

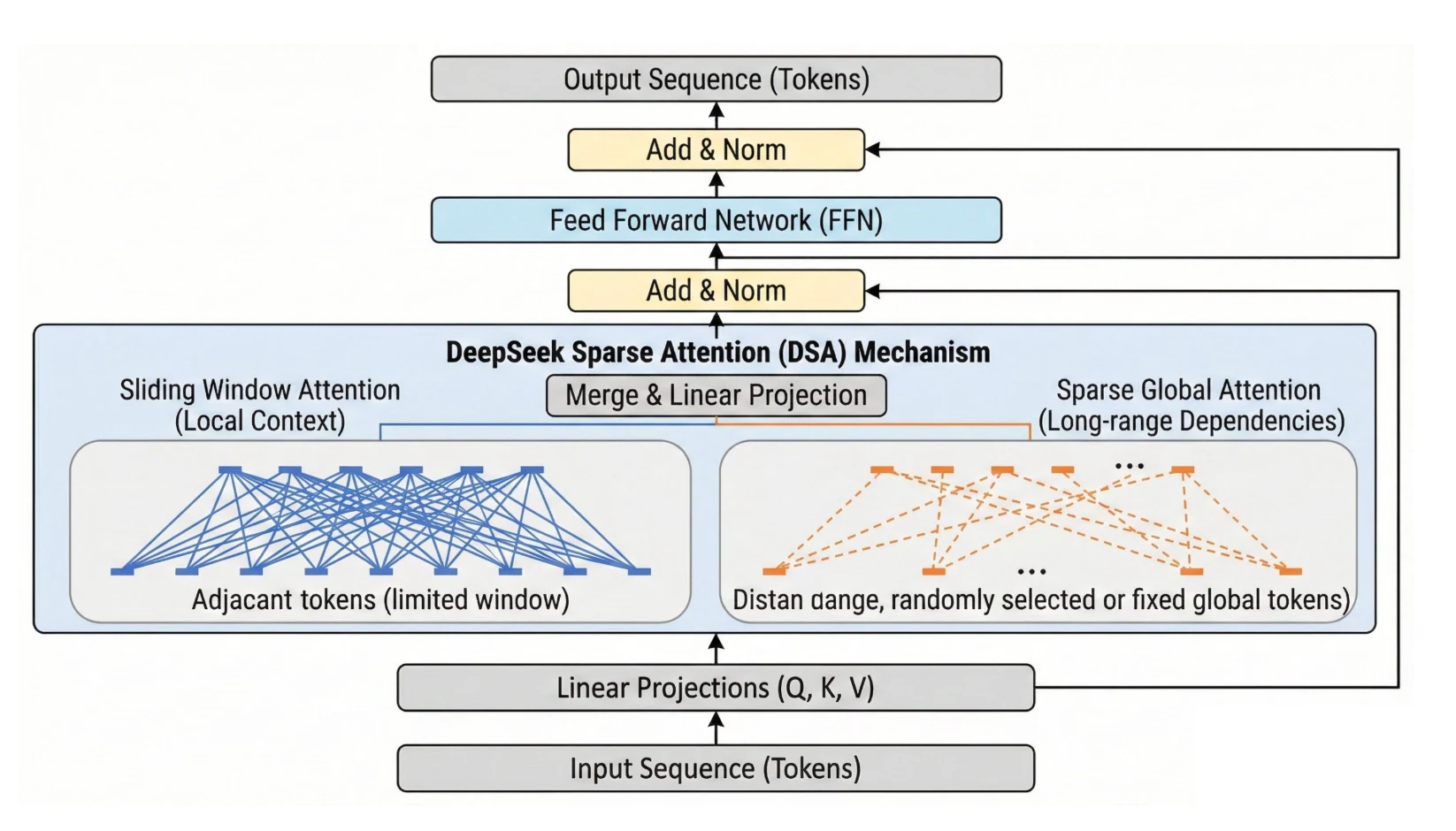
- Основные особенности архитектуры DeepSeek V3.2
- Влияние VRAM DSA из DeepSeek V 3.2
- Требования DeepSeek V3.2 к VRAM и оборудованию
- Сколько стоит локальное развертывание DeepSeek V3.2?
- Сравнение стоимости: локальный GPU против облачного GPU DeepSeek V3.2
- Более эффективный и дешевый способ работы с DeepSeek V3.2 на облачном GPU
- Как развернуть DeepSeek V3.2 на Novita AI
Novita AI запускает кампанию «Месяц разработки» (Build Month), предлагая разработчикам эксклюзивную скидку до 20% на все основные продукты!
По мере того как крупные модели рассуждений и агентные модели переходят из исследований в реальное развертывание, разработчики сталкиваются с критическим противоречием между возможностями и стоимостью. DeepSeek V3.2 является ярким примером этой проблемы: хотя он обеспечивает высокую пропускную способность при длинном контексте, надежность многошагового использования инструментов и улучшенную стабильность обучения с подкреплением, он также предъявляет существенные требования к оборудованию и VRAM, особенно при развертывании с полной точностью.
