

- Points clés de l'architecture de DeepSeek V3.2
- Impact VRAM du DSA de DeepSeek V3.2
- Exigences VRAM et matérielles de DeepSeek V3.2
- Quel est le coût du déploiement local de DeepSeek V3.2 ?
- Comparaison des coûts : GPU local vs GPU cloud de DeepSeek V3.2
- Une méthode plus efficace et moins coûteuse pour déployer DeepSeek V3.2 sur GPU cloud
- Comment déployer DeepSeek V3.2 sur Novita AI
Novita AI lance sa campagne « Build Month », offrant aux développeurs une incitation exclusive allant jusqu’à 20 % de réduction sur tous les produits principaux !
Alors que les modèles de raisonnement à grande échelle et les modèles agentiques passent de la recherche au déploiement dans le monde réel, les développeurs sont confrontés à une tension critique entre capacité et coût. DeepSeek V3.2 incarne parfaitement ce défi : s’il offre un débit élevé pour les longs contextes, une fiabilité d’utilisation d’outils multi-étapes et une stabilité améliorée de l’apprentissage par renforcement, il impose également des exigences matérielles et VRAM substantielles, notamment en déploiement pleine précision.
Cet article répond à ces questions en examinant l’architecture de DeepSeek V3.2, ses exigences VRAM et matérielles, la structure des coûts du déploiement local et les alternatives économiques offertes par les solutions GPU flexibles de Novita AI.
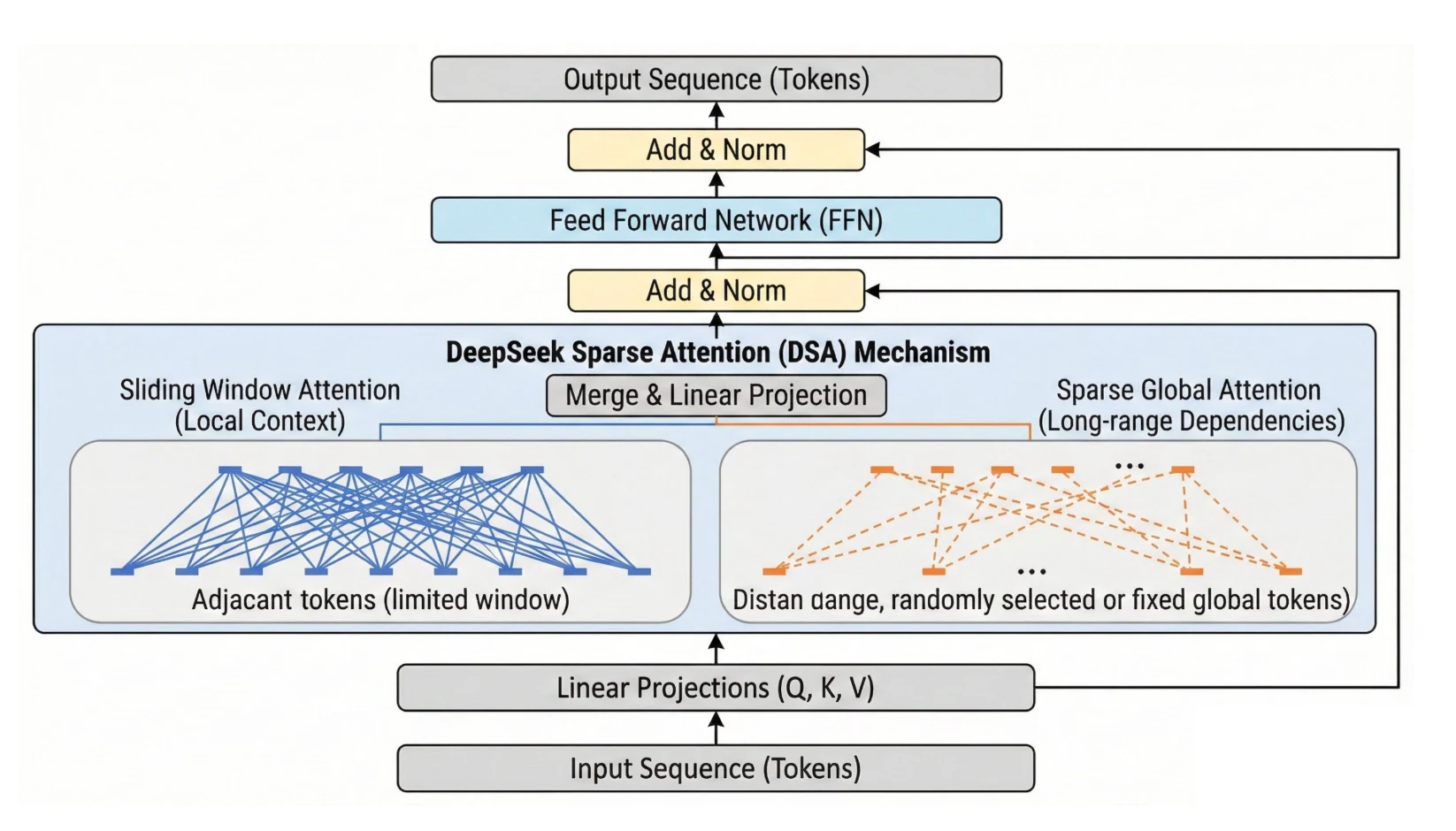
Points clés de l’architecture de DeepSeek V3.2
DeepSeek V3.2 est avant tout une mise à niveau « priorité déploiement » par rapport à V3/R1 : il cible un débit pratique pour les longs contextes, une utilisation d’outils agentiques avec raisonnement persistant, et une pile d’apprentissage par renforcement (RL) plus flexible qui mélange des récompenses vérifiables et des récompenses basées sur des grilles d’évaluation pour les tâches non vérifiables, ce qui intéresse directement les utilisateurs d’API qui se soucient de la latence, de la pression sur le contexte et de la fiabilité multi-étapes.
