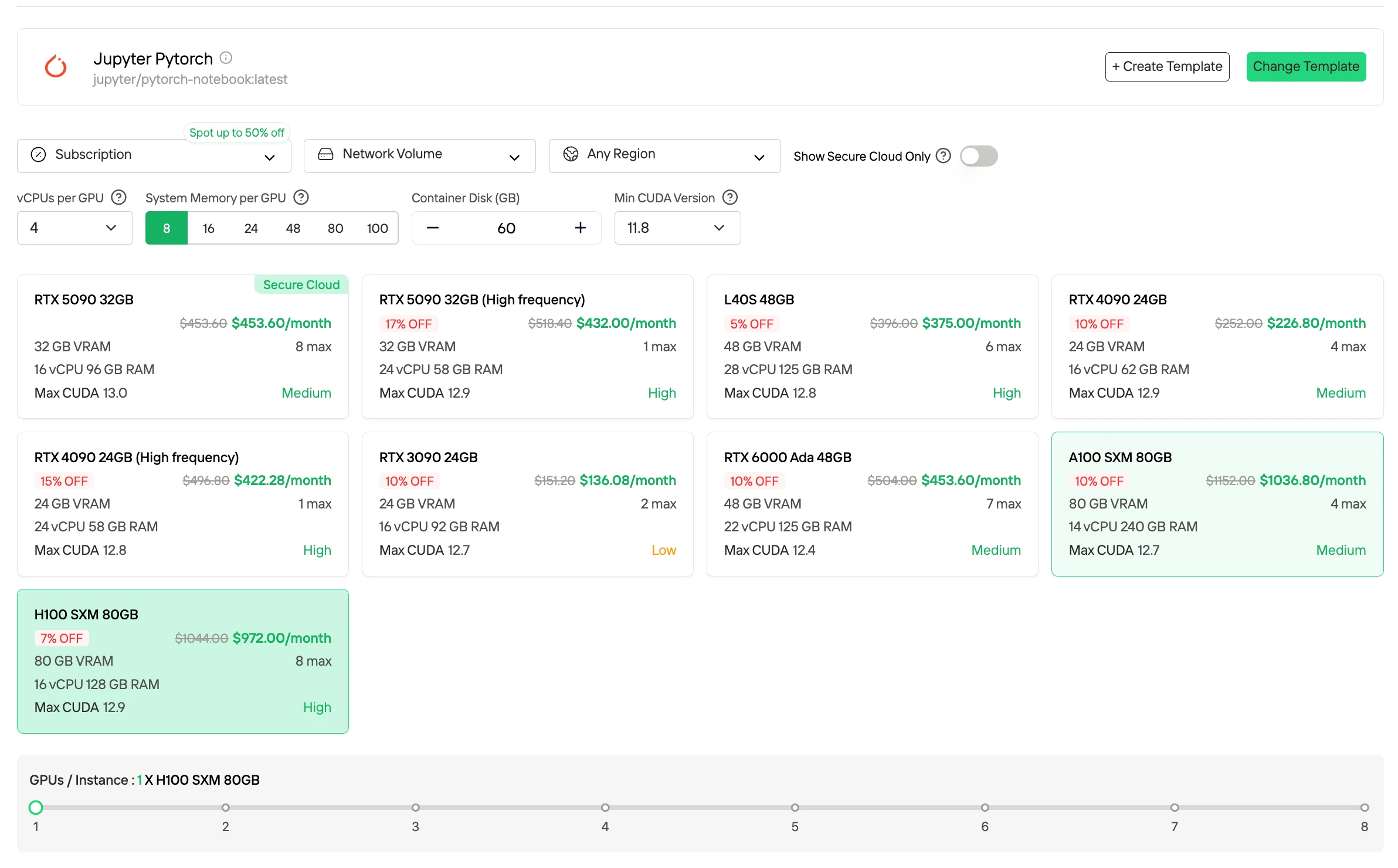
- Abonnement / Reservierte Pläne
Abonnement- und reservierte Pläne sind monatlich oder jährlich verfügbar und bieten dedizierte GPU-Ressourcen mit vorhersehbarer Verfügbarkeit. Im Vergleich zu On-Demand-Preisen bieten diese Pläne in der Regel niedrigere effektive Stückkosten im Austausch gegen langfristige Verpflichtungen. Sie eignen sich am besten für stabile, kontinuierliche Workloads und Produktionsumgebungen, die konsistente Rechenkapazität erfordern.
Probieren Sie jetzt schnelle und günstige GPUs aus!