В этой статье мы рассматриваем эти вопросы, анализируя архитектуру DeepSeek V3.2, требования к VRAM и оборудованию, структуру стоимости локального развертывания и экономически эффективные альтернативы, предоставляемые гибкими предложениями GPU от Novita AI.
Основные особенности архитектуры DeepSeek V3.2
DeepSeek V3.2 лучше всего понимать как обновление «с упором на развертывание» по сравнению с V3/R1: оно нацелено на практическую пропускную способность при длинном контексте, агентное использование инструментов с постоянными рассуждениями и более гибкий стек RL, который сочетает проверяемые награды с наградами на основе рубрик для непроверяемых задач, что напрямую важно для пользователей API, которых волнует задержка, нагрузка на контекст и надежность многошаговых операций.
| Слой | Что добавляет V3.2 | Что это меняет для пользователей API |
|---|---|---|
| Длинный контекст (DSA) | Разреженное внимание DeepSeek (DSA) с молниеносным индексатором + селектором токенов (top-k). Разреженное внимание снижает объем вычислений внимания. | Длинные запросы становятся экономически целесообразными: более низкая предельная стоимость за дополнительную позицию токена в длинных контекстах, улучшенная сквозная скорость в сценариях с длинным контекстом, меньше развертываний, «требующих разбиения на части». |
| Возможности агента | «Рассуждения при использовании инструментов» плюс управление контекстом, которое сохраняет следы рассуждений между выводами инструментов, и крупномасштабный агентный синтез данных (официальные примечания к релизу: 1800+ сред, 85к+ сложных инструкций). | Более высокий процент успешных операций в многоинструментальных рабочих процессах. Снижение количества сбоев из-за повторного вычисления состояния при каждом вызове инструмента, но также повышенный риск переполнения контекста при неправильном управлении. |
| RLVR + множественные награды | Смешанный RL использует награду за результат на основе правил + штраф за длину + языковую согласованность для задач рассуждений/агентов; порождающая модель наград с рубриками для каждого запроса для общих задач. GRPO стабилизирован с помощью несмещенной оценки KL, маскировки последовательностей off-policy, сохранения маршрутизации (MoE), сохранения маски выборки (top-p/top-k). | Более надежное согласование для открытых задач без символических верификаторов; лучшая стабильность RL в масштабах; более контролируемая многословность с помощью штрафов за длину. |
Влияние VRAM DSA из DeepSeek V 3.2
Разреженное внимание DeepSeek (DSA) снижает стоимость вычислений и памяти для слоев внимания при длинных контекстах, отсекая внимание только наиболее релевантным токенам, что снижает общий количество операций FLOPs и нагрузку на VRAM по сравнению с плотным вниманием при большом количестве токенов. Снижение цен на API более чем на 50% отражает эти преимущества эффективности на практике.
- DSA снижает стоимость вычислений и памяти при длинном контексте примерно на 50%+ по сравнению с плотным вниманием в сценариях с длинными последовательностями, с незначительным снижением качества.
- Это снижение не изменяет общее количество параметров модели (≈685 млрд), но уменьшает объем памяти во время выполнения для длинных окон, особенно использование KV-кэша и рабочего пространства внимания на токен.
| Длина контекста | Плотное внимание (базовая тенденция) | Эффект DSA (разреженного внимания DeepSeek) (приблизительно) |
|---|---|---|
| 8K токенов | Базовая память и вычислительные ресурсы | аналогичная или немного более низкая память — минимальные накладные расходы на разреженность при коротких длинах |
| 32K токенов | Квадратичный рост становится большим | на 30-40% меньше использования памяти по сравнению с плотным вниманием при аналогичных длинах контекста (инференс) |
| 128K токенов | Стоимость и память становятся очень высокими | на 60-70% меньше использования памяти и стоимости, при этом стоимость инференса снижена более чем на 60%, а использование памяти снижено примерно на 70% с DSA |
Из Amitray
Требования DeepSeek V3.2 к VRAM и оборудованию
Полная точность (FP16/BF16)
При стандартном развертывании с полной точностью (FP16/BF16) инференс DeepSeek-V3.2 предъявляет крайне высокие требования к оборудованию, поскольку совокупный объем памяти GPU, необходимый для весов модели и выполнения во время работы, превышает примерно 1 ТБ. Для сценариев BF16/FP16 обычно используются конфигурации 8–16 GPU H100 или A100 класса с 80 ГБ VRAM каждая, что в сумме дает общую емкость памяти GPU почти 1,3 ТБ.
Компромиссы квантования и выгрузки
| Уровень квантования | Приблизительный объем памяти |
|---|---|
| FP16 / BF16 | 1,3 ТБ всего |
| 8-битный (w8a8) | 670 ГБ всего |
| 4-битный | 335 ГБ всего |
Сколько стоит локальное развертывание DeepSeek V3.2?