| Couche | Ce que V3.2 ajoute | Ce que cela change pour les utilisateurs d’API |
|---|---|---|
| Long contexte (DSA) | DeepSeek Sparse Attention (DSA) avec un indexeur éclair + un sélecteur de jetons (top-k). L’attention éparse réduit l’attention. | Les prompts longs deviennent économiquement viables : coût marginal plus faible par position de jeton supplémentaire dans les longs contextes, vitesse de bout en bout améliorée dans les scénarios de long contexte, moins de déploiements nécessitant un découpage obligatoire des prompts. |
| Capacité agentique | « Réflexion lors de l’utilisation d’outils » plus une gestion de contexte qui conserve les traces de raisonnement entre les sorties d’outils, et une synthèse de données agentiques à grande échelle (notes de publication officielles : plus de 1 800 environnements, plus de 85 000 instructions complexes). | Taux de réussite plus élevés dans les flux de travail multi-outils. Réduction des échecs liés à la redérivation de l’état à chaque appel d’outil, mais aussi risque plus élevé de dépassement de contexte en cas de mauvaise gestion. |
| RLVR + récompenses multiples | RL mixte utilisant une récompense basée sur des règles + une pénalité de longueur + une cohérence linguistique pour les tâches de raisonnement/agentiques ; modèle de récompense génératif avec des grilles d’évaluation par prompt pour les tâches générales. GRPO stabilisé grâce à une estimation KL non biaisée, un masquage de séquence hors politique, le maintien du routage (MoE), le maintien du masque d’échantillonnage (top-p/top-k). | Alignement plus robuste pour les tâches ouvertes sans vérificateurs symboliques ; meilleure stabilité du RL à grande échelle ; verbosité plus contrôlable grâce aux pénalités de longueur. |
Impact VRAM du DSA de DeepSeek V3.2
L’attention éparse DeepSeek (DSA) réduit le coût de calcul et de mémoire des couches d’attention pour les longs contextes en éliminant l’attention sur tous les jetons sauf les plus pertinents, réduisant ainsi globalement les FLOPs et la pression sur la VRAM par rapport à l’attention dense pour un grand nombre de jetons. Les baisses de prix des API de plus de 50 % reflètent ces gains d’efficacité en pratique.
- Le DSA réduit le coût de calcul et de mémoire des longs contextes d’environ 50 % ou plus par rapport à l’attention dense dans les scénarios de longues séquences, avec une dégradation de qualité négligeable.
- Cette réduction ne modifie pas le nombre total de paramètres du modèle (≈685B) mais réduit l’empreinte mémoire d’exécution pour les longues fenêtres, notamment l’utilisation du KV par jeton et de l’espace de travail d’attention.
| Longueur de contexte | Attention dense (tendance de référence) | Effet du DSA (Attention éparse DeepSeek) (approx.) |
|---|---|---|
| 8 000 jetons | Mémoire et calcul de référence | Mémoire similaire ou légèrement inférieure — surcharge d’éparsité minimale pour les courtes longueurs |
| 32 000 jetons | Augmentation quadratique importante | 30 à 40 % d’utilisation mémoire en moins par rapport à l’attention dense pour des longueurs de contexte similaires (inférence) |
| 128 000 jetons | Coût et mémoire deviennent très élevés | 60 à 70 % d’utilisation mémoire et de coût en moins, avec un coût d’inférence réduit de plus de 60 % et une utilisation mémoire réduite d’environ 70 % avec le DSA |
Source : Amitray
Exigences VRAM et matérielles de DeepSeek V3.2
Pleine précision (FP16/BF16)
En déploiement pleine précision (FP16/BF16) standard, l’inférence avec DeepSeek-V3.2 impose des exigences matérielles extrêmement élevées, car la mémoire GPU combinée nécessaire pour les poids du modèle et l’exécution en temps d’exécution dépasse environ 1 To. Pour les scénarios BF16/FP16, les configurations couramment adoptées incluent 8 à 16 GPU de classe H100 ou A100 avec 80 Go de VRAM chacun, soit une capacité totale de mémoire GPU d’environ 1,3 To.
Compromis de quantification et de déchargement
| Niveau de quantification | Empreinte mémoire approximative |
|---|---|
| FP16 / BF16 | 1,3 To total |
| 8 bits (w8a8) | 670 Go total |
| 4 bits | 335 Go total |
Quel est le coût du déploiement local de DeepSeek V3.2 ?
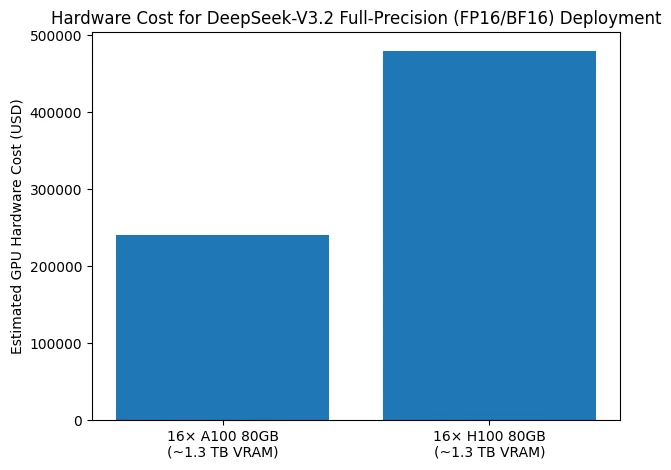
Le graphique à barres illustre le coût matériel nécessaire pour déployer DeepSeek-V3.2 en paramètres pleine précision (FP16/BF16). Pour répondre à l’exigence de mémoire GPU d’environ 1,3 To, une configuration typique repose sur 16 GPU avec 80 Go de VRAM chacun. Avec des GPU A100 80 Go, le coût estimé pour les seuls GPU est d’environ 240 000 USD, tandis qu’une configuration équivalente basée sur des GPU H100 80 Go porte ce coût à environ 480 000 USD.