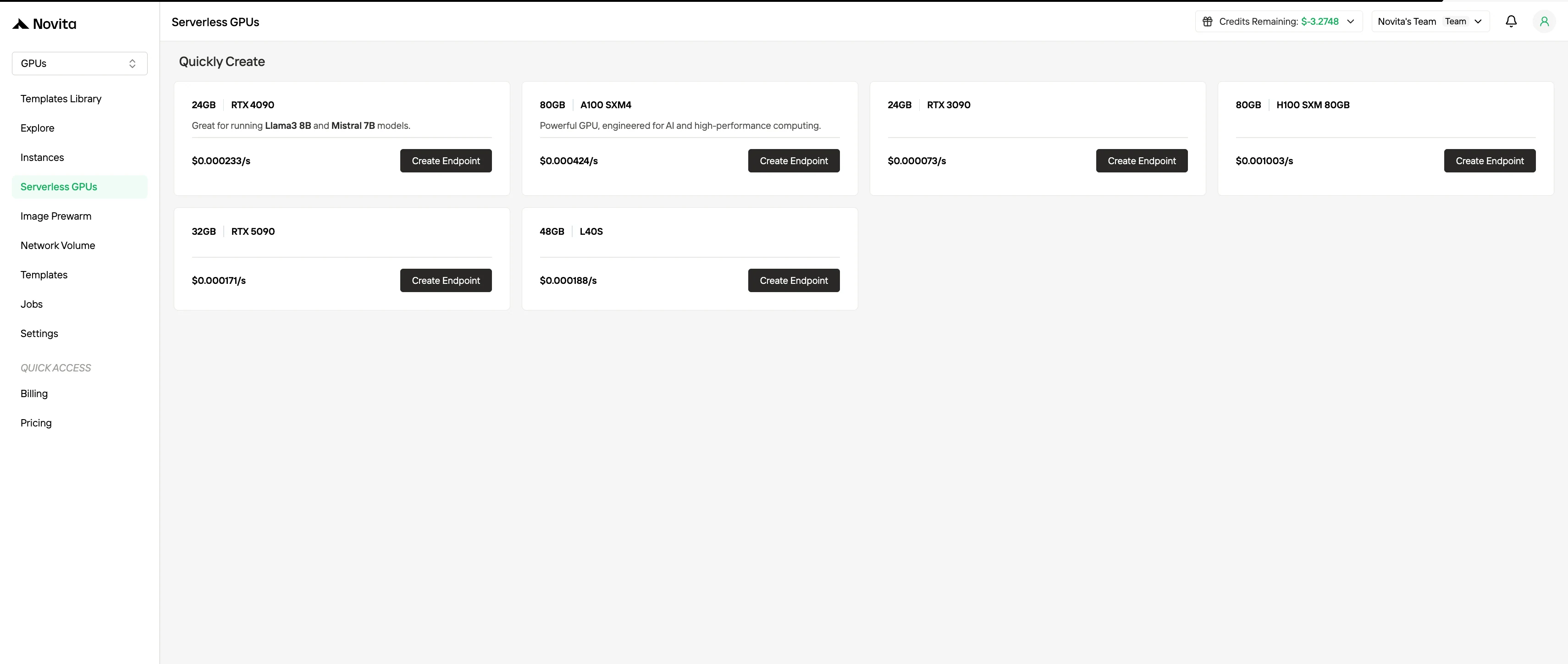
- Serverlose GPU-Abrechnung
Serverlose GPU-Abrechnung abstrahiert die Instanzverwaltung, indem sie GPU-Ressourcen automatisch als Reaktion auf die Workload-Nachfrage skaliert. Nutzer werden nur für die tatsächlich verbrauchten Rechenressourcen berechnet, nicht für bereitgestellte Instanzen. Dieses Modell ist vorteilhaft für ereignisgesteuerte oder stark elastische Workloads, da es den Betriebsaufwand minimiert und gleichzeitig die Kosteneffizienz verbessert.
Probieren Sie jetzt schnelle und günstige GPUs aus!