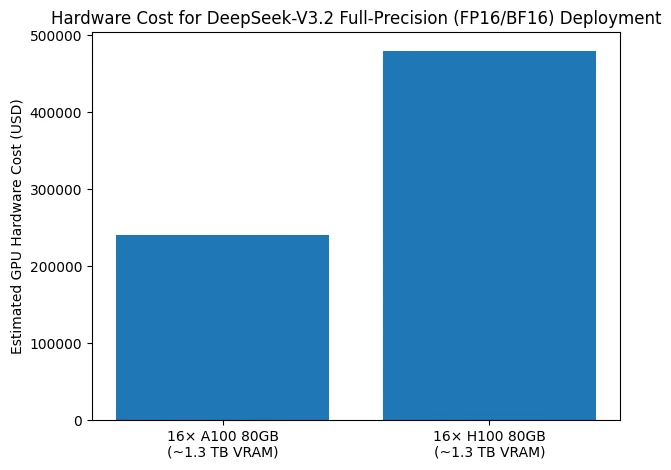
Столбчатая диаграмма иллюстрирует стоимость оборудования, необходимого для развертывания DeepSeek-V3.2 в режиме полной точности (FP16/BF16). Для удовлетворения требования примерно к 1,3 ТБ памяти GPU типичная конфигурация использует 16 GPU с 80 ГБ VRAM каждая. При использовании GPU A100 80 ГБ оценочная стоимость только GPU составляет около 240 000 долларов США, а эквивалентная конфигурация на основе GPU H100 80 ГБ увеличивает стоимость примерно до 480 000 долларов США.
Это сравнение подчеркивает, что даже без учета серверов, высокоскоростных межсоединений, электропитания и инфраструктуры охлаждения, инференс DeepSeek-V3.2 с полной точностью уже предполагает инвестиции в GPU в размере нескольких сотен тысяч долларов США только за сами GPU. Таким образом, цифра подчеркивает исключительно высокий барьер стоимости оборудования для развертывания DeepSeek-V3.2 в FP16/BF16, что объясняет, почему такие развертывания в основном ограничены крупными дата-центрами, и почему стратегии квантования и выгрузки часто считаются необходимыми на практике.
Сравнение стоимости: локальный GPU против облачного GPU DeepSeek V3.2
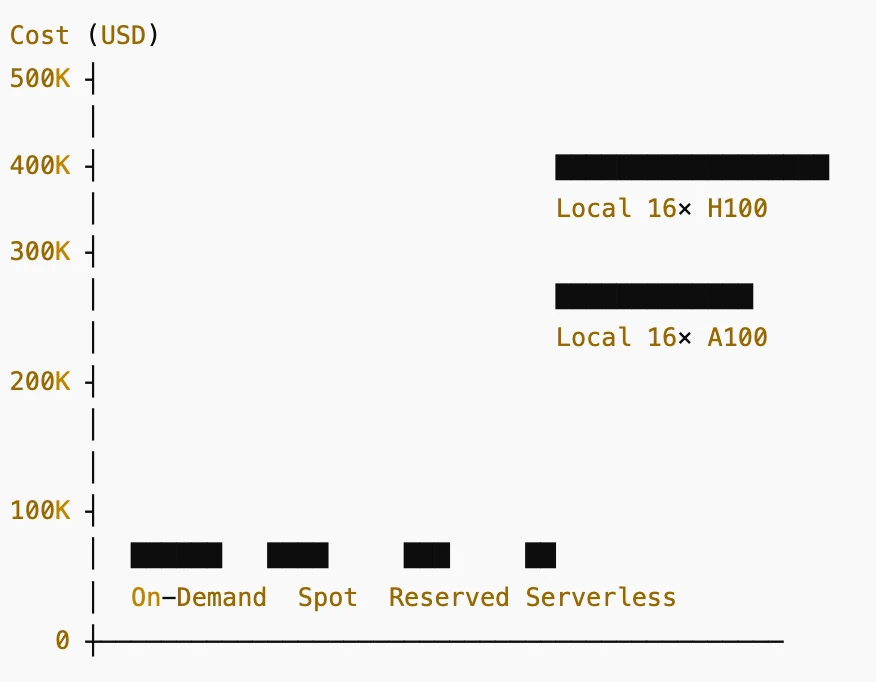
Столбцы (слева направо):
- По требованию (On-Demand): ~26 000 долларов в год
- Спотовые инстансы (Spot Instances): ~13 000 долларов в год
- Резервированные / подписки (Reserved / Subscription): ~8 000 долларов в год
- Бессерверное биллинг GPU (Serverless GPU Billing): ~5 000 долларов в год
- Локальный 16× A100 80 ГБ: ~240 000 долларов стоимость оборудования
- Локальный 16× H100 80 ГБ: ~480 000 долларов стоимость оборудования
Более эффективный и дешевый способ работы с DeepSeek V3.2 на облачном GPU
Novita AI предоставляет четыре модели биллинга GPU для адаптации к различным паттернам рабочих нагрузок и требованиям к стоимости.