Cette comparaison met en évidence que, même sans prendre en compte les serveurs, les interconnexions haut débit, l’alimentation électrique et les infrastructures de refroidissement, l’inférence en pleine précision de DeepSeek-V3.2 implique déjà plusieurs centaines de milliers de dollars d’investissement dans les GPU seuls. Ce chiffre souligne donc la barrière de coût matériel exceptionnellement élevée du déploiement de DeepSeek-V3.2 en FP16/BF16, ce qui explique pourquoi de tels déploiements sont largement confinés aux centres de données à grande échelle et pourquoi les stratégies de quantification et de déchargement sont souvent considérées comme essentielles en pratique.
Comparaison des coûts : GPU local vs GPU cloud de DeepSeek V3.2
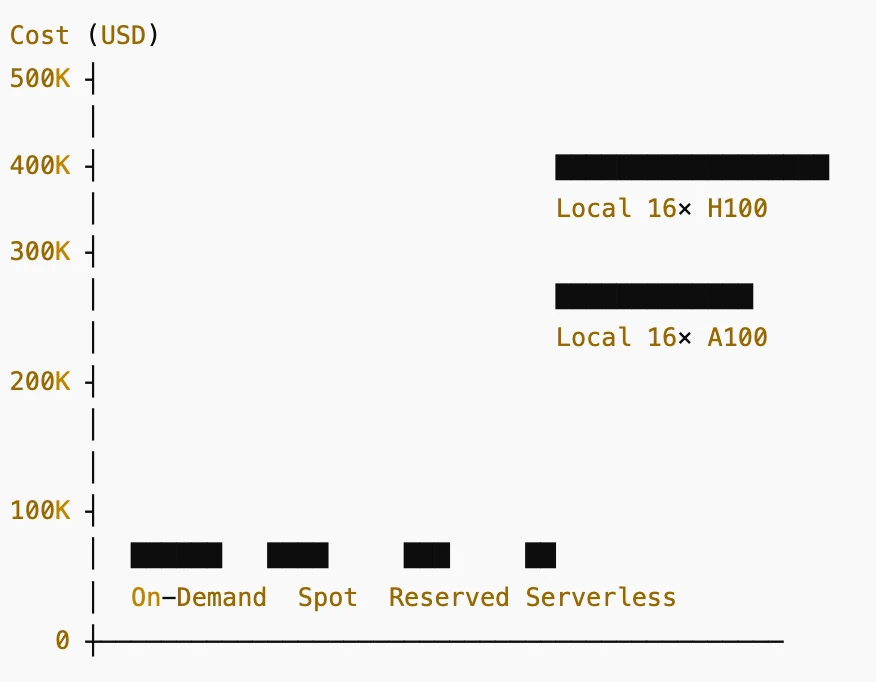
Barres (de gauche à droite) :
- À la demande : ~26 000 $/an
- Instances Spot : ~13 000 $/an
- Réservé / Abonnement : ~8 000 $/an
- Facturation GPU serverless : ~5 000 $/an
- Local 16 × A100 80 Go : ~240 000 $ de coût matériel
- Local 16 × H100 80 Go : ~480 000 $ de coût matériel
Une méthode plus efficace et moins coûteuse pour déployer DeepSeek V3.2 sur GPU cloud
Novita AI propose quatre modèles de facturation GPU pour s’adapter à différentes charges de travail et exigences de coûts.
Modèle de tarification Méthode de facturation Disponibilité des ressources Niveau de coût Risque d’interruption Cas d’usage typiques À la demande (pay-as-you-go) Facturé selon le temps d’exécution réel (par seconde ou par heure) Élevée, les instances peuvent être démarrées ou arrêtées à tout moment Moyen Aucun Développement et test, débogage de modèles, charges de travail variables ou imprévisibles Instances Spot Facturé selon le temps d’exécution à des tarifs réduits Moyenne, dépend de la capacité inactive disponible Faible (souvent jusqu’à ~50 % moins cher que l’à la demande) Oui, les instances peuvent être préemptées Tâches par lots, inférence hors ligne, entraînement tolérant aux pannes, charges de travail sensibles aux coûts Abonnement / Plans réservés Facturation fixe mensuelle ou annuelle Élevée, ressources dédiées et prévisibles Moyen à faible (réduit par rapport à l’à la demande) Aucun Charges de travail stables à long terme, systèmes de production, entraînement ou inférence continu Facturation GPU serverless Facturé selon la puissance de calcul réellement consommée par exécution Mise à l’échelle automatique selon la demande Faible à moyen (ne payez que ce que vous utilisez) Aucun (entièrement géré par la plateforme) Inférence pilotée par les événements, trafic en rafale, service de modèles basé sur API, surcharge opérationnelle minimale
1. À la demande (pay-as-you-go)
L’à la demande est le modèle de consommation standard dans lequel la puissance de calcul GPU est facturée strictement selon le temps d’exécution, généralement par seconde ou par heure, sans engagement ni réservation à long terme. Il offre une flexibilité maximale et est parfaitement adapté aux charges de travail variables, aux utilisations intermittentes et aux expérimentations en phase précoce, car les coûts ne sont engagés que lorsque l’instance est active. Le stockage et les ressources auxiliaires, y compris les disques et le réseau, sont facturés à l’usage.
Essayez des GPU rapides et peu coûteux dès maintenant !