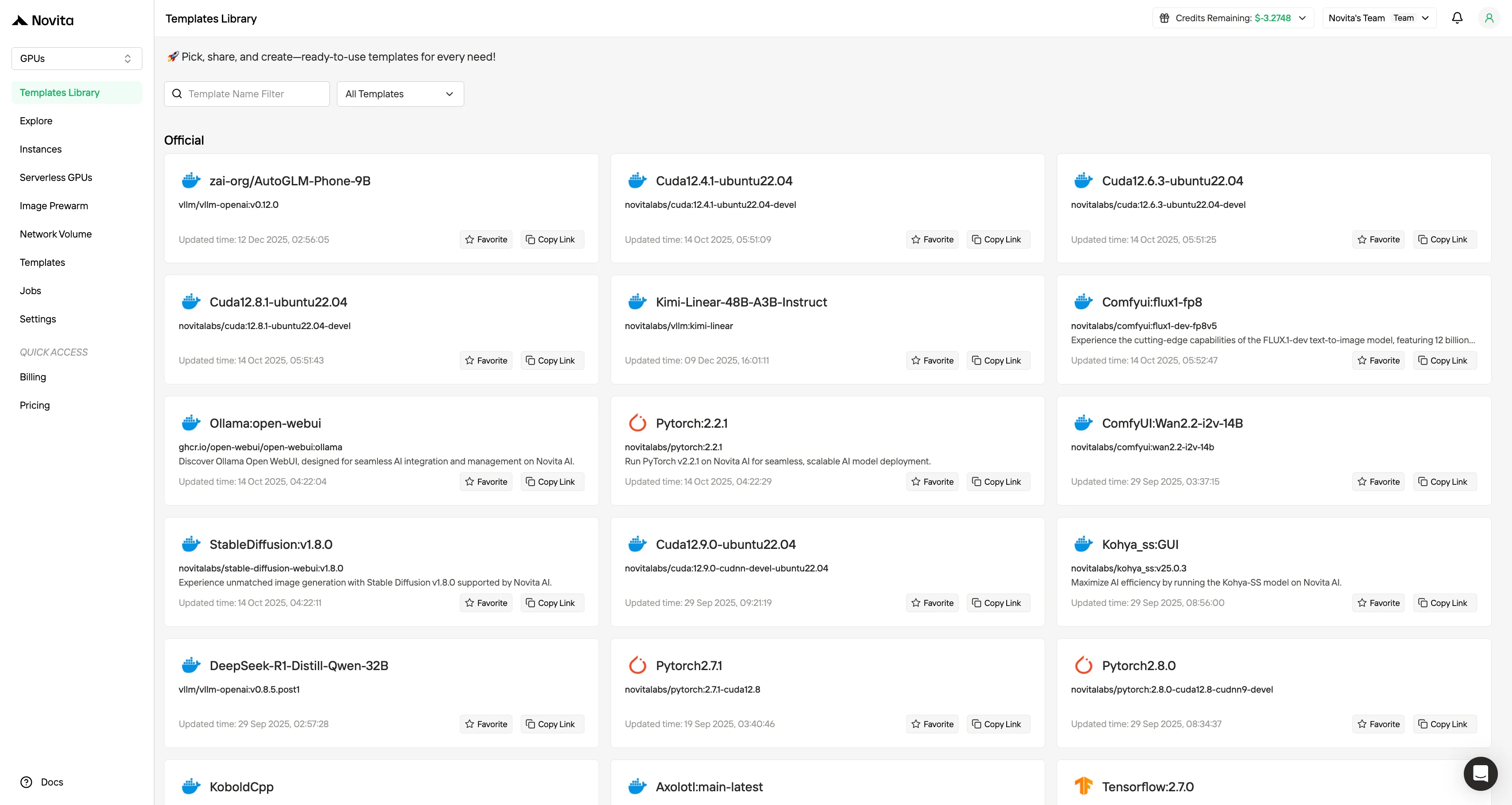
Novita AI bietet außerdem Vorlagen, die entwickelt wurden, um den betrieblichen und kognitiven Aufwand für die Bereitstellung von GPU-basierten KI-Workloads deutlich zu senken. Anstatt dass Entwickler Umgebungen von Grund auf manuell zusammenstellen müssen, bietet das Vorlagensystem vorkonfigurierte, produktionsbereite Images, die das Betriebssystem, CUDA- und cuDNN-Versionen, Deep-Learning-Frameworks, Inferenz-Engines und in einigen Fällen sogar vollständig verdrahtete Modell-Serving-Stacks bündeln.
So stellen Sie DeepSeek V3.2 auf Novita AI bereit
Schritt 1:Registrieren Sie ein Konto
Erstellen Sie Ihr Novita AI-Konto über unsere Website. Nach der Registrierung navigieren Sie zum Bereich „Entdecken“ in der linken Seitenleiste, um unsere GPU-Angebote anzusehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2:Vorlagen und GPU-Server erkunden
Wählen Sie Vorlagen wie PyTorch, TensorFlow oder CUDA, die zu den Anforderungen Ihres Projekts passen. Wählen Sie dann Ihre bevorzugte GPU-Konfiguration – Optionen umfassen die leistungsstarken L40S, RTX 4090 oder A100 SXM4, jeweils mit unterschiedlichen VRAM-, RAM- und Spezifikationen.