Модель ценообразования Метод биллинга Доступность ресурсов Уровень стоимости Риск прерывания Типичные сценарии использования По требованию (Pay-as-you-go) Оплачивается по фактическому времени работы (за секунду или час) Высокий, инстансы можно запускать или останавливать в любое время Средний Отсутствует Разработка и тестирование, отладка моделей, переменные или непредсказуемые рабочие нагрузки Спотовые инстансы (Spot Instances) Оплачивается по времени работы по сниженным тарифам Средний, зависит от доступного простаивающего объема Низкий (часто до ~50% дешевле, чем по требованию) Да, инстансы могут быть принудительно завершены Пакетные задачи, офлайн-инференс, отказоустойчивое обучение, чувствительные к стоимости рабочие нагрузки Подписка / Резервированные планы (Subscription / Reserved Plans) Фиксированная ежемесячная или годовая оплата Высокий, выделенные и предсказуемые ресурсы Средний–Низкий (скидка по сравнению с оплатой по требованию) Отсутствует Стабильные долгосрочные рабочие нагрузки, производственные системы, непрерывное обучение или инференс Бессерверное биллинг GPU (Serverless GPU Billing) Оплачивается по фактически потребленным вычислительным ресурсам за выполнение Автоматически масштабируется в зависимости от спроса Низкий–Средний (оплачивается только за то, что используется) Отсутствует (полностью управляется платформой) Инференс на основе событий, пиковые трафики, обслуживание моделей через API, минимальные накладные расходы на эксплуатацию
- По требованию (Pay-as-you-go)