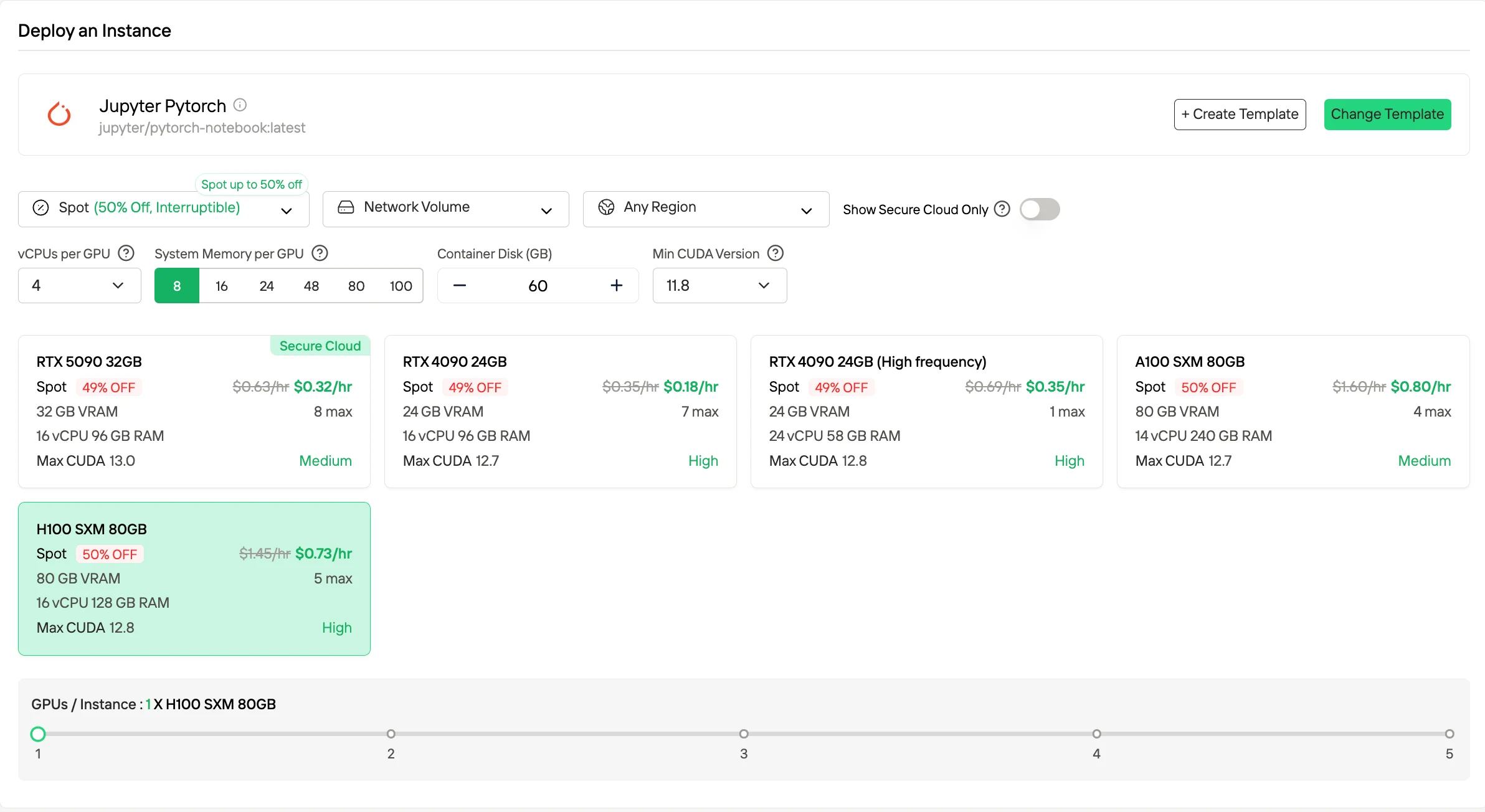
2. Instances Spot
Les instances Spot proposent des tarifs horaires considérablement réduits, souvent jusqu’à environ 50 % moins chers que les tarifs à la demande, en utilisant la capacité GPU inactive. Ces instances peuvent être préemptées par la plateforme. Novita atténue ce risque en fournissant une fenêtre de protection d’une heure et des notifications d’arrêt anticipé. Ce mode de tarification est adapté aux charges de travail tolérantes aux pannes ou par lots, où des interruptions occasionnelles peuvent être acceptées.
Essayez des GPU rapides et peu coûteux dès maintenant !
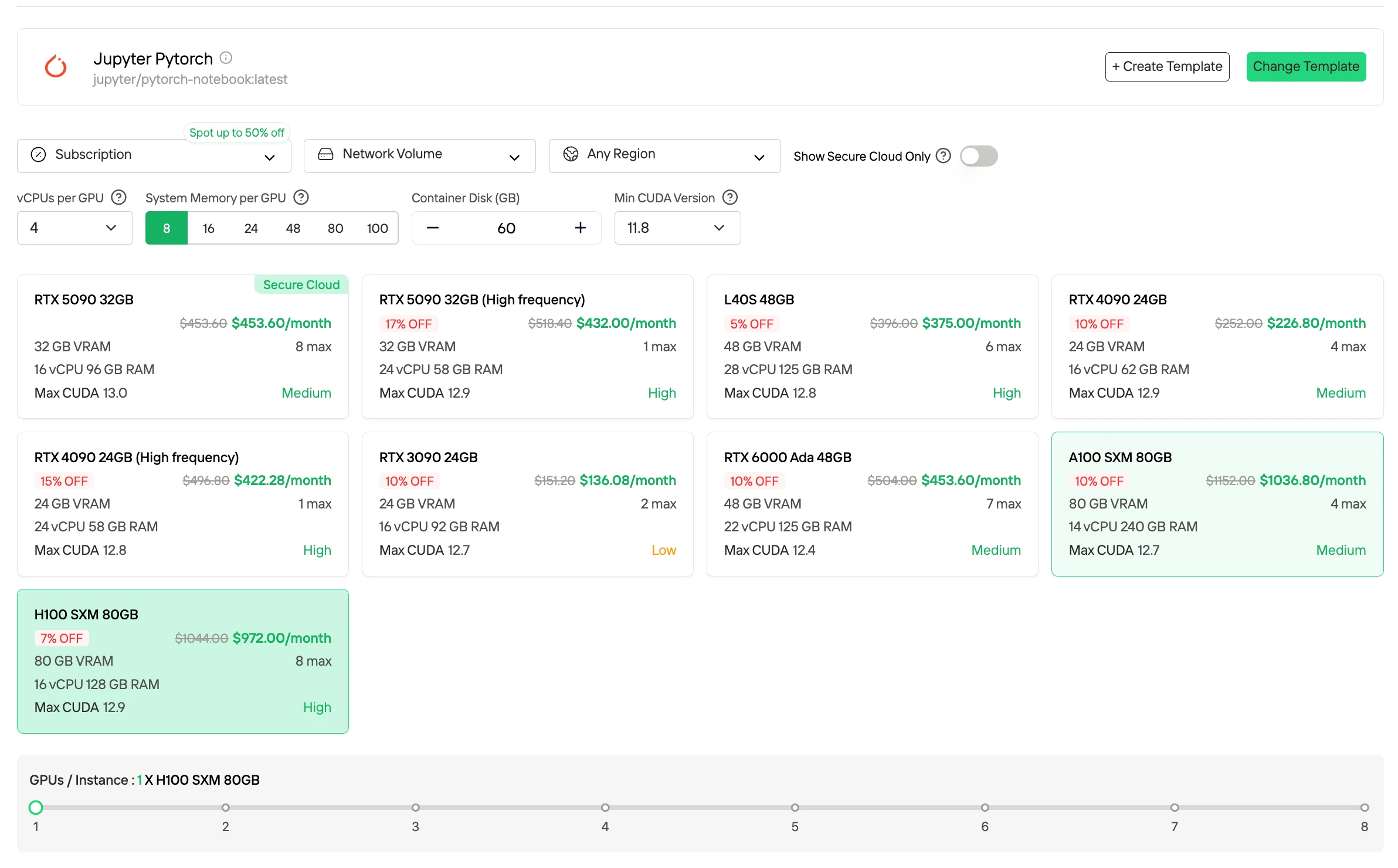
3. Abonnement / Plans réservés
Les abonnements et les plans réservés sont disponibles sur des bases mensuelles ou annuelles et fournissent des ressources GPU dédiées avec une disponibilité prévisible. Par rapport à la tarification à la