Schritt 3:Passen Sie Ihre Bereitstellung an und starten Sie eine Instanz
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um eine optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen zu gewährleisten. Anschließend ist Ihre leistungsstarke GPU-Umgebung innerhalb von Minuten einsatzbereit, sodass Sie sofort mit Ihren Machine-Learning-, Rendering- oder Rechenprojekten beginnen können.
Schritt 4: Bereitstellungsfortschritt überwachen
Navigieren Sie zur Instanzverwaltung, um auf die Steuerungskonsole zuzugreifen. Dieses Dashboard ermöglicht es Ihnen, den Bereitstellungsstatus in Echtzeit zu verfolgen.
Probieren Sie jetzt schnelle und günstige GPUs aus!
Schritt 5: Image-Pull-Status anzeigen
Klicken Sie auf Ihre spezifische Instanz, um den Download-Fortschritt des Container-Images zu überwachen. Dieser Vorgang kann je nach Netzwerkbedingungen mehrere Minuten dauern.
Schritt 6: Erfolgreiche Bereitstellung verifizieren
Nach dem Start der Instanz beginnt sie mit dem Herunterladen des Modells. Klicken Sie auf „Logs“ → „Instanz-Logs“, um den Download-Fortschritt des Modells zu überwachen. Suchen Sie nach der Meldung
"Application startup complete."in den Instanz-Logs. Dies zeigt an, dass der Bereitstellungsprozess erfolgreich abgeschlossen wurde.Klicken Sie auf „Connect“, dann auf → „Connect to HTTP Service [Port 8000]“. Da es sich um einen API-Dienst handelt, müssen Sie die Adresse kopieren.
Um Anfragen an Ihr Modell zu senden, ersetzen Sie bitte „http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai" durch Ihre tatsächliche exponierte Adresse. Kopieren Sie den folgenden Code, um auf Ihr privates Modell zuzugreifen!
DeepSeek V3.2 stellt eine bereitstellungsorientierte Evolution großer MoE-Sprachmodelle dar, die Sparse Attention, agentenbewusstes Reasoning und gemischte Belohnungsverstärkung kombiniert, um die Effizienz bei langen Kontexten und die Multi-Tool-Zuverlässigkeit zu verbessern. Unter FP16/BF16-Einstellungen erfordert DeepSeek V3.2 jedoch approximately 1,3 TB an aggregiertem GPU-Speicher, was in mehreren hunderttausend US-Dollar an GPU-Hardwarekosten allein resultiert. Quantisierung und Auslagerung reduzieren den Speicherdruck deutlich, bringen aber Kompromisse in Bezug auf Komplexität und Leistung mit sich. Im Gegensatz dazu bietet die Cloud-basierte Bereitstellung auf Novita AI einen zugänglicheren Weg, der flexible Abrechnungsmodelle, vorkonfigurierte Vorlagen und schnelle Bereitstellung nutzt, um sowohl finanzielle als auch betriebliche Hürden zu senken. Zusammen machen diese Optionen klar, wie DeepSeek V3.2 strategisch und nicht prohibitiv bereitgestellt werden kann.
Häufig gestellte Fragen
Warum erfordert DeepSeek V3.2 bei voller Präzision so viel GPU-Speicher?
DeepSeek V3.2 erfordert viel GPU-Speicher, weil seine ≈685B Parameter zusammen mit Long-Context-KV-Caches und Laufzeitausführungspuffern FP16/BF16-Bereitstellungen auf approximately 1,3 TB an aggregiertem VRAM drücken.
Wie senkt DeepSeek V3.2 die Kosten für lange Kontexte im Vergleich zu früheren Modellen?
DeepSeek V3.2 führt DeepSeek Sparse Attention (DSA) ein, die Attention auf die Top-k relevantesten Token beschneidet und so die Rechenleistung und VRAM-Nutzung für lange Kontexte um 50–70 % im Vergleich zu dichter Attention bei großen Kontextlängen reduziert.
Welche Hardware wird typischerweise benötigt, um DeepSeek V3.2 in FP16/BF16 auszuführen?
Die vollpräzise Inferenz von DeepSeek V3.2 basiert üblicherweise auf 8–16 A100- oder H100-GPUs mit je 80 GB VRAM, was zu insgesamt fast 1,3 TB GPU-Speicher aggregiert.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen ermöglicht. Integrierte APIs, serverlos, GPU-Instanz – die kosteneffektiven Tools, die Sie brauchen. Eliminieren Sie Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.
Empfohlene Lektüre
MiniMax Speech 02: Top-Lösung für schnelle und natürliche Sprachgenerierung ERNIE-4.5-VL-A3B VRAM-Anforderungen: Führen Sie multimodale Modelle mit geringeren Kosten aus Qwen3 Embedding 8B: Leistungsstarke Suche, flexible Anpassung und mehrsprachig