Оплата по требованию — это стандартная модель потребления, при которой вычислительные ресурсы GPU оплачиваются строго по времени работы, обычно за секунду или час, без долгосрочных обязательств или резервирований. Она обеспечивает максимальную гибкость и хорошо подходит для переменных рабочих нагрузок, нерегулярного использования и ранних экспериментов, так как расходы возникают только тогда, когда инстанс активен. Хранилище и вспомогательные ресурсы, включая диски и сеть, оплачиваются по факту использования.
Попробуйте быстрые и дешевые GPU сейчас!
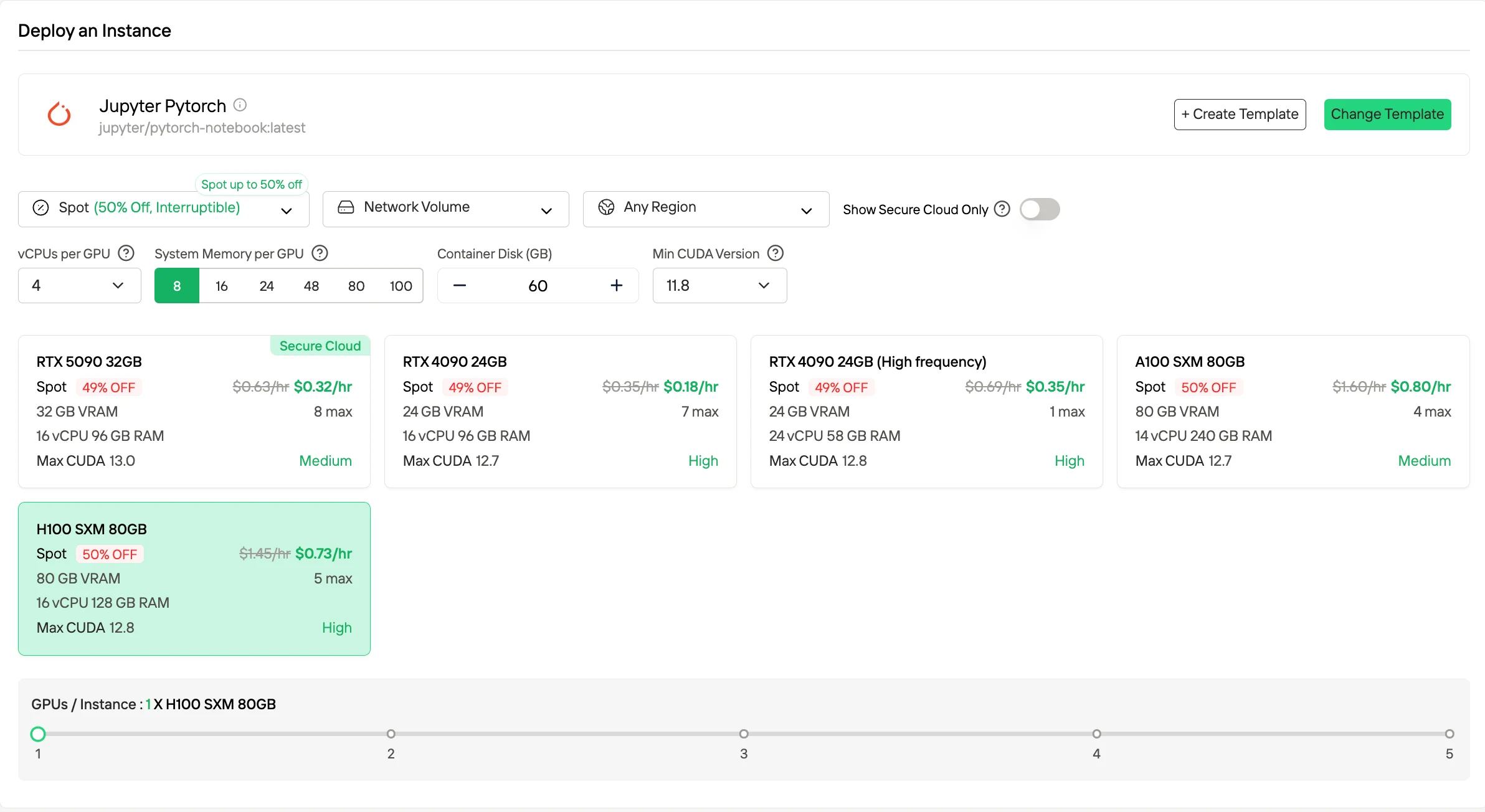
- Спотовые инстансы (Spot Instances)
Спотовые инстансы предлагают значительно сниженные часовые тарифы, часто до примерно 50% ниже ставок по требованию, за счет использования простаивающего объема GPU. Эти инстансы могут быть принудительно завершены платформой. Novita снижает этот риск, предоставляя окно защиты на 1 час и уведомления о завершении заранее. Этот режим ценообразования подходит для отказоустойчивых или пакетных рабочих нагрузок, в которых могут учитываться возможные прерывания.
Попробуйте быстрые и дешевые GPU сейчас!
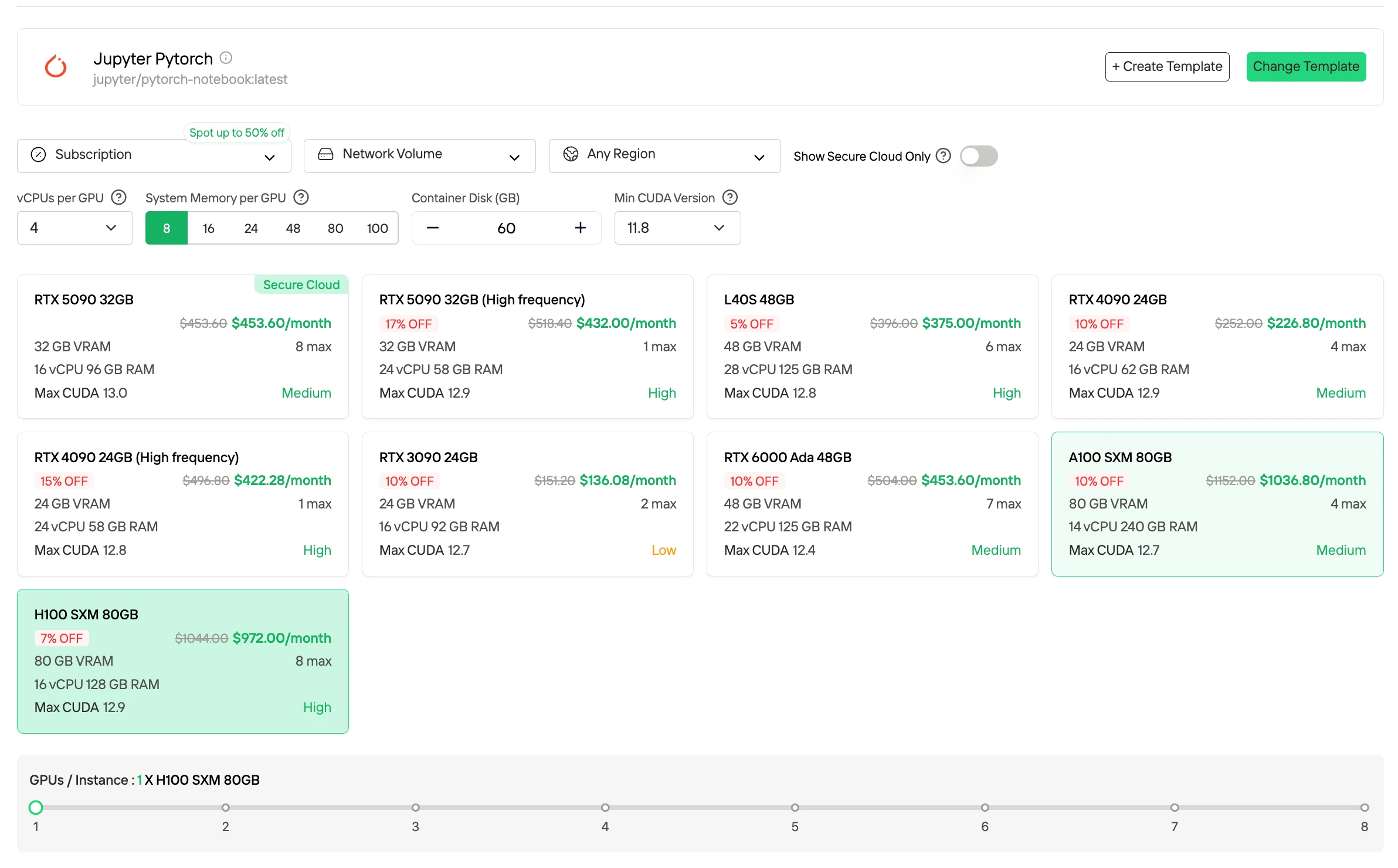
- Подписка / Резервированные планы (Subscription / Reserved Plans)
Подписки и резервированные планы доступны на месячных или годовых условиях и предоставляют выделенные ресурсы GPU с предсказуемой доступностью. По сравнению с ценообразованием по требованию, эти планы обычно обеспечивают более низкую эффективную удельную стоимость в обмен на долгосрочные обязательства. Они наиболее подходят для стабильных, непрерывных рабочих нагрузок и производственных сред, требующих постоянной вычислительной мощности.