demande, ces plans offrent généralement des coûts unitaires effectifs plus bas en échange d’un engagement à plus long terme. Ils sont particulièrement adaptés aux charges de travail stables et continues, ainsi qu’aux environnements de production nécessitant une capacité de calcul constante.
Essayez des GPU rapides et peu coûteux dès maintenant !
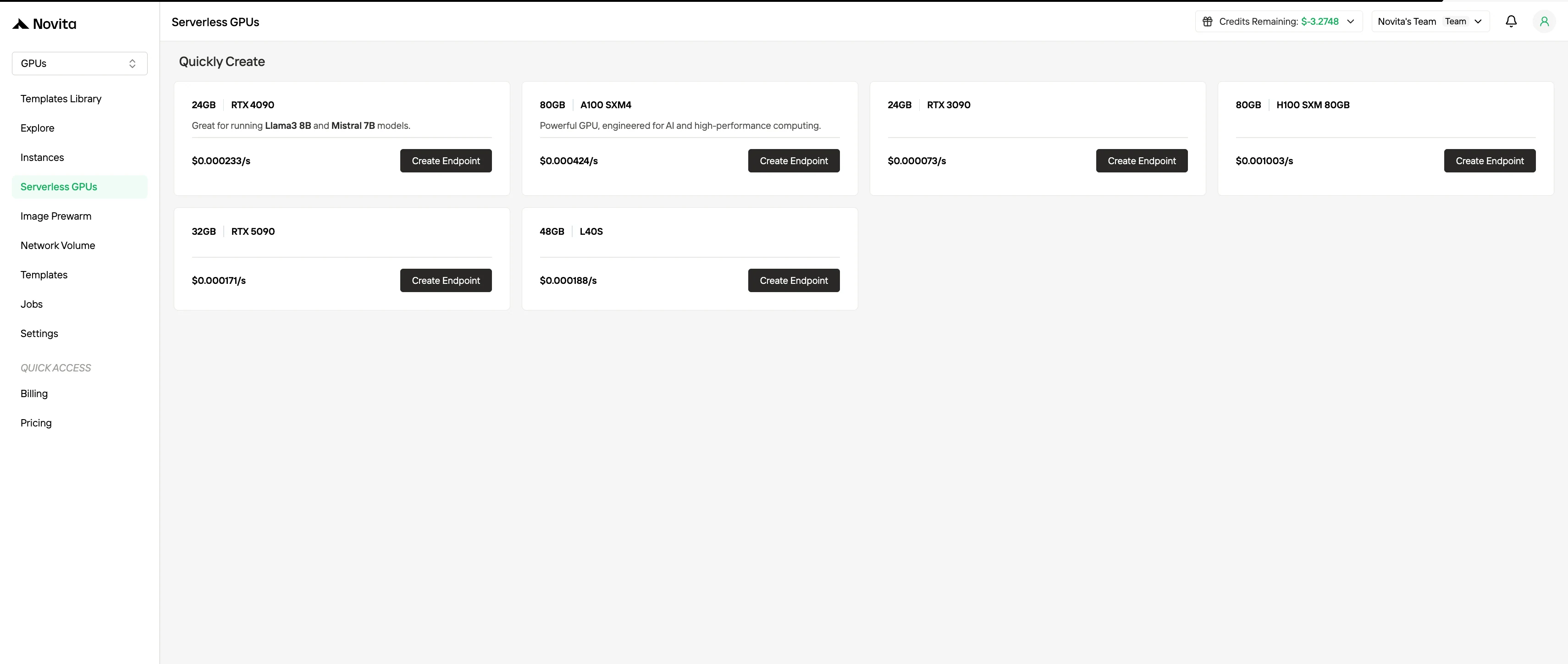
4. Facturation GPU serverless
La facturation GPU serverless abstrait la gestion des instances en mettant automatiquement à l’échelle les ressources GPU en fonction de la demande de charge de travail. Les utilisateurs ne sont facturés que pour les ressources de calcul réellement consommées, et non pour les instances provisionnées. Ce modèle est avantageux pour les charges de travail pilotées par les événements ou très élastiques, car il minimise la surcharge opérationnelle tout en améliorant l’efficacité des coûts.
Essayez des GPU rapides et peu coûteux dès maintenant !
Novita AI propose également des modèles, conçus pour réduire considérablement la surcharge opérationnelle et cognitive associée au déploiement de charges de travail IA basées sur GPU. Au lieu de demander aux développeurs d’assembler manuellement des environnements à partir de zéro, le système de modèles fournit des images préconfigurées, prêtes pour la production, qui regroupent le système d’exploitation, les versions de CUDA et cuDNN, les frameworks d’apprentissage profond, les moteurs d’inférence, et dans certains cas même des piles de service de modèles entièrement préconfigurées.
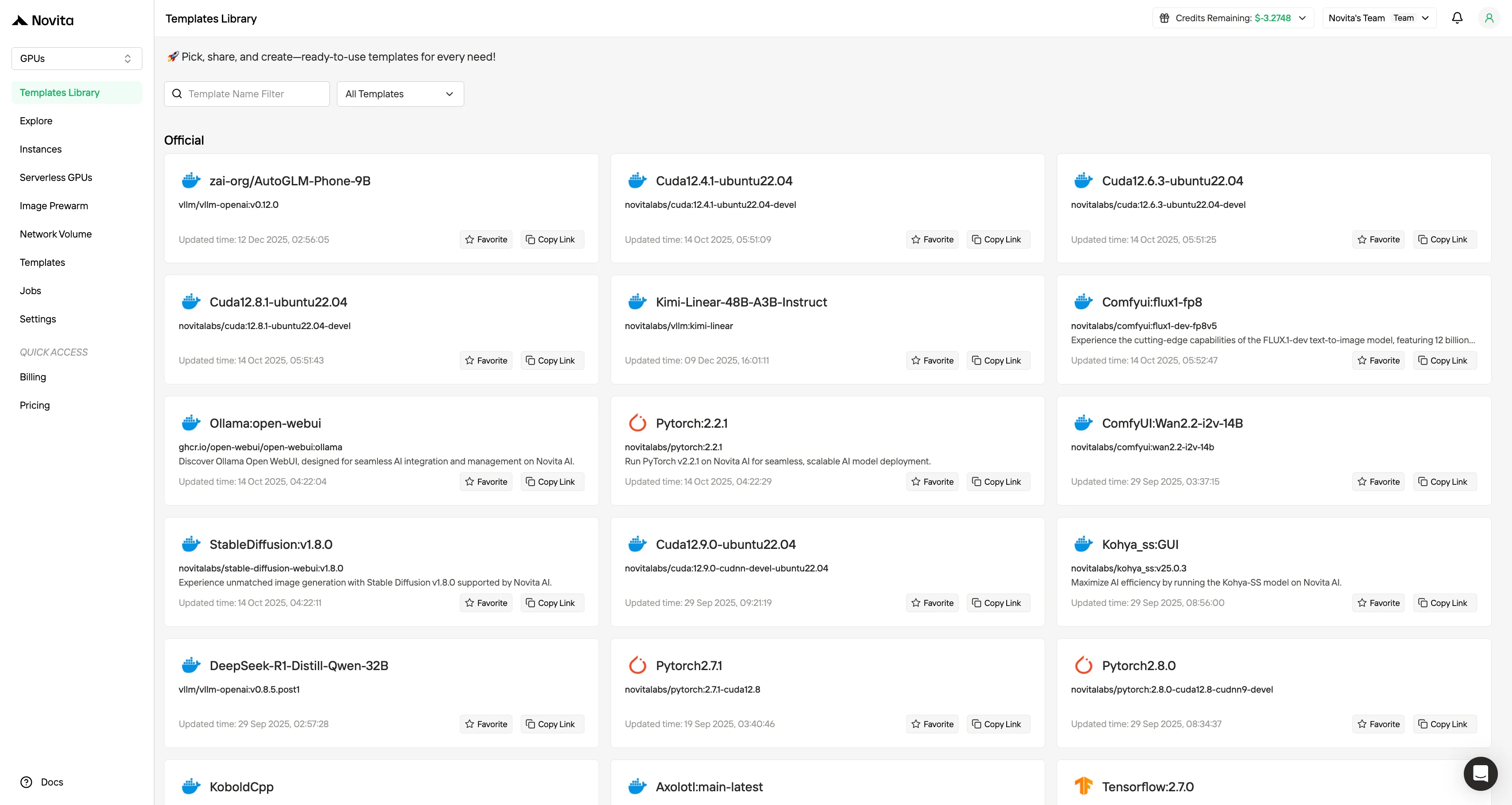
Comment déployer DeepSeek V3.2 sur Novita AI
Étape 1 : Créer un compte
Créez votre compte Novita AI via notre site web. Après l’inscription, accédez à la section « Explorer » dans la barre latérale gauche pour consulter nos offres GPU et commencer votre parcours de développement IA.

Étape 2 : Explorer les modèles et les serveurs GPU
Choisissez parmi des modèles comme PyTorch, TensorFlow ou CUDA correspondant aux besoins de votre projet. Sélectionnez ensuite votre configuration GPU préférée : les options incluent les puissants L40S, RTX 4090 ou A100 SXM4, chacun avec des spécifications de VRAM, RAM et stockage différentes.
Étape 3 : Personnaliser votre déploiement et lancer une instance
Personnalisez votre environnement en sélectionnant votre système d’exploitation préféré et les options de configuration pour garantir des performances optimales pour vos charges de travail IA et vos besoins de développement spécifiques. Votre environnement GPU haute performance sera alors prêt en quelques minutes, vous permettant de commencer immédiatement vos projets d’apprentissage automatique, de rendu ou de calcul.