Попробуйте быстрые и дешевые GPU сейчас!
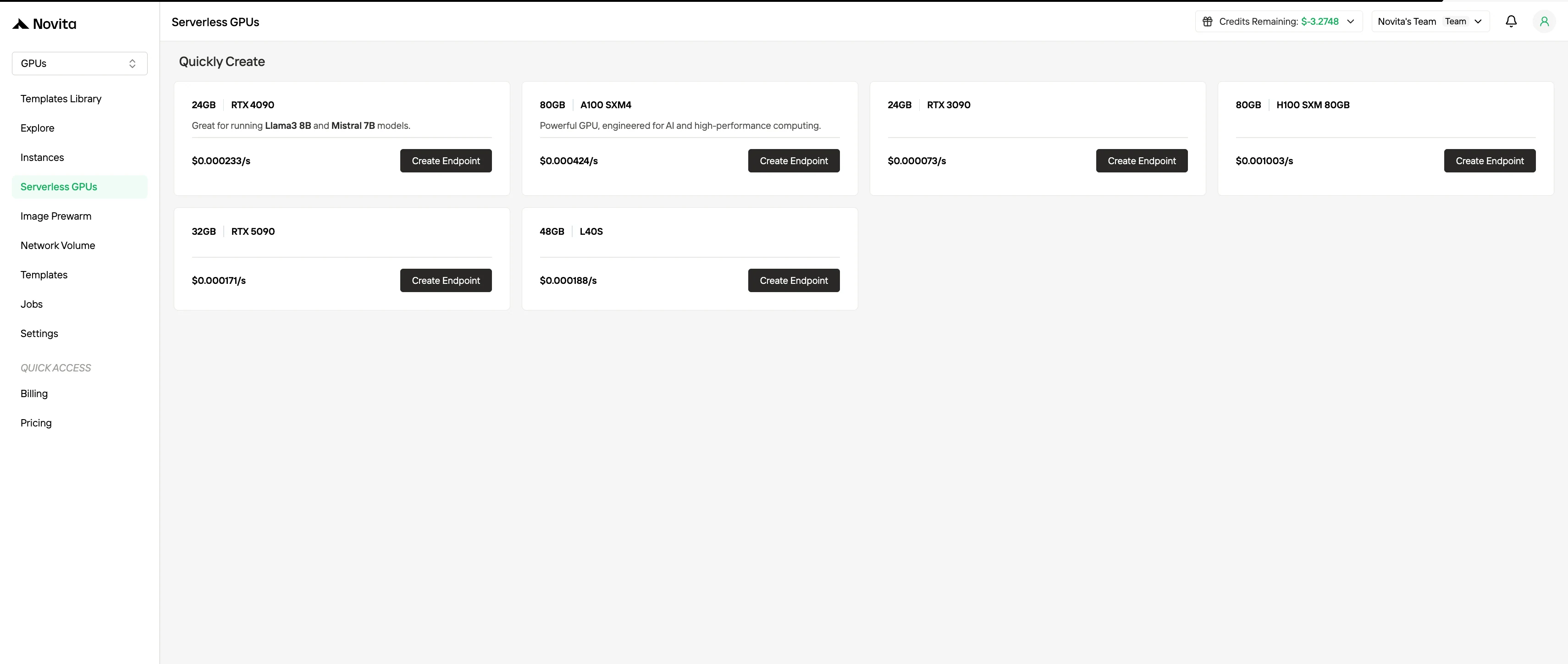
- Бессерверное биллинг GPU (Serverless GPU Billing)
Бессерверное биллинг GPU абстрагирует управление инстансами, автоматически масштабируя ресурсы GPU в ответ на спрос рабочей нагрузки. Пользователи оплачивают только те вычислительные ресурсы, которые фактически потребляются, а не подготовленные инстансы. Эта модель выгодна для рабочих нагрузок на основе событий или сильно эластичных, так как минимизирует эксплуатационные накладные расходы, повышая при этом экономическую эффективность.
Попробуйте быстрые и дешевые GPU сейчас!
Novita AI также предлагает шаблоны, которые разработаны для значительного снижения эксплуатационных и когнитивных накладных расходов, связанных с развертыванием рабочих нагрузок ИИ на GPU. Вместо того чтобы требовать от разработчиков ручной сборки окружений с нуля, система шаблонов предоставляет предварительно настроенные, готовые к производству образы, в которые входят операционная система, версии CUDA и cuDNN, фреймворки глубокого обучения, движки инференса, а в некоторых случаях даже полностью собранные стеки обслуживания моделей.
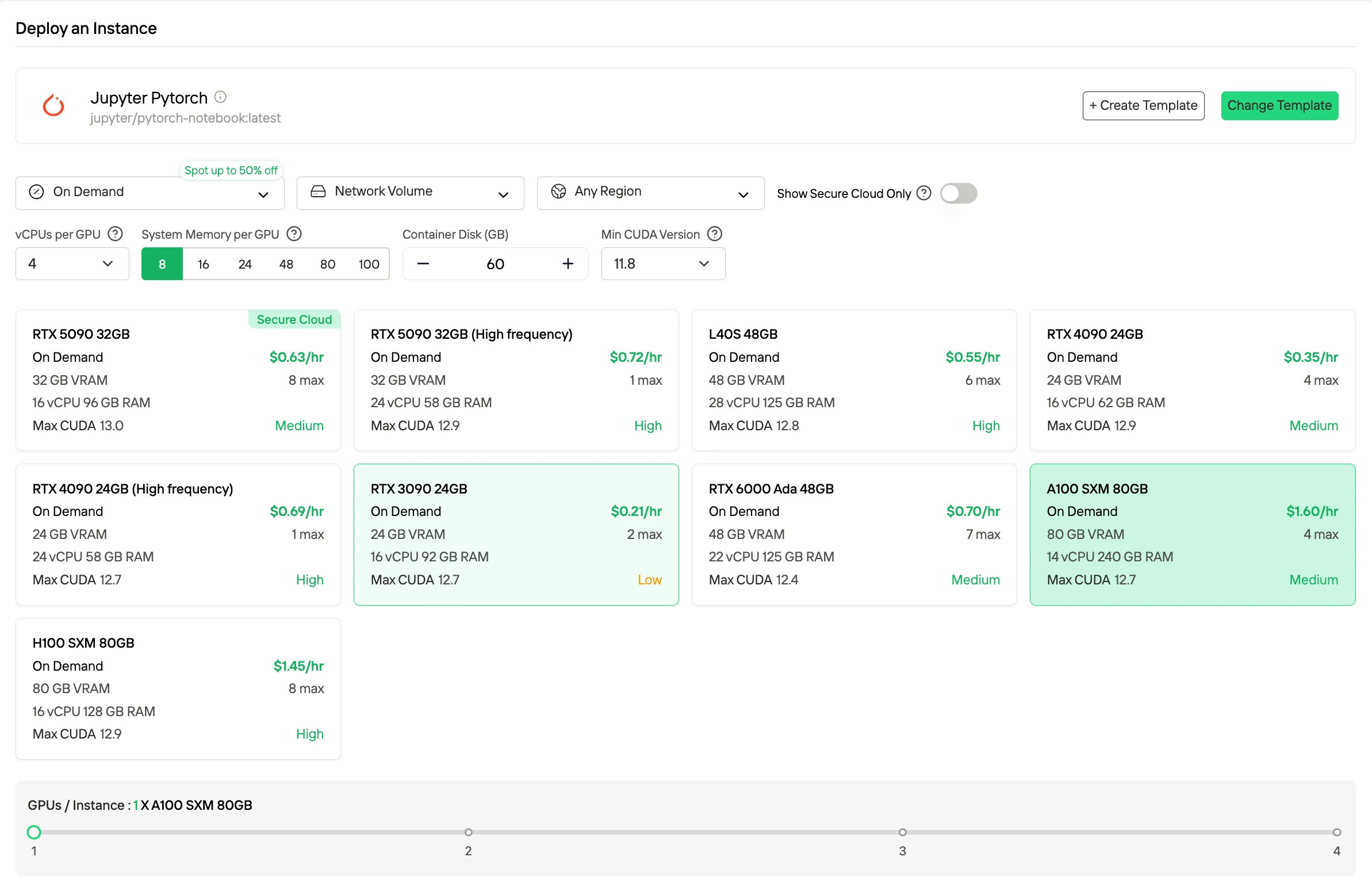
Как развернуть DeepSeek V3.2 на Novita AI
Шаг1: Зарегистрировать аккаунт
Создайте аккаунт Novita AI на нашем сайте. После регистрации перейдите в раздел «Explore» (Исследовать) в левой боковой панели, чтобы просмотреть наши предложения GPU и начать свой путь в разработке ИИ.