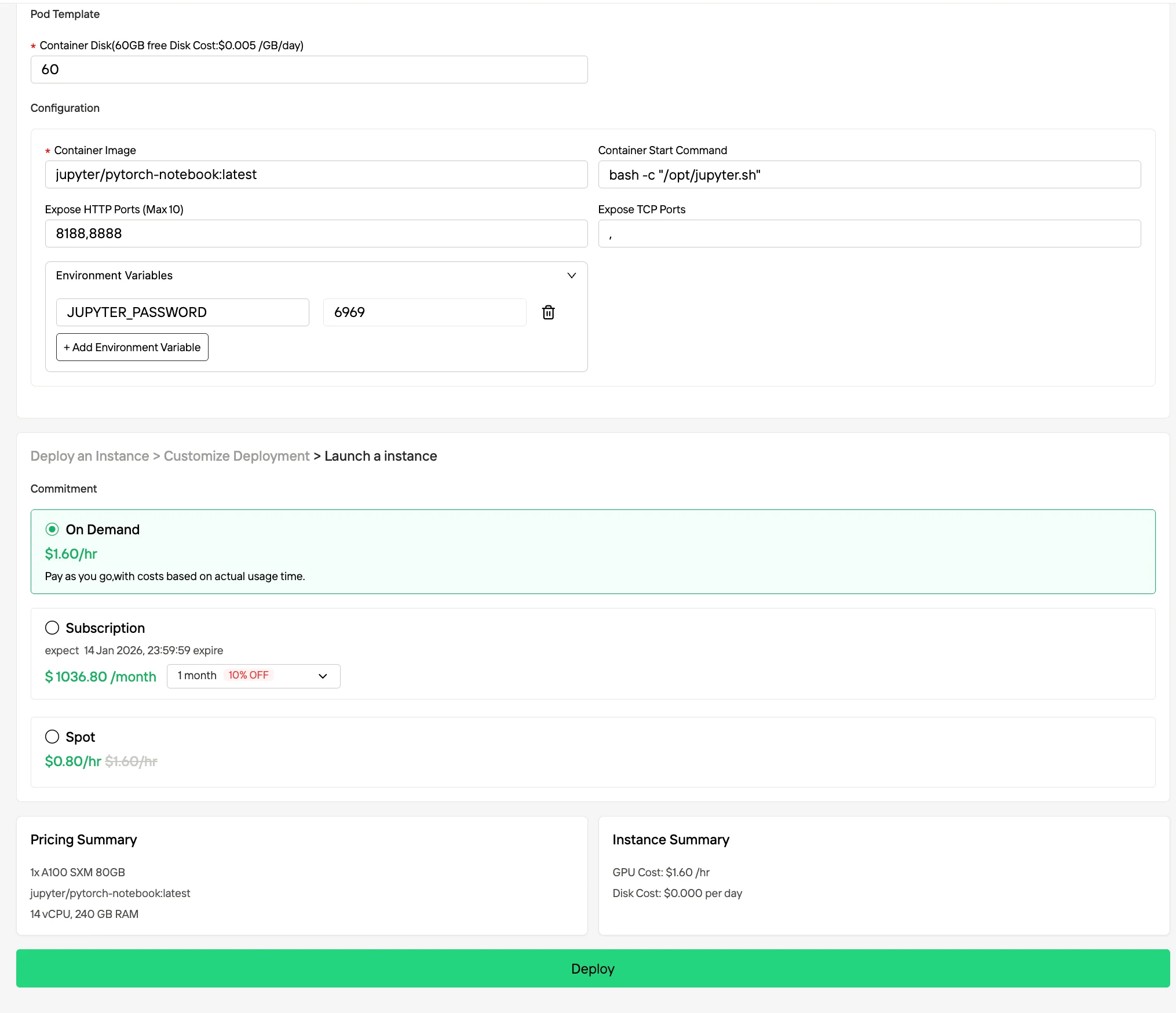
Étape 4 : Surveiller l’avancement du déploiement
Accédez à la Gestion des instances pour ouvrir la console de contrôle. Ce tableau de bord vous permet de suivre l’état du déploiement en temps réel.
Essayez des GPU rapides et peu coûteux dès maintenant !
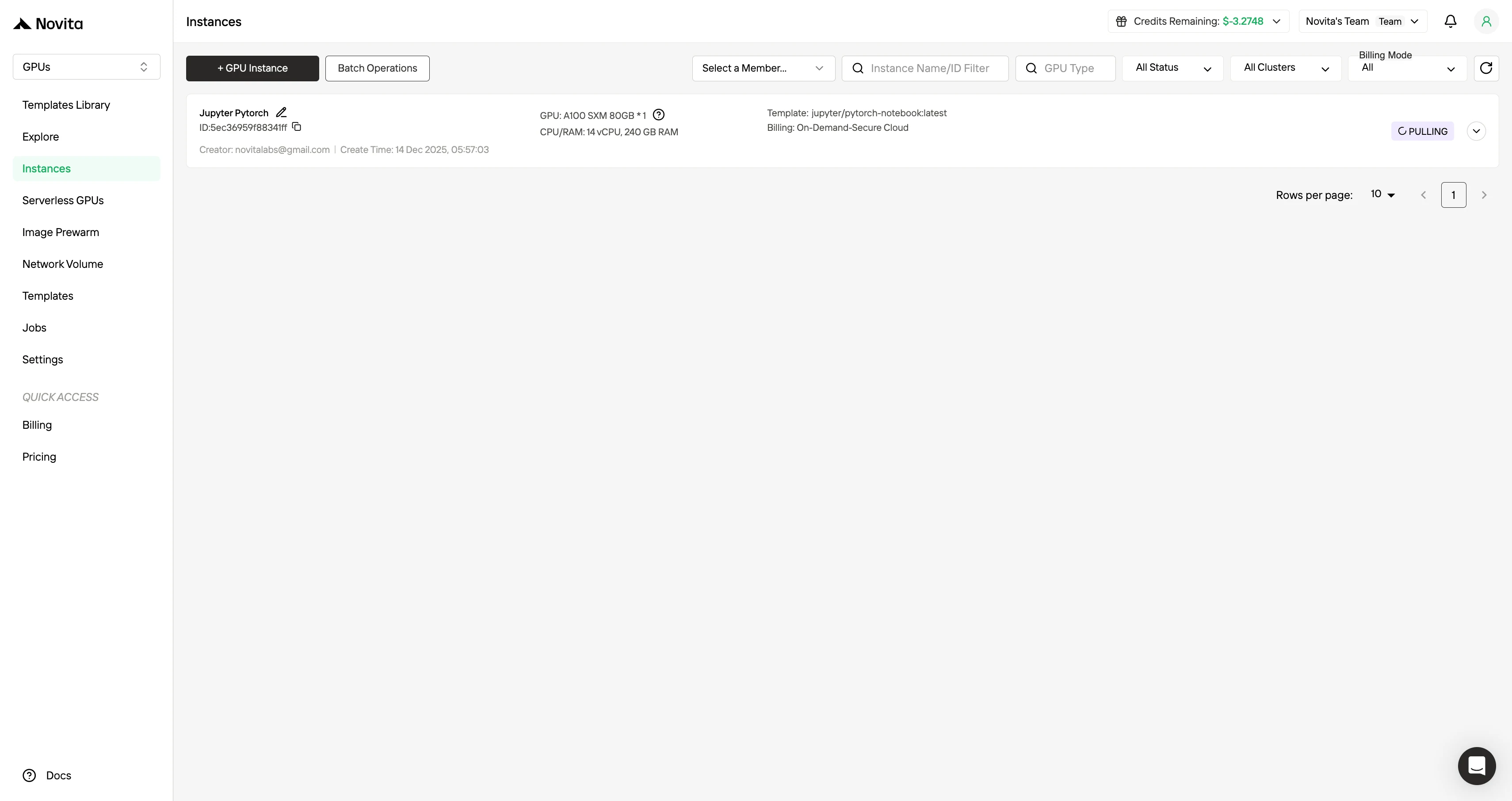
Étape 5 : Vérifier l’état de téléchargement de l’image
Cliquez sur votre instance spécifique pour suivre la progression du téléchargement de l’image conteneur. Ce processus peut prendre plusieurs minutes selon les conditions du réseau.
Étape 6 : Vérifier le succès du déploiement
Après le démarrage de l’instance, elle commencera à télécharger le modèle. Cliquez sur « Journaux » → « Journaux de l’instance » pour suivre la progression du téléchargement du modèle. Recherchez le message
"Application startup complete."dans les journaux de l’instance. Cela indique que le processus de déploiement s’est terminé avec succès.Cliquez sur « Se connecter », puis cliquez sur → « Se connecter au service HTTP [Port 8000] ». Comme il s’agit d’un service API, vous devrez copier l’adresse.
Pour effectuer des requêtes sur votre modèle, veuillez remplacer « http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai » par votre adresse exposée réelle. Copiez le code suivant pour accéder à votre modèle privé !
DeepSeek V3.2 représente une évolution des grands modèles de langage MoE orientée déploiement, combinant attention éparse, raisonnement conscient des agents et apprentissage par renforcement à récompenses mixtes pour améliorer l’efficacité des longs contextes et la fiabilité multi-outils. Cependant, en paramètres FP16/BF16, DeepSeek V3.2 nécessite environ 1,3 To de mémoire GPU agrégée, ce qui représente des centaines de milliers de dollars de coûts matériels GPU rien que pour cela. La quantification et le déchargement réduisent considérablement la pression sur la mémoire mais introduisent des compromis en termes de complexité et de performances. À l’inverse, le déploiement sur cloud via Novita AI offre une voie plus accessible, en s’appuyant sur des modèles de facturation flexibles, des modèles préconfigurés et un provisionnement rapide pour réduire à la fois les barrières financières et opérationnelles. Ensemble, ces options clarifient comment DeepSeek V3.2 peut être déployé de manière stratégique plutôt que de manière prohibitivement coûteuse.
Questions fréquemment posées
Pourquoi DeepSeek V3.2 nécessite-t-il une aussi grande mémoire GPU en pleine précision ?
DeepSeek V3.2 nécessite une grande mémoire GPU car ses ≈685B paramètres, combinés aux caches KV de long contexte et aux tampons d’exécution en temps réel, poussent les déploiements FP16/BF16 à environ 1,3 To de VRAM agrégée.
Comment DeepSeek V3.2 réduit-il les coûts des longs contextes par rapport aux modèles précédents ?
DeepSeek V3.2 introduit l’attention éparse DeepSeek (DSA), qui élimine l’attention sur tous les jetons sauf les k plus pertinents, réduisant ainsi le calcul des longs contextes et l’utilisation de la VRAM de 50 à 70 % par rapport à l’attention dense pour de grandes longueurs de contexte.
Quel matériel est généralement nécessaire pour exécuter DeepSeek V3.2 en FP16/BF16 ?
L’inférence en pleine précision de DeepSeek V3.2 repose couramment sur 8 à 16 GPU A100 ou H100 avec 80 Go de VRAM chacun, soit un total de près de 1,3 To de mémoire GPU.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions IA. APIs intégrées, serverless, instances GPU — les outils rentables dont vous avez besoin. Éliminez les infrastructures, commencez gratuitement et concrétisez votre vision IA.
Lectures recommandées
MiniMax Speech 02 : Meilleure solution pour une génération vocale rapide et naturelle
Exigences VRAM d’ERNIE-4.5-VL-A3B : Exécutez des modèles multimodaux à moindre coût
Qwen3 Embedding 8B : Recherche puissante, personnalisation flexible et multilingue