Шаг2: Изучение шаблонов и GPU-серверов
Выберите шаблоны, такие как PyTorch, TensorFlow или CUDA, соответствующие потребностям вашего проекта. Затем выберите предпочитаемую конфигурацию GPU — доступны мощные L40S, RTX 4090 или A100 SXM4, каждый с разными характеристиками VRAM, RAM и хранилища.
Шаг3: Настройте развертывание и запустите инстанс
Настройте окружение, выбрав предпочитаемую операционную систему и параметры конфигурации, чтобы обеспечить оптимальную производительность для ваших конкретных рабочих нагрузок ИИ и потребностей разработки. После этого ваше высокопроизводительное GPU-окружение будет готово за несколько минут, и вы сможете немедленно начать свои проекты в области машинного обучения, рендеринга или вычислительных задач.
Шаг 4: Мониторинг прогресса развертывания
Перейдите в Управление инстансами (Instance Management), чтобы получить доступ к консоли управления. Эта панель позволяет отслеживать статус развертывания в реальном времени.
Попробуйте быстрые и дешевые GPU сейчас!
Шаг 5: Просмотр статуса загрузки образа
Нажмите на ваш конкретный инстанс, чтобы отслеживать прогресс загрузки образа контейнера. Этот процесс может занять несколько минут в зависимости от состояния сети.
Шаг 6: Проверка успешного развертывания
После запуска инстанса он начнет загрузку модели. Нажмите «Логи (Logs)» → «Логи инстанса (Instance Logs)», чтобы отслеживать прогресс загрузки модели. Ищите сообщение
"Application startup complete."в логах инстанса. Это указывает, что процесс развертывания завершен успешно.Нажмите «Подключиться (Connect)», затем нажмите → «Подключиться к HTTP-сервису [Порт 8000] (Connect to HTTP Service [Port 8000])». Поскольку это сервис API, вам нужно будет скопировать адрес.
Чтобы отправлять запросы к вашей модели, замените «http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai" на ваш фактический открытый адрес. Скопируйте следующий код для доступа к вашей приватной модели!
DeepSeek V3.2 представляет собой эволюцию крупных MoE-языковых моделей с упором на развертывание, сочетающую разреженное внимание, рассуждения с учетом агентов и обучение с подкреплением с смешанными наградами для повышения эффективности при длинном контексте и надежности многоинструментальных операций. Однако в режиме FP16/BF16 DeepSeek V3.2 требует примерно 1,3 ТБ совокупной памяти GPU, что влечет за собой стоимость оборудования GPU в несколько сотен тысяч долларов США только за сами GPU. Квантование и выгрузка значительно снижают нагрузку на память, но вносят компромиссы в сложность и производительность. В отличие от этого, облачное развертывание на Novita AI предлагает более доступный путь, используя гибкие модели биллинга, предварительно настроенные шаблоны и быстрое подготовление ресурсов для снижения как финансовых, так и эксплуатационных барьеров. Вместе эти варианты позволяют понять, как развертывание DeepSeek V3.2 может быть стратегическим, а не запретительно дорогим.
Часто задаваемые вопросы
Почему DeepSeek V3.2 требует такого большого объема памяти GPU при полной точности?
DeepSeek V3.2 требует большого объема памяти GPU, потому что его ≈685 млрд параметров в сочетании с длинными KV-кэшами контекста и буферами выполнения во время работы продвигают развертывания FP16/BF16 до уровня примерно 1,3 ТБ совокупной VRAM.
Как DeepSeek V3.2 снижает стоимость при длинном контексте по сравнению с предыдущими моделями?
DeepSeek V3.2 внедряет Разреженное внимание DeepSeek (DSA), которое отсекает внимание только top-k релевантным токенам, снижая стоимость вычислений и использование VRAM при длинном контексте на 50–70% по сравнению с плотным вниманием при больших длинах контекста.
Какое оборудование обычно требуется для запуска DeepSeek V3.2 в режиме FP16/BF16?
Инференс DeepSeek V3.2 с полной точностью обычно опирается на 8–16 GPU A100 или H100 с 80 ГБ VRAM каждая, что в сумме дает почти 1,3 ТБ общей памяти GPU.
Novita AI — это универсальная облачная платформа, которая реализует ваши амбиции в области ИИ. Интегрированные API, бессерверные решения, GPU-инстансы — экономически эффективные инструменты, которые вам нужны. Устраните инфраструктурные барьеры, начните бесплатно и воплотите ваше видение ИИ в реальность.
Рекомендуемые материалы
MiniMax Speech 02: Лучшее решение для быстрой и естественной генерации речи ERNIE-4.5-VL-A3B VRAM Requirements: Запускайте мультимодальные модели с меньшими затратами Qwen3 Embedding 8B: Мощный поиск, гибкая кастомизация и многоязычность



